Archives of IT (AIT) began when entrepreneur Roger Graham saw the need to interview the founding generation of the IT Industry and save their stories for the future. Up to this point, heritage work was happening to save the history of computers, hardware and games but little was being done to preserve the social and oral history of the people behind the technology.
Founder Roger Graham (copyright AIT).
Archives of IT was registered as a Charitable Incorporated Organisation (CIO) in 2015, with the aims of educating the public on the history of IT, particularly through the provision of a digital archive, accessible at www.archivesit.org.uk. AIT is governed by trustees, chaired by communications specialist John Carrington, and has a small number of part time staff and a team of volunteers who manage the acquisition of materials, the website and the production of blogs and education resources.
Trustees From L to R: Roger Graham OBE (Founder), Tom Abram (Director), Patrick Chapman, Tola Sargeant, Iain Mitchell KC (WCIT Liaison), John Carrington (Chair) (Copyright AIT).
Initially, the focus for interviews has been on early post-war pioneers of IT that were at the forefront of this new industry – the intention to save those stories before time ran out. However, as time has passed interviews have become more contemporary, capturing more current trends in the IT sector, and taking in diverse topics such as women in STEM, infra-red technology, cybersecurity, venture capitalists and wearable health devices.
Oral history interviews
Much has been achieved in AIT’s first seven years, including more than 220 oral history interviews recorded, transcribed, and uploaded to the website for people to view. The first interview was published on the website in 2017; David Potter CBE discusses his life in academia in computer simulation, then his move to the business world establishing Potter Scientific Instruments, or Psion. They invented the world’s first personal digital assistant – the Psion Organiser – in 1984 and advising Nokia in the 1990s as mobile telephone technology began to take off.
Other oral history collection highlights include:
The first UK Professor of Informatics and a pioneer of early commercial computing Professor Frank Land
As part of its charitable aims to contribute to IT education in the UK, AIT have produced primary school learning and careers resources for teachers in collaboration with The Institution of Engineering and Technology. Key Stage 1 and 2 lesson plans have been developed and are available to download on the website. Key Stage 3 and 4 careers advice to encourage pupils to consider a job in IT are also available.
A recent school competition to design a logo for FIFA World Cup 2026 was successful, with nearly 100 entries from UK Schools. This latest competition was linked to the national curriculum by encouraging schoolchildren to use technology purposefully to create, organise, store, manipulate and retrieve digital content to accomplish a given goal.
It also involved history by looking at events beyond living memory that are significant nationally or globally and art, to use drawing to develop and share their ideas, experiences and imaginations and develop a wide range of design techniques using colour, line, shape, form, and space.
Education resources – Research projects
AIT is working with several partners to produce research based on its collections. Published research can be read here on topics ranging from the post Second World War IT Industry to 60 years progress of women working in IT.
Dr Elisabetta Mori with an Olvetti Elea 9003. Photograph by Armin Linke.
A small number of publications have been donated to us by supporters and interviewees, and digitised versions of them can be viewed on our website, alongside other databases and websites hosted independently by people involved in the early years of the IT industry, that may be of use to researchers browsing our website.
The Archives Hub
AIT is a new archive, and non-traditional in that it has no geographical location and is digital only. As it develops, AIT is focusing on improving discovery of its collections on the internet.
As part of these plans, in 2022 we contributed an online resource description to the Archives Hub. This description is intended as a guide to AIT’s website, and it is hoped its presence on the Hub will increase the website’s use by academics and university students. The aim is to contribute a multi-level description of AIT’s collections to the Hub soon.
In 1983 the government allocated the papers of Arthur Wellesley, first Duke of Wellington, the long serving politician and the premier soldier of his generation, to the University of Southampton under national heritage legislation. The collection arrived on 17 March of that year. This brought to Southampton the University’s first major manuscript collection, leading to the creation of an Archives Department and the development of a major strand of activity within the University Library.
Official opening of the Wellington Suite Archives accommodation: Mr Naylor, University Librarian, Professor Smith, Department of History (hidden), Mr. Woolgar, Archivist, and the Duke of Wellington looking at display of papers, 14 May 1983. [MS1/Phot/39/ph3526]
Composed of around 100,000 items that cover the Duke’s career as a soldier, statesman and diplomat from 1790 to his death in 1852, the collection bears witness to great military, political and social events of the time. It is exceptional among the papers of nineteenth-century figures for its size and scope.
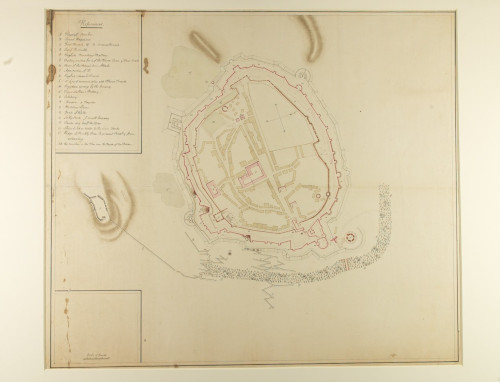
Plan of Seringapatam at the time of its capture by Wellington, early 19th century [MS61/WP15/6]
Wellington’s time in India, 1798-1805, when he made his fortune and his name as a military commander, is well represented by three series of letter books, the first two series arranged chronologically, with the third, covering 1802-5, arranged by correspondent. The sections for the Peninsular War (1808-14) and for the Waterloo campaign provide an unrivalled source for the history of British participation. The collection also includes Wellington’s correspondence and papers for the congresses at the end of the Napoleonic wars and the allied occupation of France, 1815-18, a period when Wellington was a major player on the European political scene.
Letter from Wellington to Lord Bathurst after the battle of Vitoria using the phrase ‘scum of the earth’, 1813 [MS61/WP1/373/6]
Wellington was involved in politics throughout his career, serving as an MP in the Irish parliament in the 1780s onwards and as Chief Secretary for Ireland, 1807-9. There is considerable material for his political career post 1818, including two times as prime minister, as well as for his role as Lord Lieutenant of Hampshire and as Commander in Chief of the Army. Amongst the extensive number of cabinet papers, drafted in the Duke’s own hand is the memorandum written by Wellington and Peel setting out the details of the Catholic emancipation act of 1829. Material from his tenure as Lord Lieutenant of Hampshire includes death threats from Captain Swing dating from the Swing riots around the southern counties of England.
Letter to Wellington, signed “Swing” threatening assassination, n.d. c. 8 November 1830 [MS61/WP1/1159/114]
As the archive is from the great age of government by correspondence, as well as coinciding with a wider revolution in communication, it contains material from a wide cross section of society. Everyone wrote to the Duke of Wellington, offering the national hero their views on a whole range of subjects, asking for patronage, promotion or assistance, wishing to dedicate their works to him, or asking him to be the godfather of their children or to be allowed to name them after him. In response to one letter, Wellington noted with his usual acerbic wit the inconvenience of calling all boys born on his birth by the name “Arthur”.
Cataloguing the Wellington Archive in the 1980s using BBC microcomputers.
The arrival of the Wellington Archive in 1983 was significant in another way in that it marked the beginning of Southampton’s long involvement in automated archive catalogues. The Wellington Papers Database could claim to be one of, if the not the earliest, online archive catalogue in the UK. Investigations into a system to support this were already underway in December 1982, prior to the arrival of the papers. In July 1983 the University decided to develop a manuscript cataloguing system using STATUS software and it was in use for cataloguing material early the following year. The cataloguing was done “offline” by the archivists on BBC microcomputers equipped with rudimentary word-processing packages – but no memory – and all text was saved onto floppy discs. It was subsequently transferred to an ICL mainframe computer for incorporation into the database by batch programme. This being the days prior to the WWW, the initial database was made available by the Joint Academic Network (JANET) and the public switched telephone network. It was initially scheduled to be made available 156 hours a week, rising to 168. In 2023 the catalogue of the Wellington Archive can be accessed in the Epexio Archive Catalogue, a new system that we launched in November 2021.
