Shakespeare Hut aerial view (YMCA archive image, courtesy of the Cadbury Research Library at the University of Birmingham).
A forgotten building that opened 100 years ago and which was a safe haven for nearly 100,000 First World War soldiers, is to be remembered at the London School of Hygiene & Tropical Medicine this summer.
Digital Drama, a UK-based media production company, was awarded a Heritage Lottery Fund (HLF) grant for the project Resurrecting the Shakespeare Hut, in partnership with the London School of Hygiene & Tropical Medicine and The Mustard Club.
London School of Hygiene & Tropical Medicine under construction, c.1927.
The project commemorates the lives of the servicemen who used, and the women who worked at, the Shakespeare Hut, which was erected on the grounds of what is now the London School of Hygiene & Tropical Medicine’s Keppel Street site in Bloomsbury, in August 1916.
During the First World War the YMCA (http://www.ymca.org.uk/) erected over 4,000 huts to provide soldiers with food and a place to rest, either on the frontline or at home in military camps and railway stations. For the duration of the War, 35,000 unpaid volunteers and 26,000 paid YMCA staff ran the huts, serving 4.8 million troops in 1,500 canteens.
YMCA Huts were a regular sight in England, France and on all the fighting fronts during the First World War, providing a ‘home from home’ for soldiers to rest, recover and be entertained. However, the Keppel Street hut was built with a special purpose – to commemorate the 300th anniversary of Shakespeare’s death and to entertain the troops through the playwright’s work.
In the year of the 400th anniversary of Shakespeare’s death, and with the ongoing commemoration of the First World War Centenary, this is a relevant time to resurrect the Shakespeare Hut. The project will introduce the public to the Hut’s history, lift the lid on what life was like for those who used the building, and relive stories of those who fought and lived through the First World War, as well as preserving its heritage for future generations.
On 8 July an installation will open at the School, providing visitors with a chance to go back in time by stepping into a replica room – the design is taken from a photograph taken inside the original building. Images showing the Hut in action will also be on display as well as audio and visual exhibits recounting local residents’ family memories of the First World War.
Architects’ drawing of London School of Hygiene & Tropical Medicine North Courtyard, 1924.
At the same time, the School’s Archives Service are mounting an exhibition called The Changing Face of Keppel Street, which uses material from the archive collections to explore the history of the Keppel Street area and the development of the School’s iconic art-deco style building.
Engaging with the community and bringing people together is an essential element of the project. ‘Digital Drama’ will work with volunteers to capture local stories, and 90 students from local schools will receive valuable research and media experience by developing blogs, animations and web pages. After the installation closes, photographs and recordings will be displayed and then kept at the London borough of Camden Local Studies and Archives Centre.
Stuart Hobley, Head of Heritage Lottery Fund London, said: “In the 400th anniversary of Shakespeare, this is an ideal moment to celebrate how Britain’s most famous playwright inspired troops during the First World War. Thanks to National Lottery players, the Resurrecting the Shakespeare Hut project will record and exhibit the hidden heritage of the forgotten YMCA building and share the stories of servicemen and women during the Great War.”
Photograph showing London School of Hygiene & Tropical Medicine exterior, c.1951.
The Installation and The Changing Face of Keppel Street exhibition runs from 8 July to 18 September. It will be open to the public from 9am to 5pm weekdays and for the Open House weekend – 17 and 18 September.
The School’s archives include documents, photographs, maps, publications and objects relating to tropical and infectious diseases and public health issues. The Archives also hold material on the history and development of the School since its foundation in 1899. Our collections date from the mid-nineteenth century to the present and have a global coverage.
Photograph of the London School of Hygiene & Tropical Medicine Library reading room in 1929.
NB. the LSHTM images in this feature are from a collection not yet included on the Archives Hub but the collection description is planned to be added in the future.
All images copyright the London School of Hygiene & Tropical Medicine and YMCA Archive, reproduced with the kind permission of the copyright holders.
29th June 2016 sees the 50th anniversary of the official launch of Barclaycard, the first all-purpose credit card in Europe.
Origins and Idea
The idea of Barclaycard is credited to general manager Derek Wilde, later a vice-chairman of Barclays, and James Dale, who became Barclaycard’s first departmental manager. Their idea was backed by Barclays’ chairman John Thomson, who recognised the need to ‘beat the others to it’. The immediate inspiration came from a visit to the United States in 1965 by Wilde, Dale and computer expert Alan Duncan, specifically to look at Bank of America’s BankAmericard.
James “Dickie” Dale
Barclays had, since the mid-1950s, begun to innovate and modernise in areas such as technology and advertising, for example ordering the first computer for branch accounting in 1959, and experimenting with cinema advertising. In 1967 Barclays would pioneer the world’s first external wall-mounted cash machines.
The card scheme was approved by the board without any market research or pilot, or adequate in-house computer system, and in the face of not inconsiderable internal and external suspicion, even hostility. It was recognised that profitability would be long-term, since the set-up costs were so high and credit controls strict.
Although the idea of a plastic card for making general purchases was novel in Britain, consumer credit had already secured a place in people’s lives. Working people had long bought essentials ‘on tick’ from their corner shop, and after World War Two the idea of hire purchase was developed into big business, becoming an integral part of the ‘affluent society’.
The most successful outlets in the early period, despite a very low profit margin, were petrol stations, whose proprietors envisaged improved security in reducing the use of cash, while Barclays saw advantage in roadside advertising.
Early advertising at a garage
Launch
‘The Barclaycard is the largest operation the Bank has ever mounted’, declared Barclays’ staff magazine.
On 10th January 1966 the scheme was announced to the public. The press release shows that Barclays carefully eschewed advertising it as a source of unsecured borrowing. Instead, Barclaycard was described as,
‘a logical extension of the existing commercial bank facilities provided by the Barclays Group. Its purpose is to reduce the use of cash in shopping and other transactions and the scheme is designed to appeal not only to those who must travel and spend a good deal of money in restaurants, but also to the everyday shopper throughout the country. For retail and service establishments it will provide a means of reducing or eliminating the book-keeping now needed to maintain customers’ credit accounts.’
Indeed, Thomson saw Barclaycard as, ‘…more of a development of existing retail banking than an innovation…’ As with automated accounting and cash machines, Barclaycard held a promise for the bank of reducing its labour costs, which, with the advent of relatively full employment and strong trade unions, were rising steadily.
Barclaycard Centre, Northampton
Barclays set itself the daunting task of recruiting 1 million cardholders and 30,000 outlets by the launch date. A derelict footwear factory in Northampton was converted as the operations centre, while £500,000 was spent on advertising and over 23 million forms were sent to prospective customers. Barclays adapted the computer programme used by BankAmericard. Distribution of the 1m cards involved extra Post Office and railway facilities.
Signing up merchant outlets was achieved by an organisational innovation. Dale recruited salesmen, largely selected from the Barclays staff on recommendation by inspection teams and branch managers, who were trained to call personally on prospective merchants. The idea of undertaking ‘selling’ was still anathema to the traditional British banker, but these recruits were often glad to break free of the confines of branch banking and enter the modern world of marketing. External training was also used by Barclays for the first time. In the words of one of the early salesmen,
‘It was all direct selling and it was cold selling in many ways. It was in actual fact, just walking along the streets and just looking at shops and saying, yes, the average sale in that shop is a certain amount, that’s a good average sale.’
Acceptance – the triumph of plastic
Most of the 1.25m unsolicited cards sent to potential users in 1966 were accepted, but some were either returned, destroyed or not used: in 2015 Group Archives was pleased to receive the timely donation from a customer, of her late father’s unused card, surviving in pristine condition from 1966!
