As mentioned in my last post, we’re looking at the possibilities Artificial Intelligence and Machine Learning can offer the Archives Hub and the archives community in general. I also now have a wider role in Jisc as a ‘Technical Innovations Manager’, so my brief is to consider the wider technical and strategic possibilities of AI/ML for the Digital Resources directorate and Jisc as a whole. We continue to work behind the scenes, but we also keep a watch on cultural heritage and wider sector activities. As part of this I participated in the Aeolian Project’s ‘Online Workshop 1: Employing Machine Learning and Artificial Intelligence in Cultural Institutions’ yesterday.
‘Visual AI and Printed Chapbook Illustrations at the National Library of Scotland’ – Dr Giles Bergel (University of Oxford / National Library of Scotland)
Giles’ team have been using machine learning (ML) on data from data.nls.uk. He outlined their three part approach. First they find illustrations in manuscripts using Google’s EfficientDet object detection convolutional neural network seeded by manually pre-annotated images. They found the object detector worked extremely well after relatively few learning passes. There were a few false positives such as image ink showing through, marginalia and dog ears that would confuse the model.
False positive ML recognition – ink showthrough
Next they matched and grouped the illustrations using their “state of art” image search engine. Giles believes this shows that AI simplifies the task of finding things that are related in images. The final step was to apply classification alogorithms with the VGG Image Classification Engine which uses Google as a source of labelled images. The lessons learned were:
AI requires well-curated data
Tools for annotating data are no less important than classifiers
Generic image models generalize well to printed books
‘Classical’ computer vision still works
AI software development benefits from end-to-end use-cases including data preparation, refinement, consulting with domain experts, public engagement etc.
‘Machine Learning and Cultural Heritage: What Is It Good Enough For?’ – John Stack (UK Science Museum)
John described how AI is being used as part of the Science Museum’s linked data work to collect data into a central knowledge graph. He noted that the Science Museum are doing a great deal of digitisation but currently they only have what John describes as ‘thin’ object data.
They are looking at using AI for name disambiguation as a first step before adding links to wikidata and using entity recognition to enhance their own catalogue. It stuck me that they, and we at the Hub, have been ‘doing AI’ for a while now with such technologies as entity recognition and OCR before the term AI was used. They are aiming to link through to wikidata such that they can pull in the data and add it to their knowledge graph. This allows them to enhance their local data and apply ML to perform such things as clustering to draw out new insights.
John identified the main benefits of ML currently as suggesting possibilities and identifying trends and gaps. It’s also useful for visualisation and identifying related content as well as enhancing catalogues with new terminology. However there were ‘but’s. ML content needs framing and context. He noted that false positives are not always apparent and usually require specialist knowledge. It’s important to approach things critically and understand what can’t be done. John mentioned that they don’t have any ML driven features in production as yet.
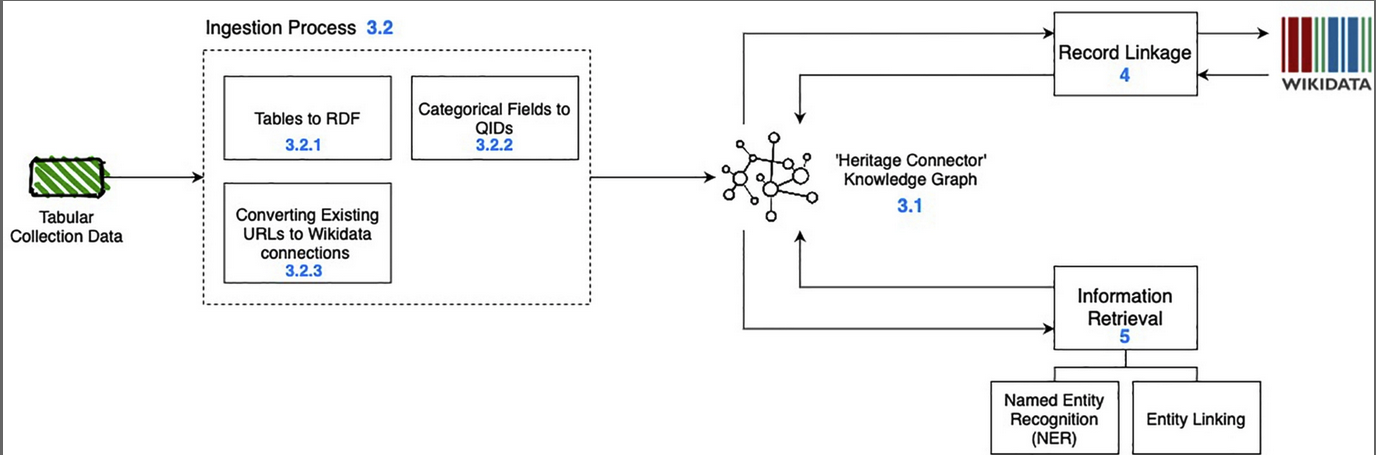
Diagram showing the components of the Heritage Connector software
This was followed by a Q&A where several issues came up. We need to consider how AI may drive new ways/modalities of browsing that we haven’t imagined yet. A major issue is the work needed to feed AI enhancements into user interfaces. Most work so far has been on backend data. AI tools need to integrate into day-to-day workflows for their benefits to be realised. More sector specific case-studies, training materials, tools and models are needed that are appropriate to cultural heritage. See the Heritage Connector blog for more information.
‘AI and the Photoarchive‘ – John McQuaid (Frick Collection), Dr Vardan Papyan (University of Toronto), and X.Y. Han (Cornell University)
The Frick Collection have been using the PyTorchdeep neural network to identify labels for their photo archive collection. They then compared the ML results as a validation exercise with internally crowdsourced data from their staff and curators captured by the Zooinverse software for the same photos.
Frick Collection ML workflow
They found that 67% of the ML labels matched with the crowdsource validations which they considered a good result. They concluded that at present ML is most useful for ‘curatorial amplification’, but much human effort is still needed. This auto-generation of metadata was their main use case so far.
‘Keep True: Three Strategies to Guide AI Engagement‘ – Thomas Padilla (Center for Research Libraries)
Thomas believes GLAMs have an opportunity to distinguish themselves in the AI space. He covered a number of themes, the first being the ’Non-scalability imperative’. Scale is everywhere with AI. There’s a great deal of marketing language about scale, but we need to look at all the non-scalable processes that scale depends on. There’s a problematic dependency where scalability is made possible by non-scalable processes, resources and people. Heterogeneity and diversity can become a problem to be solved by ML. There’s little consideration that AI should be just and fair.
The second theme was ‘Neoliberal traps’ in AI. Who says ethical AI is ethical AI? GLAMs are trying to do the right thing with AI, but this is in the context of neoliberal moral regulation which is unfair and ineffective. He mentioned some of the good examples from the sector including from CILIP, Museums AI Network and his own ‘Responsible Operations‘ paper.
He credited Melissa Terras for asking the question “How are you going to advocate for this with legislation?”. The US doesn’t have any regulations at the moment to get the private sector to get better. I mentioned the UK AI Council who are looking at this in the UK context, and the recent CogX event where the need for AI regulation was discussed in many of the sessions.
The final theme was ‘Maintenance as Innovation’. Information maintenance is a Practice of Care. There is an asserted dichotomy between maintenance and innovation that’s false. Maintenance is sustained innovation and we must value the importance of maintenance to innovation. He appealed to the origin of the word ‘innovation’ which derives from the latin ‘innovare’ which means “to alter, renew, restore, return to a thing, introduce changes in the way something is done or made”. It’s not about creating from new. At the Hub we wholeheartedly endorse this view. We feel there’s far too much focus on the latest technology meme and we’ve had tensions within our own organisation along these lines. There may appear to be some irony here given the topic of this post, but we have been doing AI for a while as noted above. He referred us to https://themaintainers.org/ for more on this.
Roundtable discussion with the AEOLIAN Project Team
Dr Lise Jaillant, Dr Annalina Caputo, Glen Worthey (University of Illinois), Prof. Claire Warwick (Durham University), Prof. J. Stephen Downie (University of Illinois), Dr Paul Gooding (Glasgow University), and Ryan Dubnicek (University of Illinois).
Stephen Downie talked about the need for standardisation of ML extracted features so we can re-use these across GLAMs in a consistent way. The ‘Datasheets for Datasets’ paper was mentioned that proposes “a short document to accompany public datasets, commercial APIs, and pretrained models”. This reminded me of Yves Bernaert’s talk about the related need for standardisation of carbon consumption measures. Both are critical issues and possible areas for Jisc to be involved in providing leadership. Another point that Stephen made is that researchers are finding they can’t afford the bill for ML processing. Finding hardware and resources is a big problem. As noted by ML guru Andrew Ng, we have a considerable data issue with AI and ML work . It may be that we need to work more on the data rather than wasting time, electricity and money re-creating expensive ML models. A related piece of work, ‘Lessons from Archives‘ was also mentioned in this regard. There is a case for sharing model developments across the sector for efficiency and sustainability here.
As archivists, we deal with ethical issues a good deal. But the ability to link disparate and diverse data sources opens up new challenges in this area, and I wanted to explore this a bit.
If you do a general search for ethics and data, top of the list comes health. An interesting example of data join-up is the move to link health data to census data, which could potentially highlight where health needs are not being met:
“Health services are required to demonstrate that they are meeting the needs of ethnic minority populations. This is difficult, because routine data on health rarely include reliable data on ethnicity. But data on ethnicity are included in census returns, and if health and census data for the same individuals can be linked, the problem might be solved.” (Ethnicity and the ethics of data linkage)
However, individuals who stated their ethnicity in census returns were not told that this might subsequently be linked with their health data. Should explicit informed consent be given? Given the potential benefits, is this a reasonable ask? It is certainly getting into hazardous terrain to ignore the principle of informed consent. In their book ‘Rethinking Informed Consent in Bioethics‘, Manson and O’Neill argue that informed consent cannot be fully specific or fully explicit. They argue for a distinctive approach where rights can be waived or set aside in controlled and specific ways.
This leads to a wider question, is fully explicit and specific informed consent actually achievable within the joined-up online world? A world where data travels across connections, is blended, re-mixed, re-purposed. A world where APIs allow data to be accessed and utilised for all sorts of purposes, and ‘open data’ has become a rallying cry. Is there a need to engage the public more fully in order to gain public confidence in what open data really means, and in order to debate what ‘informed consent’ is, and where it is really required?