The collection also came with a major conservation challenge – some ten percent of the collection was so badly damaged it was unfit to handle and in a parlous state. Considerable progress has been made in addressing this. Important material is now available for research, including for the Peninsular War, papers for 1822 (for the Congress of Verona) and for Wellington as Prime Minister in 1829. The badly degraded and mould-damaged bundles from 1832, significant as the time of the First Reform Act, are available for the first time since 1940.
19th Wellington Lecture – Martin Carthy.
The last forty years also has seen a great deal of outreach and activity focused on the Wellington Archive. As well as research and teaching sessions, drop-in sessions, events and exhibitions, the Archives Department has arranged six international Wellington congresses. In 2015 and 2017 Karen Robson and Professor Chris Woolgar presented a MOOC they had co-created relating to Wellington and Waterloo. And since 1989 there has been the annual Wellington Lecture with speakers or presenters ranging from Elizabeth Longford to Martin Carthy.
To mark Women’s History Month, we’re highlighting some fascinating features, fantastic collections and online resources relating to women, their achievements and influence.
Archives Hub features
We have a wide range of Archives Hub monthly features focusing on women, including:
Black Georgians: Phillis Wheatley
PHOTOS/25 Photocopy of a Phillis Wheatley Portrait. Colour photocopy (undated) of artwork by Scipio Moorhead portraying Phillis Wheatley (1753-1784) for her book ‘Poems on Various Subjects’ (unknown source).
Phyllis was sold as a child servant to the all-white Wheatley family in 1761.
Susanna Wheatley, the mistress of the Wheatley family, recognised her extraordinary flair of intuitive intelligence, fostering the intellectual development of Phillis by allowing her to learn to read and write, learn Latin and to read the Bible.
She later became the first African-American woman to publish poetry.
The Imogen Holst archive: papers of a passionate and open-minded woman musician
Holst conducting a military band, 1948, photographer: Nicholas Horne (ref no. HOL/2/11/4/6), Britten-Pears Foundation Archive.
Imogen Holst (1907-1984) was the daughter of composer Gustav Holst, best-known for The Planets.
Holst, herself a composer, is perhaps best-known today as Benjamin Britten’s musical assistant, but she also had an exceptional, wide-ranging but lesser known career as, amongst other things, educator, conductor and music traveller.
The Legacy of Ahmed Archive and the Courage and Inspiration of his Mother
Family photograph, Ahmed third from left (GB3228.19.6.1), Ahmed Iqbal Ullah Race Relations Resource Centre.
In 1986 Ahmed Iqbal Ullah was murdered by a fellow pupil in the grounds of his high school in Manchester. Very quickly, Ahmed the boy disappeared behind the story of his tragic death.
The story of his family and of his mother’s bravery and fortitude similarly became obscured.
‘Phyllis Bedells’ c. 1911. Rotary Photographic Series, Royal Academy of Dance.
The Anita White Foundation International Women and Sport Archive, c1936- [ongoing]
In 2010 the University of Chichester decided to establish an archive on the international women and sport movement. This decision was based on the potential donation of documents from Dr Anita White and Professor Celia Brackenridge, two individuals associated with the university who had been centrally involved in the leadership and development of the movement since 1990.
Papers of Georgiana Cavendish, Duchess of Devonshire (1757–1806)
Georgiana Cavendish (née Spencer), Duchess of Devonshire (1757–1806) is well-known as a style icon and also for her personal life. However, she was also actively involved in the Whig party. Following the resignation of William Pitt in 1801, she was instrumental in getting Fox and the Prince to settle their differences, as well as reuniting the different Whig factions into a force that could be co-ordinated. Whilst Pitt returned as Prime Minister in 1804, following his death in 1806, the new government – the ‘ministry of all the talents’ – largely consisted of the coalition that Georgiana had helped to build.
Elouise was born in 1932 in Guyana, South America. She travelled to England in 1961 to join her husband Beresford Edwards. They settled in Manchester and soon became active in the struggle against inequality and racism that existed at that time. They challenged racist attitudes and campaigned for the needs of people from overseas. This developed into a lifelong fight for equality. Elouise Edwards was instrumental in celebrating Black culture, battling racism and developing vital community resources in Moss Side. She was awarded an MBE for her amazing contribution. Elouise also has an African Chieftaincy. She was nominated for her work with African people in Manchester and the honour was bestowed by the Nigerian organisation at the British Council.
As a campaigner for Women’s Suffrage, Emily is arguably most famous for her death. She joined the Women’s Social and Political Union in 1906, soon becoming involved in a long series of arrests, imprisonments and releases after force-feeding. She managed to enter and hide in the House of Commons three times between 1910 and 1911, and was the first to embark on a campaign of setting fire to pillar-boxes. On the 4th June 1913, she tried to seize the bridle of the King’s horse running at the Derby. She received head injuries and never recovered consciousness, dying on the 8th June. Her funeral was preceded by a large funeral cortege that became one of the iconic events of the campaign for Women’s Suffrage.
Press photograph of women factory workers during WW1, Institution of Mechanical Engineers Archive.
The North’s Forgotten Female Reformers: Women’s suffrage and fight for reform and change throughout the UK, provided by Newcastle University Special Collections and Archives.
The back end of a new system usually involves a huge amount of work and this was very much the case for the Archives Hub, where we changed our whole workflow and approach to data processing (see The Building Blocks of the new Archives Hub), but it is the front end that people see and react to; the website is a reflection of the back end, as well as involving its own user experience challenges, and it reflects the reality of change to most of our users.
We worked closely with Knowledge Integration in the development of the system, and with Gooii in the design and implementation of the front end, and Sero ran some focus groups for us, testing out a series of wireframe designs on users. Our intention was to take full advantage of the new data model and processing workflow in what we provided for our users. This post explains some of the priorities and design decisions that we made. Additional posts will cover some of the areas that we haven’t included here, such as the types of description (collections, themed collections, repositories) and our plan to introduce a proximity search and a browse.
Speed is of the Essence
Faster response times were absolutely essential and, to that end, a solution based on an enterprise search solution (in this case Elasticsearch) was the starting point. However, in addition to the underlying search technology, the design of the data model and indexing structure had a significant impact on system performance and response times, and this was key to the architecture that Knowledge Integration implemented. With the previous system there was only the concept of the ‘archive’ (EAD document) as a whole, which meant that the whole document structure was always delivered to the user whatever part of it they were actually interested in, creating a large overhead for both processing and bandwidth. In the new system, each EAD record is broken down into many separate sections which are each indexed separately, so that the specific section in which there is a search match can be delivered immediately to the user.
To illustrate this with an example:-
A researcher searches for content relating to ‘industrial revolution’ and this scores a hit on a single item 5 levels down in the archive hierarchy. With the previous system the whole archive in which the match occurs would be delivered to the user and then this specific section would be rendered from within the whole document, meaning that the result could not be shown until the whole archive has been loaded. If the results list included a number of very large archives the response time increased accordingly.
In the new system, the matching single item ‘component’ is delivered to the user immediately, when viewed in either the result list or on the detail page, as the ability to deliver the result is decoupled from archive size. In addition, for the detail page, a summary of the structure of the archive is then built around the item to provide both the context and allow easy navigation.
Even with the improvements to response times, the tree representation (which does have to present a summary of the whole structure), for some very large multi-level descriptions takes a while to render, but the description itself always loads instantly. This means that that the researcher can always see they have a result immediately and view it, and then the archival structure is delivered (after a short pause for very large archives) which gives the result context within the archive as a whole.
The system has been designed to allow for growth in both the number of contributors we can support and the number of end-users, and will also improve our ability to syndicate the content to both Archives Portal Europe and deliver contributors own ‘micro sites‘.