Barclaycard steadily secured a place in retail culture. Its first operating profit was recorded in 1972, by which time there were 1.7m cardholders and 52,000 merchants. As another salesman recalled of this period:
‘Well, I would just go and say, have you ever thought of taking Barclaycard? It was such a strong product then that they either said yes or no. And if they said yes, you’d sign them up and if no, you’d go into the next shop. It was so easy to do then.’
The move towards a plastic credit society was cautious in the early years. When in November 1967 (following relaxation of the government’s credit squeeze), Barclaycard granted extended or revolving credit to holders, this was done on the understanding (with the Bank of England), that the card could not be used to acquire credit for more than 3 months, and that advertising would be suspended pro tem. This, it was recognised by Barclays at the time, was the only way that the card would ever make a profit. In effect card holders had a personal overdraft facility.
Confirmation that credit cards were here to stay came in 1972 with the launch of Barclaycard’s first major rival – Access – by Lloyds, NatWest and Midland.
Advertising
As in other areas, Barclaycard’s marketing was at the forefront of innovation for Barclays and British banking as a whole.
From the start, use was made of modern techniques, including direct mailings and colour magazine adverts. The initial recruitment of holders in 1966 was helped by a mass campaign, including the first direct mail shot by a British bank and a complete list of all the merchant outlets, believed to be one of the largest newspapers adverts ever published. High street campaigns were another radical departure for a Bank:
Barclaycard 1972 promotions.
‘….we would go to a town and set this promotion up with all the retailers. So we picked somewhere big like Brighton or Manchester or Liverpool and you always needed one or two big department stores as a sort of corner-stone, and we persuaded all these stores and shops to display Barclaycard material.’ Barclaycard ‘girls’, hired from an agency and dressed in a uniform to attract attention, would stop people on the street.
Flyer for Travelling Light, 1968
In 1968 an award-winning cinema film, Travelling Light, featured a young shopper with a card tucked into her bikini:
‘ One of my jobs was to make sure that the Barclaycard always showed correctly and so on, so I had the job of positioning it in her briefs to make sure it was all positioned correctly…. It had a very good message, because I think the message at the end was that all you need to go shopping is a Barclaycard.’
Later developments
Although space doesn’t permit an account of Barclaycard’s subsequent history here, it’s worth noting some of the landmarks, several of which have derived from advances in computer and mobile phone technology:
1972: first television advert (first for Barclays, too)
1973: 2 million card holders
1977: Barclaycard a founder of the VISA network
1977: Company Barclaycard
1982: first in series of Alan Whicker TV adverts
1985: 8 million card holders
1986: PDQ machines, the first electronic card payment terminals in the UK, introduced to replace manual imprinters
1988: Student Barclaycard
1990: first in series of Rowan Atkinson TV adverts
1990s: expansion into Europe
1995: Barclaycard Netlink, the UK’s first bank-related commercial internet service, which soon enabled card holders to pay their bills online
1997: introduction of microchips on cards to improve security
2001: initial sponsorship of FA Premiership
2002: 11 million cards
2004: acquisition of Juniper, enabling Barclaycard to expand in USA
2007: ‘contactless’ cards, first in the UK
2012: PayTag, enabling customers to pay using their mobile phone by sticking a Barclaycard PayTag to the back of their handset
2014: 30 million cards
Alan Whicker was the face of Barclaycard in the 1980s.
Records and research
‘Plastic money’, a phrase detected in a Barclays report from as early as 1967, has attracted attention from academic researchers in recent years, Barclaycard being cited as an example of technical and financial innovation, marketing success and market leadership.
Most of the documentation of Barclaycard is to be found with the Bank’s main record series. By establishing contacts with the marketing teams, a good representative selection of advertising material has also been captured, and this has been supplemented by donations from former staff members.
Research by Archives staff has established a good framework for the factual history of Barclaycard. For the story of the early years, Group Archives is able to supplement the written record by means of oral history interviews, a few excerpts from which have been quoted above.
In just over a decade from conception in 1965, Barclays successfully embedded the credit card in the retail economy of Britain, an essential payment medium that is taken for granted today.
Books from the TUC Library’s collection of publications from the Federation of Worker Writers and Community Publishers.
The Federation of Worker Writers and Community Publishers (FWWCP) was a network of community-based writing groups that stretched across the UK and, to a much lesser extent, Europe and the USA. Voluntary, community-run groups met to allow working class people to share and discuss their creative writing and facilitate community self-publication. It was the most significant working class writing/publication project of the 20th century, distributing over a million books between 1976-2007. It thrived during a period of significant social, economic and political change in the UK especially through the 1970s and 1980s, and represented a significant counter-cultural movement.
Many of the groups emerged out of local politics and campaigning, some such as Hackney’s Centerprise were a model of community cohesion, providing a bookshop, publisher, crèche, cafe and legal advice. Others still exist such as Brighton’s QueenSpark, Books, the UK’s longest running community publisher that started out of a grassroots campaign to establish a nursery school instead of a casino.
Books from the TUC Library’s collection of publications from the Federation of Worker Writers and Community Publishers.
Through the medium of poetry, prose, fiction, biography, autobiography and local history, they document the changing experience of working class people over the course of the second half of the twentieth century, and much like oral history, they contain testimony about cultural history and working lives. They also reveal an emerging identity politics focused on issues of local community, immigration, race/ethnicity, gender, mental health and sexuality, with groups setting up to discuss, publish and represent those identities.
Some of the groups were involved in the establishment of community bookshops, Bookplace, Newham Books, and Tower Hamlets Arts Project (known as THAP and Eastside Books). They were important in providing an outlet for FWWCP publications and frequently provided a meeting space for writers and adult literacy groups.
Books from the TUC Library’s collection of publications from the Federation of Worker Writers and Community Publishers.
The TUC Library started its collection of publications from the Federation of Worker Writers and Community Publishers in August 2014 with a major deposit from Nick Pollard, a lecturer at Sheffield Hallam University who had a long-running involvement in the Federation. This has been followed by a number of other smaller deposits over the last 18 months, from former writers, members and enthusiasts.
From London alone there are at least 11 groups represented, including: Black Ink, Peckham People’s History, Stepney Books, Basement Writers, Working Press, Tower Hamlets Arts Project, Hammersmith & Fulham Community, Newham Writers Workshop, London Voices, Age Exchange, Southwark Mind and Survivors. All published biographies, autobiographies, fiction, prose and poetry.
There are also audio recordings of meetings, performances and festivals, and some video footage of these events. The Collection contains publications from over 100 groups that were part of the Federation.
Groups were prolific in publishing prose and poetry.
Some of the FWWCP legacy still exists in the form of The FED, a much smaller network that follows many of the FWWCP principles but uses an online presence to keep members in touch. The FED includes writing workshops and groups across the country, mostly centered in London, and like its predecessor, continues to celebrate diversity. It is holding its annual writing festival on the 4th June 2016.
Although generally about working class experience, some groups were focused on gender, LGBT, BAME and mental health, and there is much testimony contained in this collection.
The TUC Library is working closely with the University in making the most of the FWWCP Collection, and we’ve provided inductions for students from social sciences and humanities generally, we’ve also provided workshops for those from creative writing students to theatre and performance students. Students from Syracuse University taking a Civic Writing course, helped create an index to the collection. The group taught by Jess Pauszek, through Syracuse’s London Campus, at Faraday House, spent three weeks in summer 2015 and will continue work in 2016.
Having carried out a series of consultative meetings with former members London Metropolitan University and the TUC Library will be applying for funds to carry out an oral history and digitisation project.
The Henry Moore Institute is a world-recognised centre for the study of sculpture in the heart of Leeds. An award-winning exhibitions venue, research centre, Library and Archive of Sculptors’ Papers, the Institute hosts a year-round programme of exhibitions, conferences and lectures, as well as developing research and publications, to expand the understanding and scholarship of historical and contemporary sculpture. The Institute is part of the Henry Moore Foundation, which was set up by Moore in 1977 to encourage appreciation of the visual arts, particularly sculpture.