I am working on a project to create name records, and I am looking at bringing data sources together. Of course, this is hardly new. Wikipedia is the most well-known hub for biographical data. Anyone can add anything to a Wikipedia page (within some limits, and with some policing and editing by Wikipedia, but in essence it is an open database). Wikidata, which underlies Wikipedia, is about bringing sources together in an automated way. Projects within cultural heritage are also working on linked data approaches to create rich sources of information on people. SNAC has taken archival data from many different archive repositories and brought it together. A page for one person, such as Martin Luther-King provides a whole host of associations and links. These sources are not all individually checked and verified, because this kind of work has to be done algorithmically. However, there is a great deal of provenance information, so that all sources used are clear.
The Face of White Australia
There are some amazing projects working to reveal hidden histories. Tim Sherratt has done some brilliant work with Australian records. Projects such as Invisible Australians, which aims to reveal hidden lives, using biographical information found in the records. He has helped to create some wonderful sites that reveal histories that have been marginalised. Tim talks about ‘hacking heritage’ and says: ‘By manipulating the contexts of cultural heritage collections we can start to see their limits and biases. By hacking heritage we can move beyond search interfaces and image galleries to develop an understanding of what’s missing.’ (Hacking heritage, blog post) He emphasises that access to indigenous cultural collections should be subject to community consultation and control. But what does community consultation and control really mean?
I have always been keen to work with the names in archival descriptions – archival creators and all the other people who are associated with a collection. They are listed in the catalogue (leastways the names that we can work with are listed – many names obviously aren’t included, but that’s another story), so they are already publicly declared. It is not a case of whether the name should be made public at all, or, at least, that decision has been made already by the cataloguer. But our plan is to take the names and bring them to the fore – to give them their own existence within our service. We are taking them out of the context of a single archive collection and putting them into a broader one. In so doing, we want to give the archive collections themselves more social context, we want to give more effective access to distributed historical records, and we also want to enable researchers to travel through connections to create their own narratives.
This may help to reveal things about our history and highlight the roles that people have played. It may bring people to the fore people who have been marginalised. Of course, it does not address the problem of biases and subjective approaches to accessions and cataloguing. But a joined-up approach may help us to see those biases and gaps; to understand more about the silent spaces.
Creating persistent identifiers and linking data reveals knowledge. It is temping to see that in simple terms as a good thing. But what about privacy and ethics? Even if someone is no longer living, there are still privacy issues, and many people represented in archives are alive.
Do individuals want to be persistently identified? What about if they change their identity? Do they want a pseudonym associated with their real name? They might have very good reasons for keeping their identity private. Persistent identification encourages openness and transparency, which can have real benefits, but it is not always benign. It is like any information – it can be used for good and bad purposes, and who is to say what is good and what is not? Obviously we have GDPR and the Data Protection Act, and these have a good deal to say about obligations, the value of historical research and the right to be forgotten. This is something we’ll need to take into account. But linked data principles are not so much about working with personal data as working with data that may not seem personal, but that can help to reveal things when linked with other sources of data.
GDPR supports the principle of transparency and the importance of people’s awareness and control over what happens to their personal data. Even if we are not creating and storing personal data, it seems important to engage with data protection and what this means. The challenge of how to think about data when it is part of an ever shifting and growing global data environment seems to me to be a huge one.
Certainly the horse has bolted to some degree with regards to joining up data. The Web lowered barriers considerably, and now we increasingly have structured data, so it is somewhat like one gigantic database. Finding things out about individuals is entirely feasible with or without something like a Names service created by the Archives Hub. We are not creating any new content, but creating this interface means we are consciously bringing data together, and obviously we want to be responsible, and respect people’s right to privacy. Clearly it is entirely impractical to try to get permission from all those living people who might be included. So, in the end, we are taking a degree of risk with privacy. Of course, we will un-publish on request, and engage with any feedback and concerns. But at present we are taking the view that the advantages and benefits outweigh the risks.
“Imagine being a sibling in a family that continually removes you from photos; tries its best to erase you…As you go through [the scrapbook] you see events where you know you were there, but you are still missing.” Lae’l Hughes-Watkins (University of Maryland) gave an impassioned and inspiring talk at DCDC 2019 about her experiences. She argued that archivists need to interrogate the reality that has been presented, and accept that our ideas of neutrality are misplaced. She wants a history that actively represents her – her history and culture, and experiences as a black woman in the USA. She related moving stories of people with amazing stories (and amazing archives) who distrust cultural institutions because they don’t feel included or represented.
This may seem a long way away from our small project to create name records, but in reality our project could be seen as one very small part of a move towards what Lae’l is talking about. Bringing descriptions together from across the UK together maybe helps us to play a small role in this – aiming to move towards documenting the full breadth of human experience. The archives that we cover may retain the biases and gaps for some time to come (probably for ever, given that documentary evidence tends to represent the powerful and the elite much more strongly), but by aggregating and creating connections with other sources, we help to paint a bigger picture. By creating name records we help to contextualise people, making it much easier to bring other lives and events into the picture. It is a move towards recognising the limitation of what is actually in the archive, and reaching out to take advantage of what is on the Web. In doing this through explicitly identifying people we do leave ourselves more open to the dangers of not respecting privacy or anonymity. When we plug fully into the Web, we become a part of its infinite possibilities, which is always going to be a revealing, exciting, uncontrollable and risky business. By allowing others to use this data in different ways, we open it up to diverse perspectives and uses.
The Archives Hub team and Knowledge Integration, our system suppliers, are embarking upon a short four month project to start to lay the groundwork, define the challenges and test the approaches to presenting end users with a name-based means to search, and connect to a broad range of resources related to people and organisations. I will be blogging about the project as we go along.
Our key aims in the long-term are:
To provide the end user with a way to search for people and organisations and find a range of material relevant to their research
To enable connections to be made between resources within and external to Jisc, using names as the main focus
To bring archive collections together in an intellectual sense and provide different contexts to collections by creating networks across our data
This first project will not create an end-user interface, but will concentrate on processing, matching names and linking resources. We want to explore how this can be administered in order to be sustainable over time. In the end, the most challenging part of working with the names we have is identification, disambiguation and matching. The aim is to explore the space and start to formulate a longer-term plan for the full implementation of names as entities within the Archives Hub.
Creation of name records from EAD description records
NB: This blog often refers to personal names for convenience, but names include personal, family and corporate entities.
EAD descriptions include personal, family and corporate names. These ‘entities’ may be listed as archival creators and also associated with the collection as index terms. Archival creators may optionally be given biographical or administrative histories. The relationship of the collection with names in the index is not made explicit in the description (in a structural way), though it may often be gleaned from the descriptive information within the EAD record.
Creating name records for all names
We are proposing to begin by creating name records for all of these entries, no matter how thin the information for each entry may be.
Here is a random selection of names that are included in Archives Hub records:
Grote, Arthur
Gaskell, Arthur
Wilson, John
Thatcher, J. Wells, Barrister at Law
Barron, Margaret
Stanley, Catherine, 1792-1862
Roe, Alfred Charles
Rowlatt, Mary, b 1908
Milligan, Spike, 1918-2002
Fawcett, Margaret, d. 1987
Rolfe, Alan, 1908-2002 actor
Mayers, Frederick J (fl 1896-1937 : designer : Kidderminster, England)
Joan
Only a percentage of names have life dates. Some have born or death dates, some floruit dates.
Of course, the life dates, occupations and outputs of many people are not known, or may be very difficult to find. Also, life dates will change when a birth date is joined by a death date. Epithets may also change over time (and they are not controlled vocabulary anyway).
In addition, we have inverted and non-inverted names on the Archive Hub, names with punctuation in different places, names with and without brackets, etc. These issues create identification challenges.
Even taking names as creators and names as index terms within one single description, the match is often not exact:
Lingard, Joan (creator name)
Lingard, Joan Amelia, 1932- (index term)
The archival descriptions on the Archives Hub vary a great deal in terms of the structure, and different repositories have different approaches to cataloguing. Some do not add name of creator, some do not add index terms, some add them intermittently, and often the same name is added differently for different collections within the same repository. In many cases the cataloguer does not add life dates, even when they are known, or they are added to the name as creator but not in the index list, or vice versa. This sounds like a criticism, but the reality is that there are many reasons why catalogues have ended up as they are.
There has not been a strong tradition amongst archivists of adding names as unique identifiable entities, but of course, it has only been in the last few decades that we have had the potential, which is becoming increasingly sophisticated, of linking data through entity relationships, and creating so much more than stand-alone catalogue records. Many archivists still think primarily in terms of human readable descriptions. Some people feel that with the advent of Google and sophisticated text analysis, there is no need to add names in this structured way, and there is no need for index terms at all. But in reality search engines generally recommend structured data, and they are using it in sophisticated ways. Schema.org is for structured data on the web, an initiative started by Google, Microsoft, Yahoo, and Yandex. Explicit markup helps search engines understand content and it potentially helps with search engine optimisation (ensuring your content surfaces on search engines). Also, if we want to move down the Linked Data road, even if we are not thinking in terms of creating strict RDF Linked Data, we need to identify entities and provide unique identifiers for them (URLs on the web). Going back to Tim Berners-Lee’s seminal Linked Data article from 2006:
“The Semantic Web isn’t just about putting data on the web. It is about making links, so that a person or machine can explore the web of data. With linked data, when you have some of it, you can find other, related, data.”
So, including names explicitly provides huge potential (as well as subjects, places and other entities) and it has become more important, not less important. Indeed, I would go so far as to say that structured data is more important than standards compliant data, especially as, in my experience, standards are often not strictly adhered to, and also, they need constant updating in order to be relevant and useful.
The idea with our project is that we start with name records for every entity – a pot of data we can work with. We may create Encoded Archival Context (Corporate Bodies, Persons and Families), otherwise known as EAC-CPF…but that is not important at this stage. EAC is important for data ingest and output, and we intend to use it for that purpose, so it will come into the picture at some point.
The power of the anonymous
There are benefits in creating name records for people who are essentially anonymous or not easily identifiable. Firstly, these records have unknown potential; they may become key to making a particular connection at some point, bearing in mind that the Archives Hub continually takes new records in. Secondly, we can use these records to help with identification, and the matching work that we undertake may help to put more flesh on the bones of a basic name record. If we have ‘Grote, Arthur’ and then we come across ‘Grote, Arthur, 1840-1912’, we can potentially use this information and create a match. Of course, the whole business of inference is a tricky thing – you need more than a matching surname and forename to create a ‘same as’ relationship (I won’t get into that now). But the point is that a seemingly ‘orphan’ name may turn out to have utility. It may, indeed, provide the key to unlocking our understanding of particular events – the relationships and connections between people and other entities are what enable us to understand more about our history.