Look and Feel
Some of the feedback that we received suggested that the old website design was welcoming, but didn’t feel professional or academic enough – maybe trying to be a bit too cuddly. We still wanted to make the site friendly and engaging, and I think we achieved this, but we also wanted to make it more professional looking, showing the Hub as an academic research tool. It was also important to show that the Archives Hub is a Jisc service, so the design Gooii created was based upon the Jisc pattern library that we were required to use in order to fit in with other Jisc sites.
We have tried to maintain a friendly and informal tone along with use of cleaner lines and blocks, and a more visually up-to-date feel. We have a set of consistent icons, on/off buttons and use of show/hide, particularly with the filter. This helps to keep an uncluttered appearance whilst giving the user many options for navigation and filtering.
In response to feedback, we want to provide more help with navigating through the service, for those that would like some guidance. The homepage includes some ‘start exploring’ suggestions for topics, to help get inexperienced researchers started, and we are currently looking at the whole ‘researching‘ section and how we can improve that to work for all types of users.
Navigating
We wanted the Hub to work well with a fairly broad search that casts the net quite widely. This type of search is often carried out by a user who is less experienced in using archives, or is new to the Hub, and it can produce a rather overwhelming number of results. We have tried to facilitate the onward journey of the user through judicious use of filtering options. In many ways we felt that filtering was more important than advanced search in the website design, as our research has shown that people tend to drill down from a more general starting point rather than carry out a very specific search right from the off. The filter panel is up-front, although it can be hidden/shown as desired, and it allows for drilling down by repository, subject, creator, date, level and digital content.
Another way that we have tried to help the end user is by using typeahead to suggest search results. When Gooii suggested this, we gave it some thought, as we were concerned that the user might think the suggestions were the ‘best’ matches, but typeahead suggestions are quite a common device on the web, and we felt that they might give some people a way in, from where they could easily navigate through further descriptions.
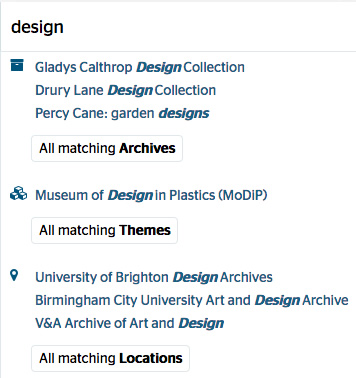
A search for ‘design’ with suggested results
The suggestions may help users to understand the sort of collections that are described on the Hub. We know that some users are not really aware of what ‘archives’ means in the context of a service like the Archives Hub, so this may help orientate them.
Suggested results also help to explain what the categories of results are – themes and locations are suggested as well as collection descriptions.
We thought about the usability of the hit list. In the feedback we received there was no clear preference for what users want in a hit list, and so we decided to implement a brief view, which just provides title and date, for maximum number of results, and also an expanded view, with location, name of creator, extent and language, so that the user can get a better idea of the materials being described just from scanning through the hit list.
Expanded mode gives the user more information
With the above example, the title and date alone do not give much information, which is particularly common with descriptions of series or items, of so the name of creator adds real value to the result.
Seeing the Wood Through the Trees
The hierarchical nature of archives is always a challenge; a challenge for cataloguing, processing and presentation. In terms of presentation, we were quite excited by the prospect of trying something a bit different with the new Hub design. This is where the ‘mini map’ came about. It was a very early suggestion by K-Int to have something that could help to orientate the user when they suddenly found themselves within a large hierarchical description. Gooii took the idea and created a number of wireframes to illustrate it for our focus groups.
For instance, if a user searches on Google for ‘conrad slater jodrell bank’ then they get a link to the Hub entry:
Result of a search on Google
The user may never have used archives, or the Archives Hub before. But if they click on this link, taking them directly to material that sits within a hierarchical description, we wanted them to get an immediate context.
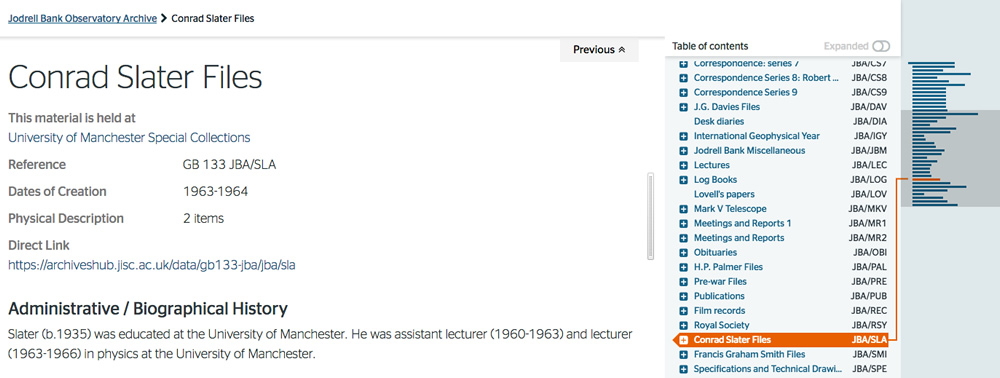
Jodrell Bank Observatory Archives: Conrad Slater Files
The page shows the description itself, the breadcrumb to the top level, the place in the tree where these particular files are described and a mini map that gives an instant indication of where this entry is in the whole. It is intended (1) to give a basic message for those who are not familiar with archive collections – ‘there is lots more stuff in this collection’ and (2) to provide the user with a clearly understandable expanding tree for navigation through this collection.
One of the decision we made, illustrated here, was to show where the material is held at every level, for every unit of description. The information is only actually included at the top level in the description itself, but we can easily cascade it down. This is a good illustration of where the approach to displaying archive descriptions needs to be appropriate for the Web – if a user comes straight into a series or item, you need to give context at that level and not just at the top level.
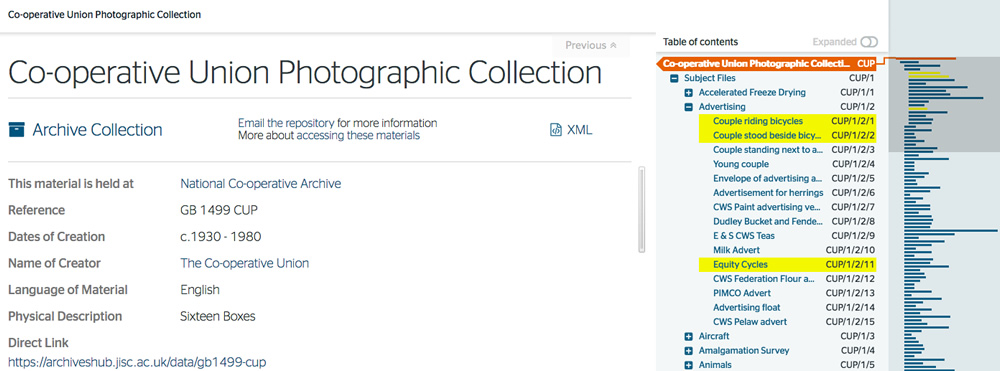
The design also works well for searches within large hierarchical descriptions.
Search for ‘bicycles’ within the Co-operative Union Photographic Collection
The user can immediately get a sense of whether the search has thrown up substantial results or not. In the example above you can see that there are some references to ‘bicycles’ but only early on in the description. In the example below, the search for ‘frost on sunday’ shows that there are many references within the Ronnie Barker Collection.
Search within the Ronnie Barker Collection for ‘frost on sunday’
One of the challenges for any archive interface is to ensure that it works for experienced users and first-time users. We hope that the way we have implemented navigation and searching mean that we have fulfilled this aim reasonably well.