Henry Moore (1898–1986) studied in Leeds at the city’s School of Art (now known as Leeds College of Art) in 1919 and was always grateful for the quality of art education he received. In 1982, through his Foundation, investment was made in Leeds City Art Gallery to establish the Henry Moore Centre for the Study of Sculpture (HMCSS) which built on the existing sculpture collection by diversifying and collecting works on paper and preparatory archive material.
In 1993 the Henry Moore Foundation funded refurbishment by architects Dixon Jones of the building next to the City Art Gallery to house the HMCSS, named the Henry Moore Institute, which offered new galleries, conference facilities and new accommodation for the Research Library and Archive of Sculptors’ Papers. Since 1993 the Henry Moore Institute Research Library and Archive have continued to play a crucial role in the work and endeavours of the Institute as intended by Moore, providing an important research facility to enable a greater understanding of the history and practice of sculpture. Leeds Museums and Galleries owns the Archive which the Institute houses and maintains, in addition to managing the closely related Leeds Sculpture Collections, in a unique partnership that has built one of the largest public collections of British sculpture.
The Henry Moore Institute, Leeds. Image courtesy of the Henry Moore Institute. Photo: David Cotton.
The Henry Moore Institute Archive is a specialist repository for papers relating to sculpture in Britain and has material dating from the eighteenth century to the present day with a particular emphasis on the period post-1880. The Archive now comprises over 300 individual collections which contain a diverse range of material including the personal papers of sculptors, correspondence, diaries, important collections of photographs, casting ledgers, sketchbooks and works on paper, press cuttings and printed ephemera. The collection is used extensively for research, display and features in many publications related to sculpture and other related disciplines.
The following collections from the Archive demonstrate the extent, variety and unique nature of the material held:
The Thornycroft Family Papers
The first major acquisition by the Henry Moore Institute Archive was the Thornycroft family papers in 1986. The papers are a rare survival which document the work of three generations of nineteenth and early twentieth-century artists. John Francis (1780–1861), was the first of the three generations, a portrait sculptor who exhibited extensively at the Royal Academy. John Francis taught his daughter, Mary (1809–95), who became a successful sculptor and produced many commissions for Queen Victoria. Her husband, Thomas Thornycroft (1815–85), was one of her father’s pupils, who specialised in public commemorative sculpture and completed many statues of Prince Albert.
Photograph of William Gladstone Memorial, William Hamo Thornycroft, London, 1905, from the Thornycroft Family Papers. Image courtesy of Leeds Museums and Galleries (Henry Moore Institute Archive).
Their youngest son, Sir William Hamo Thornycroft (1850–1925), also trained as a sculptor and his papers form the main part of the family’s collection. The papers of Hamo Thornycroft are important for their extensive scope and for the fact that they document the everyday activities of one of the foremost practitioners of the New Sculpture movement. The collection provides detailed documentation of all his major works, including ‘The Mower’ from 1884, a maquette for which is held in the Leeds Sculpture Collections. The collection is extremely comprehensive and consists of approximately 3,000 items of correspondence, 32 sketchbooks, 300 drawings which range from initial sketches and life drawings to presentation drawings and architectural plans for his work, as well as over 300 photographs of his work, studio and personal family photographs.
Papers of Betty Rea
The representation of female artists within the collection is a continuing area of development. Among current holdings is the archive of Betty Rea (1904–65). Rea was a sculptor who favoured realist sculpture in a period when abstract modernism held sway. Her sculptures tenderly celebrate quotidian life, whether by depicting teenage girls rocking with laughter or women completing household tasks, as can be seen in works such as ‘Silly Girls’ (1959) or ‘Folding a Carpet’ (1956). Betty Rea’s archive gives an interesting glimpse into both her artistic practice and the social and political world in which she lived. The contents of this collection can be considered as representative of the contents of many other collections. For example, the Betty Rea archive contains an album of photographs and over 200 loose photographs that record Rea and her sculptural process, a selection of correspondence that refer to the organisation of exhibitions, exhibition catalogues, private view cards, press cuttings largely relating to exhibitions Rea was involved in and one of her sketchbooks.
Material from the Henry Moore Institute Archive is frequently drawn upon and used to inform exhibitions held at the Institute as well as other institutions. For example, in 2005 the Institute curated the exhibition Jaki Irvine: Plans for Forgotten Works. This exhibition, held in Gallery 4, displayed a series of works created by Jaki Irvine as a result of her Fellowship at the Henry Moore Institute in 2004. During her Fellowship, Irvine engaged with some of the least expected areas of the Institute’s archive and material relating to the life and work of Betty Rea particularly captured her interest. Read more about this exhibition and Jaki Irvine’s Fellowship here: http://www.henry-moore.org/hmi/exhibitions/past-exhibitions/2005/jaki-irvine-plans-for-forgotten-works
Letter regarding the Huntingdon Anglo-Soviet Friendship Committee to Betty Rea, 27 February 1943, from the Papers of Betty Rea Image courtesy of the Estate of Betty Rea and Leeds Museums and Galleries (Henry Moore Institute Archive).
Stephen Cripps Archive
Installation view of the Henry Moore Institute exhibition Stephen Cripps: Pyrotechnic Sculptor, Sculpture Study Galleries, Leeds Art Gallery, 21 November 2013 – 16 February, 2014. Image courtesy of the Henry Moore Institute. Photo: Jerry Hardman-Jones.
More recent acquisitions include the archive of British sculptor and performance artist Stephen Cripps (1952-82) which was acquired in 2013, and provides a fascinating insight into Cripps’ artistic practice. His work was experimental and often included found objects, sound recordings from the urban environment around him and explosives. In 2013 the Institute curated the exhibition Stephen Cripps: Pyrotechnic Sculptor which was held in the Sculpture Studies Galleries of Leeds Art Gallery.
This exhibition celebrated the acquisition of the Cripps’ archive and utilised items from the collection, such as his drawings and photographs of his performances, to explore the originality and experimental nature of Cripps’ sculptural work.
Untitled drawing by Stephen Cripps, n.d., Stephen Cripps Archive. Image courtesy of Leeds Museums and Galleries (Henry Moore Institute Archive).
The Archive is open to all who wish to consult the collection. Please contact Claire Mayoh, Archivist, for further information about the collection or to arrange an appointment to visit, (claire@henry-moore.org).
Katie Gilliland Library, Archive and Collections Trainee Henry Moore Institute
APAC, the Association of performing arts collections in the UK and Ireland: A peer network championing the documentation of performing arts material and its access by everyone.
Samuel Alex Walker, Sepia photograph of Connie Gilchrist as Abdallah in The Forty Thieves, at the Gaiety Theatre, 1880. [From the Guy Little Collection, V&A, Museum Number S.135:398-2007.]Performing arts are all around us and come in many different shapes and sizes: drama, opera, circus, local amateur theatre groups, dance, carnivals, pantomime, music festivals and more. Although performances are increasingly recorded live and high profile productions screened to your local cinemas; capturing the process of putting on a show, the collaborations between a creative team and cast, followed by the public reception present quite a few challenges to collection managers. How to capture the depth and breadth of performing arts at local and national level? How to make performing arts information and material easily accessible to the diverse users ranging from academics, theatre enthusiasts, family historians, school children and the creative industry itself?
Detail from page 29 of a theatrical scrapbook compiled by Jonathan Cleveland Milbourne, showing costumes from “Robinson Crusoe” performed at the Avenue Theatre, 26 December 1886. Part of the Theatre & Performance Archives, Special Collections & Archives, University of Kent.
