Have you ever wondered what LGBTQ+ archives might be held at North East Wales Archives (NEWA)?
North East Wales Archives images.
Today, we would like to shine the spotlight on some of the initiatives which are helping Wales to uncover the LGBTQ+ heritage held within our archives. It can be quite a challenge to find records of this type of history since, because of its historically subversive nature, it was often hidden, destroyed or even put into code to avoid discovery. Searching for records of LGBTQ+ history can prove difficult, because the terms that were used historically are different to those used in today’s language. Glamorgan Archives have put together an extremely helpful guide (PDF) called ‘Queering Glamorgan’, which also has an essential glossary of words and terms to help researchers find articles and stories in historic newspapers.
Colourised image of archival storage units #LGBTQ (NEWA/Adobe Spark).
Societies like #Draig Enfys or #Rainbow Dragon are working tirelessly to find and share the stories and lives of people in Wales throughout the ages and to help us to explore the archives for ourselves. Draig Enfys is a research group set up by Norena Shopland, who specialises in researching, recording and promoting LGBT+, women’s and Welsh histories; Mark Etheridge, National Museum Wales; and Susan Edwards, Glamorgan Archives. They wanted to create a forum for researchers to network, help each other out and prevent people working on duplicate subjects. They saw the benefit of people joining forces and collaborating together in this often lonely field of research.
There is also a hive of creative activity in this field, with original research being undertaken in Wales. Projects like Living Histories Cymru, run by Jane Hoy and Helen Sandler, bring historic Welsh LGBTQ+ individuals to life through lively, costumed talks and plays. Other researchers and groups of young people are currently working with National Museum Wales to host various exhibitions and publish books on LGBTQ+ history.
James Henry Lynch: The Rt. Hon. Lady Eleanor Butler & Miss Ponsonby ‘The Ladies of Llangollen’. A portrait from the Welsh Portrait Collection at the National Library of Wales. Image in the public domain via Wikimedia Commons.
At the Denbighshire branch of NEWA, we hold Minutes of the weekly medical officers meetings which contain details of patient cases, including discussions on the benefits and problems associated with ECT treatment, and brief details on the treatment of a homosexual patient in March 1968. We also hold records relating to the celebrated ‘Ladies of Llangollen’, ‘romantic friends’ in the 18th century, who ran away together to escape the constraints of patriarchal society to live together in isolation. Newspapers and court records at both branches are also rich sources of LGBTQ+ stories and pathways to further research.
Photographs of the Hawarden (Archifdy Sir y Fflint / Flintshire Record Office) and Ruthin (Archifau Sir Ddinbych / Denbighshire Archives) branches.
If you are interested in LGBTQ+ history, why not try using the terms in Glamorgan Archives’ glossary to search for stories in online newspapers? You can also visit our website to uncover more sources of historical stories from your local area!
Teresa Davies Archive Assistant North East Wales Archives/NEWA (Hawarden)
In the last Names post I wrote about the 4-step process that covers ‘matching and meaning’. Step 2 was ‘Structuring data’, which means implementing a process to structure the elements that form part of a name string.
Many names are not structured. But if we can process the data to create better structure, we have a much better chance of matching it to other entries.
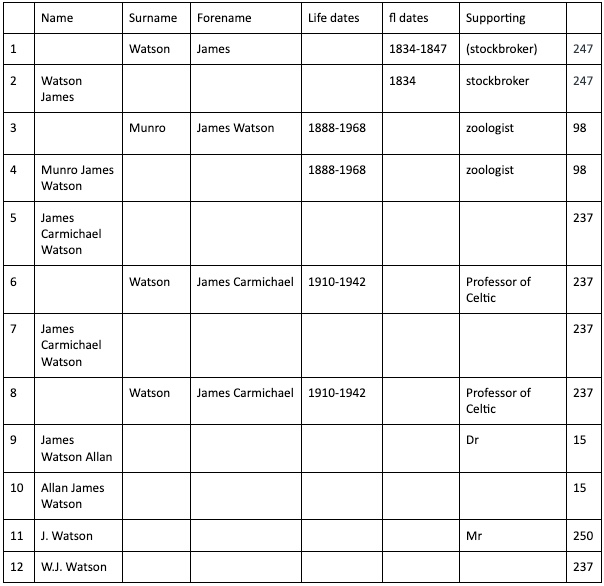
Here is a table showing some name entries around ‘J Watson’ (my examples are taken from real data, but sometimes tweaked a bit in order to cover different types of patterns – all the patterns will be found within the data).