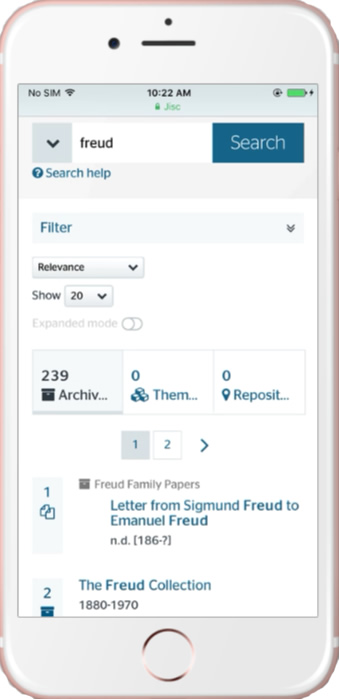
Small is Beautiful
The Archives Hub on an iPhone
The old site did not work well on mobile devices. It was created before mobile became massive, and it is quite hard to retrospectively fit a design to be responsive to different devices. Gooii started out with the intention of creating a responsive design, so that it renders well on different sized screens. It requires quite a bit of compromise, because rendering complex multi-level hierarchies and very detailed catalogues on a very small screen is not at all easy. It may be best to change or remove some aspects of functionality in order to ensure the site makes sense. For example, the mobile display does not open the filter by default, as this would push the results down the page. But the user can open the filter and use the faceted search if they choose to do so.
We are particularly pleased that this has been achieved, as something like 30% of Hub use is on mobiles and tablets now, and the basic search and navigation needs to be effective.
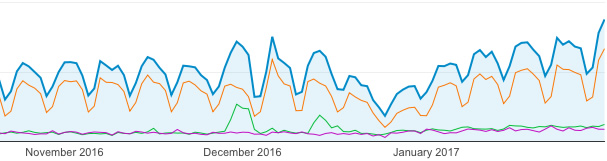
Devices used to view the Hub site over a three month period
In the above graph, the orange line is desktop, the green is mobile and the purple is tablet. (the dip around the end of December is due to problems setting up the Analytics reporting).
Cutting Our Cloth
One of the lessons we have learnt over 15 years of working on the Archives Hub is that you can dream up all of the interface ideas that you like, but in the end what you can implement successfully comes down to the data. We had many suggestions from contributors and researchers about what we could implement, but oftentimes these ideas will not work in practice because of the variations in the descriptions.
We though about implementing a search for larger, medium sized or smaller collections, but you would need consistent ‘extent’ data, and we don’t have that because archivists don’t use any kind of controlled vocabulary for extent, so it is not something we can do.
When we were running focus groups, we talked about searching by level – collection, series, sub-series, file, item, etc. For some contributors a search by a specific level would be useful, but we could only implement three levels – collection (or ‘top level’), item (which includes ‘piece’) and then everything between these, because the ‘in-between’ levels don’t lend themselves to clear categorisation. The way levels work in archival description, and the way they are interpreted by repositories, means we had to take a practical view of what was achievable.
We still aren’t completely sold on how we indicate digital content, but there are particular challenges with this. Digital content can be images that are embedded within the description, links to images, or links to any other digital content imaginable. So, you can’t just use an image icon, because that does not represent text or audio. We ended up simply using a tick to indicate that there is digital content of some sort. However, one large collection may have links to only one or two digital items, so in that case the tick may raise false expectations. But you can hardly say ‘includes digital content, but not very much, so don’t get too excited’. There is room for more thought about our whole approach to digital content on the Hub, as we get more links to digital surrogates and descriptions of born-digital collections.
Statistics
The outward indication of a more successful site is that use goes up. The use of statistics to give an indication of value is fraught with problems. Do the number of clicks represent value? Might more clicks indicate a poorer user interface design? Or might they indicate that users find the site more engaging? Does a user looking at only one description really gain less value than a user looking at ten descriptions? Clearly statistics can only ever be seen as one measure of value, and they need to be used with caution. However, the reality is that an upward graph is always welcomed! Therefore we are pleased to see that overall use of the website is up around 32% compared to this period during the previous year.
Jan 2016 (the orange line) and Jan 2017 (the blue line), which shows typical daily use above 2,000 page views.
Feedback
We are pleased to say that the site has been very well received…
“The new site is wonderful. I am so impressed with its speed and functionality, as well as its clean, modern look.” (University Archivist)
“…there are so many other features that I could pick out, such as the ability to download XML and the direct link generator for components as well as collections, and the ‘start exploring’ feature.” (University Archivist)
“Brand new Archives Hub looks great. Love how the ‘explorer themes’ connect physically separated collections” (Specialist Repository Head of Collections)
“A phenomenal achievement!” (Twitter follower)
With thanks to Rob Tice from Knowledge Integration for his input to this post.
Stacy Capner reflects on her first six months as Project Officer for the Archives Wales Catalogues Online project, a collaboration between the Archives and Records Council Wales and the Archives Hub to increase the discoverability of Welsh archives.
For a few years now there has been a strategic goal to get Wales’ archive collections more prominently ‘out there’ using the Archives Wales website. Collection level descriptions have been made available previously through the ‘Archives Network Wales’ project, but the aim now is to create a single portal to search and access multi-level descriptions from across services. The Archives Hub has an established, standards based way of doing this, so instead of re-inventing the wheel, Archives and Records Council Wales (ARCW) saw an opportunity to work with them to achieve these aims.
The work to take data from Welsh Archives into the Archives Hub started some time ago, but it became clear that getting exports from different systems and working with different cataloguing practices required more dedicated 1-2-1 liaison. I am the project officer on a defined project which began in April to provide dedicated support to archive services across Wales and to establish requirements for uploading their catalogue data to the Archives Hub (and subsequently to Archives Wales).
This project is supported by the Welsh Government through its Museums Archives and Libraries Division, with a grant to Swansea University, a member of ARCW and a long-standing contributor to the Hub. I’m on secondment from the University to the project, which means I’ve found myself back in my northern neck of the woods working alongside the Archives Hub team. This project has come at a time when the Archives Hub have been putting a lot of thought into their processes for uploading data straight from systems, which means that the requirements for Welsh services have started to define an approach which could be applied to archive services across Scotland, England and Northern Ireland.
Here are my reflections on the project so far:
Wales has fantastic collections, holding internationally significant material. They deserve to be promoted, accessible and searchable to as wide an audience as possible. Some examples-
National Library of Wales, The Survey of the Manors of Crickhowell & Tretower (inscribed in the UNESCO Memory of the World Register, 2016) https://www.llgc.org.uk/blog/?p=11715
Photograph of Ammanford colliers and workmen standing in front of anthracite truck, c 1900. From the South Wales Coalfield Collection. Source: Richard Burton Archives, Swansea University (Ref: SWCC/PHO/COL/11)
Don’t be scared of EAD ! I was. My knowledge of EAD (Encoded Archival Description) hadn’t been refreshed in 10 years, since Jane Stevenson got us to create brownie recipes using EAD tags on the archives course. So, whilst I started the task with confidence in cataloguing and cataloguing systems, my first month or so was spent learning about the Archives Hub EAD requirements. For contributors, one of the benefits of the Archives Hub is that they’ve created guidance, tools and processes so that archivists don’t have to become experts at creating or understanding EAD (though it is useful and interesting, if you get the chance!).
The Archives Hub team are great! Their contributor numbers are growing (over 300 now) and their new website and editor are only going to make it easier for archive services to contribute and for researchers to search. What has struck me is that the team are all hot on data, standards and consistency, but it’s combined with a willingness to find solutions/processes which won’t put too much extra pressure on archive services wishing to contribute. It’s a balance that seems to work well and will be crucial for this project.
The information gathering stage was interesting. And tiring. I visited every ARCW member archive service in Wales to introduce them to the project, find out what cataloguing systems they were using, and to review existing electronic catalogues. Most services in Wales are using Calm, though other systems currently being used include internally created databases, AtoM, Archivists Toolkit and Modes. It was really helpful to see how fields were being used, how services had adapted systems to suit them, and how all of this fitted in to Archives Hub requirements for interoperability.
