I imagine many of you have tried asking ChatGPT questions like these, but we thought it was worth providing this blog, for those who haven’t tried it out. For anyone who has managed to avoid the headlines around this technology, ChatGPT is an artificial intelligence chatbot developed by OpenAI and released in November 2022.
First of all, we wanted to try a question that focussed on using one archive, so we asked:
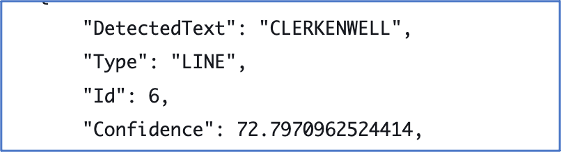
Can you give me advice on how to write a dissertation on Stanley Kubrick using primary sources or archives?
ChatGPT answered:
Certainly, here are some tips for writing a dissertation on Stanley Kubrick using primary sources or archives:
- Choose a research question: The first step in writing a dissertation is to identify a research question that you want to explore. This could be anything from analyzing Kubrick’s use of color in his films to examining his working methods and creative process. Make sure that your research question is focused enough to be manageable within the scope of your dissertation.
- Identify relevant primary sources and archives: Once you have a research question, you need to identify primary sources and archives that are relevant to your topic. This could include Kubrick’s personal papers, scripts, storyboards, correspondence, and production notes. You can also look for archives and collections related to Kubrick’s collaborators and contemporaries, such as other film directors, writers, or actors.
- Conduct a literature review: Before diving into primary sources and archives, conduct a thorough literature review to see what has already been published on your topic. This will help you identify any gaps in the existing research and refine your research question further. It will also give you a sense of the debates and issues within the field that your dissertation will need to address.
- Plan your research visits: Before visiting archives, you need to plan ahead and make sure that you have enough time to access and review the materials you need. Some archives have strict access requirements or limited opening hours, so check this in advance. Make a list of the specific documents or materials you need to examine, and plan your research visits accordingly.
- Analyze and evaluate primary sources: Once you have access to primary sources, you will need to analyze and evaluate the materials carefully. Make notes of important details, such as dates, locations, and people involved. Look for patterns, themes, and connections in the materials, and identify any contradictions or inconsistencies. Keep in mind the broader research question you are trying to answer, and look for evidence that can support your argument.
- Write your dissertation: Once you have reviewed and analyzed your primary sources, you can start writing your dissertation. Make sure to frame your analysis within the broader context of existing scholarship, and use primary sources to support your arguments and interpretations. Use quotations and examples from primary sources to illustrate your points and make your argument more convincing.
Writing a dissertation on Stanley Kubrick using primary sources and archives can be a rewarding and challenging task. Make sure to plan ahead, conduct thorough research, and use primary sources effectively to support your arguments and interpretations.
*****
We then wanted to see how well ChatGPT would summarise the role and value of Archives Hub, so we asked:
How do I use Archives Hub to help with my research?
ChatGPT answered:
The Archives Hub can be a valuable resource for researchers who are looking to explore archival collections held in institutions across the UK. Here are some tips on how to use Archives Hub to help with your research:
- Search the Archives Hub database: Start by using the search bar on the Archives Hub homepage to search for keywords, names, or locations that are relevant to your research topic. This will bring up a list of archives and collections that match your search terms. You can then click on each archive or collection to view more detailed information, including a description of the materials held, contact information for the holding institution, and links to related collections.
- Refine your search: You can refine your search results using the menus on the left-hand side of the page. These menus allow you to narrow your search by institution, keyword, date range, or subject. Use these filters to focus your search on the most relevant materials.
- Contact the holding institution: Once you have identified an archive or collection that seems relevant to your research, contact the holding institution to confirm the availability of the materials and to arrange a research visit if necessary. The contact information for each institution is listed on the Archives Hub website.
- Plan your visit: Before visiting an archive, make sure to plan ahead and think about what materials you want to examine. Familiarize yourself with the archive’s policies on access and handling of materials, and bring any necessary equipment, such as a camera or laptop. Make sure to take detailed notes during your visit, as well as copies or photographs of any relevant documents or materials.
- Follow ethical guidelines: When conducting research in archives, it is important to follow ethical guidelines and practices. This means properly citing your sources, respecting the privacy and confidentiality of individuals mentioned in archival materials, and obtaining permission to use any copyrighted materials. This will help to maintain the trust and cooperation of archival repositories and their staff.
By using the Archives Hub to identify collections and institutions that are relevant to your research, you can gain access to a vast array of archival materials held across the UK. Be sure to plan ahead, follow ethical guidelines, and take detailed notes during your research visits to make the most of these valuable resources.
*****
Both answers are very convincing and it is hard to argue that we would have done better if we had written them ourselves, though we might want to add more information to what is there. The guide for using the Archives Hub seems to utilise text from different parts of our website, including our Guide for Beginners, access information and search help. But the text is not lifted directly – it is far more sophisticated than that. There are many examples of text that does not echo anything we have said on our website and I can’t find the text elsewhere. For example, ChatGPT refers to possible dissertation subjects for Kubrick: ‘analyzing Kubrick’s use of color in his films to examining his working methods and creative process’. There are sentences that widen the scope, for example: ‘Make sure to frame your analysis within the broader context of existing scholarship, and use primary sources to support your arguments and interpretations.’ There are sentiments that I don’t recall seeing stated in quite the same way that ChatGPT has done, for example: ‘This means properly citing your sources, respecting the privacy and confidentiality of individuals mentioned in archival materials, and obtaining permission to use any copyrighted materials. This will help to maintain the trust and cooperation of archival repositories and their staff.’
It is easy to see why ChatGPT is seen as a means to write effectively. Maybe there are questions around what is left out of the above answers, but I would certainly be happy to use them as a basis for our own guidelines.