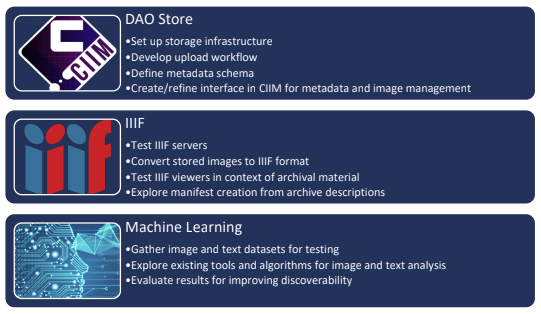
In this post I will go through the steps we took to create a human labelled dataset (i.e. naming objects within images), applying the labels to bounding boxes (showing where the objects are in the image) in order to identify objects and train an ML model. Note that the other approach, and one we will talk about in another post, is to simply let a pre-trained tool do the work of labelling without any human intervention. But we thought that it would be worthwhile to try the human labelling out before seeing what the out-of-the-box results are.
I used the photographs in the Claude William Jamson archive, kindly provided by Hull University Archives. This is a collection with a variety of content that lends itself to this kind of experiment.

I used Amazon SageMaker for this work. In SageMaker you can set up a labelling job using the Ground Truth service, by giving the location of the source material – in this case, the folder containing the Jamson photographs. Images have to be jpg, or png, so if you have tif images, for example, they have to be converted. You give the job a name and provide the location of the source material (in our case an S3 bucket, which is the Amazon Simple Storage Service).
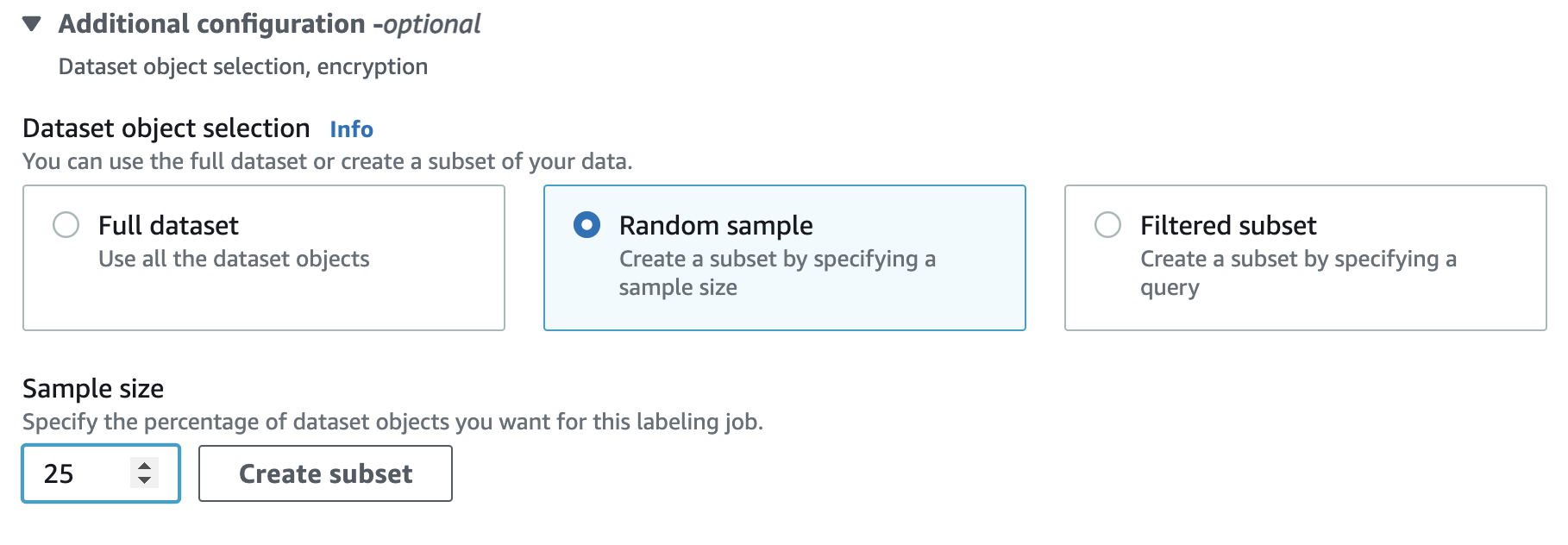
I then decide on my approach. I trained the algorithm with a random sample of images from this collection. This is because I wanted this sample to be a subset of the full Jamson Archive dataset of images we are working with. We can then use the ML model created from the subset to make object detection predictions for the rest of the dataset.