Perks of working visits to beautiful parts of Wales.
The support stage is set to be more interesting. And probably more tiring! The next 6 months will be spent providing practical support to services to help enable their catalogues to meet Archives Hub requirements. I’ll be able to address most of the smaller, service specific, tasks on site visits. The Hub team and I have identified a number of trickier ‘issues’ which we’ll hash out with further meetings and feedback from services. I can foresee further blog posts on these so briefly they are:
Multilingualism- most services catalogue Welsh items/collections in Welsh, English items/collections in English and multi-language item/collections bilingually. However, the method of doing this across services (and within services) isn’t consistent. We’re going to look at what can be done to ensure that descriptions in multiple languages are both human and machine readable.
Ref no/Alt ref- due to legacy issues with non-hierarchical catalogues, or just services personal preference, there are variations in the use of these fields. Some services use the ref no as the reference, others use the alt ref no as the reference. This isn’t a problem (as long as it’s consistent). Some services use ref no as the reference but not at series level, others use the alt ref no as the reference but not at series level. This will prove a little trickier for the Archives Hub to handle but hopefully workarounds for individual services will be found.
Extent fields missing- this is a mandatory field at collection level for the Archives Hub. It’s important to give researchers an idea of the size of the collection/series (it’s also an ISAD(G) required field). However, many services have hundreds of collection level descriptions which are missing extent. It’s not something I’ll practically be able to address on my support visits so the possibility of further work/funding will be looked into.
Indexing- this is understandably very important to the Archives Hub (they explain why here). For several archive services in Wales it seems to have been a step too far in the cataloguing process, mainly due to a lack of resource/time/training. Most have used imported terms from an old database or nothing at all. Although this will not prevent services from contributing catalogues to the Archives Hub, it does open up opportunities to think about partnership projects which might address this in the future (including looking at Welsh language index terms).
The project has made me think about how I’ve catalogued in the past. It’s made me much more aware that catalogues shouldn’t just be an inward-facing, local or an intellectual control based task; we should be constantly aware of making our descriptions more discoverable to researchers. And it’s shown me the importance of standards and consistency in achieving this (I feel like I’ve referenced consistency a lot in this one blog post; consistency is important!). I hope that the project is also prompting Welsh archive services to reflect on the accessibility of their own cataloguing- something which might not have been looked at in many years.
There’s a lot of work to be done, both in this foundation work and further funding/projects which might come of the back of it. But hopefully in the next few years you’ll be discovering much more of Wales’ archive collections online.
Stacy Capner Project Officer Archives Wales Catalogues Online
In the ArchivesGrid analysis, the <unitdate> field use is around 72% within the high-level (usually collection level) description. The Archives Hub does significantly better here, with an almost universal inclusion of dates at this level of description. Therefore, a date search is not likely to exclude any potentially relevant descriptions. This is important, as researchers are likely to want to restrict their searches by date. Our new system also allows sorting retrieved results by date. The only issue we have is where the dates are non-standard and cause the ordering to break down in some way. But we do have both displayed dates and normalised dates, to enable better machine processing of the data.
Collection Title
“for sorting and browsing…utility depends on the content of the element.”
Titles are always provided, but they are very varied. Setting aside lower-level descriptions, which are particularly problematic, titles may be more or less informative. We may introduce sorting by title, but the utility of this will be limited. It is unlikely that titles will ever be controlled to the extent that they have a level of consistency, but it would be fascinating to analyse titles within the context of the ways people search on the Web, and see if we can gauge the value of different approaches to creating titles. In other words, what is the best type of title in terms of attracting researchers’ attention, search engine optimisation, display within search engine results, etc?
Lower-level descriptions tend to have titles such as ‘Accounts’, ‘Diary’ or something more difficult to understand out of context such as ‘Pigs and boars’ or ‘The Moon Dragon’. It is clearly vital to maintain the relationship of these lower-level descriptions to their parent level entries, otherwise they often become largely meaningless. But this should be perfectly possible when working on the Web.
It is important to ensure that a researcher finding a lower-level description through a general search engine gets a meaningful result.
A search result within Google
The above result is from a search for ‘garrick theatre archives joanna lumley’ – the sort of search a researcher might carry out. Whilst the link is directly to a lower -level entry for a play at the Garrick Theatre, the heading is for the archive collection. This entry is still not ideal, as the lower-level heading should be present as well. But it gives a reasonable sense of what the researcher will get if they click on this link. It includes the <unitid> from the parent entry and the URL for the lower-level, with the first part of the <scopecontent> for the entry. It also includes the Archives Hub tag line, which could be considered superfluous to a search for Garrick Theatre archives! However, it does help to embed the idea of a service in the mind of the researcher – something they can use for their research.
Extent
“It would be useful to be able to sort by size of collection, however, this would require some level of confidence that the <extent> tag is both widely used and that the content of the tag would lends itself to sorting.”
This was an idea we had when working on our Linked Data output. We wanted to think about visualizations that would help researchers get a sense of the collections that are out there, where they are, how relevant they are, and so on. In theory the ‘extent’ could help with a weighting system, where we could think about a map-based visualization showing concentrations of archives about a person or subject. We could also potentially order results by size – from the largest archive to the smallest archive that matches a researchers’ search term. However, archivists do not have any kind of controlled vocabulary for ‘extent’. So, within the Archives Hub this field can contain anything from numbers of boxes and folders to length in linear metres, dimensions in cubic metres and items in terms of numbers of photographs, pamphlets and other formats. ISAD(G) doesn’t really help with this; the examples they give simply serve to show how varied the description of extent can be.
Genre
“Other examples of desired functionality include providing a means in the interface to limit a search to include only items that are in a certain genre (for example, photographs)”.
This is something that could potentially be useful to researchers, but archivists don’t tend to provide the necessary data. We would need descriptions to include the genre, using controlled vocabulary. If we had this we could potentially enable researchers to select types of materials they are interested in, or simply include a flag to show, e.g. where a collection includes photographs.
The problem with introducing a genre search is that you run the risk of excluding key descriptions, because the search will only include results where the description includes that data in the appropriate location. If the word ‘photograph’ is in the general description only then a specific genre search won’t find it. This means a large collection of photographs may be excluded from a search for photographs.
Subject
In the Bron/Proffitt/Washburn article <controlaccess> is present around 72% of the time. I was surprised that they did not choose to analyse tags within <controlaccess> as I think these ‘access points’ can play a very important role in archival descrpition. They use the presence of <controlaccess> as an indication of the presence of subjects, and make the point that “given differences in library and archival practices, we would expect control of form and genre terms to be relatively high, and control of names and subjects to be relatively low.”
On the Archives Hub, use of subjects is relatively high (as well as personal and corporate names) and use of form and genre is very low. However, it is true to say that we have strongly encouraged adding subject terms, and archivists don’t generally see this as integral to cataloguing (although some certainly do!), so we like to think that we are partly responsible for such a high use of subject terms.
Subject terms are needed because they (1) help to pull out significant subjects, often from collections that are very diverse, (2) enable identification of words such as ‘church’ and ‘carpenter’ (ie. they are subjects, not surnames), (3) allow researchers to continue searching across the Archives Hub by subject (subjects are all linked to the browse list) and therefore pull collections together by theme (4) enable advanced searching (which is substantially used on the Hub).
Names (personal and corporate)
In Bron/Proffitt/Washburn the <origination> tag is present 87% of the time. The analysis did not include the use of <persname> and <corpname> within <origination> to identify the type of originator. In the Archives Hub the originator is a required field, and is present 99%+ of the time. However, we made what I think is a mistake in not providing for the addition of personal or corporate name identification within <origination> via our EAD Editor (for creating descriptions) or by simply recommending it as best practice. This means that most of our originators cannot be distinguished as people or corporate bodies. In addition, we have a number where several names are within one <origination> tag and where terms such as ‘and others’, ‘unknown’ or ‘various’ are used. This type of practice is disadvantageous to machine processing. We are looking to rectify it now, but addressing something like this in retrospect is never easy to do. The ideal is that all names within origination are separately entered and identified as people or organisations.