Names based around ‘J Watson’ put into a structure table
The elements have been put into columns, and this is the idea with our structuring process. Some names are still strings – we cannot always know which part is a surname and which part a forename; and some names do not have that kind of structure anyway. We hope to identify floruit dates, and categorise them as distinct from life dates. We don’t want to match ‘1888-1938’ with ‘fl 1888-1938’ (although we might want to see this as a potential match). We will aim do something similar with birth and death dates. We want to gather all the information that is not a name or a date as ‘supporting information’.
Once we have the structure, it is far more likely we can match the name, and also control our level of confidence about matching. Here is a shorter table based on some of the entries from above:
name
surname
forename
dates
fl dates
info
Watson
James
1834-1847
stockbroker
Watson James
1834-
stockbroker
Watson
J
b 1834
Mr
James Watson
1840-1847
You can see that two of the names are simply name strings. We may not be able to identify a surname and forename in ‘James Watson’ or ‘Watson James’. With the structure that we have imposed, it is possible to write a name matching process that provides a match between the first and second entries in the above table, because we can say with some confidence that a name that includes ‘James Watson’ and that has the birth date of ‘1834’ and the additional information ‘stockbroker’ refers to the same person. We might say this is a ‘definite’ match, or a ‘probable’ match. The third entry could be a ‘possible’ match, as it includes ‘Watson’ and ‘J’ with the same birth date of 1834. If the fourth entry had ‘stockbroker’, for example, then we might consider a possible match, but as things stand, it would not be a match.
It is very important that the interface we develop indicates to end users that we are matching name strings. There is a distinction between matching name strings and simply stating that X and Y are the same person. This will help us with introducing the idea of likely, probable and possible matches.
This structuring work is absolutely at the heart of creating a name interface, and enabling researchers to look up ‘James Watson’ and then potentially go in many different directions through the connections, finding ways that archives may be related. But it is really challenging. We will not ‘get it right’. Even if we had really substantial resources and time, we could not make it perfect. Archivists, as information professionals, are keen on ‘getting it right’, which is usually a good thing; but pulling together information using names created over decades, by thousands of cataloguers, in different systems, without a clear standard to work to….it ain’t ever going to be perfect. The key question is, whether this will substantially enhance the researcher experience and allow new connections to be made. And whether it will enable us to create connections outside of the archives domain. We have to have a change of mindset to accept that it is not perfect, but it is still hugely beneficial to research.
Just to emphasise the variation in data that we have, here are some EAD names, given as they are structured. They are all fine displayed within a description, suitable for a human reader, but they create challenges in terms of name matching. When you look at these, you have to think of the structure and semantics – essentially, how can we write an algorithm that allows us to truly identify the person (or that they are not a person!):
<persname>Barron, Lilias Mary Watson (b1912 : science graduate : University of Glasgow, Scotland)</persname>
<origination label=”Creator: “><persname role=”author”>Name of Author: various </persname></origination>
The last one was actually taken directly from VIAF and imported into the Archives Hub, which is, in principle, a really good way to create a structured name. Unfortunately, the process of pulling it into the Hub using the VIAF APE did not go quite according to plan. VIAF has just the same challenges as we do – there will be structural mistakes. However, it has the VIAF ID, so funnily enough, it is easier to match than many other names.
Many of the above examples are names added as archival creator names (‘origination’). Unfortunately, there has been a tendency for cataloguers to add creator names in a very unstructured way. The old Archives Hub Editor used to encourage this, and most archival systems have a free text field for name of creator. (Now, our Editor structures the creator name and adds it as an index term – so they are both identical).
We are currently looking at the challenge of matching origination name with the index term within the same description. That may sound like an easy task, but very often they are really quite different. For example, for the name of creator you may get:
<origination>Name of Authors: various but include Reverend<persname role=”author”>Thomas Frognall Dibdin</persname>,<persname role=”author”>Richard Bentley</persname>,<persname role=”author”>Philip Bliss </persname>and<persname role=”author”>Frederick James Furnivall</persname></origination>
This is nicely structured, so that it is easy to see that they are separate names, although the lack of life dates makes unique identification more difficult. If these individual names are also added as index terms, then we want to create just one entry for e.g. ‘Thomas Frognall Dibdin’ – we don’t want two entries for the one name (taken from the ‘origination’ and the ‘controlaccess’ index area) that both represent the same archive collection.