Components of a name record
So, all names will have name records, some with just a name, some with life dates of different sorts, some with biographical or administrative histories. The exception to this may be names that are not identifiable as people or organisations. It is potentially possible to discover the type of entity from the context, but that is a whole separate piece of work. Hundreds of names on the Archives Hub are simply labelled as ‘creator’ or ‘name’. This is down to historical circumstance – partly the Archives Hub made errors in the past (our old cataloguing tool which entered creators as simply EAD ‘origination’), partly other systems we ingest data from. At the moment, for example, we are taking in descriptions from Axiell’s AdLib system, but the system does not mark up creator names as people or organisations (unless the cataloguer explicitly adds this), so we cannot get that information. This is probably a reflection of a time when semantically structured data was simply less important. If a human reads ‘Elizabeth Gaskell’ in a catalogue entry they are likely to understand what that string means; if undertaking large-scale automated processing, it is just a string of characters, unless it includes semantic information.
From the name records that we create, we intend to develop and run algorithms to match names. In many cases, we should be able to draw several names together, with a ‘same-as’ relationship. Some may be more doubtful, others more certain. I will talk about that as we get into the work.
At the moment, we have some ideas about how we will work with these individual records in terms of the workflow and the end user experience, but we have not made any final decisions, and we think that what is most important at this stage is the creation and experimentation with algorithms to see what we can get.
Master name records
We intend to create master records for people and organisations. The principle is to see these master records not as something within the archives domain, but as stand-alone records about a person or organisation that enable a range of resources to be drawn together.
So, we might have several name records for one person:
Example of master record, with various related information included:
Webb, Martha Beatrice, 1858-1943, social reformer and historian
Examples of additional name records that should link to the master record:
Webb, Beatrice, 1858-1943 (good match)
Webb, Martha Beatrice, 1858-1943, economist and reformer (good match)
Webb, Martha Beatrice, nee Potter, 1858-1943 (good match)
Webb, M.B. b. 1858 (possible match)
but…
Potter, Martha Beatrice, b 1858
…might well not be a match, in which case it would stand separately, and the archive connected to it would not benefit from the links being made.
We have discussed the pros and cons of creating master records for all names. It makes sense to bring together all of the Beatrice Webb names into one master record – there is plenty that can be said about that individual; but does it make sense to have a master record for single orphaned names with no life dates and nothing (as yet) more to say about that individual? That is a question we have yet to answer.
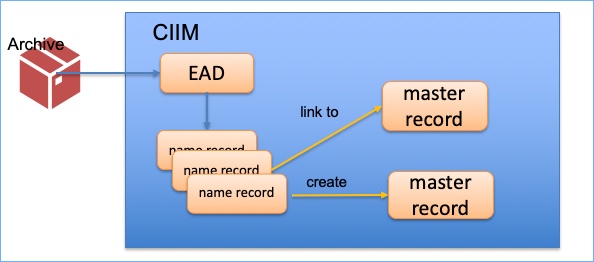
The archive is described though an EAD description held on our system (the CIIM). We take all the names from this to create a huge store of individual names. From this, we aim to create and update ‘definitive’ name records.
The principle is to have name records that enables us to create links to the Archives Hub entries and also to other Jisc services and resources beyond that – resources outside of the archives domain. Many of these resources may also help us with our own identification and matching processes. It is important to benefit from the work that has already been done in this area.
We are looking at various name resources and assessing where our priorities will be. This is a fairly short project, and we won’t have time to look at more than a handful of options. But we are currently thinking in terms of VIAF, ORCID and Wikidata. More on that to follow.
Personally, I’ve been thinking about working with names for several years. We have been asked about it quite a bit. But the challenge is so big and nebulous in many ways. It has not been feasible to embark upon this kind of work in the past, as our system has not supported the kind of systematic processing that is required. We are also able to benefit from the expertise K-Int can bring to data processing. It is one thing doing this as a stand-alone project; it is quite another to think about a live service, long term sustainability, version control and revisions, ingest from different systems, etc. And also, to break it down into logical phases of work. It is exciting, but it is going to involve a great deal of hard work and hard thinking.
Here at the Archives Hub we’ve not been so focussed on Linked Data (LD) in recent years, as we’ve mainly been working on developing and embedding our new system and workflows. However, we have continued to remain interested in what’s going on and are still looking at making Linked Data available in a sustainable way. We did do a substantial amount of work a number of years back on the LOCAH project from which we provided a subset of archival linked data at data.archiveshub.ac.uk. Our next step this time round is likely to be embedding schema.org markup within the Hub descriptions. We’ve been closely involved in the W3C Schema Architypes Group activities, with Archives Hub URIs forming the basis of the group’s proposals to extend the “Schema.org schema for the improved representation of digital and physical archives and their contents”.
We are also aiming to reconnect more closely with the LODLAM community generally, and to this end I attended a TNA ‘Big Ideas’ session ‘Is Linked Data an appropriate technology for implementing an archive’s catalogue?’ given by Jean-Luc Cochard of the Swiss Federal Archives. I took a few notes which I thought it might be useful to share here.
Why we looked at Linked Data?
This was initially inspired by the Stanford LD 2011 workshop and the 2014 Open data.swiss initiative. In 2014 they built their first ‘aLOD’ prototype – http://alod.ch/
The Swiss have many archive silos from which they transformed the content of some systems to LD and then were able to merge. They created basic LD views, Jean-Luc noting that the LD data is less structured than data in the main archival systems, an example of which is e.g. http://data.ge.alod.ch/id/archivalresource/adl-j-125
They also developed a new interface http://alod.ch/search/ with which they were trying for an innovative approach to presenting the data such as providing a histogram with dates. It’s currently just a prototype interface running off SPARQL with only 16,000 entries so far.
They are also now currently implementing a new archival information system (AIS) and are considering LD technolgy for the new system, but may go with a more conventional database approach. The new system has to work with the overall technical architecture.
Linked data maturity?
Jean-Luc noted that they expect that in three years born digital will greatly expand by factor of ten, though 90% of the archive is currently analogue. The system needs to cope with 50M – 1.5B triples. They have implemented Stardog triple stores 5.0.5 and 5.2. The larger configuration is a 1 TB RAM, 56 CPU and 8 TB disk machine.
As part of performance testing they have tried loading the system with up to 10 Billion triples and running various insert, delete and query functions. The larger config machine allowed 50M triple inserts in 5 min. 100M plus triples took 20min to insert. With the update function things were found to be quite stable. They then combined querying with triple insertions at the same time, and this highlighted some issues with slow insertions with a smaller machine. They also tried full text indexing with the larger config machine. They got very variable results with some very slow response times with the insertions, finding the latter was a bug in the system.
Is Linked Data adequate for the task?
A key weakness of their current archival system is that you can only assign records to one provenance/person. Also, their current system can’t connect records to other databases, so they have the usual silo problem. Linked data can solve some of these problems. As part of the project they looked at various specs and standards:
BIBFRAME v2.0 2016
Europeana EDM released 2014.
EGAD activities – RiC-CM -> RiC-O based on OWL (Record in context)
A local initiative- Matterhorn RDF Model. Matterhorn uses existing technologies, RDA, BPMN, DC, PREMIS. There is a first draft available.
They also looked at relevant EU R&D projects: ‘Prelia’, on preservation of LD and ‘Diachron’ – managing evolution and preservation of LD.
Jean-Luc noted that the versatility of LD is appealing for several reasons –
It can be used at both the data and metadata levels.
It brings together multiple data models.
It allows data model evolution.
They believe it is adequate to publish archive catalogue on the web.
It can be used in closed environment.
Jean-Luc mentioned a dilemma they have between RDF based Triple stores and graph databases. Graph databases tend to be proprietary solutions, but have some advantages. Graph databases tend to use ACID transactions intended to guarantee validity even in the event of errors, power failures, etc., but they are not sure how ACID reliable triple stores are.
Their next step is expert discussion of a common approach, with a common RDF model. Further investigation is needed regarding triple store weaknesses.
The project explored Britain’s design history by connecting design-related content in different archives, with the aim of giving researchers the freedom to explore around and within archives.
You can read a number of blog posts on the project, and there is also a video introducing the EBD website on You Tube, but in this post I wanted to set out how we have learned from the project and how it has informed the development of the new Archives Hub.
Unfortunately, we may not be able to maintain the website longer term, and so it seemed timely to reflect on how the principles used in this project are being taken forward.
Modelling the Data
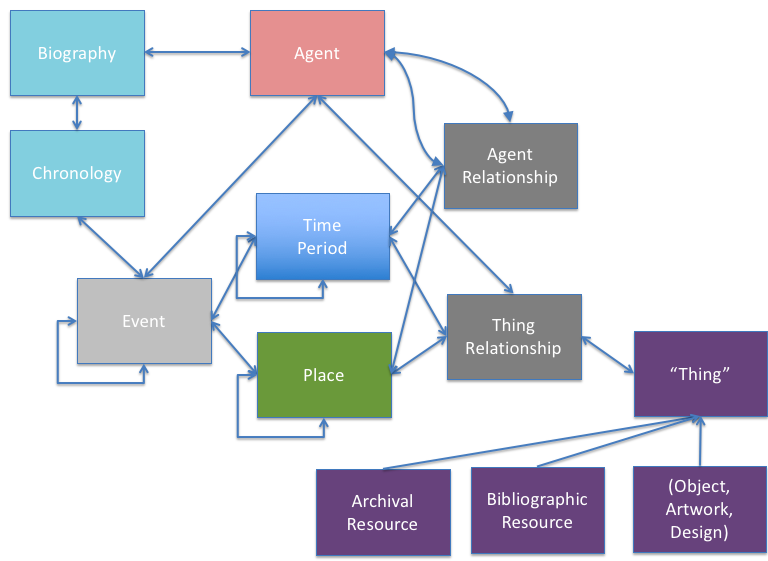
A key component of EBD was our move away from the traditional approach of putting the archive collection at the centre of the user experience. Instead, we wanted to reflect the richness of the content – the people, organisations, places, subjects, events that a collection represents.
We had many discussions and filled many pieces of paper with ideas about how this might work.
Coming up with ideas for how EBD should work
We then took these ideas and translated them into our basic model.
Relationships between entities in the EBD data
Archives are represented on our model as one aspect of the whole. They are a resource to be referenced, as are bibliographic resources and objects. They relate to the whole – to agents, time periods, places and events. This essentially puts them into a whole range of contexts, which can expand as the data grows.