The Association of Performing Arts Collections, APAC, was founded in 1979 by a number of librarians, archivists and museums curators, as the then Theatre Information Group. Its mission is to champion best practice in documenting the performing arts and making it accessible to their users. The peer network of information professionals and interested individuals has grown to almost 100 members and includes institutions responsible for most of the UK’s performing arts heritage: public museums, libraries, and archives; archives of theatres and companies; college and university archives and libraries. APAC is the UK and Ireland affiliate of SIBMAS, the international organisation of libraries, museums, archives and documentation centres of performing arts. The national and international network of collection managers provides an excellent forum for information exchange, to discuss issues and explore solutions.
The APAC Executive Committee arranges regular meetings, alongside visits to collections and performing arts venues in addition to conferences and study days concentrating on issues of relevance to our holdings, such as copyright, digital preservation, audio-visual materials, costume, photography, digitisation, exhibitions, etc. These events are aimed at updating and extending members’ knowledge and skills, but also to benefit from each other’s trials and errors and encourage collaborative projects. In addition APAC has a number of working groups bringing together APAC members discussing specific challenges in their day-to-day work and seeking solutions, which are shared with the wider membership. Current working groups concentrate on digital preservation and authority datasets for performing arts.
One major challenge faced by most organisations holding performing arts materials is the fact, that international documentation standards for archive, library and museum collections do not adequately allow the capture of production/event information, which includes details of the work, its venue, production run and creative and cast involved. Many theatre and performance venues managing their own collections have implemented solutions to document their performance history and then to link these up with relevant material held within their organisation. Excellent examples are the National Theatre Archive, the Royal Opera House Collections, the Royal Albert Hall or the archives of the Royal Shakespeare Company held by the Shakespeare Birthplace Trust. However, much related material is held by other organisations across the country, which tend to not have equivalent production databases due to lack of resources, both time and money. Also organisations, such as museums, local libraries or archives do not want to duplicate the effort of re-entering performance data in their own systems and then just link up their own material.
‘Phyllis Bedells’ c. 1911. Rotary Photographic Series, Royal Academy of Dance.
The technical developments and online opportunities over the last decade led to APAC’s main vision of establishing an www.IMDB.com style solution of making a single database freely available online, where past and current productions across the UK and Ireland can be recorded. It is not only the ambition to facilitate a single point of access to find out about production, cast and venue information, but also to make the link to actual holdings held by organisations across the two countries. This ambitious project will hopefully see the closing of the major information gap, but should also result in a new and innovative way of making material discoverable using technology readily available. In tandem with technical developments, the APAC Authority Working Group, comprising of information professionals across the sector plans to draw up guidelines on how to use this resource alongside your in-house archive, library or museum system.
To find out more about APAC, please check out the APAC website, which holds information about APAC members and other resources, which may be of relevance to other organisations: www.performingartscollections.org.uk.
And now it is time to meet some of the APAC members holding archival collections and making these available via the Archives Hub:
Central Saint Martin’s Museum & Study Collection
The Central Saint Martin’s Museum & Study Collection has been collecting work by students and staff for more than a century and for the last 20 years has bought work from degree shows. There has been a theatre design department (now called Design for Performance) for much of that time and the collection now includes dress research, costume designs, theatre models and photographs from that department. Drama Centre London is also part of Central Saint Martin’s, and the museum has some of their material.
The National Theatre Archive documents, protects and makes accessible material related to the history of the theatre. The NT Archive collects around productions as well as the administrative and strategic history of the institution. Its external collections focus on the early days of the National Theatre and on staff members, who were integral to its development.
A couple of the external collections are on the Hub with more to come. The Shakespeare Memorial National Theatre Collection (https://archiveshub.jisc.ac.uk/data/gb2080-smnt) charts the movement to found the National Theatre and the collection of Catherine Fleming (https://archiveshub.jisc.ac.uk/data/gb2080-cf), a vocal coach, who worked with the National Theatre Company when it was housed at the Old Vic.
The Rambert Archive documents the development of dance in Britain through the heritage of Britain’s first established dance company, Rambert. The collections include the Company collection, dating from the first performance of a ballet choreographed by an English person. The collections also include personal archives created by our founder, Dame Marie Rambert DBE, who played a role in the birth of modernism in ballet and music, as well in the early days of the Dalcroze Eurythmics movement. Other former alumni have contributed collections, including those of the choreographer Walter Gore, whose ballet company pioneered new works in the 1950s; the Ballet Workshop who hosted new collaborations between choreographers, designers and composers including some of the earliest black British ballets; the first tours to China and to Australian and New Zealand by any British dance company, and extensive material about the popularisation of dance as an art-form during the Second World War.
Photo by GBL Wilson: Sadler’s Wells Ballet’s 25th Birthday Gala at the Royal Opera House, Covent Garden. Margot Fonteyn and Michael Somes (centre) in Frederick Ashton’s Birthday Offering. Royal Academy of Dance.
The Royal Academy of Dance was founded in 1920, a time when there was a heightened interest in the establishment of a British Ballet tradition. As a result, the RAD’s archive collections contain a variety of materials that relate to this period including programmes, photographs, costume designs, papers and correspondence. These are housed alongside the significant personal collections of RAD founders Dame Adeline Genée (https://archiveshub.jisc.ac.uk/data/gb3370-rad/ag ), Phyllis Bedells (https://archiveshub.jisc.ac.uk/data/gb3370-rad/pb ) and Philip Richardson (https://archiveshub.jisc.ac.uk/data/gb3370-rad/pjsr ), and the photographic archive of GBL Wilson (https://archiveshub.jisc.ac.uk/data/gb3370-rad-gblw ) documents the subsequent heyday of British Ballet from the 1940s through to the 1980s.
The Theatres Trust’s collections focus on theatre buildings, their architecture, design, management and history. Our institutional archive charts the development of, and The Theatres Trust’s relationship with theatre buildings in the United Kingdom and primarily contains correspondence, building descriptions, photographs, press cuttings, architectural plans and planning applications. Our donated special collections consist primarily of theatre photographs, postcards, press cuttings and scrapbooks. Other resources provided by The Theatres Trust include an online Theatres Database and Image Library.
Participants dancing outside in a movement choir at the Moreton Hall Modern Dance Holiday Course, Moreton Hall, Oswestry, 1942. Featuring Rudolf Laban’s Polovstian Dances from Prince Igor . Photographer unknown. Held in the Lorna Wilson Collection, Laban Library and Archive, Trinity Laban Conservatoire of Music and Dance. Ref: D21/2007/74/10/2.
Trinity Laban Conservatoire of Music and Dance is the UK’s only conservatoire of music and contemporary dance. Leaders in music and contemporary dance education, the Conservatoire also provides exciting opportunities for the public to encounter dance and music, and access arts health programmes, all housed in landmark buildings.
The Laban Archive, within the Faculty of Dance at Trinity Laban, focuses on the history and development of Rudolf Laban the man, Laban the institution and on the field of contemporary dance from its roots in European dance theatre practice in the early twentieth century, via its American influences in the 1960s and 1970s to its current contemporary artists. Whilst tying in with the dance faculty’s focus on contemporary dance, the contents reflect the wide influences and associations of the dance form and document both the creative processes and performances of Laban-influenced choreographers and dance practitioners.
Collections include the Laban Collection, comprising papers, notation scores, photographs and other documents of Rudolf Laban and his associates for the period 1918-2001, the Sylvia Bodmer Collection, comprising notebooks, papers, photographs and correspondence of a distinguished exponent of Rudolf Laban’s movement ideas, the Peter Brinson Collection, being the professional and personal papers of a key figure in the expansion of dance education in the UK, and the Peter Williams Collection which includes ca. 50,000 photographs of dance companies from around the world for the period 1950-1980.
University of Kent, Special Collections & Archives
Lithograph illustrating the front page of the sheet music for “After Dark Galop” composed by Charles Coote and designed by Alfred Concanen. Part of the Calthrop Boucicault Collection, Special Collections & Archives, University of Kent.