A common pattern is something like:
<origination label=”name of creator:”>Frances Dennis</origination>
‘Frances Dennis’ as a name string is very likely to be a match with ‘Frances Mary Dennis b1847 missionary’ when it is within the same collection. If these two entries were in different descriptions, we would not match them.
Our pre-match structuring will go a long way to increasing the number of matches, and hence the intellectual bringing together of knowledge through names. Matching creator name and index term name will reduce the amount of duplication. The framework will be tweakable, so that we can constantly review and improve.
Over the past few years at the Salvation Army International Heritage Centre, we have been working towards digitising parts of our collections in order to provide open access to them online. Our digitisation has been focussed on small, self-contained series of nineteenth-century periodicals and pamphlets from The Salvation Army’s early history. We envisaged these digital collections not only as ways of allowing more people to use and enjoy the material, but also as places where we could put the historical material in context and provide other helpful tools like indices and research guides. As they represent only tiny fraction of our holdings, these digital collections were never intended to be a substitute for accessing our collections in person. However, when in March 2020 we had to close to the public and limit our own access to the archives due to the global response to the COVID-19 pandemic, they unexpectedly became one of the few ways we had of keeping ourselves and others connected with our collections.
Three of the digital collections that we have created so far have now been added to Archives Hub as Online Resources. They are all still works in progress that will continue to grow as we are able to add to them, but this feature provides an introductory overview.
The Darkest England Gazette
In October 1890 — just over 130 years ago — The Salvation Army’s founder William Booth published what is probably his best-known and most influential book, In Darkest England and the Way Out. Planned and researched in under a year while his wife Catherine was terminally ill and released just weeks after her death, the book was penned with substantial assistance from the journalist WT Stead, a family friend and supporter of The Salvation Army’s work. Taking inspiration from the title of Henry Morton Stanley’s In Darkest Africa, published earlier the same year, In Darkest England described the social landscape of the United Kingdom as it had come to be seen by Booth over the course of 25 years of directing The Salvation Army’s evangelistic and social work among people living in poverty.
In Darkest England lithograph.
Booth estimated that a tenth of the country’s population experienced conditions of such extreme misery and destitution that it had become impossible for them to improve their lives without assistance. He called these people ‘the submerged tenth’ and the striking and colourful frontispiece of the book (the work of an unknown artist) shows them struggling to stay afloat in a turbulent sea as waves of hardship (unemployment, starvation, drunkenness, want and sin) crash over their heads. The book set out Booth’s grand plan for rescuing them, which would form the basis for The Salvation Army’s social work going forward. The overarching idea was to reverse the urbanisation that Booth saw as being at the root of so many contemporary social problems by creating a system of ‘colonies’ which would provide shelter, work and support. He intended that people progress through these in a landward direction, starting off in the ‘City Colony’ before moving to the ‘Farm Colony’ and then ultimately to the ‘Colony across the Sea’ where, in the dominant imperial view of the time, open land was considered plentiful and available for the taking.
In Darkest England sold exceptionally well—its first print run sold out on the day of publication and two more editions were printed by the end of the year. Although the reception from readers was mixed, it succeeded in providing the finance and impetus for the rapid expansion of Salvation Army social work and the establishment of many of the institutions Booth had envisaged. The Darkest England Scheme, as The Salvation Army’s organised social work became known, had far-reaching and lasting effects on both The Salvation Army and wider society that have recently been explored in a new anniversary publication, In Darkest England 130 Years On (London: Shield Books, 2020). At the time, however, the Scheme’s objectives and achievements were reported in a weekly newspaper called The Darkest England Gazette which is the subject of one of our digital collections.
The Darkest England Gazette ran from 1 July 1893 to 16 June 1894, after which it continued under the new name The Social Gazette. The Social Gazette soon adopted a smaller, cheaper 4-page format, and it continued to be published in this form until 1917. All 51 issues of The Darkest England Gazette have now been digitised and a growing selection is available online. The digital collection also includes a series of research guides that offer brief introductions to prominent themes from the Gazette which include some quite surprising subjects from animal welfare, vivisection and vegetarianism to poetry and popular fiction.
