As mentioned in my last post, we’re looking at the possibilities Artificial Intelligence and Machine Learning can offer the Archives Hub and the archives community in general. I also now have a wider role in Jisc as a ‘Technical Innovations Manager’, so my brief is to consider the wider technical and strategic possibilities of AI/ML for the Digital Resources directorate and Jisc as a whole. We continue to work behind the scenes, but we also keep a watch on cultural heritage and wider sector activities. As part of this I participated in the Aeolian Project’s ‘Online Workshop 1: Employing Machine Learning and Artificial Intelligence in Cultural Institutions’ yesterday.
‘Visual AI and Printed Chapbook Illustrations at the National Library of Scotland’ – Dr Giles Bergel (University of Oxford / National Library of Scotland)
Giles’ team have been using machine learning (ML) on data from data.nls.uk. He outlined their three part approach. First they find illustrations in manuscripts using Google’s EfficientDet object detection convolutional neural network seeded by manually pre-annotated images. They found the object detector worked extremely well after relatively few learning passes. There were a few false positives such as image ink showing through, marginalia and dog ears that would confuse the model.

Next they matched and grouped the illustrations using their “state of art” image search engine. Giles believes this shows that AI simplifies the task of finding things that are related in images. The final step was to apply classification alogorithms with the VGG Image Classification Engine which uses Google as a source of labelled images. The lessons learned were:
- AI requires well-curated data
- Tools for annotating data are no less important than classifiers
- Generic image models generalize well to printed books
- ‘Classical’ computer vision still works
- AI software development benefits from end-to-end use-cases including data preparation, refinement, consulting with domain experts, public engagement etc.
‘Machine Learning and Cultural Heritage: What Is It Good Enough For?’ – John Stack (UK Science Museum)
John described how AI is being used as part of the Science Museum’s linked data work to collect data into a central knowledge graph. He noted that the Science Museum are doing a great deal of digitisation but currently they only have what John describes as ‘thin’ object data.
They are looking at using AI for name disambiguation as a first step before adding links to wikidata and using entity recognition to enhance their own catalogue. It stuck me that they, and we at the Hub, have been ‘doing AI’ for a while now with such technologies as entity recognition and OCR before the term AI was used. They are aiming to link through to wikidata such that they can pull in the data and add it to their knowledge graph. This allows them to enhance their local data and apply ML to perform such things as clustering to draw out new insights.
John identified the main benefits of ML currently as suggesting possibilities and identifying trends and gaps. It’s also useful for visualisation and identifying related content as well as enhancing catalogues with new terminology. However there were ‘but’s. ML content needs framing and context. He noted that false positives are not always apparent and usually require specialist knowledge. It’s important to approach things critically and understand what can’t be done. John mentioned that they don’t have any ML driven features in production as yet.
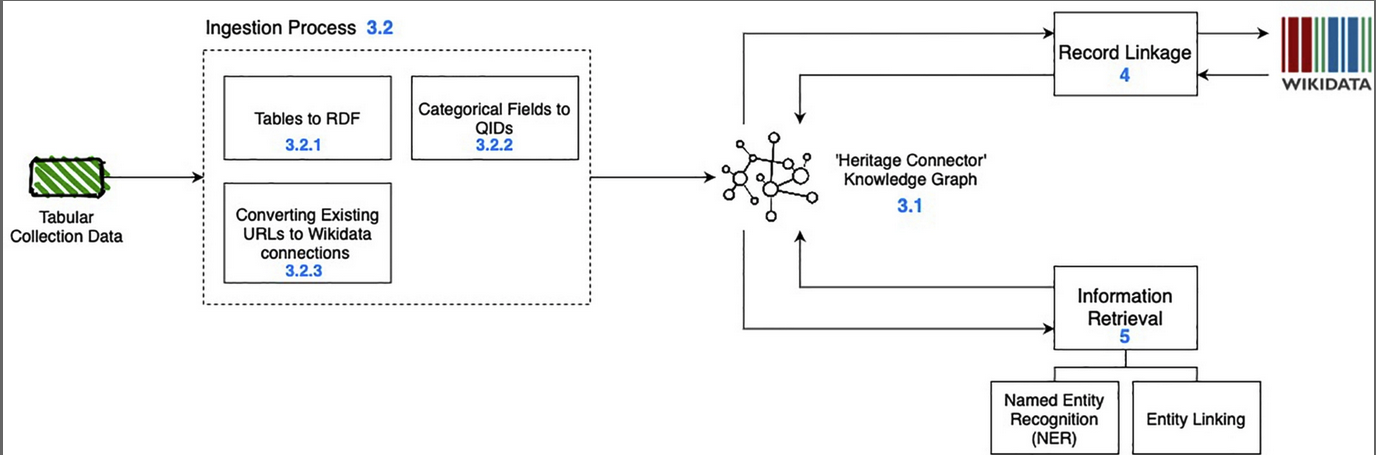
This was followed by a Q&A where several issues came up. We need to consider how AI may drive new ways/modalities of browsing that we haven’t imagined yet. A major issue is the work needed to feed AI enhancements into user interfaces. Most work so far has been on backend data. AI tools need to integrate into day-to-day workflows for their benefits to be realised. More sector specific case-studies, training materials, tools and models are needed that are appropriate to cultural heritage. See the Heritage Connector blog for more information.