Special Collections & Archives at the University of Kent includes a significant Theatre and Performance Archive. With a focus on theatre history, the Collections are particularly rich in Victorian and Edwardian Theatre and contain playbills, programmes, scripts, photographs, publicity and administrative material. There is also a collection of twentieth and twenty-first century programmes and theatrical ephemera.
As well as the unique Britannia Theatre prompt scripts, heavily annotated for use by Britannia’s Stage manager, Frederick Wilton (Pettingell Collection), Kent holds the archive of the Melville Theatrical dynasty, which produced significant popular productions from the late nineteenth into the twentieth centuries. Other significant holdings include two collections related to Dion Boucicault, with materials such as legal papers, scripts, research material and printed performance ephemera from the Victorian period up to the late twentieth century.
In addition, the British Stand-Up Comedy Archive has recently been founded at the University. The British Stand-Up Comedy Archive intends to celebrate, preserve, and provide access to the archives and records of British stand-up comedy and comedians.
Costume design by Wilhelm (1858-1925) for ‘Princess Ida’ in Act II of the original production of Princess Ida, at the Savoy Theatre, 1884. [From the D’Oyly Carte Archive, V&A, Museum Number S.3006-2015.]The V&A holds the United Kingdom’s national collection of the performing arts and is one of the largest of its kind in the world. In 1924, the private collection of Gabrielle Enthoven transferred to the Victoria and Albert Museum and in keeping with her mission to document and index every performance, more than 750,000 playbills and programmes of London and regional productions from the 18th century to the present day now form the centre of the collection. In addition our relevant library and museum object collections, the V&A has more than 450 archive collections documenting the many aspects of performing arts including:
– Theatre company archives, including English Stage Company at the Royal Court, Young Vic, Cheek by Jowl, Talawa, Tricycle Theatre, Prospect Theatre Company;
– Personal papers, including Sir Michael Redgrave, Peter Brook, Vivien Leigh, Paul Scofield, Ivor Novello;
– Designer and architect collections, incl. Lez Brotherston, Oliver Messel, Frank Matcham Company; and the
– Arts Council of Great Britain Archive.
Search logs can give us an insight into how people really search. Our current system provides ‘search logs’ that show the numbers based on the different search criteria and faceting that the Hub offers, including combined searches. We can use these to help us understand how our users search and to give us pointers to improve our interface.
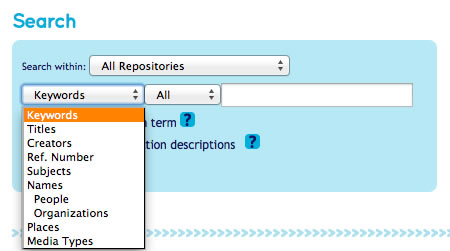
The Archives Hub has a ‘default search’ on the homepage and on the main search page, so that the user can simply type a search into the box provided. This is described as a keyword search, as the user is entering their own significant search terms and the results returned include any archival description where the term(s) are used.
The researcher can also choose to narrow down their search by type. The figure below shows the main types the Archives Hub currently has. Within these types we also have boolean type options (all, exact, phrase), but we have not analysed these at this point other than for the main keyword search.
Archives Hub search box showing the types of searches available
There are caveats to this analysis.
1. Result will include spiders and spam
With our search logs, excluding bots is not straightforward, something which I refer to in a previous post: Archives Logs and Google Analytics. We are shortly to migrate to an entirely new system, so for this analysis we decided to accept that the results may be slightly skewed by these types of searches. And, of course, these crawlers often perform a genuine service, exposing archive descriptions through different search engines and other systems.
2. There are a small number of unaccounted for searches
Unidentified searches only account for 0.5% of the total, and we could investigate the origins of these searches, but we felt the time it would take was not worth it at this point in time.
3. Figures will include searches from the browse list.
These figures include searches actioned by clicking on a browse list, e.g. a list of subjects or a list of creators.
4. Creator, Subject and Repository include faceted searching
The Archives Hub currently has faceted searching for these entities, so when a user clicks to filter down by a specific subject, that counts as a subject search.
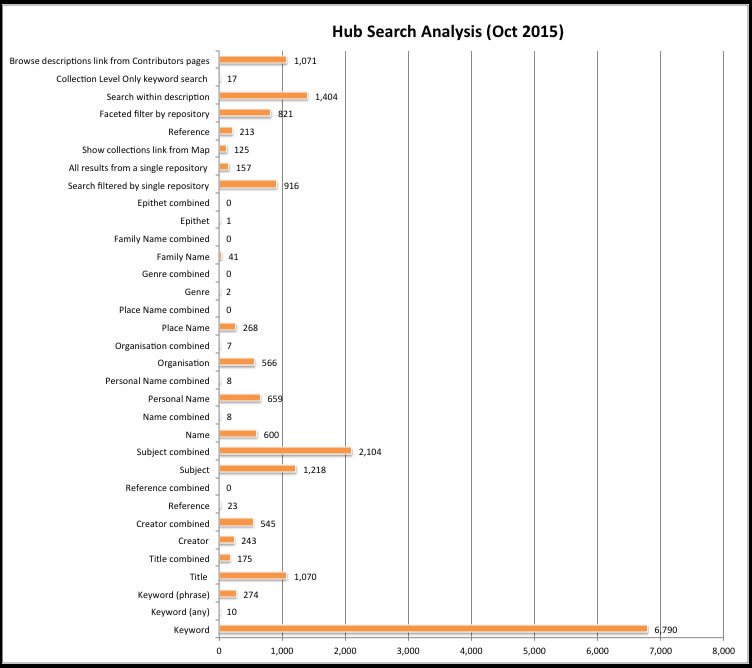
Results for One Month (October 2015)
For October 2015 the total searches are 19,415. The keyword search dominates, with a smaller use of the ‘any’ and ‘phrase’ options within the keyword search. This is no surprise, but this ‘default search’ still forms only 36% of the whole, which does not necessarily support the idea that researchers always want a ‘google type’ search box.
We did not analyse these additional filters (‘any/phrase/exact’) for all of the searches, but looking at them for ‘keyword’ gives a general sense that they are useful, but not highly used.
A clear second is search by subject, with 17% of the total. The subject search was most commonly combined with other searches, such as a keyword and further subject search. Interestingly, subject is the only search where a combined subject + other search(es) is higher than a single subject search. If we look at the results over a year, the combined subject search is by far the highest number for the whole year, in fact it is over 50% of the total searches. This strongly suggests that bots are commonly responsible for combined subject searches.
These searches are often very long and complex, as can be seen from the search logs:
It is most likely that the bots are not nefarious; they may be search engine bots, or they may be indexing for the purposes of information services of some kind, such as bibliographic services, but they do make attempts to assess the value of the various searches on the Hub very difficult.
Of the remaining search categories available from the main search page, it is no surprise that ‘title’ is used a fair bit, at 6.5%, and then after that creator, name, and organisation and personal name. These are all fairly even. For October 2015 they are around 3% of the total each, and it seems to be similar for other months.
The repository filter is popular. Researchers can select a single repository to find all of their descriptions (157), select a single repository and also search terms (916), and also search for all the descriptions from a single repository from our map of contributors (125). This is a total of 1,198, which is 6.1% of the total. If we also add the faceted filter by repository, after a search has been carried out, the total is 2,019, and the percentage is 10.4%. Looking at the whole year, the various options to select repository become an even bigger percentage of the total, in particular the faceted filter by repository. This suggests that improvements to the ability to select repositories, for example, by allowing researchers to select more than one repository, or maybe type of repository, would be useful.
Google Map on the Hub showing the link to search by contributor
We have a search within multi-level descriptions, introduced a few years ago, and that clearly does get a reasonable amount of use, with 1,404 uses in this particular month, or 7.2% of the total. This is particularly striking as this is only available within multi-level descriptions. It is no surprise that this is valuable for lengthy descriptions that may span many pages.
