I attended the final Zoom session for the Heritage Persistent Identifiers Project this week.
PID or Persistent Identifiers can be incredibly useful within the heritage sector. The PID project was looking at the use of PIDs across collections. They were aiming to increase uptake of PIDs, so that they service as a foundation infrastructure for drawing collections together.
The project ran two surveys with responses mainly from the UK but a number from other countries. 66 and 47 responses were received for the 1st and 2nd surveys respectively. Both surveys showed that most institutions have pockets of awareness of PIDs, although the number of people with no awareness decreased slightly over time.
The main barriers according to the surveys are lack of resources and technical issues. It is also clear that decision makers need to be more appreciative the benefits of PIDs.
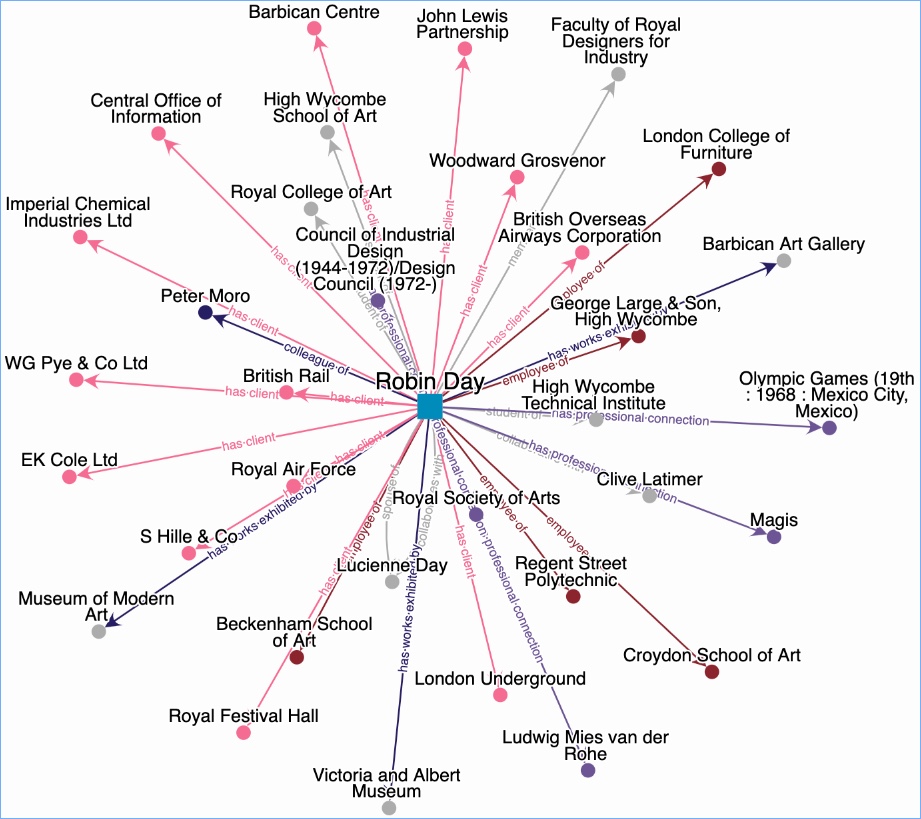
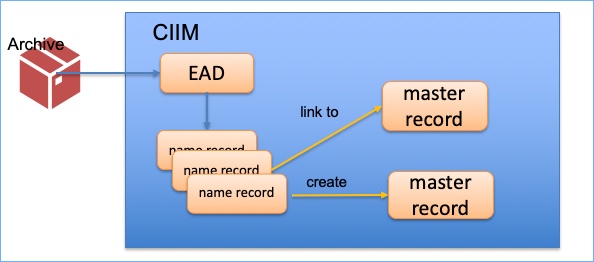
The project case studies were found to be particularly useful by survey respondents, and also the PID demonstrator that showed how collections can be linked through PIDs. The case studies included the National Gallery – interestingly they are using the CIIM, as we are, so their PIDs were created as a component of the CIIM.
One thing that struck me as I was listening is that PIDs apply to all sorts of things – documents, objects, collections, publications, people, organisations, places. I think that this can make it difficult to grasp the context when people are talking about PIDs in general. I found myself getting a bit lost in the conversation because it is such a large landscape, and I am someone who has a reasonable knowledge of this area.