We do also have names within <controlaccess>, and this brings the same advantages as for <subjects>, ensuring the names are properly structured, can be used for searching and for bringing together archives relating to any one individual or organisation.
Repository
“Use of this element falls into the promising complete category (99.46%: see Table 7). However, a variety of practice is in play, with the name of the repository being embellished with <subarea> and <address> tags nested within <repository>.”
On the Archives Hub repository is mandatory, but as yet we do not have a checking system whereby a description is rejected if it does not contain this field. We are working towards something like this, using scripts to check for key information to help ensure validity and consistency at least to a minimum standard. On one occasion we did take in a substantial number of descriptions from a repository that omitted the name of repository, which is not very useful for an aggregation service! However, one thing about <repository> is that it is easy to add because it is always the same entry. Or at least it should be….we did recently discovery that a number of repositories had entered their name in various ways over the years and this is something we needed to correct.
Scope and content, biographical history and abstract
It is notable that in the US <abstract> is widely used, whereas we don’t use it at all. It is intended as a very brief summary, whereas <scopecontent> can be of any length.
“For search, its worth noting that the semantics of these elements are different, and may result in unexpected and false “relevance””
One of the advantages of including <controlaccess> terms is to mitigate against this kind of false relevance, as a search for ‘mason’ as a person and ‘mason’ as a subject is possible through restricted field searching.
The Bron/Proffitt /Washburn analysis shows <bioghist> used 70% of the time. This is lower than the Archives Hub, where it is rare for this field not to be included. Archivists seem to have a natural inclination to provide a reasonably detailed biographical history, especially for a large collection focussed on one individual or organisation.
Digital Archival Objects
It is a shame that the analysis did not include instances of <dao>, but it is likely to be fairly low (in line with previous analysis by Wisser and Dean, which puts it lower than 10%). The Archives Hub currently includes around 1,200 instances of images or links to digital content. But what would be interesting is to see how this is growing over time and whether the trajectory indicates that in 5 years or so we will be able to provide researchers with routes into much of the Archives Hub content. However, it is worth bearing in mind that many archives are not digitised and are not likely to be digitised, so it is important for us not to raise expectations that links to digital content will become a matter of course.
The Future of Discovery
“In order to make EAD-encoded finding aids more well suited for use in discovery systems, the population of key elements will need to be moved closer to high or (ideally) complete.”
This is undoubtedly true, but I wonder whether the priority over and above completeness is consistency and controlled vocabulary where appropriate. There is an argument in favour of a shorter description, that may exclude certain information about a collection, but is well structured and easier to machine process. (Of course, completeness and consistency is the ideal!).
The article highlights geo-location as something that is emerging within discovery services. The Archives Hub is planning on promoting this as an option once we move to the revised EAD schema (which will allow for this to be included), but it is a question of whether archivists choose to include geographical co-ordinates in their catalogues. We may need to find ways to make this as easy as possible and to show the potential benefits of doing so.
In terms of the future, we need a different perspective on what EAD can and should be:
“In the early days of EAD the focus was largely on moving finding aids from typescript to SGML and XML. Even with much attention given over to the development of institutional and consortial best practice guidelines and requirements, much work was done by brute force and often with little attention given to (or funds allocated for) making the data fit to the purpose of discovery.”
However, I would argue that one of the problems is that archivists sometimes still think in terms of typescript finding aids; of a printed finding aid that is available within the search room, and then made available online….as if they are essentially the same thing and we can use the same approach with both. I think more needs to be done to promote, explain and discuss ‘next generation finding aids’. By working with Linked Data, I have gained a very different perspective on what is possible, challenging the traditional approach to hierarchical finding aids.
Maybe we need some ‘next generation discovery’ workshops and discussions – but in order to really broaden our horizons we will need to take heed of what is going on outside of our own domain. We can no longer consider archival practice in isolation from discovery in the most general sense because the complexity and scale of online discovery requires us to learn from others with expertise and understanding of digital technologies.
A HEFCE study from 2010 states that “96% of students use the internet as a source of information” (1). This makes me wonder about the 4% that don’t; it’s not an insignificant number. The same study found that “69% of students use the internet daily as part of their studies”, so 31% don’t use it on a daily basis (which I take to mean ‘very frequently’).
There have been many reports on the subject of technology and its impact on learning, teaching and education. This HEFCE/NUS study is useful because it concentrates on surveying students rather than teachers or information professionals. One of the key findings is that it is important to think about the “effective use of technology” and “not just technology for technology’s sake”. Many students still find conventional methods of teaching superior (a finding that has come up in other studies), and students prefer a choice in how they learn. However, the potential for use of ICT is clear, and the need to engage with it is clear, so it is worrying that students believe that a significant number of staff “lack even the most rudimentary IT skills”. It is hardy surprising that the experiences of students vary considerably when they are partly dependent upon the skills and understanding of their teachers, and whether teachers use technology appropriately and effectively.
At the recent ELAG conference I gave a joint presentation with Lukas Koster, a colleague from the University of Amsterdam, in which we talked about (and acted out via two short sketches) the gap between researchers’ needs and what information professionals provide. Thinking simply about something as seemingly obvious as the understanding and use of
Random selection of interface terminology from archives sites.
the term ‘archives’ is a good case in point. Should we ensure that students understand the different definitions of archives? The distinction between archives that are collections with a common provenance and archives that are artificial collections? The different characters of archives that are datasets, generally used by social scientists? The “abuse” of the term archives for pretty much anything that is stored in any kind of longer-term way? Should users understand archival arrangement and how to drill down into collections? Should they understand ‘fonds’, ‘manuscripts’, ‘levels’, ‘parent collection’? Or is it that we should think more about how to translate these things into everyday language and simple design, and how to work things like archival hierarchy into easy-to-use interfaces? I think we should take the opportunities that technology provides to find ways to present information in such a way that we facilitate the user experience. But if students are reporting a lack of basic ICT skills amongst teachers, you have to wonder whether this is a problem within the archive and library sector as well. Do information professionals have appropriate ICT skills fit for ensuring that we can tailor our services to meet the needs of the technically savvy user?
Should we be teaching information literacy to students? One of the problems with this idea is that they tend to think they are already pretty literate in terms of use of the internet. In the HEFCE report, a survey of 213 FE students found that 88% felt they were effective online researchers and the majority said they were self-taught. They would not be likely to attend training on how to use the internet. And there is a question over whether they need to be taught how to use it in the ‘right’ way, or whether information professionals should, in fact, work with the reality of how it is being used (even if it is deemed to be ‘wrong’ in some way). Students are clear that they do want training “around how to effectively research and reference reliable online resources”, and maybe this is what we should be concentrating on (although it might be worth considering what ‘effective use of the internet’ and ‘effective research using the internet’ actually mean). Maybe this distinction highlights the problem with how to measure effective use of the internet, and how to define online or discovery skills.
A British Library survey from 2010 found that “only a small proportion [of students] …are using technology such as virtual-research environments, social bookmarking, data and text mining, wikis, blogs and RSS-feed alerts in their work.” This is despite the fact that many respondents in the survey said they found such tools valuable. This study also showed that students turn to their peers or supervisors rather than library staff for help.