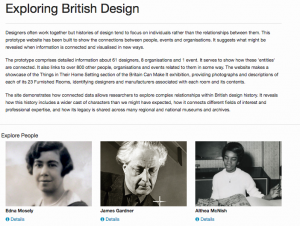
Homepage of Exploring British Design: People are foremost.
The Exploring British Design website was one way to reflect the inter-connected model that we created.
We have taken the principles of this approach with the new Archives Hub architecture and website, which was launched back in December 2016. Whilst the archive collection description stays very much in the forefront of the users’ experience, we have introduced additional tabs to represent themed collections and repositories. All three of these sources of information are, in a data and processing sense, treated equally. The user searches the Hub and the search runs across these three data sources. The model allows us to be flexible with how we present the data, so we could also try different interfaces in future, maybe foregrounding images, or events.
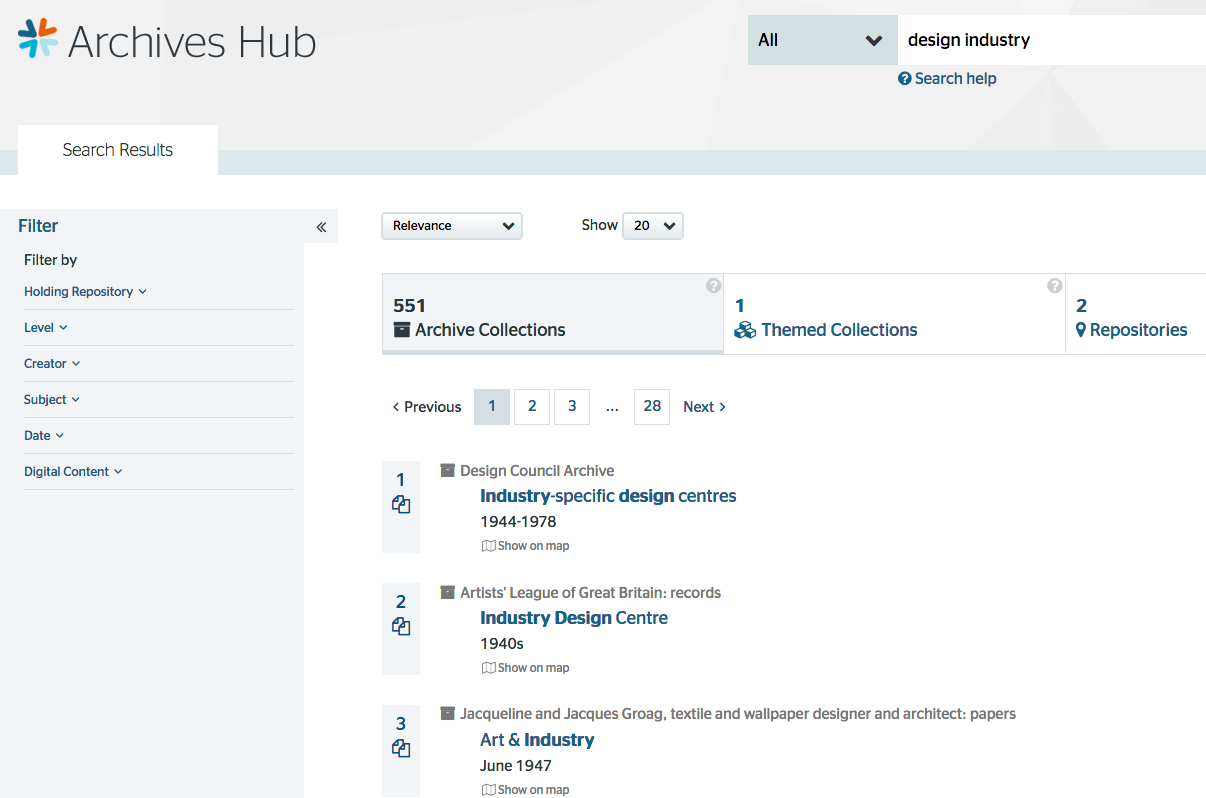
Search for ‘design industry’ gives results across Archive Collections, Themed Collections and Repositories
Names
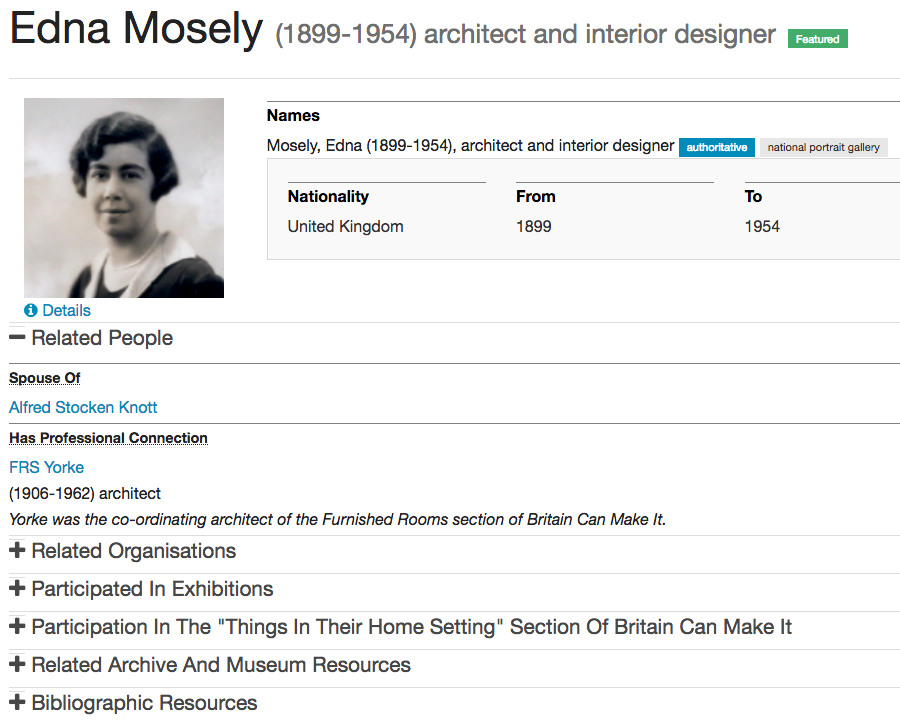
The EBD project had a particular focus on people. We opted to combine machine methods of data extraction – data taken partly from our already existent archive descriptions as well as from other external sources – with manual methods, to create rich records about designers. This manual approach is not sustainable for a large-scale service like the Archives Hub, but it shows what is possible in terms of creating more context and connectivity.
EBD website showing a person page
We wanted to indicate that well-structured data allows a great deal more flexibility in presentation. In this case the ‘Archive and Museum Resources’ are one link in the list of resources about or related to the individual. We could have come up with other ways to present the information, given how it was structured.
We are intending to introduce names pages to the Archives Hub, which will then more clearly echo the EBD approach. They will largely have been created through automated processes, as we needed to create them at scale. They will generally be quite brief, without the ideal structure or depth, but the principle remains that we can then link from a person page to a host of related resources. The Hub website will have a new tab for ‘Names’ and end users will be able to run searches that take in collections, themes, repositories, people and organisations.
The EBD project allowed us to explore standards used for the creation of names data. It was our first experience of using Encoded Archival Context (Corporate Bodies, Persons and Families) (EAC-CPF), so we could start to see what we could do with it, as well as discover some of the shortcomings of the standard, as our data went beyond what is supported. For example, we wanted to link images to people and events but this was not covered by the standard. It was useful to have this preliminary exploration of it, and what it can – and can’t – do, as we look to adopt it for names within the Archives Hub.
Structured Data
One of the things the project did reinforce for me was the importance of indexing. On the Archives Hub we have always recommended indexing, but we have had mixed reactions from archivists, some feeling that it is less useful than detailed narrative, some saying that it is not needed ‘now we have Google’, some simply saying they don’t have time.
Indexing has many advantages, some of which I’ve touched on in various blog posts – and one at the top of the list, is that it brings the advantages of structured data. A name in a narrative can, in theory, be pulled out and utilised as a point of connectivity, but a name as an index term tends to be a great deal easier to work with: it is identified as a name, it usually has structured surname, forename content, it usually includes life dates and may include titles and epithets to help unambiguously identify an individual.
EBD was all about structured data, and we gave ourselves the luxury of adding to the data by hand, creating rich structured records about designers. This was partly to demonstrate what could be done in an interface, but we were well aware that it would be problematic to create records of that level of detail at scale. However, as we start to grapple with expanding name records in the Archives Hub, we have EBD as a reference point. It has helped us to think more about approaches and priorities when creating name records. If we were to create an EAC Editor (similar to our EAD Editor) we would think carefully about how to facilitate creating relationships. For example, the type of relationship – should there be a controlled list of relationship types? e.g. ‘worked with, collaborated with, had professional connection with, influenced by, spouse of’ – these are some of the relationships we used in EBD, after much discussion about how best to approach this. Or would it be more practical to stick to ‘associated with’ (i.e. not defined), which is easier, but far less useful to a researcher. Could we have both? How would one combine them in an interface? Another example – the potential to create timelines. If we wanted to provide end users with timelines, we would need to focus on time-bound events. There are many issues to consider here, not least of which is how comprehensive the timeline would be.
The vexed question of how to combine data from name descriptions created by several institutions is not something we really dealt with in EBD, but that will be one of the biggest challenges for us in aiming to implement name data on the Archives Hub.
The level of granularity that you decide upon has massive implications for complexity, resources and benefits. The more granular the data, the more potential for researchers to be able to drill down into lives, events, locations, etc. So including life dates allows for a search for designers from 1946; including places of education allows for exploring possible connections through education, but adding dates of education allows for a more specific focus still.
Explaining our approach
One thing that struck me about this project was that it was harder than I had anticipated to convey to people what we were trying to achieve and what we could achieve. I tended to find that showing the website raised a number of expectations that I knew would be difficult to fulfill, and if I’m being honest, I sometimes felt rather frustrated at the lack of recognition of what we had achieved – it’s really not easy to combine, process and present different data sources! It is ironic that the more we press forwards with new functionality, and try to push the boundaries of what we do, the more it seems that people ask for developments that are beyond that! You can try to modify expectations by getting deep down and technical with the challenges involved in aggregating and enhancing data created over time, by different people, in different environments (we worked with CSV data, EAC-CPF data, RDF and geodata for example), with different perspectives and priorities. But detailed explanations of technical challenges are not going to work for most audiences. End users see and make an assessment of the website; they shouldn’t really need to be aware of what is going on behind the scenes.