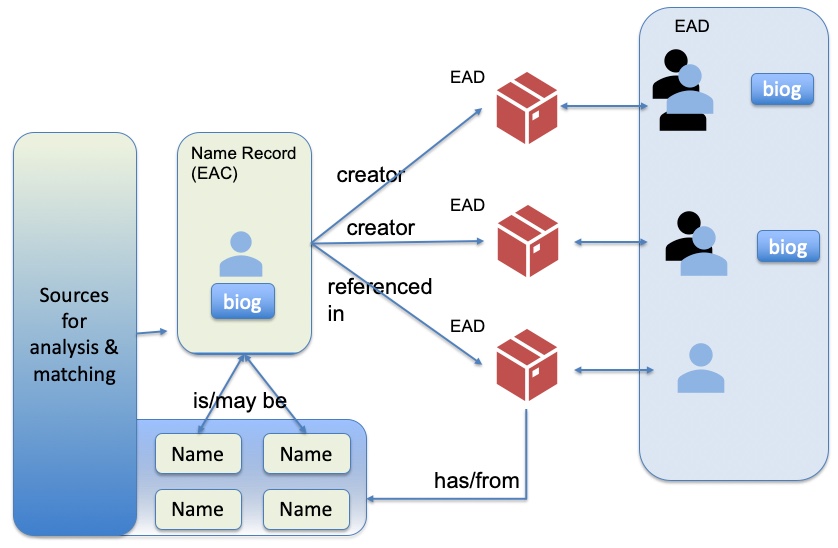
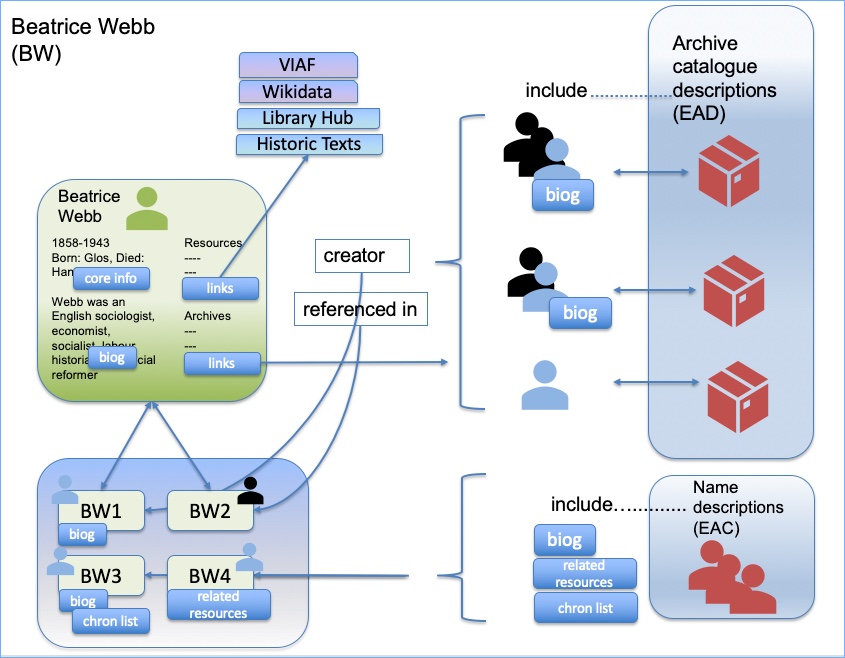
Within the Archives Hub we have persistent identification of descriptions, at all levels – so each unit of description has a PID. e.g. https://archiveshub.jisc.ac.uk/data/gb275-davies uses the country code GB, the repository code 275 and the reference ‘davies’. These are URIs, which gives more utility, as they can be referenced on the Web as well as in publications. We had very very long discussions about the make-up of these identifiers. We did consider having completely opaque identifiers, but we felt there was some advantage of having user-friendly URIs, especially for things like analytics – if you see that ‘gb275-davies’ has had 53 views then you may know what that means, whereas if ‘27530981’ has had 53 views, you have to go and dereference it to find out what that actually is. However, references can change over time, so if you use them in persistent identifiers you have a problem when the reference changes.
Granularity is a question that needs to be addressed when thinking about PIDs for archives. Should every item have a DOI for example (digital object identifier)?. Should the DOI be assigned to the collection? Not all collections are described to item level, so in many cases this might be a moot point. So far I don’t think we’ve received archive descriptions that include DOIs so I don’t think it is going to be top of the agenda for archives any time soon. It may not be something that we, as an aggregator, necessarily get involved with anyway. If a contributor to the Hub includes a DOI, then we can display that, and maybe that is our work done. I’m not sure that it has a role in linking aggregated data to other datasets.
ARKs were mentioned in the session. We haven’t yet considered using these within our system. We’ve only had 2 contributors out of 350 who have included them, so we are not sure that it is worth us working with them at this stage. This is one of the problems with adopting PIDs – uptake and scale. ORCIDs were also referenced. An ORCID is for researchers – eventually their papers may come to the archive, so ORCID IDs may become more relevant in time. It is important for ORCID to work with Wikidata and other PIDs to enable linking. Bionomia was mentioned as a project that already works with ORCID and Wikidata.
Overall my impression listening to the presentations was of a very mixed landscape, and that is something that makes it harder to figure out how to start working with PIDs – there is no one clear way forward. In the case studies presented there was quite a bit of emphasis on internal use cases, and that can limit the external benefits, but there was also a range of approaches. This doesn’t help anyone starting out and hoping for a clear way forward.