The Christian Mission
The Salvation Army counts its age from July 1865, but its current name was not adopted until 1878. For most of the first 13 years of its existence it was known as The Christian Mission. The Mission grew out of the East London Special Services Committee, a group of Christian businessmen who did evangelistic work in the east end of London. William Booth, a former Methodist turned independent evangelist, first had contact with this committee in June 1865, when he preached at a meeting organised by them at the Quaker Burial Ground in Whitechapel. Within a short time, he had been asked to give permanent leadership to their ministry and over subsequent decades, grew it into an international movement.
Christian Mission Magazine, January 1870.
From October 1868, the Mission began publicising its work by means of its own monthly magazine, which ran until it was superseded by the well-known War Cry in December 1879. This magazine is one of the most important surviving sources of information about the early development of The Salvation Army and its expansion from the east end of London throughout the UK. We have now put many issues online alongside a selection of other documents produced by the Mission.
Rare pamphlets
As our other digital collections show, since its earliest days as the Christian Mission (and even before), The Salvation Army’s leaders and members have been prolific publishers, not only of periodicals and books, but also of various forms of pamphlet. One of the earliest in our collection is an 1870 edition of Catherine Booth’s treatise Female Ministry, or Women’s Right to Preach the Gospel, which is a revised version of her 1859 pamphlet Female Teaching. No known copies of the first edition survive but a second edition of her original text dating from 1861 survives in the John Rylands Library at Manchester University. Catherine’s views shaped The Salvation Army’s position on women preachers, whose equal status with their male counterparts has been written into the organisation’s constitution since 1870.
Catherine Booth.
This pamphlet and more than seventy others are now accessible online in our Rare Pamphlets Collection, covering a wide variety of subjects from slum ministry and social work, to international missionary work, to biographies and songs.
Ruth Macdonald Archivist & Deputy Director The Salvation Army International Heritage Centre
High up on a sheltered, well lit corner of a wall in an outbuilding at Cotesbach Hall can be deciphered a faint scribbling entitled ‘TOTAL TATERS 1920’ [1].
Writing on the Wall, Cotesbach Hall: ‘Total Taters 1920’. Photo: Tom Clark, CET Archive volunteer.
The unmistakeable hand of Rowley Marriott (1899-1992) can be discerned listing the weight of potatoes yielded from each of three areas in the walled garden, to a total imperial equivalent of 1,238 kg, nearly three times what we considered to be an exceptional yield this year, 420kg. Struggling out of the war years, the family having lost two sons on the bloody fields of Flanders and then Father who died of grief in 1918, this harvest would have been no mean feat, and their circumstances many times more challenging than ours. What may seem a trivial detail holds spine tingling resonance for us, a most tangible, personal connection to the people who lived here before us. It was a remarkable harvest a century ago, otherwise the result would never have been written on the wall.
We are very fortunate that the Cotesbach Archive preserves a mine of documents which enable us to piece these stories together connecting people to place, and to wider context. Rowley was one of seven brothers whose boyhood was filled with occupations such as collecting birds eggs [2] and following the hunt, through which they learned to know and love the countryside around, the names and characteristics of each field and spinney.
Record of birds’ eggs collected by Marriott brothers of Cotesbach, 1910-1913, Digby (1895-1915), Rowley (1899-1992), Michael (1900-1974).
They stepped up to the challenge of vegetable production when the war came along with a spirit of novelty and competition which shows through in Rowley’s letters from his brother Michael, who nicknames him ‘My dear old Parsnip’, signed ‘Your blasted Broccoli’, describing to some extent what and how they were growing. Yet the yield from an initial search on ‘harvest’ in the archive catalogue is sparse: Mother (Mary Emily nee Peach 1862-1934) writing to their elder brother James ca 1914, along with reporting on the tenant farmer’s arable harvest mentions that: ‘Potatoes are being taken up, so there is plenty to do in the garden’ [3, understatement!]. So often, the commonplace is un-remark-able.
Letter from Mary Emily Marriott to her eldest son James, September 13th 1914. COTMA:5413.