Originally, in our project specification, we asked the question: “How can we encourage researchers, archive and museum professionals, and the public, to apprehend an integrated and extended rather than collection-specific sense of Britain’s design history?” Whilst we did not go as far to answer this question as we had hoped, the work that we did made me feel that it might be harder than I had envisaged. People are very used to the traditional catalogues and other finding aids that are out there, and it creates a certain (possibly unconscious) mindset. I know this too well, because, as an archivist, I have had to adjust my own thinking to see data in a different way and appreciate that traditional approaches to cataloguing and discoverability are not always suited to the digital online age.
Data Model
The hierarchical approach to data is very embedded among archivists, and this is what people are used to being presented with. Unless archivists catalogue in a different way, providing more structured information about entities (names, places, etc) then actually presenting things in a more connected way is hard.
A folder structure is often used to represent archival hierarchy
A more inter-connected model, which eschews linear hierarchy in favour of fluid entity relationships, and allows for a more flexible approach with the front-end interface to the data relies upon the quality, structure and consistency of the data. If we don’t have place names at all we can’t provide a search by place. If we don’t have place names that are unambiguously identified (i.e. not just ‘Cambridge’) then we can provide a search by place, but a researcher will be presented with all places called Cambridge, anywhere in the world (including the US, Australia and Jamaica).
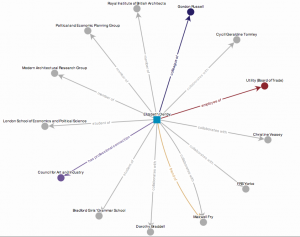
An example of connected entities
The new Archives Hub was designed on the basis of a model that allows for entities to be introduced and new connections made.
Entities within the Archives Hub system
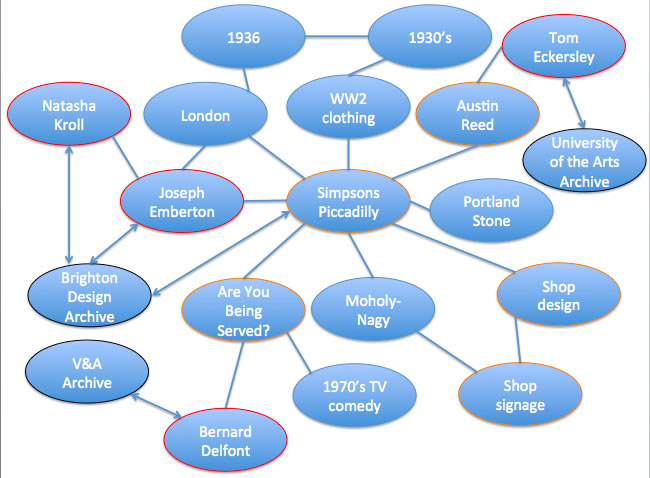
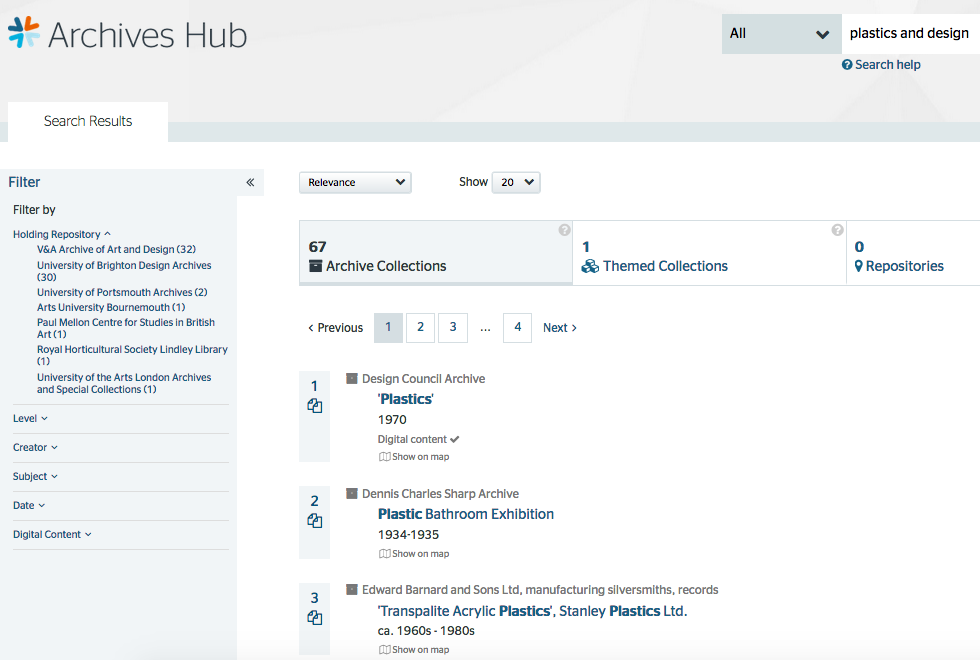
So, the tabs that the end user sees in the interface can be modified and extended over time. Searches can be run across all entities; it is not solely about retrieving descriptions of archives. This approach allows for researchers to find e.g. repositories that are significantly about ‘design’ or repositories that are located in London. It allows us to introduce Themed Collections as a separate type of description, so a student doing a project on ‘plastics’ would discover the Museum of Design in Plastics as a resource alongside archive collections at repositories including Brighton Design Archives, the V&A and the Paul Mellon Centre.
Search for ‘plastics and design’ shows archives and themed resources
Website Maintenance
One of the things I’ve learnt from this project is that you need to factor in the ongoing costs and effort of maintaining a project website. The EBD website is quite sophisticated, which means there are substantial technical dependencies, and we ended up running into issues with security, upgrades and compatibility of software, issues that are par for the course for a website but nonetheless need dealing with promptly. Maybe we should have factored this in more than we did, as we know the systems administration required for the Archives Hub is no small thing, but when you are in the throws of a project your focus is on the objectives and final output more than the ongoing issues. We cannot maintain a site long-term that is not being regularly used. EBD does not get the level of use that would justify the resources we would have to put into it on an ongoing basis.
Conclusion
When we were creating the model for the Archives Hub, we thought as much about flexibility and future potential as anything else. This is one thing that we have learnt from running the Hub for 25 years and from projects like Exploring British Design. You need to plan for potential developments in order to start to work with cataloguers, to get the data into the shape that you need it to be. We wanted to be able to introduce additional entities, so that we could have names, places, languages, images, or any other entities as ‘first class citizens‘ of the Hub. We wanted to be able to enhance the end user’s ability to take different paths, and locate relevant archives through different avenues of exploration.
We need to temper our ambitions for the Hub with the realities of cataloguing, aggregation and resources available, and we need as much information as we can get about what researchers really want; but this is why it is so important to encompass potential as well as current functionality. We may not be able to introduce everything we have envisioned or that users ask for right now; but it is important to understand the vital link between approaches to cataloguing, adherence to data standards, and front end functionality. We created visualisations for EBD and we would love to do this for the Hub, but it was not an easy thing to do, and so we would need to consider what the data allows, the software options available, whether the technical requirements are sustainable over time, and the effectiveness of the end result for the researcher.
Visualisation for Elizabeth Denby
When we demonstrated the visualisations in EBD, they had the wow factor that was arguably lacking in the main text-based site, but for serious researchers the wow factor is a great deal less important that the breadth and depth of the content, and that requires a model that is fundamentally rigorous, sustainable over time and realistic in terms of the data that you have to work with.
If, as a researcher, you search for ‘Jane Drew’, the celebrated architect and town planner, on the Archives Hub, amongst other things, you might discover a single item, “Letter from Jane B Drew to John and Myfanwy Piper”, a letter in the “Papers of John and Myfanwy Piper”.
You can see that its a letter in a collection at the Tate Gallery Archive. The description of the collection is an example of a good quality traditional archival catalogue, giving a fairly detailed listing of the content this particular collection. But as a researcher you are really just interested in just this one letter. You may ask yourself a number of questions, possibly starting with (1) Is this the Jane Drew I’m interested in? and then (2) What is the relationship between Jane Drew and John and Myfanwy Piper? You may well be able to find answers by accessing the letter itself, but at this stage you may just want to place this connection in the broader context of Jane Drew’s life and work. As a researcher, understanding how these people are connected may shed light on your research interests.
In this blog I want to think about this question of relationships. The fact is that archivists rarely provide structured information about relationships; if there is information, it is usually in the biographical history, which might outline key events and people in someone’s life, referring to their parents, work colleagues, friends, etc. The nature of the relationship is sometimes explicitly given, but often it is not. Our standards don’t really say much about relationships between the entities (people, organisations, places, etc) that we describe in our catalogues.
Going back to the Papers of John and Myfanwy Piper as an example, the biographical history includes the following:
[John] Piper began writing reviews from the late 1920s making a name for himself as a critic writing for periodicals like ‘The Listener’ and the ‘Architectural Review’. From 1935-1937 he assisted Myfanwy Evans, with the production of a quarterly review of contemporary European abstract painting called ‘Axis’. In 1937 Piper was commissioned by his friend John Betjeman to write the ‘Shell Guide to Oxfordshire’. Piper went on to write and provide photographs for a number of the guides as well as edit the series. In the same year John Piper married the writer Myfanwy Evans.
This is a typical of a biographical history – useful historical information about the individual or organisation. Within this there is information we can potentially use to create explicit relationship information:
John Piper ‘worked with’ Myfanwy Evans
John Piper ‘was friends with’ John Betjeman
John Piper ‘worked for’ John Betjeman
John Piper ‘was married to’ Myfanwy Evans
There are a number of issues to consider here:
How can we unambiguously identify the people?
How do we choose the vocabulary we use to define the relationships?
Do we try to include dates?
Is it reasonable for us to interpret relationships as ‘friendships’ or ‘collaborations’ if this is not actually explicit?
We are looking at some of these issues through our AHRC project, Exploring British Design. They are all issues that archivists need to explore in a debate around relationship information, but the first issue to consider is simply whether we should be thinking more about including this kind of relationship information in our archival finding aids. Is it something that would be of real value to end users? This issue is coming more to the fore as we start to think about implementing ISAAR (CPF) and working with EAC-CPF , and also as Linked Open Data gains traction.
In a (well worth reading) recent article in the Journal of Contemporary Archival Studies, on the potential impact of EAC-CPF, K.M Wisser reports the findings of a survey about relationship information. The survey received 208 responses from archivists/archives in the US. Wisser wrote “The survey results indicate that the archival community has only just begun to consider relationships in the context of archival description and the role that explicit description of those relationships may play.”