The searches that get minimal use are identifier, genre, family name and epithet. This is hardly surprising, and illustrates nicely some of the issues around how to measure the value of something like this.
Identifier enables users to search by the archival reference. This may not seem all that useful, but it tends to be popular with archivists, who use the Hub as an administrative tool. However, the current Archives Hub reference search is poor, and the results are often confusing. It seems likely that our contributors would use this search more if the results were more appropriate. We believe it can fulfill this administrative function well if we adjust the search to give better quality results; it is never likely to be a highly popular search option for researchers as it requires knowledge of the reference numbers of particular descriptions.
Epithet is tucked away in the browse list, so a ‘search’ will only happen if someone browses by epithet and then clicks on a search result. Would it be more highly used if we had a ‘search by occupation or activity’? There seems little doubt of this. It is certainly worth considering making this a more prominent search option, or at least getting more user feedback about whether they would use a search like this. However, its efficacy may be compromised by the extremely permissive nature of epithet for archival descriptions – the information is not at all rigorous or consistent.
Family name is not provided as a main search option, and is only available by browsing for a family name and clicking on a result, as with epithet. The main ‘name’ search option enables users to search by family name. We did find the family name search was much higher for the whole year, maybe an indication of use by family historians and of the importance of family estate records.
Genre is in the main list of search options, but we have very few descriptions that provide the form or medium of the archive. However, users are not likely to know this, and so the low use may also be down to our use of ‘Media type’, which may not be clear, and a lack of clarity about what sort of media types people can search for. There is also, of course, the option that people don’t want to search on this facet. However, looking at the annual search figures, we have 1,204 searches by media type, which is much more significant, and maybe could be built up if we had something like radio buttons for ‘photographs’, ‘manuscripts’, ‘audio’ that were more inviting to users. But, with a lack of categorisation by genre within the descriptions that we have, a search on genre will mean that users filter out a substantial amount of relevant material. A collection of photographs may not be catalogued by genre at all, and so the user would only get ‘photographs’ through a keyword search.
Place name is an interesting area. We have always believed that users would find an effective ‘search by place’ useful. Our place search is in the main search options, but most archivists do not index their descriptions by place and because of this it does not seem appropriate to promote a place name search. We would be very keen to find ways to analyse our descriptions and consider whether place names could be added as index terms, but unless this happens, place name is rather like media type – if we promote it as a means to find descriptions on the Archives Hub, then a hit list would exclude all of those descriptions that do not include place names.
This is one of the most difficult areas for a service like the Archives Hub. We want to provide search options that meet our users’ needs, but we are aware of the varied nature of the data. If a researcher is interested in ‘Bath’ then they can search for it as a keyword, but they will get all references to bath, which is not at all the same as archives that are significantly about Bath in Gloucestershire. But if they search for place name: bath, then they exclude any descriptions that are significantly about Bath, but not indexed by place. In addition, words like this, that have different meanings, can confuse the user in terms of the relevance of the results because ‘bath’ is less likely to appear in the title. It may simply be that somewhere in the description, there is a reference to a Dr Bath, for example.
This is one reason why we feel that encouraging the use of faceted search will be better for our users. A more simple initial search is likely to give plenty of results, and then the user can go from there to filter by various criteria.
It is worth mentioning ‘date’ search. We did have this at one point, but it did not give good results. This is partly due to many units of description not including normalised dates. But the feedback that we have received suggests that a date search would be popular, which is not surprising for an archives service. We are planning to provide a filter by date, as well as the ordering by date that we currently have.
Finally, I was particularly interested to see how popular our ‘search collection level only’ is. This enables users to only see ‘top level’ results, rather than all of the series and items as well. As it is a constant challenge to present hierarchical descriptions effectively, this would seem to be one means to simplify things. However, for October 2015 we had 17 uses of this function, and for the whole year only 148. This is almost negligible. It is curious that so few users chose to use this. Is it an indication that they don’t find it useful, or that they didn’t know what it means? We plan to have this as a faceted option in the future, and it will be interesting to see if that makes it more popular or not.
We are considering whether we should run this exercise using some sort of filtering to check for search engines, dubious IP addresses, spammers, etc., and therefore get a more accurate result in terms of human users. We would be very interested to hear from anyone who has undertaken this kind of exercise.
Isambard Kingdom Brunel. Image from The Big Ship, Brunel’s Great Eastern – a pictorial history by Patrick Beaver
In the early 1980s two substantial bequests, the Clinker and Garnett collections, were left to Brunel University Library. Charles Clinker and David Garnett were two railway historians, and their collections went on to form the basis of what is now known collectively as the Transport History Collection. Over the years their bequests were joined by others, so the collection now includes books, railway maps, Bradshaw guides, timetables, journals and photographs. The maps include early Airey and Railway Clearing House maps, as well as Ordnance Survey maps and railway junction diagrams. Archival material includes Charles Clinker’s extensive notes and correspondence concerning his Register of closed stations and papers relating to his revision of MacDermot’s History of the Great Western Railway. We still collect relevant railway material, and the collection is particularly strong on the history of the Great Western Railway.
Chalk, Channel Tunnel Archive
To complement the Transport History collection, the papers of the Channel Tunnel Company and the Channel Tunnel Association were acquired in 2003. These offer a fascinating insight into the history and politics of tunneling under the English Channel from the early nineteenth century to the opening of the Channel Tunnel as we know it today. This resource includes a mixture of archival and printed material, including letters, photographs, objects (including a lump of chalk!), books, reports, advertisements, maps, conference proceedings and tunnel and bridge proposals.
Also in the 1980s here at Brunel University, John Burnett, David Vincent and David Mayall were compiling their annotated bibliography, The autobiography of the working class (Harvest Press, 1984-1989). The bibliography includes descriptions and locations of unpublished manuscripts produced by working class people who lived in England, Scotland or Wales between 1790 and 1945. Many of these autobiographies are now kept in Special Collections and are an extremely popular resource, amongst History, English and Creative Writing students.
Letter, Blount archive
Many people are surprised to learn that we have very few collections relating to Isambard Kingdom Brunel himself. Those we do have include a collection of photographs relating to the publication of The Big Ship: Brunel’s Great Eastern – a pictorial history by Patrick Beaver, and the small Gilbert Blount archive. Blount was an English Catholic architect born in 1819 who received his earliest training as a civil engineer under Isambard Kingdom Brunel, for whom he worked as a superintendent of the Thames Tunnel works. The collection here covers his early career, including correspondence with the Brunel family. It was given to the University Library by Michael May, Blount’s grandson, in 1976 and so is one of our earliest acquisitions.
Some of our other collections were later acquisitions, and we have been developing a theme around equality and advocacy issues. These collections include the Dennis Brutus Archive. Dennis Brutus was a South African poet and human rights activist who spearheaded a successful campaign to ban apartheid South Africa from international sport competitions, including the Olympic games. Related collections include Celia Brackenridge’s research archive. Celia is a recently retired Brunel academic who donated her collection to Special Collections in order to preserve original sources and information about the development of child abuse and child protection research, advocacy and policy in the UK and overseas from the 1980s to 2000s.
We also look after a couple of collections on behalf of external organisations. These are the South Asian Diaspora Arts Archive, a wide-ranging group of small collections of South Asian literature, art, theatre, dance and music by British based artists and organisations. The archive covers five main areas: literature, visual arts, theatre, dance and music, dating between approximately 1947 and the present day. The Operational Research Society houses their library at Brunel. Operational Research looks at organisations’ operations and uses mathematical or computer models, or other analytical approaches, to find better ways of doing these operations. Their library includes over 1500 books on topics including operational research, statistics, management science, market research, logistics, industrial engineering and management accounting.