Engrossed in cultivation as we have been this year, we are curious for more knowledge of traditional cultivation methods, management, storage, diet. Did they only eat potatoes, and game? Detective work into estate maps, periodic reports, receipts and correspondence will gradually reveal more, but the very absence of everyday detail is an indication of social change. Families of landowners who had previously relied on farm labourers were undergoing hardship themselves and stepped into vegetable production when it was needed most. There were mouths to feed at Cotesbach Hall, 11 residents recorded in the 1911 census, 19 a generation earlier in 1861 out of a village community of 186 (108 in 1911). Harvest time is backbreaking work, dependent on the weather, sadness at the end of summer mingled with celebration of work well done.
It was a way of life, the annual round, which for a scarcely educated farmer would involve attending Sunday church, with its diet of interminable sermons. One such work of Rev. James Powell Marriott delivered for Harvest Thanksgiving on 6th October 1864 warns repeatedly of God’s ultimate harvest of souls and His Almighty Hand which could wreak revenge just as blessing to the crops, implying the villager’s conduct would make a difference, whilst rays of light pouring into the nave would have only reminded him of work to be done, and his disappointment that the Wake or Harvest Festival had been cancelled due to villagers’ overindulgence in previous years. We empathise with that, yet also wonder at the change in values and ideologies, in these days of locked down pews, witnesses as we are of a Faustian reality where humans have induced climate change wreaking havoc with weather patterns, and the need to build and rebuild skills, knowledge and science of the environment which is greater than ever before.
When we agreed to do a slot for the Archives Hub this time last year, the world was a very different place, with our plans to take on four MA students from Leicester University for their summer placements getting under way, the results of which would have provided displays for Heritage Open Days and content for this article. Everything changed with lockdown, yet in all four areas we have made progress, enabling us to be even better placed for next year’s students. Additional HLF funding has brought forward the task of solving the question of migration of our Item level records to the Hub, which involves adopting CALM software, instead of MODES. Back in 2008, the latter seemed the most suitable match for our holistic approach to heritage, our overall aim being to preserve not only the archive but the material culture and books belonging to past generations which retain associations and have already frequently been used as educational resources and display material for the CET. Each object, especially combined with document and imagination, is a doorway into history, into time travel, into discovery.
Our catalogue records need to be as versatile as any of these possibilities, not locked into proprietary arrangements, ensuring it stays relevant and dynamic for new generations. When harvest time comes for our crop of catalogue records it is hoped that the yield will be plentiful, its quality sound, that it will reflect diversity over monoculture, the commonplace and the extraordinary – that there will be much to celebrate and fertile ground for new seed to be sown – starting with new placement proposals for summer 2021.
Smith’s Potato Crisps vintage tin 1930s, Cotesbach Family Trust.
This year has made us more attuned to the unexpected, more likely to see things with fresh eyes. And so, returning to the most wonderful subject of potatoes, this Smith’s Crisps tin suddenly came into the spotlight, from a dark corner containing bits and pieces roughly where it has sat since the 1930s [4]. My retro-hope is that after all the loss and drudgery, Mother experienced the pleasure of a ‘dainty and appetising’ potato crisp before her day of reckoning.
Sophy Newton Heritage Manager (Hon) Cotesbach Educational Trust
Related
Records of the Marriott Family of Cotesbach, 1661-1946 on the Archives Hub
Firstly, an apology to those who commented. I was on a temporary machine for a while and didn’t get the notifications to approve the comments. I really appreciate feedback! And we need to think about this whole topic as an archive community.
Secondly, I wanted to pick up on some comments:
“If cataloguing archivists have access to a central pot of name authorities we are more likely to spot and re-use existing authority entries. So if one archivist identified Elizabeth Roberts 1790-1865 (artist) with a little potted biography which placed her in Penge, then a later archivist finding material from Lizzie Roberts in Penge in 1850s is much more likely to put 2 and 2 together manually”
In fact, one of the potential developments from the work we are doing is an interface specifically for cataloguers. The whole issue of ‘match’, ‘probable’ and ‘possible’ is tricky to present to end users, but relatively easy to present to cataloguers to help with creating names that will successfully be connected. So, we are bearing that in mind as a future development.