As one respondent wrote:
“relationships are among the most important facets in a collection and deserve a high priority in description. One cannot understand the historical value of an event, person, or organization without knowing [the] relationship among and between them.”
One thing that really strikes me in Wisser’s findings is that archivists see relationships that are documented outside of the collection as almost as significant as those that are documented within the collection. Going back to our original topic of Jane Drew: who else did Jane Drew work with? Should we provide that information to our users, whether or not it is documented within the collection? Is our role to give as full an account as we can of Drew’s life and career? Is it to limit ourselves to what is within the collection?
Wisser’s survey asked respondents about the importance of relationship types. It is curious to me that archivists rated ‘collaborated with’ as a more important relationship than ‘studied with’; they rated a friendship as far more important when it was documented in the collection; and they rated ‘influenced by’ as generally not so important. I’m surprised that the respondents had such definite ideas about the relative importance of different types of relationships, especially when the majority appeared to agree with the importance of ‘objective cataloguing’.
In our Exploring British Design project, the work we did with researchers definitely confirmed to me the fairly self-evident observation that any relationship can be of major significance in research, even if it appears of minor significance within the archive, or indeed, within the literature in general. A brief collaboration may have been a crucial influence, a short friendship may have had hitherto unrealised impact, and anyway, the importance of the relationship depends upon the research you are doing. Researchers are not really aware of how challenging it is for us as information professionals to establish these kinds of relationships in ways that they can then access. But it is clear that this is the sort of connectivity they are after.
One of the challenges with documenting relationship types is that they can be hard to define. As Wisser notes:
“The concept of influence, however, proved the most problematic. Comments such as ‘influence is a squishy sort of relationship’ and ‘I think it would often be very difficult to prove that Entity A was influenced by Entity B’ indicate a notion of intangibility.”
The conclusion could be that we should leave well alone relationships that are hard to define. On the other hand, if we are in a position, as we research a collection, to highlight potential connections, that action could be of major value to a researcher, who may otherwise never know about a link that ends up being crucial to their particular research. The relationships that are easy to define are likely to have been defined already.
One thing that strikes me about the whole notion of introducing interpretation and opinion into cataloguing (a possible argument against defining relationships) is that the horse has pretty much bolted. I’ve looked at enough ‘objective’ descriptions to be aware that the names archivists choose to add as index terms are a choice; they inevitably have to be an opinion about the names significant enough to add as index terms. And subjects are a similar case – some collections are indexed thoroughly, some not at all.
Aside from indexing, each person would create a different scope and content entry, including and excluding different information, and whether you call that subjective or not, it is certainly always selective. You could also argue that the level of detailed hierarchical cataloguing, might indicate the relative importance of the collection. On the Archives Hub there are some collections catalogued in huge detail, and it is inevitable that researchers will assume these collections are particularly important.
All of these choices have implications for discoverability.
In Wisser’s survey, a significant proportion of respondents felt that the importance of a relationship should be based upon the use of the collection. But this, again, raises the question: When thinking about relationships, is the cataloguer reflecting the scope of the collection, or are they trying to give as full a picture as they can of the person or organisation? Are we within the world of the collection; or is the collection within the world?
The reason that I believe that we should think beyond the bounds of the collection content is that I think it promises much richer rewards for our users and encourages archives to be a major player within a broader landscape of information resources. I base my thinking on the premise that the researcher is primarily interested in their research topic, which is not likely to be an archive collection per se, but rather an event, a person, an organisation, a subject, and the way things are connected. I think archivists are still tending to think in terms of a document that describes a collection, rather than how to link the collection into the cultural heritage landscape, and even more broadly beyond that. I wonder if archivists don’t always think beyond the catalogues they currently create because the researchers they have contact with (who visit the archive) are already fairly confident they want to use that repository, or a particular archive within that repository. In other words, the researcher is already in their space. When I worked in a specialist archive, I thought about researchers discovering our archive as a whole (having an online presence) and then I thought about them using our collections (individual collections each with their own description); I didn’t think about how our collections could be seen as part of a whole information landscape.
The loudest – and most convincing – argument I hear against this kind of approach is that it takes time, and archivists are short on time. But I wonder if that means we have to think fundamentally differently. Going back to Jane Drew, and think about the value of relationships for research into her life and work…
If one archive collection description highlights just a few relationships, this could take us a long way (although relationship types are a whole different thing…). If the individuals and organisations are unambiguously identified, this can help with the process of creating links out to other data sources, so that information can be linked together; then we have the chance to benefit from finding out about relationships that have been defined elsewhere. In other words, the connections one person has throughout their life can only be fully realised through the pooling of information resources, very much a joint effort. If the data is structured it can potentially be brought together.
Traditional archival cataloguing focuses on the collection, and what is documented within the collection. It tends to think in terms of a self-contained document. Pursuing relationships breaks the bounds of any one information source. That seems like a good thing, but it raises questions around approaches to cataloguing. One obvious way to tackle this is to start to think more about archival authority records. These should enable us to move beyond a collection-centric description of the collection and towards a more entity based approach, because you describe an agent (entity) independently of any one archival collection. Another option is to think in a Linked Data way, where you are concentrating on entities and relationships.
There are so many questions raised by the whole area of entities and relationships. A few of my current conclusions are:
We should primarily be led by what benefits research. Researchers are far less likely to think in terms of individual archive collections, and far more likely to think in terms of research areas (topics). The Web gives us the opportunity to think in a broader context.
Maybe it is worth considering taking some of the time used to provide a really detailed biographical history as an unstructured narrative, or the time to provide a really detailed multi-level description, and taking more time to provide (or provide the potential for) connections between our descriptions and the larger information environment. This could allow researchers to bring together much more comprehensive information, even if what we provide about individual collections is less detailed. Just adding something like a VIAF identifier to a name would be a great big leap forwards (http://viaf.org/viaf/51792789).
There is great value in being a small fish in a big pond, because most researchers are fishing for data in the big pond. As Wisser’s article says, “relationships are…seen to free collections from the isolation of individual repositories.” If we aim to be part of the big pond, we can continue to tend our smaller ponds as well!
To go back to the Piper Collection and Jane Drew….I used this as a random example, thinking of a researcher interested in one particular designer. But of course, the Tate Gallery Archive can’t be expected to define all the relationships within the description. It’s great that they have provided enough detail to find this one individual item – without that, we would not know about the connection with Jane Drew. I’m arguing for unambiguously identifying entities (people, organisations) because if we can potentially link this instance of ‘Jane Drew’ to other instances in other information sources, then it is very possible that we can find out more about this relationship; And if the relationship can’t be established through other sources, then maybe this archive provides unique evidence of a connection that could significantly benefit research.
We have recently been reprocessing the Archives Hub data, transforming it into RDF based Linked Data, and as part of this we have been working on names matching. For Linked Data, creating links to external data sources is key – it is what defines Linked Data and gives the opportunities, potentially, for researchers to explore topics across data sources.
This names matching work has big implications for archives. I have already talked extensively in the Hub Blog about the importance of structured data, which is more effectively machine processable. For archival descriptions, we have a huge opportunity to link to all sorts of useful data sources, and one of the key means to link our data is through personal names. To do this effectively, we need names to be structured, and this is one of the reasons why the Hub practice of structuring names by separating out surname, forename, dates, titles and descriptive information (epithets) is so useful. We do this structuring even though EAD (the recognised XML standard for archives) doesn’t actually allow for it. We took the decision that the advantages would outweigh the disadvantages of a non-standard approach (and we can export the data without this additional markup, so really there is no disadvantage).
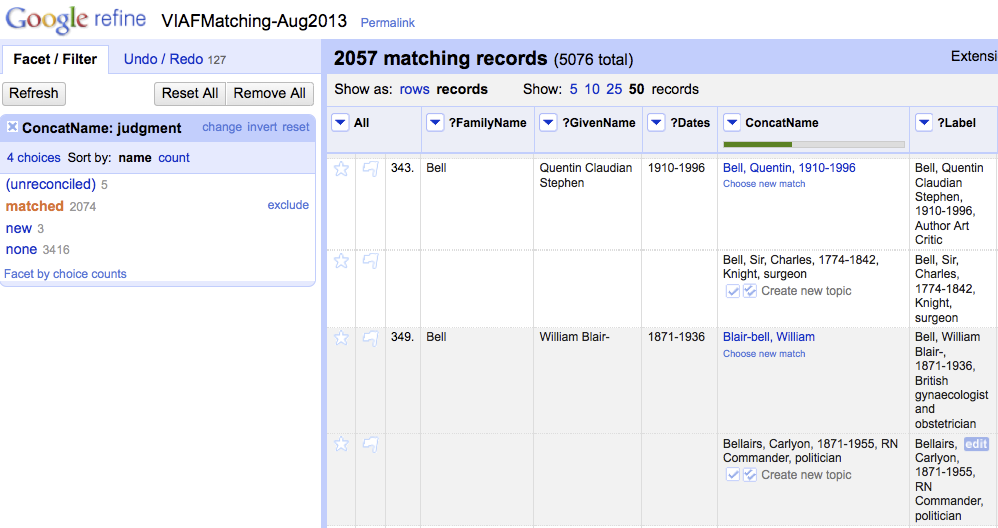
We have been working on the matching, using the freely available Open Refine data processing tool with the VIAF reconciliation service developed by Roderick Page. Freely available tools like this are so important for projects like ours, and we’re really grateful that we were able to take advantage of this service.
The matching has generally been very successful. Out of 5,076 names, just over 2,000 were linked from the Hub entry to the VIAF entry, which is a pretty good percentage.
This post provides some perspectives on the nature of the data and the results of the matching work.
Full names and epithets
With a name like ‘Bell, Sir Charles, 1774-1842, knight surgeon’, (you can see his entry in our current Linked Data views at http://data.archiveshub.ac.uk/id/person/ncarules/bellsircharles1774-1842knightsurgeon) there is plenty of information – surname, forename, dates and an epithet to help uniquely identify the individual. However, with this name, a match was not found, despite an entry on VIAF: http://viaf.org/viaf/2619993 (which is why you may not yet see the VIAF link on our Linked Data view). Normally, this type of name would yield a match. The reason it didn’t is that the epithet came through in the data we used for matching.
Screenshot of names matching using Open Refine
This highlights an issue with the use of epithets within names. It is encouraged in the NCA Rules, and it does help to uniquely identify an individual, but it introduces an additional element in the string that makes it harder to match the data.