New reading room
In 2015 Special Collections saw a big change as we moved into new reading room and storage facilities. This has improved access to our collections, as we now have a dedicated reading room space which can also be used for workshops by both internal and external groups, as well as improving and increasing the amount of storage we have.
You can find out more about our collections on our webpages, on our blog and Twitter feed (@BrunelSpecColl).
Katie Flanagan Special Collections Librarian
Related:
Browse the collections of Brunel University London on the Archives Hub.
All images copyright Brunel University London and reproduced with the kind permission of the copyright holder.
It is vital to have a sense of the value of your service, and if you run a website, particularly a discovery website, you want to be sure that people are using it effectively. This is crucial for an online service like the Archives Hub, but it is important for all of us, as we invest time and effort in putting things online and we are aware of the potential the Web gives us for opening up our collections.
But measuring use of a website is no simple thing. You may hear people blithely talking about the number of ‘hits’ their website gets, but what does this really mean?
I wanted to share a few things that we’ve been doing to try to make better sense of our stats, and to understand more about the pitfalls of website use figures. There is still plenty we can do, and more familiarity with the tools at our disposal may yield other options to help us, but we do now have a better understanding of the dangers of taking stats at face value.
Logs
We are all likely to have usage logs of some kind if we have a website, even if it is just the basic apache web logs. These are part of what the apache web server offers. The format of these can be configured to suit, although I suspect many of us don’t look into this in too much detail. You may also have other logs – your system may generate these. Our current system provides a few different logs files, where we can find out a bit more about use.
Apache access logs typically contain: the IP address of the requesting machine, the date of the access, the http method (usually ‘get’ or ‘post’), the requested resource (the URL of the page, image, pdf etc.), the size of what is returned, the referring site, if available, and the user agent. The last of these will sometimes provide information on the browser used to make the request, although this will often not be the case.
So, with this you can find out some information about the source of the request from the IP addresses and what is being requested (URL of resource).
Other logs such as our current system’s search logs may provide further information, often including more about the nature of the query and maybe the number of hits and the response time.
Google Analytics
Increasingly, we are turning to Google Analytics (GA) as a convenient method of collecting stats, and providing nice charts to show use of the service. Google Analytics requires you to add some specific code to the pages that you want tracked. GA provides for lots of customisation, but out of the box it does a pretty good job of providing information on pages accessed, number of accesses, routes, bounce rate, user agents (browsers), and so on.
Processing your stats
If you do choose to use your own logs and process your stats, then you have some decisions to make about how you are going to do this. One of the first things that I learnt when doing this is that ‘hits’ is a very misleading term. If you hear someone promoting their site on the basis of the number of hits, then beware. Hits actually refers to the number of files downloaded on your site. One page may include several photos, buttons and other graphics, and these all count as hits. So one page accessed may represent many hits. Therefore hits is largely meaningless as a measure of use. Page views is a more helpful term, as it means one page accessed counts as ‘one’.
So, if you are going to count page views, do you then simply use the numbers the logs give you?
Robots
One of the most difficult problems with using logs is that they count bots and crawlers. These may access your site hundreds or thousands of times in a month. They are performing a useful role, crawling and gathering information that usually has a genuine use, but they inflate your page views, sometimes enormously. So, if someone tells you they have 10,000 page views a month, does this count all of the bots that access the pages? Should it? It may be that human use of the site is more like 2,000 page views per month.
Identifying and excluding robot accesses accurately and consistently throughout every reporting period is a frustrating and resource intensive task. Some of us may be lucky enough to have the expertise and resources to exclude robots as part of an automated process (more on that with GA), but for many of us, it is a process that requires regular review. If you see an IP address that has accessed thousands of pages, then you may be suspicious. Investigation may prove that it is a robot or crawler, or just that it is under suspicion. We recently investigated one particular IP address that gave high numbers of accesses. We used the ‘Honey Pot‘ service to check it out. The service reported:
“This IP address has been seen by at least one Honey Pot. However, none of its visits have resulted in any bad events yet. It’s possible that this IP is just a harmless web spider or Internet user.”
The language used here shows that even a major initiative to identify dodgy IP addresses can find it hard to assess each one as they come and go with alarming speed. This project asks for community feedback in order to continually update the knowledge base.
We also checked out another individual IP address that showed thousands of accesses:
“The Project Honey Pot system has detected behavior from the IP address consistent with that of a rule breaker. Below we’ve reported some other data associated with this IP. This interrelated data helps map spammers’ networks and aids in law enforcement efforts.”
We found that this IP address is associated with a crawler called ‘megaindex.com/crawler’. We could choose to exclude this crawler in future. The trouble is that this is one of many. Very many. If you get one IP address that shows a huge number of accesses, then you might think it’s a bot, and worth investigating. But we’ve found bots that access our site 20 or 30 times a month. How do you identify these? The trouble is that bots change constantly with new ones appearing every day, and these may not be listed by services such as Honeypot. We had one example of a bot that accessed the Hub 49,459 times in one month, and zero times the next month.We looked at our stats for one month and found three bots that we had not yet identified – MegaIndex, XoviBot and DotBot. The figures for these bots added up to about 120,000 page views just for one month.
404: Page Not Found
The standard web server http response if a page does not exist is the infamous ‘404‘. Most websites will typically generate a “404 Not Found” web page. Should these requests be taken out of your processed stats? It can be argued that these are genuine requests in terms of service use, as they do show activity and user intent, even if they do not result in a content page.
500: Server Error
The standard http response if there’s been a system problem of some kind is the ‘500’ Sever Error . As with the ‘404’ page, this may be genuine human activity, even if it does not lead to the user finding a content page. Should these requests be removed before you present your stats?
Other formats
You may also have text pages (.txt), XML pages (.xml) and PDFs (.pdf). Should these be included or not? If they show high use, is that a sign of robots? It may be that people genuinely want to access them.
Google Analytics and Bots
As far as we can tell, GA appears to do a good job of not including bots by default, presumably because many bots do not run the GA tracking code that creates the GA page request log. We haven’t proved this, but our investigations do seem to bear this out. Therefore, you are likely to find that your logs show higher page accesses than your GA stats. And as a bot can really pummel your site, the differences can be huge. Interestingly, GA also now provides the option to enable bot filtering, but we haven’t found much evidence of GA logging our bot accesses.
But can GA be relied upon? We had a look in detail at some of the logs accesses and compared them with GA. We found one IP address that showed high use but appeared to be genuine, and the user agents looked like they represented real human use. The pattern of searching and pages accessed also looked convincing. From this IP address we found one example of an Archives Hub description page with two accesses in the log: gb015-williamwagstaffe. The accesses appeared to come from standard browsers (the Chrome browser). We looked at several other pages accessed from this IP address. There was no evidence to suggest these accesses are bots or not genuine, but they are not in the GA accesses.
Why might GA exclude some accesses? There could be several reasons:
GA uses javascript tracking code, and it may not know about the activity because the javascript doesn’t run when the page is requested even though it appears to be a legitimate browser according to the user agent log
The requester may be using ad-blocking, which can also block calls to GA
It may be a tracking call back failure to GA due to network issues
It may be that GA purposely excludes an IP address because it is believed to be a bot
It may not be a genuine browser, i.e. a bot, script or some other requesting agent that doesn’t run the GA tracking code
Dynamic single page applications
Modern systems increasingly use html5 and Ajax to load content dynamically. Whereas traditional systems load the analytics tracker on each page load, these ‘single page applications require a different approach in order to track activity. This requires using the new ‘Google Universal Analytics’ and doing a bit of technical work. It is not necessarily something we all have the resource and expertise to do. But it may mean that your page views appear to go down.