Once I had these settings completed, I started to create the labels for the ‘Ground Truth’ job. You have to provide the list of labels first of all from which you will select individual labels for each image. You cannot create the labels as you go. This immediately seemed like a big constraint to me.
I went through the photographs and decided upon the labels – you can only add up to 50 labels. It is probably worth noting here that ‘label bias’ is a known issue within machine learning. This is where the set of labelled data is not fully representative of the entirety of potential labels, and so it can create bias. This might be something we come back to, in order to think about the implications.
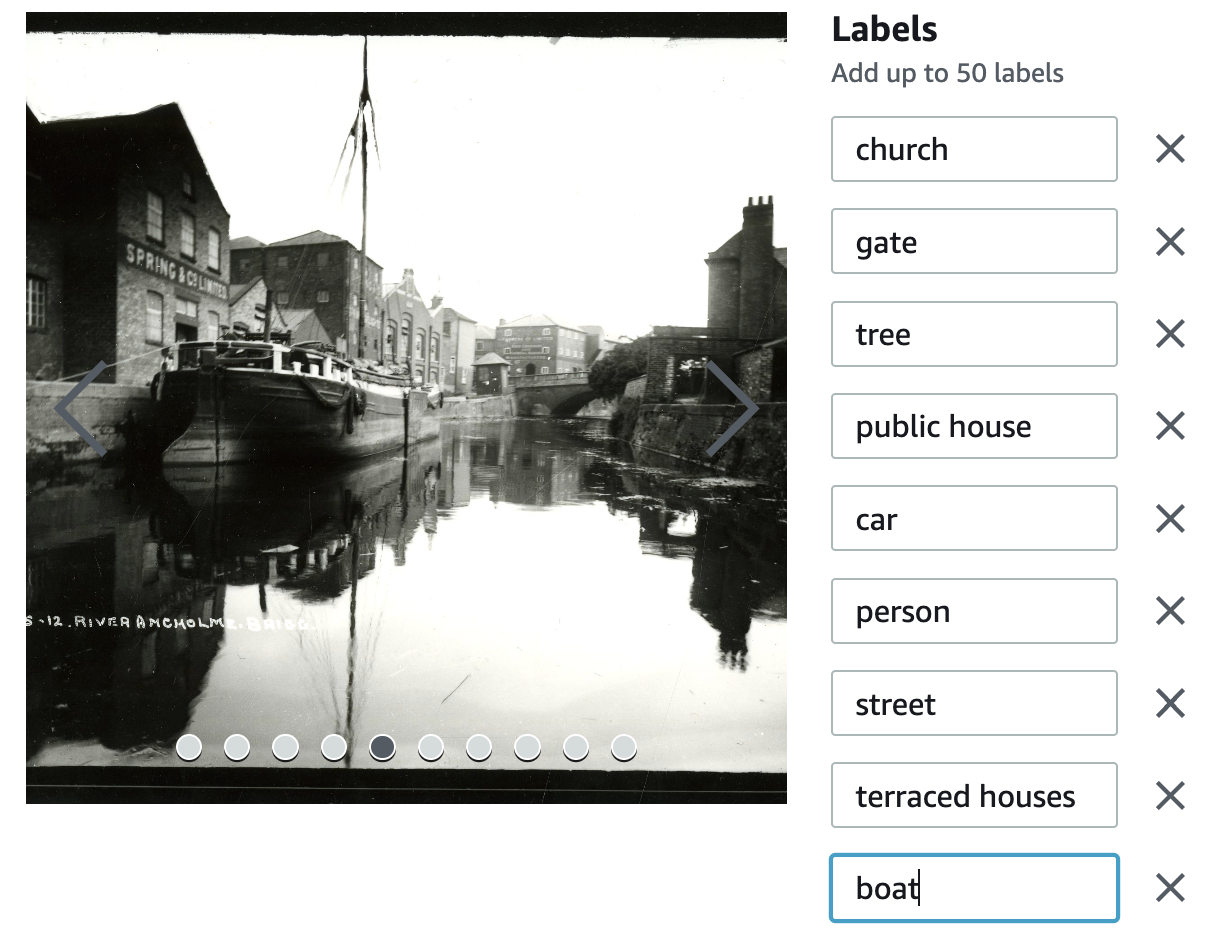
I chose to add some fairly obvious labels, such as boat or church. But I also wanted to try adding labels for features that are often not described in the metadata for an image, but nonetheless might be of interest to researchers, so I added things like terraced house, telegraph pole, hat and tree, for example.