‘AI and the Photoarchive‘ – John McQuaid (Frick Collection), Dr Vardan Papyan (University of Toronto), and X.Y. Han (Cornell University)
The Frick Collection have been using the PyTorch deep neural network to identify labels for their photo archive collection. They then compared the ML results as a validation exercise with internally crowdsourced data from their staff and curators captured by the Zooinverse software for the same photos.

They found that 67% of the ML labels matched with the crowdsource validations which they considered a good result. They concluded that at present ML is most useful for ‘curatorial amplification’, but much human effort is still needed. This auto-generation of metadata was their main use case so far.
‘Keep True: Three Strategies to Guide AI Engagement‘ – Thomas Padilla (Center for Research Libraries)
Thomas believes GLAMs have an opportunity to distinguish themselves in the AI space. He covered a number of themes, the first being the ’Non-scalability imperative’. Scale is everywhere with AI. There’s a great deal of marketing language about scale, but we need to look at all the non-scalable processes that scale depends on. There’s a problematic dependency where scalability is made possible by non-scalable processes, resources and people. Heterogeneity and diversity can become a problem to be solved by ML. There’s little consideration that AI should be just and fair.
The second theme was ‘Neoliberal traps’ in AI. Who says ethical AI is ethical AI? GLAMs are trying to do the right thing with AI, but this is in the context of neoliberal moral regulation which is unfair and ineffective. He mentioned some of the good examples from the sector including from CILIP, Museums AI Network and his own ‘Responsible Operations‘ paper.
He credited Melissa Terras for asking the question “How are you going to advocate for this with legislation?”. The US doesn’t have any regulations at the moment to get the private sector to get better. I mentioned the UK AI Council who are looking at this in the UK context, and the recent CogX event where the need for AI regulation was discussed in many of the sessions.
The final theme was ‘Maintenance as Innovation’. Information maintenance is a Practice of Care. There is an asserted dichotomy between maintenance and innovation that’s false. Maintenance is sustained innovation and we must value the importance of maintenance to innovation. He appealed to the origin of the word ‘innovation’ which derives from the latin ‘innovare’ which means “to alter, renew, restore, return to a thing, introduce changes in the way something is done or made”. It’s not about creating from new. At the Hub we wholeheartedly endorse this view. We feel there’s far too much focus on the latest technology meme and we’ve had tensions within our own organisation along these lines. There may appear to be some irony here given the topic of this post, but we have been doing AI for a while as noted above. He referred us to https://themaintainers.org/ for more on this.
Roundtable discussion with the AEOLIAN Project Team
Dr Lise Jaillant, Dr Annalina Caputo, Glen Worthey (University of Illinois), Prof. Claire Warwick (Durham University), Prof. J. Stephen Downie (University of Illinois), Dr Paul Gooding (Glasgow University), and Ryan Dubnicek (University of Illinois).
Stephen Downie talked about the need for standardisation of ML extracted features so we can re-use these across GLAMs in a consistent way. The ‘Datasheets for Datasets’ paper was mentioned that proposes “a short document to accompany public datasets, commercial APIs, and pretrained models”. This reminded me of Yves Bernaert’s talk about the related need for standardisation of carbon consumption measures. Both are critical issues and possible areas for Jisc to be involved in providing leadership. Another point that Stephen made is that researchers are finding they can’t afford the bill for ML processing. Finding hardware and resources is a big problem. As noted by ML guru Andrew Ng, we have a considerable data issue with AI and ML work . It may be that we need to work more on the data rather than wasting time, electricity and money re-creating expensive ML models. A related piece of work, ‘Lessons from Archives‘ was also mentioned in this regard. There is a case for sharing model developments across the sector for efficiency and sustainability here.