Conclusions
Web statistics are not straightforward. Google Analytics may be extremely useful, and is likely to be reasonably accurate, but it is worth understanding the pitfalls of relying on it completely. Our GA stats fell off a rather steep cliff a few years ago, and eventually we realised that the .xml and .txt pages had started being excluded. This was not something we had control over, and that is one of the downsides of using third party software – you don’t know exactly how they do what they do and you don’t have complete control.
A recent study of How Many Users Block Google Analytics by Jason Packer of Quantable suggests that GA may often be blocked at the same time as ads, using the one of the increasing number of ad blocking tools, and the effect could be significant. He ran a fairly small survey of about 2,400 users of a fairly niche site, but found that 8.4% blocked GA, which is a substantial percentage.
Remember that statistics for ‘hits’ or ‘page views’ don’t mean so much by themselves – you need to understand exactly what is being measured. Are bots included? Are 404s included?
Stats are increasingly being used to show value, but we do this at our peril. Whilst they are important, they are open to interpretation and there are many variables that mean comparing different sites through their access stats is going to be problematic.
Image of National Association for spinsters’ pensions London rally from the papers of Florence White, part of History to Herstory. Image ref 78D86/4/3, courtesy of West Yorkshire Archive Service, Bradford
This has taken a bit more work than we originally anticipated, as we’ve been stretching EAD and the current Hub structure to allow for descriptions of collections that don’t fit with what’s expected of a ‘normal’ archival description. For instance, we require descriptions on the Hub to have (at least one) named originator, but this doesn’t apply to Themed Collections, where the material might have hundreds of different originators, or none at all – finding originators for fossils would be a very interesting challenge! This means that we’ve had to make changes to how we validate the Hub’s EAD requirements, as well as how these descriptions display on the Hub.
This work started out in partnership with Jisc Content, so the Themed Collections currently on the Hub are taken from the descriptions of Jisc Content collections. But we don’t want to stop there, and are inviting submissions of Themed Collections. Adding your collections to the Archives Hub gives you exposure to a worldwide audience of thousands of searchers every month. If you have a project or collection that you think would make a good Themed Collection, please complete the form to submit it to the Hub, or contact us.
Founded in 1981, Black Cultural Archives’ mission is to collect, preserve and celebrate the heritage and history of Black people in Britain.
PHOTOS/27 Photograph and Printed Document, originally purported to be of Francis Barber. Photographic reproduction of artwork, originally purported to be a portrait of Francis Barber, companion to Dr Samuel Johnson, in the manner of Sir Joshua Reynolds. The original is held in the Tate gallery and a copy is displayed at Dr Johnson House. Original date unknown.
Black Cultural Archives have opened the UK’s first dedicated Black heritage centre in Brixton, London, in July 2014. Our unparalleled and growing archive collection offers insight into the history of people of African and Caribbean descent in Britain. The bulk of the collection is drawn from the twentieth century to the present day, while some materials date as far back as the second century. The collection includes personal papers, organisational records, rare books, ephemera, photographs, and a small object collection.
Our work at Black Cultural Archives recognises the importance of untold stories and providing a platform to encourage enquiry and dialogue. We place people and their historical accounts at the heart of everything we do.
The current exhibition at Black Cultural Archives is Black Georgians: The Shock of the Familiar. Imagining the Georgian period awakens images from Jane Austen’s parlour to Hogarth’s Gin Lane. Black Cultural Archives’ new exhibition takes you on a journey a long way from these quintessential English images. This new exhibition interrogates the seams between the all-too-often prettified costume period dramas and the very different existence of hardship, grime, disease, and violence that was the reality for many.
PHOTOS/73 Photograph of a portrait of Olaudah Equiano. Black and white photographic copy of portraits (from unknown book source) of Olaudah Equiano (Nigerian, born c.1745, Britain’s first Black political leader).
This exhibition will reveal the everyday lives of Black people during the Georgian period (1714-1830). It will offer a rich array of historical evidence and archival materials that present a surprising, sometimes shocking, and inspiring picture of Georgian Britain.
The Black Georgian narrative not only challenges preconceptions of the Black presence in Britain being restricted to post World War II, but it speaks to us of a growing population that forged a new identity with creativity, adaptability, and remarkable fortitude. It is a complex picture: while there was much oppression and restriction, there was also a degree of social mobility and integration.
Key individuals form the backbone to the exhibition, including Phillis Wheatley, the subject of this article in particular. Aged only seven, Wheatley was brought to Boston, United States, and sold as a child servant to the all-white Wheatley family in 1761. At the time, Boston was home to only 15,000 people, 800 of whom were of African descent; only 20 of these 800 were “free” individuals and not enslaved.[1] From the start, it was clear to the Wheatley family that Phillis was an extraordinary child, referred to by critics today as a ‘child prodigy’,[2] who ‘gave indications of uncommon intelligence’.[3] Susanna Wheatley, the mistress of the Wheatley family, recognised this extraordinary flair of intuitive intelligence, fostering the intellectual development of Phillis by allowing her to learn to read and write, learn Latin and to read the Bible. One may ask, why was Phillis saved from the usual domestic chores which was expected of the other servants? Vincent Carretta argues that Susanna’s attention may have been ‘a kind of social experiment to discover what effect education might have on an African’ or, perhaps, that Phillis reminded Susanna of the daughter she had lost years earlier.[4] Though we can never be certain as to why Susanna felt compelled to provide for Phillis in the manner that she did, we can see how it undoubtedly shaped the young child, with Wheatley later becoming the first African-American woman to publish poetry.
Wheatley’s first volume of poetry, Poems on Various Subjects, Religious and Moral, was first published in England in 1773, the same year that she visited London. Wheatley was viewed by many during her trip to London as a “celebrity” of the day, though she was of course not without her critics; Wheatley had to prove the authenticity of her authorship, for many doubted that a women, more especially a former enslaved individual, could be capable of producing the poetry that she published.
Unfortunately, Wheatley’s life was short, dying at the young age of 31. She had married another free Black man, John Peters, in 1778, but despite the promising turn of events in her earlier life, including literary fame as the first female African-American poet, Wheatley died in poverty in 1784, having struggled to publish any further poetry.
PHOTOS/25 Photocopy of a Phillis Wheatley Portrait. Colour photocopy (undated) of artwork by Scipio Moorhead portraying Phillis Wheatley (1753-1784) for her book ‘Poems on Various Subjects’ (unknown source).
Though short, Wheatley’s life was certainly remarkable, although there is still relatively little known about her beyond the basic facts, and less still known about her former years before being brought to Boston. Black Cultural Archives has previously recognised the remarkable life of Wheatley, highlighting her in a previous newsletter from 1992 as a ‘personality of the month’; this newsletter is part of our archival collection today, and can be found under the reference BCA/6/4/7.
Phillis Wheatley was the focus of the free Treasures in the Archive lunchtime talk on the 17th December, delivered by the Assistant Archivist, Emma Harrison; Wheatley and other prominent figures from the Georgian period can be explored further in the Black Georgians exhibition at Black Cultural Archives, which runs from the 9th October 2015 – 9th April 2016. For those who wish to interrogate and explore archival material relating to the Black Georgians exhibition, you are able to search our online catalogue (http://www.calmview.eu/BCA/CalmView/advanced.aspx?src=DServe.Catalog ). Archival material can be viewed by emailing archives@bcaheritage.org.uk to book an appointment in the reading room, which is open for archive appointments Wednesday-Friday 10am-4pm, and every second Thursday.
Emma Harrison Assistant Archivist Black Cultural Archives
[1] Vincent Carretta, Phillis Wheatley: Biography of a Genius in Bondage (London: The University of Georgia Press, 2011), p. 1.
[2] Peter Fryer, Staying Power (New York: Pluto Press, 2010), p. 91.
[3] William H. Robinson, Phillis Wheatley in the Black American Beginnings (Detroit: Broadside Press, 1975).