“When I looked at the list of names used in this article I thought ‘someone just doesn’t know what to include to properly describe a name”
Yes…I think that sometimes, when I am thinking about how to reconcile the massive variations and how to work with the lack of structure. But then I remember what it was like (when I was a proper archivist) to catalogue within time constraints. And I also remember that I am someone who spends half my life thinking about data! In addition, the point is that with archives it is perfectly valid to enter a name such as ‘Julia (fl 1976)’ because that is what you get from the item you are cataloguing, and nothing more. Maybe you could undertake research to find out who that it, but that would extend the time it takes to catalogue by days, if not weeks and months. For a researcher, this might jog something in the mind and lead to a connection being made. Something is better than nothing. For me, the entries that are rather more frustrating are names such as ‘various’ or ‘Author: various’, or ‘James MacAllister and various’ because these just aren’t names. However, many of these entries were probably created in a time when semantically structured data was not so important.
“The other way of dealing with this is to leave the final decision up to the end-user.”
Yes, this is a fair point. In our current thinking, the idea is that we have levels of confidence that we present to the user, and that allows them to make the decision. But we still need to think carefully about how to do this in a way that most clearly conveys meaning. The most difficult thing is to convey that even though you have linked several collection descriptions to one name, other name strings may also be a match. But at the end of the day, there is always the issue that decisions you make around the navigation and options provided to end users means they are likely to exclude some relevant results. A subject search will exclude any archives not indexed with that subject. Do you therefore dispense with a subject search? (More in this in future posts, as machine learning may present us with new tools to create subject entries).
Since my last post we actually hit the point of ‘blimey, this is just too difficult’. We really weren’t sure we were going to make this work, given the tremendous variations and, in particular, the lack of structure.
However, we have hacked our way through the undergrowth to create a path that I think will fulfil many of our aims. There is so much I could say, if I got into the detail of this, but I will spare you too much discussion around EAD and JSON structure!
A good part of the last few weeks from my point of view has been clarifying the thinking around what is required when processing names. I came up with the idea of the ‘4 pillars of names’.
Matching
This refers to comparing and grouping names.
Matching does not require us to know if it is a person or an organisation or to know anything about meaning at all. It is simply a process to group names. So, ‘D J MacDonald’ could be a company or a person. The question is, does that match ‘David John MacDonald’ or ‘D J MacDonald, manufacturers, Carlisle’?
Matching is therefore also about levels of confidence. It is about saying ‘D J MacDonald b.1932’ is the same as ‘D MacDonald b.1932’….or not.
Matching may also mean matching a creator name and an index term within a record. For more on this, see below.
2. Meaning
Name meaning is about whether it is a personal, corporate or family name. Many creator names are just ‘creator’. There is no tagging to distinguish the type. Index terms have to have a type, but matching them up to creator name is not always easy. See more on that below.
3. Search behaviour
What happens when the user clicks on the name? Previous posts have presented our ideas for this. Whilst we are not yet ready to develop an end user interface, the options that are available to us for display are necessarily constrained by how we process the data. So we do need to think about this now.
4. Display
How we display a name record, or a name page. Again, not something we are focussing on now, other than to think about the sorts of features that we want to include.
* * *
Our discussions have been characterised by ‘one step forwards two steps backwards’, which can feel a little dispiriting. But we believe we have now sorted out the approach we need to take. I have spent a lot of time working collaboratively with Rob Tice from Knowledge Integration, unpicking the (many and varied) challenges in the data and as a result we’ve agreed an approach that we believe will produce the data that we want.
So, this again consists of 4 parts – a 4-step process that covers matching and meaning.
Matching within a collection description
We need to try to match the creator name to the index term, if we have both. This is the first step in the workflow. To do this, the processing needs to identify names within one collection (each name needs to be attached to a collection via a reference).
Taking the description of the Caledonian Railway Company as an example (https://archiveshub.jisc.ac.uk/data/gb248-ugd008/7andugd8/38). The name appears as:
We want to create one entry for these names that we take forwards into the de-duplication process. In this case, the names are all marked up as corporate names. But in many cases the creator is not marked up in this way. We need a process to match these entities to say that they are the same. This is about applying matching at the level of one collection, rather than across collections. When you apply it to one collection, you can decide to make more assumptions. For example,
Creator: Dorothy Johnson Index term: Johnson, Dorothy, 1909-1966, Researcher into theatre history
This creator is not marked up as a personal name. If we worked with these entries in our general de-duplication, so that they were not associated with one particular collection, we could not say they are the same person. Indeed, we could not identify ‘Dorothy Johnson’ as a person, only as a creator. The relationship of these two entries would get lost. But within one collection description, we can make the assumption that they represent the same thing.