Once you have the labels, there are some other options. You can assign to a labelling team, and make the task time bound, which might be useful for thinking about the resources involved in doing a job like this. You can also ask for automated data labelling, which does add to the cost, so it is worth considering this when deciding on your settings. The automated labelling uses ML to learn from the human labelling. As the task will be assigned to a work team, you need to ensure that you have the people you want in the team already added to Ground Truth.
Those assigned to the labelling job will receive an email confirming this and giving a link to access to the labelling job.
You can now begin the job of identifying objects and applying labels.

First up I have a photograph showing rowing boats. I didn’t add the label ‘rowing boat’ as I didn’t go through every single photograph to find all the objects that I might want to label, so not a good start! ‘Boat’ will have to do. As stated above, I had to work with the labels that I created, I can’t add more labels at this stage.
I added as many labels as I could to each photograph, which was a fairly time intensive exercise. For example, in the image below I added not only boat and person but also hat and chimney. I also added water, which could be optimistic, as it is not really an object that is bound within a box, and it is rather difficult to identify in many cases, but it’s worth a try.

I can zoom in and out and play with exposure and contrast settings to help me identify objects.
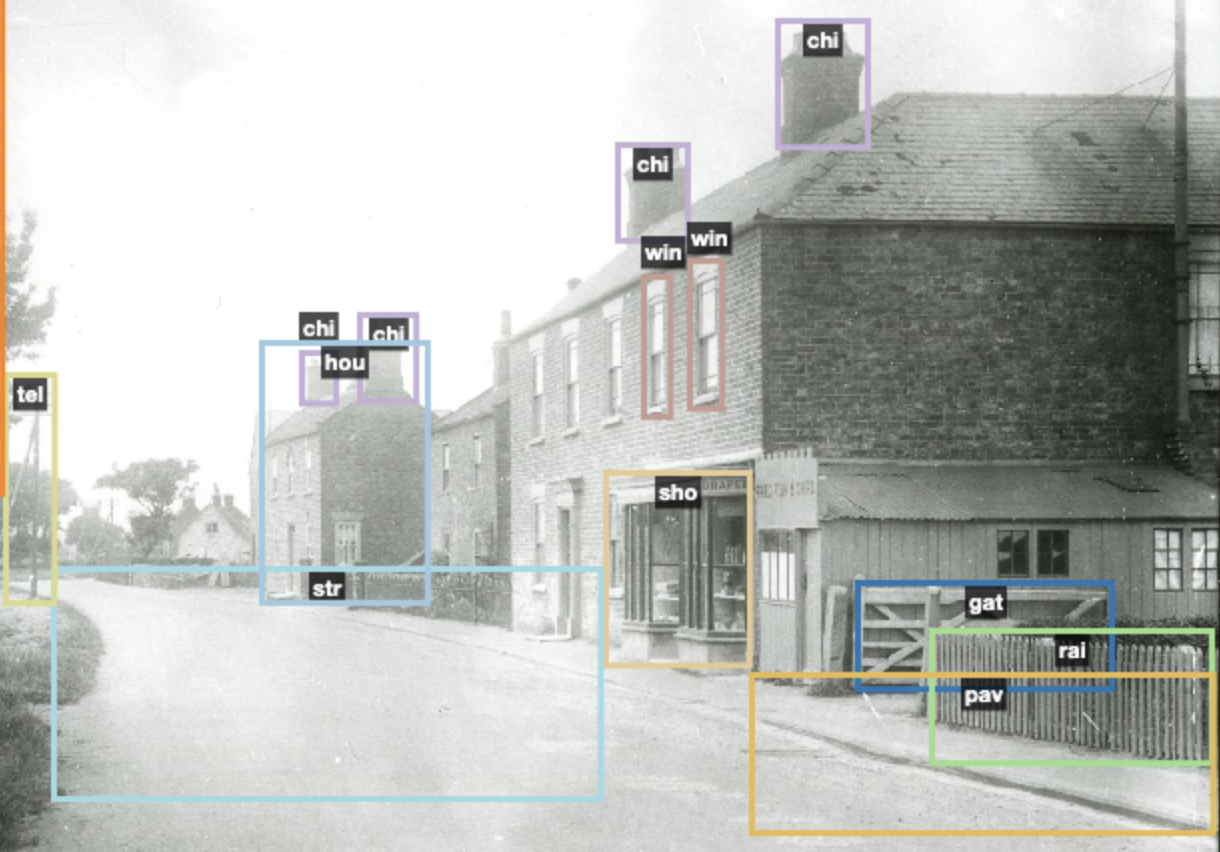
Here is another example where I experimented with some labels that seem quite ambitious – I tried shopfront and pavement, for example, though it is hard to classify a shop from another house front, and it is hard to pin-point a pavement.
The more I went through the images, drawing bounding boxes and adding labels, the more I could see the challenges and wondered how the out-of-the-box ML tools would fare identifying these things. My aim in doing the labelling work was partly to get my head into that space of identification, and what the characteristics are of various objects (especially