Part of the problem may be that the vast majority of users use the internet for leisure purposes as well as work or study, so the boundaries can become blurred, and they may feel that they are adept users without distinguishing between different types of use. They feel that they are ‘fine with the technology’, although I wonder if that could be because they spend hours playing World of Warcraft, or use Facebook or Twitter every day, or regularly download music and watch YouTube. Does that mean they will use technology in an effective way as part of their studies? The trouble is that if someone believes that they are adept at searching, they may not go that extra mile to reflect on what they are doing and how effective it really is. Do we need to adjust our ways of thinking to make our resources more user-friendly to people coming from this kind of ‘I know what I’m doing’ mindset, or do we have to disabuse them of this idea and re-train them (or exhort them to read help pages for example…which seems like a fruitless mission)? Certainly students have shown some concern over “surface learning” (skim reading, learning only the minimum, and not getting a broader understanding of issues), so there is some recognition of an issue here, and the tendency to take a superficial approach might be reinforced if we shy away from providing more sophisticated tools and interfaces.
The British Library report on the Information Behaviour of the Researcher of the Future reinforces the idea that there is a gulf between students’ assumptions regarding their ICT skills versus the reality, which reveals a real lack of understanding. It also found a significant lack of training in discovery and use of tools for postgraduate students. Studies like this can help us think about how to design our websites, and provide tools and services to help researchers using archives. We have the challenges of how to make archives more accessible and easy to discover as well as thinking about how to help students use and interpret them effectively: “The college students of the open source, open content era will distinguish themselves from their peers and competitors, not by the information they know, but by how well they convert that knowledge to wisdom, slowly and deeply internalized.” (Sheila Stearns, “Literacy in the University of 2025: Still A Great Thing‟, from The Future of Higher Education , ed. by Gary Olson & John W Presley, (Boulder: Paradigm Publishers, 2009) pp. 98-99).
What are the Solutions?
We should make user testing more integral to the development of our interfaces. It requires resource, but for the Archives Hub we found that even carrying out 10 one-hour interviews with students and academics helped us to understand where we were making assumptions and how we could make small modifications that would improve our site. And our annual online survey continues to provide really useful feedback which we use to adjust our interface design, navigation and terminology. We can understand more about our users, and sometimes our assumptions about them are challenged.
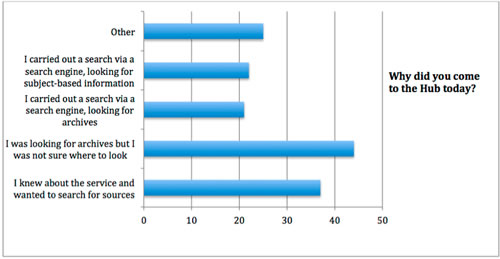
Archives Hub survey 2013: Why did you come to the Hub today?
User groups for commercial software providers can petition to ensure that out-of-the-box solutions also meet users’ needs and take account of the latest research and understanding of users’ experiences, expectations and preferences in terms of what we provide for them. This may be a harder call, because vendors are not necessarily flexible and agile; they may not be willing to make radical changes unless they see a strong business case (i.e. income may be the strongest factor).
We can build a picture of our users via our statistics. We can look at how users came into the site, the landing pages, where they went from there, which pages are most/least popular, how long they spent on individual pages, etc. This can offer real insights into user behaviour. I think a few training sessions on using Google Analytics on archive sites could come in handy!
We can carry out testing to find out how well sites rank on search engines, and assess the sort of experience users get when they come into a specialist site from a general search engine. What is the text a Google search shows when it finds one of your collections? What do people get to when they click on that link? Is it clear where they are and what they can do when they get to your site?
* * *
This is the only generation where the teachers and information professionals have grown up in a pre-digital world, and the students (unless they are mature students) are digital natives. Of course, we can’t just sit back and wait a generation for the teachers and information professionals to become more digitally minded! But it is interesting to wonder whether in 25 years time there will be much more consensus in approaches to and uses of ICT, or whether the same issues will be around.
Nigel Shadbolt has described the Web as “one of the most disruptive innovations we have ever witnessed” and at present we really seem to be struggling to find out how best to use it (and not use it), how and when to train people to use it and how and when to integrate it into teaching, learning and research in an effective way.
It seems to me that there are so many narratives and assessments at present – studies and reports that seem to run the gamut of positive to negative. Is technology isolating or socialising? Are social networks making learning more superficial or enabling richer discussion and analysis? Is open access democratising or income-reducing? Is the high cost of technology encouraging elitism in education? Does the fact that information is so easily accessible mean that researchers are less bothered about working to find new sources of information? With all these types of debates there is probably no clear answer, but let us hope we are moving forward in understanding and in our appreciation of what the Web can do to both enhance and transform learning, teaching and research.
This post picks out some highlights from a report from Ithaka S+R, “Supporting the Changing Research Practices of Historians” by Roger C Schonfeld and Jennifer Rutner (December 2012). It concentrates on findings that are of particular relevance for archivists and for discovery. The report is recommended reading. It is a US study, but clearly there are strong similarities with other countries.
The report finds that underlying research methods are still broadly as they were but practices have changed considerably: “Based on interviews with dozens of historians, librarians, archivists, and other support services providers, this project has found that the underlying research methods of many historians remain fairly recognizable even with the introduction of new tools and technologies, but the day to day research practices of all historians have changed fundamentally.”
It goes on to summarise the improvements that archives might make to meet changing needs, none of which are unexpected: “For archives, we recommend ongoing improvements to access through improved finding aids, digitization, and discovery tool integration, as well as expanded opportunities for archivists to help historians interpret collections, to build connections among users, and to instruct PhD students in the use of archives.”
It is very encouraging to see the positive comments about researchers’ interactions with archivists: “Having a meeting with the archivist and librarian is really fantastic, because they help you understand what is in the archive, and what you might be able to use.” It is clear from the study that archivists have a vital role to play as key collaborators and colleagues of historians, and their value is clear: “Archivists are often able to hone and direct an inquiry, bringing to light items and collections that the researcher may have been unaware of.”
The study does highlight the changing nature of interactions with archival material, as a result of the use of digital cameras in particular, which enables the analytical work to take place elsewhere. It is generally felt to be a convenient and time-saving option, enabling long-term interaction with resources outside of the reading room. This development is actually described as “the single most significant shift in research practices among historians.” It raises questions about whether the role of the archivist changes when the analytical work is displaced from the archive, as archivists may have less opportunity for intellectual engagement with researchers. The study does highlight a possible issue with digital copies, namely the separation of metadata from content, where the researcher has hundreds of images and needs to organise them constructively, and it also found that scholars are struggling to work with digitised non-textual content effectively.
The ability to find time for research trips was a primary challenge for many researchers. “Interviewees repeatedly emphasized that the amount of time they are able to spend in the archives shapes the nature of the interaction with the sources significantly.” Because most struggle to find time for research trips, digitised sources are hugely beneficial.
The study found that digitised finding aids help researchers to “travel more strategically”. It suggests that high-quality finding aids may become more important as researchers move more towards photographic visits to archives, rather than serendipitous visits. This connection is something I have not thought about before, and I would be very interested to hear what archivists think about this idea.
Of major relevance for a service like the Archives Hub is the conclusion about finding aids:
“The use of online finding aids greatly facilitates, and sometimes displaces, these visits. If a “good” finding aid is readily available online, this might make a scouting visit unnecessary, depending on the importance of the archive to the research project. In some cases, researchers were able to rule out a visit to an archive based on the online finding aids, and re-purpose funds and effort to tracking down other sources for the project.”
This study is a clear endorsement for our belief (which, I should say, is also backed up by our own researcher surveys) that finding aids play a role not only in identifying and prioritising sources, but also in providing enough information in themselves to make a visit unnecessary. As well as this, they may have a kind of positive negative effect: the researcher knows that materials can be ruled out. The study strongly emphasised the need for “searchable databases” and “centralized searching” and participants talked about the problem with locating each collection independently, especially across the diverse types of archive repository: “The process of identifying archives – in some cases small, local archives or international archives – can present an amazing challenge to researchers.” Clearly comprehensive cross-searching search tools are a huge boon to researchers.