Where our process did not manage to get the family name, forename and dates to match with VIAF, we used the ‘label‘ information that we have in our Linked Data. This label information includes the epithet. For example: Nosek, Václav, 1892-1955, Czechoslovak politician. This doesn’t tend to find a match, because of the epithet. With examples like this we can manually check, and in this case there is a VIAF match (http://viaf.org/viaf/23683886). But manual checking is problematic where you have thousands of names.
In 95% of cases we did manage to omit the epithet. But sometimes the epithet was included because we used the label, as stated, or because the markup on the Archives Hub is not always consistent and sometimes the structured names I referred to above are not present in Hub data because the data has come from other systems. (We may have found a way to remove these stray epithets, but it would have taken a good deal more time and effort to achieve).
Bringing together information on an individual
The reference to Sir Charles Bell came from a collection of “Papers of Sir Charles Bell” (http://archiveshub.ac.uk/data/gb96-ms386). In this description his occupation is “surgeon”. In the VIAF description (http://viaf.org/viaf/2619993) he is described as “Scottish painter, draftsman, and engraver”. Ostensibly this doesn’t look like the same person, but looking down the VIAF description, you can see titles such as “The nervous system of the human body” and other works that are clearly written by a scientist. The linking of our description with the VIAF description brings together Sir Charles Bell scientist and Sir Charles Bell painter, a good illustration of how linking provides a better perspective, as the different data sources effectively become joined up.
Pulling sparse sources together
For Francis Campbell Ross Douglas VIAF only has the surname and forename (http://viaf.org/viaf/211588539/), although if you look at the source records you also find “Douglas Of Barloch” to help with identification. This is an example where the Hub record has much more information (http://archiveshub.ac.uk/data/gb097-douglasofbarloch), and therefore creating the link is particularly useful. It shows how archives can help contribute to our knowledge of individuals within the Linked Data space, as they often have little known information, gleaned from the archives themselves.
<persname>
<surname>Bell</surname>,
<forename>William Blair-</forename>
(<dates>1871-1936</dates>)
<epithet>British gynaecologist and obstetrician</epithet>
</persname>
This is an example of the application of the NCA Rules, which insist on the last entry element as the main element, so it means the element ‘Bell’ is marked up as the surname. In fact, the matching still works because, with all the elements there, the reconciliation service can still find the right person (http://viaf.org/viaf/14336292/). However, it still concerns me that within the archive sector we have a rule that separates out the surname in this way, as it makes the name non-standard compared to other data sources. It is interesting to note that the name is generally given as Blair-Bell, but the Library of Congress enters the name as Bell, W. Blair (William Blair), 1871-1936 (http://id.loc.gov/authorities/names/no92003069.html), so there is an inconsistency in how different services deal with hyphenated and compound surnames. It could be argued that once we have a match, the different formats matter less, as they are simply alternatives that can be used to identify the individual.
Hub names without structured markup
As stated, in the Hub names are marked up by surname, forename, dates, epithet, titles. However, there are still some entries that are not marked up like this, usually because they were created in proprietary software and exported. An example is Carlyon Bellairs (referenced in http://archiveshub.ac.uk/data/gb097-assoc17). The name is marked up as:
You can see the XML mark up at http://archiveshub.ac.uk/data/gb097-assoc17.xml?hub. We have been working on a script to markup the component parts of these names in the Hub, and we have been able to implement it successfully for several institutions. But it is not easy to do this with non-standard names (i.e. not in the surname, forename, dates, epithet format). We do have some instances of names such as the British Prime Minister, James Callaghan, or the author Rudyard Kipling, that are not yet marked up in this way. These individuals should be easy to match, but without the structure within the index term, it is harder for us to ensure that we can get just the name and dates from an unstructured name to match with VIAF.
It is also impossible to implement structured markup on a name where there is a compound surname entered according to NCA Rules – we simply cannot mark these names up correctly because we have no way of knowing whether part of the forename is actually part of the surname. For example, if we have the name “George, David Lloyd” we can’t write a script that can transform this into “Lloyd George, David” because most of the time a name like this will be two forenames and one surname.
The importance of life dates and the use of ‘Is Like’
If we don’t have life dates, it makes matching with certainty almost impossible. Of course, cataloguers can’t always find life dates for a person, but it is worth stressing that the need for life dates has become even more important in recent years, now we have the potential to process data in so many ways. An example is at http://archiveshub.ac.uk/data/gb532-bel – Joyce Margaret Bellamy, a Senior Research Officer at the University of Hull. As we don’t have a birth date, we did not get a match with her VIAF entry at http://viaf.org/viaf/94773174. If we have this kind of entry, without life dates, we could potentially decide to use a different status from an exact match (which usually uses the owl:sameAs property), and for example, we could use the ‘isLike‘ property from the Umbel vocabulary instead. This would be useful where we believe the two names to be referring to the same person, but this type of matching has to be done manually (although potentially we could run something where a name match without a date match was always an ‘isLike’). In the process of checking the 2,000 matches for our data we did enter a number of matches manually, and the whole process of checking took around 5 hours. Not too bad for 2,000 names, and with some time also given to thinking about the results (and making notes for this post!). But if we were to work on the entire Archives Hub data, we couldn’t undertake to do this kind of manual work unless we just had a few thousand ‘not sure’ names that we might be prepared to work through.
Matches without life dates
We do get matches to VIAF where we don’t have dates. We got a match for ‘Hilda Chamberlain’ with VIAF entry http://viaf.org/viaf/286538995/. This seems to be correct, as she is the daughter of Joseph Chamberlain, so we kept the match. But we had to check it manually. Another example is Hercules Ross – http://viaf.org/viaf/21209582/ – matched to the name in description http://archiveshub.ac.uk/data/gb254-ms17. But in this case we don’t really have enough evidence to identify the individual, even though the surname and forename match. The source of the name on VIAF is “Guild, J. Proceedings before the sheriff depute of Forfarshire … against Hercules Ross and David Scott, Esquires, 1809”, but the title deeds described in the Archives Hub cover the sixteenth to the nineteenth century!
With a name like Gustav Wilhelm Wolff (http://archiveshub.ac.uk/data/gb738-ms174), again we only have the name and not the life dates. The match given is for someone born in 1811 (http://viaf.org/viaf/8221966/), and the papers relate to Victorian Jews in Britain. This makes the match likely, but we can’t be sure without dates, so we could potentially enter an ‘is like’, to imply that they are the same person, but that we cannot be certain.
Floruit!
We had a number of individuals without known life dates where the cataloguer used a ‘floruit’, e.g. Sharman W. fl 1884 (Secretary of National Association for the Repeal of the Blasphemy Laws). This sort of entry, whilst it may be the total of the information the archivist has, is difficult to use to identify someone in order to match them. However, the majority of individuals with this kind of entry are not likely to be on VIAF simply because a floruit normally indicates someone for whom life dates cannot be found. It would be interesting to consider a tool that matches floruit dates to possible life dates (e.g. fl 1900-1910 would match to life dates of 1880-1945) but I’m not sure how much it would add much to the accuracy of a match.
Alternative names
The reconciliation service often works where VIAF provides names that are not ‘the same’ as our name. So, for example, the Hub data may have the name ‘Orton, John Kingsley, 1933-1967’. This was linked to Joe Orton (http://viaf.org/viaf/22163951), and within the VIAF data you can see that Joe Orton is also known as John Kingsley Orton.
Fame does not always give identity
Sometimes very famous people prove problematic, and an example is someone like Queen Victoria, because the name doesn’t include a surname and people tend to enter it in various ways. There were a few examples of this type of thing in our data, although most royal names matched with no problem. It always helps if it is easier to structure a name, but kings, queens, popes, etc. are non-standard.
Some Hub names are quite fulsome, such as “Edward Albert Christian George Andrew Patrick David, 1894-1972, Duke of Windsor, formerly Edward VIII, King of Great Britain and Ireland”. This should link to VIAF http://viaf.org/viaf/47553571 (Windsor, Edward, Duke of, 1894-1972), but the match was not given due to the lack of similarity.
Accented characters may cause problems
We didn’t get a match on Jeremy Bentham, despite having the full structured name, but this may be because the VIAF match has an accent: http://viaf.org/viaf/59078842/. We could possibly have stripped out accents in our data, but in this case the accent was in the VIAF data. I only found one example where this was a problem, but clearly many names do contain accented characters.
Matches sometimes surprise…
A particularly nice match came up for “Mary-Teresa Craigie Pearl 1867-1906 novelist, dramatist and journalist as John Oliver Hobbes nee Richards”. A complex string, but the algorithm matched the basic elements that we provided (Cragie Pearl, Mary-Teresa, 1867-1906) to the name ‘John Oliver Hobbes’ on VIAF.
Mismatches
Leonard Wright, a Leiutenant (http://archiveshub.ac.uk/data/gb99-kclmawrightlw) matched to Clara Colby (http://viaf.org/viaf/63445035/), also known as Mrs Leonard Wright Colby. Here is an example of an incorrect match due to the same name, but in VIAF the person is a ‘Mrs’ (due to the old fashioned practice of using the husband’s name). The reason for the match seems to be that the name on the Hub includes a floruit (Leonard Wright, fl 1916) which matches the death date of Mrs Leonard Wright (Leonard Wright, Mrs, d 1916).
On the Hub we have an example of an archive that includes “a letter from Charlotte Bronte to Elizabeth Firth”, and the name is simply given as Elizabeth Firth in the index. The match to VIAF was for Mrs J.F.B Firth (http://viaf.org/viaf/71217693/). In this case the match is wrong, as we can see from the Hub description that Elizabeth Firth is actually “Mrs. James Clarke Franks”, and the dates within the additional information don’t seem to match.
There were very few examples of this type of mismatch, but it shows why well structured data, with life dates, helps to minimize any incorrect matches.
Incorrect Suggestions
In the names that did not find definite matches (i.e outside of the 2,000 matches), there were a few examples of suggested names that did not bear much resemblance to the text provided. One example of this was for “Bell, Vanessa, 1879-1961”. The suggestions for ‘sameAs’ names to link to this individual were Stephen, Julia Prinsep British model, 1846-1895; Woolf, Virginia, 1882-1941; Stephen, Leslie, 1832-1904. In fact, VIAF does have Vanessa Bell (http://viaf.org/viaf/7399364), and the link appears to be that the names are related within VIAF (i.e. VIAF establishes that there is an association between these people). However, these were only suggestions, they were not given as matches.