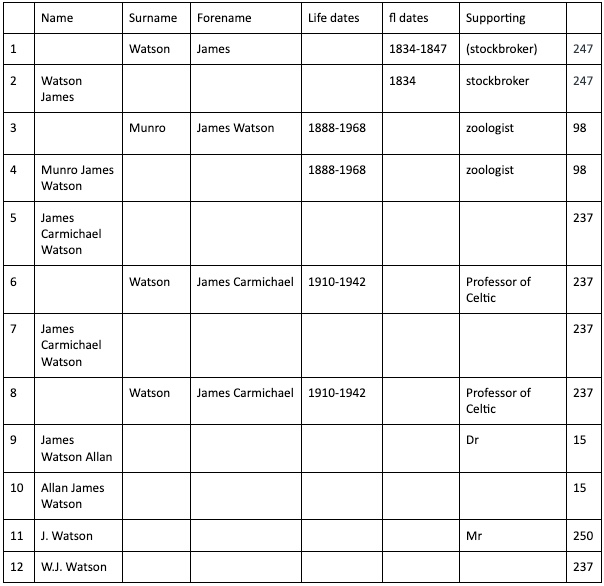
The Archives Hub has done work on identifying personal and organisational names and we are going to be blogging more about the outcome of that when work we implement changes to our user interface over the next few months. But it is worth saying that if you want to implement PIDs for names, you have to look at the names you have and how identifiable they really are. It has been extremely difficult for us to do this work, and we cannot possibly achieve 100% identification because of the very variable state of the names that we have in the data.
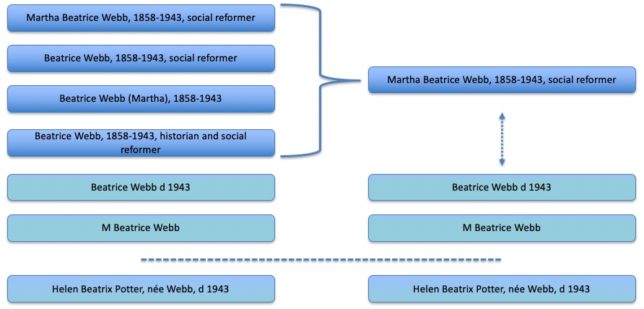
PIDs need to know what they are identifying, and being clear about what that is may in itself be a big challenge. If you assign a PID to a person, an organisation, or any entity, you want to be confident that it is right. ORCIDs are for current researchers, and if you set yourself up with an ORCID, you are going to know that it identifies you (one would hope). But if we have seven ‘Elizabeth Roberts‘ referred to on the Archives Hub, referenced in a range of archives, we may find it very difficult to know if they are the same person. Assigning identification to historical records is a massive detective challenge.
We have been looking to match our names to VIAF or Wikidata, so that we can benefit from these widely used PIDs. But to do that we need to find a way to create matches and set levels of confidence for matches. Increasingly, I am wondering if Wikidata is more promising than VIAF due to the ability to add to the database. For archives, where many names are not published individuals, this might prove to be a good way forward.
The PID project came up with a number of recommendations. Many of these were about generally promoting PIDs and integrating them into workflows. Quite a few of the recommendations look like they need significant funding. One that I think is very pertinent is working with system suppliers. It needs to be straightforward to integrate PIDs when a collection is being catalogued.
The recommendations tended to just refer to PIDs and not specific PIDs and I’m not sure whether this is helpful as it is such a broad context. Maybe it is more useful to be more specific about whether you are looking at PIDs for collections/artefacts or for researchers, for all names or for topics. For example, if you recommend looking at cost analysis, is this for any and all PIDs that might be implemented across all of the cultural heritage sector? The project has found that it is not possible to be prescriptive and narrow things down, but I still feel that talking about certain kinds of identifiers rather than PIDs in general might help to give more context to the conversation.
There are many persistent identifier systems. If we all use different identifiers then we aren’t really getting towards the kind of interconnectivity that we are after. We could do with adopting a common approach – even just a common approach within the archives domain would be useful – but that requires resource and that requires funding. Having said that, it is not essential to use exactly the same PIDs. For example, if one organisation adopts VIAF IDs for their names and another adopts Wikidata Q codes, then that is not really a problem in that VIAF and Wikidata link to each other. But adopting a system that is not widely used (and not linked up to other systems) is not really going to be very helpful.
In the end, we need a very clear sense of the benefits that PIDs will bring us. As an aggregator it is very difficult to add PIDs to data that we receive. Archives should ideally add PIDs as they create descriptions. If VIAF IDs or Wikidata Q codes, or Geonames identifiers for place names, were added during cataloguing, that could potentially be of great benefit. But this raises a big issue – we need archival management systems to make it really easy to add PIDs, and at present many of them don’t do this. Our own cataloguing tool does provide a look-up and this has proved to be really successful. It makes adding identifiers easier than not adding them – and that is what you want to achieve.