objects in the historic images that are common in archive collections). But my aim was also to train the model to improve accuracy. For an object like a chimney, this labelling exercise looked like it might be fruitful. A chimney has certain characteristics and giving the algorithm lots of examples seems like it will improve the model and thus identify more chimneys. But giving the algorithm examples of shop fronts is harder to predict. If you try to identify the characteristics, it is often a bay window and you can see items displayed in it. It will usually have a sign above, though that is indistinct in many of these pictures. It seems very different training the model on clear, full view images of shops, as opposed to the reality of many photographs, where they are just part of the whole scene, and you get a partial view.
There were certainly some features I really wanted to label as I went along. Not being able to do this seemed to be a major shortcoming of the tool. For example, I thought flags might be good – something that has quite defined characteristics – and I might have added some more architectural features such as dome and statue, and even just building (I had house, terraced house, shop and pub). Having said that, I assume that identifying common features like buildings and people will work well out-of-the-box.
Running a labelling job is a very interesting form of classification. You have to decide how thorough you are going to be. It is more labour intensive than simply providing a description like ‘view of a street’ or ‘war memorial’. I found it elucidating as I felt that I was looking at images in a different way and thinking about how amazing the brain is to be able to pick out a rather blurred cart or a van or a bicycle with a trailer, or whatever it might be, and how we have all these classifications in our head. It took more time than it might have done because I was thinking about this project, and about writing blog posts! But, if you invest time in training a model well, then it may be able to add labels to unlabelled photographs, and thus save time down the line. So, investing time at this point could reap real rewards.