Conclusions
If there was no match given, but we can see that the name and dates have gone to VIAF, then we would assume there simply is no match and VIAF does not have anyone with our surname, forename and dates. But if we can see an epithet has also been included in the data we have provided, then there may well be a match because the epithet can be problematic for finding a match. Our intention would be to continue to improve our filtering to try to remove all epithets, but if the names are not properly structured this can be difficult.
When actually checking data like this, one thing that really comes to the fore is the risk of a ‘sameAs’ where the individual is not the same, and this is a particular risk where you are dealing with a notorious character – maybe a criminal. A number of war criminals are referred to in the Hub data, and it would be very unwise to link these to the wrong person – this is why it is best to only provide matches where the life dates match, but it is not impossible to have the same name with the same life dates of course.
In conclusion I would say that wherever our names have life dates, and these can be successfully carried over to the matching process, the likelihood of a correct match is 99%, but there is always a risk of a mismatch. Clearly the main problem would lie with two people sharing a name and life dates, and the chances of this happening will increase if we only have birth or death date.
Last week I attended a meeting at the British Museum to talk with some museum folk about ways forward with Linked Data. It was a follow up to a meeting I organised on Archives and Linked Data, and it was held under the auspices of the CIDOC Documentation Standards Working Group. The group consisted of me, Richard Light (Museum consultant), Rory McIllroy (ULCC), Jeremy Ottevanger (Imperial War Museum), Jonathan Whitson Cloud (British Museum), Julia Stribblehill (British Museum), and briefly able to join us was Pete Johnston (worked on the Locah project and now on the Linking Lives Linked Data project).
It proved to be a very pleasant day, with lots of really useful discussion. We spent some time simply talking about the differences – and similarities – in our perspectives and in our data. One of our aims was to start to create more links and dialogue between our sectors, and in this regard I think that the day was undoubtedly successful.
To start with our conversation ranged around various issues that our domains deal with. For example, we talked a bit about definitions, and how important they are within a museum context. For example, if you think about a collection of coins, defining types is key, and agreeing what those types are and what they should be called could be a very significant job in itself. We were thinking about this in the context of providing authoritative identifiers for these types, so that different data sources can use the same terms. Effectively identifying entities such as names and places are vital for museums, libraries and archives, of course, and then within the archive community we could also provide authoritative identifiers for things like levels of description. Workign together to provide authoritative and persistent URIs for these kinds of things could be really useful for our communities.
We talked about the value of promoting ‘storytelling’ and the limitations that may inhibit a more event-based approach. DBPedia (Wikipedia as Linked Data) may be at the centre of the Linked Data Cloud, but it may not be so useful in this context because it cannot chart data over time. For example, it can give you the population of Berlin, but it cannot give you the changing population over time. We agreed that it is important to have an emphasis on this kind of timeline approach.
We spent a little while looking at the British Museum’s departmental database, which includes some archives, but treats them more as objects (although the series they form a part of is provided, this contextual information is not at the fore – there is not a series description as such). The proposal is to find a way to join this system up with the central archive, maybe through the use of Linked Data.
We touched upon the whole issue of what a ‘collection’ is within the museum context, which is often more about single objects, and reflected on the challenge of how to define a collection, because even something like a cup and saucer could be seen as a collection…or it is one object?…or is a full tea set a collection?
For archivists, quite detailed biographical information is often part of the description of a collection. We do this in order to place the collection within a context. These biographical histories often add significant value to our descriptions, and sometimes the information in them may be taken from the archive collection, so new information may be revealed. Museums don’t tend to provide this kind of detail, and are more likely to reference other sources for the researcher to use to find out about individuals or organisations. In fact, referencing external sources is something archives are doing more frequently, and Linked Data will encourage this kind of approach, and may save us time in duplicating effort creating new biographical entries for the same person. (There is also the move towards creating separate name authorities, but this also brings with it big challenges around sharing data and using the same authorities).
We moved on to talk about Linked Data more specifically, and thought a bit about whether the emphasis should be on discovery or the quality and utility of what you get when you are presented with the results. We generally felt that discovery was key because Linked Data is primarily about linking things together in order to make new discoveries and take new directions in research.
Wellcome Library, London
One of the main aims of the day was to discuss the idea of the use of design patterns to help the cultural heritage community create and use Linked Data. It would facilitate the process of querying different graphs and getting reasonably predictable information back, if we could do things in common where possible. Richard has written up some thoughts about design patterns from a museum perspective and there is a very useful Linked Data Patterns book by Leigh Dodds and Richard Davis. We felt this could form a template for the sort of thing that we want to do. We were well aware that this work would really benefit from a cross-domain approach involving museums, archives, libraries and galleries, and this is what we hope to achieve.
We spoke briefly about the value of something like OpenCalais and wondered whether a cultural heritage version of this kind of extraction tool would be useful. If it was more tailored for our own sectors, it may be more useful in creating authorities, so that we can refer to things in a common way, as a persistent URL would be provided for the people, subjects, concepts, that we need to describe. We considered the scenario that people may go back to writing free text and then intelligent tools will extract concepts for them.
We concluded that it would be worth setting up a Wiki to encourage the community to get involved in exploring the idea of Linked Data Patterns. We thought it would be a good idea to ask people to tell us what they want to know – we need the real life questions and then we can think about how our data can join up to answer those questions. Just a short set of typical real-life questions would enable us to look at ways to link up data that fit a need, because a key question is whether existing practices are a good fit for what researchers really want to know.
I don’t think we made much of a fuss about reaching 200 contributors, but we’re really pleased to say that we’re now into the 200’s and new contributors are coming on board regularly, which makes the Hub even more useful to even more researchers.
We’re currently trying out a bit of a whizzy thing with the contributors’ map – go to http://archiveshub.ac.uk/contributorsmap/ and try a few clicks and you’ll see what I mean. We particularly like the jump from Aberdeen to Exeter, and are looking for archives from further afield in order to execute even bigger jumps!
Speaking of contributors, we’ve made a few changes to our contributor pages. We now have a link to browse each contributor’s descriptions, and also a link to simply show the list of collections. This link was largely introduced to help us with our quest to bring the Hub out loud and strong through Google. We’re doing pretty well on that front….we’ve found that page views have gone up radically over the last few months, and that can only be good for archives. I think the list of descriptions can really look quite impressive – I tried Aberdeen and found collections from ‘favourite tunes’ to ‘a valuation of the Shire of Aberdeen’.
We’ve been busy on our new Linking Lives project, using Linked Data to create a Web front-end, and making the data available via an open licence. We’re really pleased that the vast majority of contributors have not asked us to exclude their descriptions, and many have emailed specifically to endorse what we are doing. This is brilliant news, and I think it shows that most archivists are actually forward-thinking and understand that technology can really benefit our domain (flattery will get you everywhere!). We want to ensure that archives are out there in the Web of Data, and part of the innovative work that is happening now. You may have seen a few blog posts to get going on Linking Lives: http://archiveshub.ac.uk/linkinglives/. Pete’s are rather more technical than mine, and brilliantly set out some of the difficult issues. I’m trying to think about what archivists are interested in and how we think about archival context. I hope our posts on licensing convey how much we are thinking about the best way to present and attribute the content.
Lastly for this month’s HubbuB, I’ve knocked up a fairly short Feature on the latest stuff that’s happening. I’m thinking of this as an annual feature – sometimes we are so busy we kind of forget to actually make a bit of noise about what we’ve achieved. You’ll see that we’re working on some record display improvements. I really hope I can show you these soon.
I have just come back from the Europeana Tech conference, a 2 day event on various aspects of Europeana’s work and on related topics to do with data. The big theme was ‘open, open, open’, as well, of course, as the benefits of a European portal for cultural heritage. I was interested to hear about Europeana’s Linked Data output, but my understanding is that at present, we cannot effectively link to their data, because they don’t provide URIs for concepts. In other words, identifiers for names such as http://data.archiveshub.ac.uk/doc/agent/gb97/georgebernardshaw, so that we can say, for example, that our ‘George Bernard Shaw’ is the same as ‘George Bernard Shaw’ represented on Europeana.
I am starting to think about the Hub being part of APENet and Europeana. APENet is the archival aggregator for Europe. I have been in touch with them about the possibility of contributing our data, and if the Hub was to contribute, we could probably start from next year. Europeana only provide metadata for digital content, so we could only supply descriptions where the user can link to the digital content, but this may well be worth doing, as a means to promote the collections of any Hub contributors who do link to digital materials.
If you are a contributor, or potential contributor, we would like to know what you think…. we have a quick question for you at http://polldaddy.com/poll/5565396/. It simply asks if you think its a good idea to be part of these European initiatives. We’d love to get your views, and you only have to leave your name and a comment if you want to.
Flickr: an easy way to provide images online
You will be aware that contributors can now add images to descriptions and links to digital content of all kinds. The idea is that the digital content then forms an integral whole with the metadata, and it is also interoperable with other systems.
I’ve just seen an announcement by the University of Northampton, who have recently added materials to Flickr . I know that many contributors struggle to get server space to put their digital content online, so this is one possible option, and of course it does reach a huge number of people this way. There may be risks associated with the persistence of the URIs for the images, but then that is the case wherever you put them.
Ideally, contributors would supply digital content at item level, so the metadata is directly about the image/digital content, but it is fine to provide it at any level that is appropriate. The EAD Editor makes adding links easy (http://archiveshub.ac.uk/dao/). If you aren’t sure what to do, please do email us.
Preferred Citation
We never had the field for the preferred citation in our old template for the creation of EAD, and it has not been in the EAD Editor up till now. We were prompted to think about this after seeing the results of a survey on the use of EAD fields presented at the Society of American Archivists conference. Around 80% of archive institutions do use it. We think it’s important to advise people how to cite the archive, so we are planning to provide this in the Editor and may be able to carry out global edits to add this to contributors’ data.
List of Contributors
Our list of contributors within the main search page has now been revised, and we hope it looks substantially more sensible, and that it is better for researchers. This process really reminded us how hard it is to come up with one order for institutions that works for everyone! We are currently working on a regional search, something that will act as an alternative way to limit searching. We hope to introduce this next year.
And finally…A very engaging Linked Data interface
This interface demonstration by Tim Sherratt shows how something driven by Linked Data can really be very effective. It also uses some of the Archives Hub vocabulary from our own Linked Data work, which is a nice indication of how people have taken notice of what we have been doing. There is a great blog post about it by Pete Johnston, Storytelling, archives and Linked Data. I agree with Pete that this sort of work is so exciting, and really shows the potential of the Linked Data Web for enabling individual and collective storytelling…something we, as archivists, really must be a part of.