In terms of discovery, Google is clearly a major tool and there was a feeling that it was the most comprehensive discovery tool, as well as being convenient and easy to use. It is often used at the start of a searching process.: “Generally, historians discover finding aids through Google searches and archive websites.” There is a clear demand for more descriptions online: “The general consensus among interviewees was that more online finding aids would greatly benefit their research, and that archives should continue to make efforts to make these accessible online. Continued and expanded efforts to develop finding aids more efficiently and to make them available digitally would seem to support the needs of historians for improved access.”
In terms of PhD students (and maybe others who are inexperienced researchers), the study found issues with the use of archives and other sources:
“Interviews with PhD candidates indicated that there is often little support for them in learning about new research methods or practices, either in their department or elsewhere at their institution, of which they are aware. While the subject matter treated by historians continues to diversify dramatically, new methodologies develop, and research practices change rapidly, it is clearly critically important that students have a grounding in the methods and practices of the field.” The Archives Hub has recently produced a brief Guide to Using Archives for the Inexperienced, and discussions on the archives email list showed just how much this is an important topic for archivists and how there was a general consensus that PhD students need more training on research methodologies.
Summing up, the report makes six recommendations specifically for Archives:
1. More online finding aids
2. More digitisation
3. Discovery tools that promote cross-searching, crossing institutional boundaries and encompassing small and local record offices
4. Adequate resources for ensuring the expertise of the archivist continues to be available, enabling archivists to be active interpreters of the collections
5. Adapting to and facilitating the use of digital cameras and scanners in reading rooms
6. Training PhD students in the use of archives
There is a great deal more of interest and relevance in the report around searching, Google Scholar, the use of the academic library, organising and managing research, citation management and digital research methods. It is very well worth reading.
This is something that I’ve thought about quite a bit, as I work as the manager of an online service for Archives and I do training and teaching for archivists and archive students around creating online descriptions. I would like to direct this blog post to archive students or those considering becoming archivists. I think this applies equally to records managers, although sometimes they have a more defined role in terms of audience, so the perspective may be somewhat different.
It’s fine if you have ‘a love of history’, if you ‘feel a thrill when handling old documents’. That’s a good start. I’ve heard this kind of thing frequently as a motivation for becoming an archivist. But this is not enough. It is more important to have the desire to make those archives available to others; to provide a service for researchers. To become an archivist is to become a service provider, not an historian. It may not sound as romantic, but as far as I am concerned it is what we are, and we should be proud of the service we provide, which is extremely valuable to society. Understanding how researchers might use the archives is, of course, very important, so that you can help to support them in their work. Love of the materials, and love of the subject (especially in a specialist repository) should certainly help you with this core role. Indeed, you will build an understanding of your collections, and become more expert in them over time, which is one of the wonderful things about being an archivist.
Your core role is to make archives available to the community – for many of us, the community is potentially anyone, for some of us it may be more restricted in scope. So, you have an interest in the materials, you need to make them available. To do this you need to understand the vital importance of cataloguing. It is this that gives people a way in to the archives. Cataloguing is a real skill, not something to be dismissed as simply creating a list of what you have. It is something to really work on and think about. I have seen enough inconsistent catalogues over the last ten years to tell you that being rigorous, systematic and standards-based in cataloguing is incredibly important, and technology is our friend in this aim. Furthermore, the whole notion of ‘cataloguing’ is changing, a change led by the opportunities of the modern digital age and the perspectives and requirements of those who use technology in their every day life and work. We need to be aware of this, willing (even excited!) to embrace what this means for our profession and ready to adapt.
This brings me to the subject I am particularly interested in: the use of technology. Cataloguing *is* using technology, and dissemination *is* using technology. That is, it should be and it needs to be if you want to make an impact; if you want to effectively disseminate your descriptions and increase your audience. It is simply no good to see this profession as in any way apart from technology. I would say that technology is more central to being an archivist than to many professions, because we *deal in information*. It may be that you can find a position where you can keep technology at arm’s length, but these types of positions will become few and far between. How can you be someone who works professionally with information, and not be prepared to embrace the information environment? The Web, email, social networks, databases: these are what we need to use to do our jobs. We generally have limited resources, and technology can both help us make the most of the resources we have and, conversely, we may need to make informed choices about the technology we use and what sort of impact it will have. Should you use Flickr to disseminate content? What are the pros and cons? Is ‘augmented reality’ a reality for us? Should you be looking at Linked Data? What is is and why might it be important? What about Big Data? It may sound like the latest buzz phrase but it’s big business, and can potentially save time and money. Is your system fit for purpose? Does it create effective online catalogues? How interoperable is it? How adaptable?
Before I give the impression that you need to become some sort of technical whizz-kid, I should make clear that I am not talking about being an out-and-out techie – a software developer or programmer. I am talking about an understanding of technology and how to use it effectively. I am also talking about the ability to talk to technical colleagues in order to achieve this. Furthermore, I am talking about a willingness to embrace what technology offers and not be scared to try things out. It’s not always easy. Technology is fast-moving and sometimes bewildering. But it has to be seen as our ally, as something that can help us to bring archives to the public and to promote a greater understanding of what we do. We use it to catalogue, and I have written previously about how our choice of system has a great impact on our catalogues, and how important it is to be aware of this.
Our role in using technology is really *all about people*. I often think of myself as the middleman, between the technology (the developers) and the audience. My role is to understand technology well enough to work with it, and work with experts, to harness it in order to constantly evolve and use it to best advantage, but also to constantly communicate with archivists and with researchers. To have an understanding of requirements and make sure that we are relevant to end-users. Its a role, therefore, that is about working with people. For most archivists, this role will be within a record office or repository, but either way, working with people is the other side of the coin to working with technology. They are both central to the world of archives.
If you wonder how you can possibly think about everything that technology has to offer: well, you can’t. But that’s why it is even more vital now than it has ever been to think of yourself as being in a collaborative profession. You need to take advantage of the experience and knowledge of colleagues, both within the archives profession and further afield. It’s no good sitting in a bubble at your repository. We need to talk to each other and benefit from sharing our understanding. We need to be outgoing. If you are an introvert, if you are a little shy and quiet, that’s not a problem; but you may have to make a little more effort to engage and to reach out and be an active part of your profession.
They say ‘never work with children and animals’ in show business because both are unpredictable; but in our profession we should be aware that working with people and technology is our bread and butter. Understanding how to catalogue archives to make them available online, to use social networks to communicate our messages, to think about systems that will best meet the needs of archives management, to assess new technologies and tools that may help us in our work. These are vital to the role of a modern professional archivist.
One of our key aims at the Hub is to increase the range of archives who can contribute. Not just because we like having lots of contributors (we do!), but because we want to help open up hidden archive collections, and help archivists to make them discoverable online.
Used under a CC licence from http://www.flickr.com/photos/markkelley/157662318/
So, new for 2012 is Project Headway. Building on some work we’ve been doing over the past couple of years with Calm and Adlib to improve the EAD export, Project Headway aims to make it easier for archives to contribute to the Archives Hub. We’re especially thinking about archives with little or no online presence, who may not have archival management systems.
With this in mind, one of the things Headway is going to be looking at is producing an Excel template, to allow institutions which catalogue in Excel to convert their catalogues to EAD. This would mean that they could upload their descriptions to online catalogues (such as the Hub), as well as giving them a version of their data that’s in a robust, sustainable, platform-neutral format.
Project headway is scheduled to run until then end of June, and we’re also going to be looking at EAD exports from ICA-AtoM, the Archivist’s Toolkit, and Modes, as well as continuing our work with Calm and Adlib.
We hope to be able to expand on Headway work in the second half of the year, and look at other archival management systems, as well as export from Access databases.
If you’d like to know more about the project, want to volunteer to send us some descriptions, or have a system you’d like us to consider for phase 2, please get in touch!