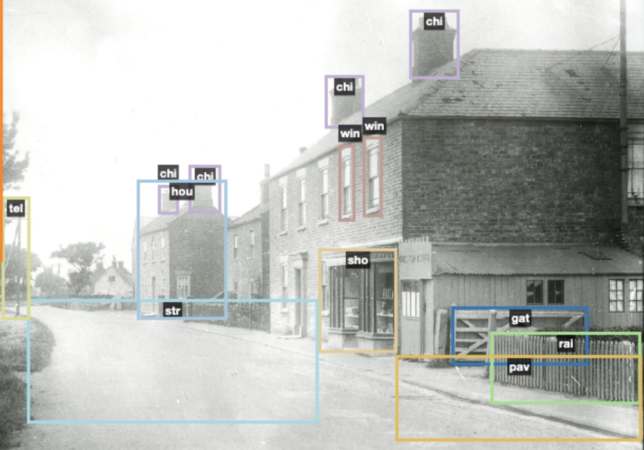
In the above example, I’ve outlined an object that i’ve identified as a telegraph pole. One question I had is whether I am are right in all of my identifications, and I’m sure there will be times when things will be wrongly identified. But this is certainly the type of feature that isn’t normally described within an image, and there must be enthusiasts for telegraph poles out there! (Well, maybe more likely historians looking at communications or the history of the telephone). It also helps to provide examples from different periods of history, so that the algorithm learns more about the object. I’ve added a label for a cart and a van in this photo. These are not all that clear within the image, but maybe by labelling less distinct features, I will help with future automated identification in archival images.
I’ve added hat as a label, but it strikes me that my boxes also highlight heads or faces in many cases, as the people in these photos are small, and it is hard to distinguish hat from head. I also suspect that the algorithm might be quite good with hats, though I don’t yet know for sure.
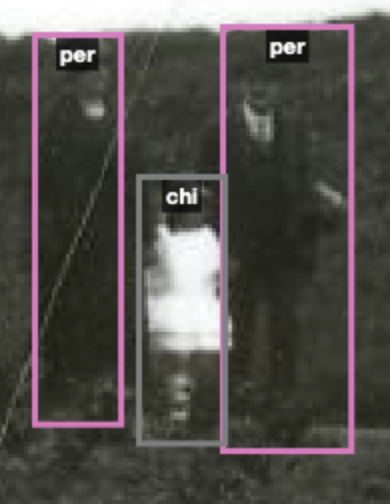
I used ‘person’ as a label, and also ‘child’, and I tended not to use ‘person’ for ‘child’, which is obviously incorrect, but I thought that it made more sense to train the algorithm to identify children, as person is probably going to work quite well. But again, I imagine that person identification is going to be quite successful without my extra work – though identifying a child is a rather more challenging task. In the end, it may be that there is no real point in doing any work identifying people as that work has probably been done with millions of images, so adding my hundred odd is hardly going to matter!
I had church as a label, and then used it for anything that looked like a church, so that included Beverly Minster, for example. I couldn’t guarantee that every building I labelled as a church is a church, and I didn’t have more nuanced labels. I didn’t have church interior as a label, so I did wonder whether labelling the interior with the same label as the exterior would not be ideal.
I was interested in whether pubs and inns can be identified. Like shops, they are easy for us to identify, but it is not easy to define them for a machine.

A pub is usually a larger building (but not always) with a sign on the facade (but not always) and maybe a hanging sign. But that could be said for a shop as well. It is the details such as the shape of the sign that help a human eye distinguish it. Even a lantern hanging over the door, or several people hanging around outside! In many of the photos the pub is indistinct, and I wondered whether it is better to identify it as a pub, or whether that could be misleading.
I found that things like street lamps and telegraph poles seemed to work well, as they have clear characteristics. I wanted to try to identify more indistinct things like street and pavement, and I added these labels in order to see if they yield any useful results.
I chose to label 10% of the images. That was 109 in total, and it took a few hours. I think if I did it again I would aim to label about 50 for an experiment like this. But then the more labels you provide, the more likely you will get results.
The next step will be to compare the output using the Rekognition out of the box service with one trained using these labels. I’m very interested to see how the two compare! We are very aware that we are using a very small labelled dataset for training, but we are using the transfer learning approach that builds upon existing models, so we are hopeful we may see some improvement in label predications. We are also working on adding these labels to our front end interface and thinking about how they might enhance discoverability.
Thanks to Adrian Stevenson, one of the Hub Labs team, who took me through the technical processes outlined in this post.