If we make this the first step we can remove many of the creator-as-string names from the processing – they will already be matched to a structured index term.
2. Structuring data
This is a process of following rules to structure data. Many names are not structured. PIDs (persistent identifiers) can by-pass this need for consistency, but at present the archive community barely uses recognised identifiers. I have posted previously on name authorities and structure. So, anyway, to introduce a bit of EAD, you might have:
<persname><emph altrender=”surname”>Nightingale</emph><emph altrender=”forename”>Florence</emph><emph altrender=”dates”>1820-1910</emph><emph altrender=”epithet”>Reformer of Hospital Nursing</emph></persname>
If we can process the first entry to give the kind of structure you see in the second entry that enables us to carry out de-duplication, and we have a much better chance of matching it to other entries. This is decidedly non-trivial, and we won’t be able to do this for all names.
3. De-Duplication
This is the process outlined in the blog post on de-duplication at scale . Once the other processes are in place, we are in a position to run the de-duplication process, and start to try out different levels of confidence with matching.
A working example: George Bernard Shaw
collection match:
George Bernard Shaw (gb97-photographs) matches: Shaw, George Bernard, 1856-1950, author and playwright (gb97-photographs)
structure rules:
apply rule: if it includes YYYY-YYYY and the preceding words include a comma then the first entry is a surname and the second entry is a forename apply rule: YYYY-YYYY is a date apply rule: words after YYYY-YYYY are additional information
Creates: Surname: Shaw Forename: George Bernard Dates: 1856-1950 Additional information: author and playwright
de-duplication:
The structured entry matches a name from another description:
So, we are now in the process of implementing this workflow. The current phase of this project will not allow us to complete this work, but it will lay the foundations. Of course, we’ll find other challenges and issues. We still don’t know how successful we will be. There will definitely be names we can’t match and we can’t identify as personal or corporate. But then it is down to how we present the information to the end user.
I called this post ‘A 4 year old in red wellington boots’ because in her comment on the previous blog post Teresa used that as a metaphor for how we can think about data. We need to explore, to play with data, to search and discover, to not mind getting dirty. It is easy to get stressed about not getting everything right; but we need to jump into the puddles and just see what happens!
Now more than ever as we continue to battle the COVID-19 pandemic, the world is reliant on its digital infrastructure; the need to provide and access accurate and up-to-date information is of paramount importance. This raises some interesting questions, challenges and opportunities for archive services who can play their part in the collective response to the crisis by capturing and recording events, activities and decisions. Archives and recordkeeping professionals have always supported the notions of accountability and transparency through their work, something which is being demonstrated in real time during the development of the pandemic.
As the UK’s largest trade union and professional association for nurses, the Royal College of Nursing (RCN) has been supporting and representing nurses and healthcare workers throughout the pandemic. It is vital that records of how this has been done are available to the organisation in perpetuity as evidence of advice given and decisions taken. The RCN has a responsibility to its members to be able to demonstrate that the organisation has been working in their best interests and the interests of their patients. In turn, the RCN archive has a responsibility to ensure that records with evidential and research value are captured, preserved and accessible to right audiences at the right time.
One of our first attempts at archiving the RCN COVID-19 webpages using our digital archive.
As a result, like many of our archivist and recordkeeping colleagues across the world, we have created a COVID-19 archive. Since the beginning of the year the RCN archive team have been actively collecting records relating to COVID-19 from across the organisation to build up a picture of how the pandemic has unfolded through the eyes of RCN members and staff. Unsurprisingly, this covers a wide range of record types and digital formats: web crawls of special COVID-19 webpages containing up-to-date guidance and advice, targeted staff emails, member surveys on working conditions and PPE, General Secretary’s video messages, special committee situation reports, newly created online nursing resources, publications – the list could go on. Within this set of records is a complex combination of access requirements and restrictions which, through balancing business confidentiality with public interest, we will manage alongside the records themselves.
We are in the fortunate position of having a remotely accessible network and a digital archive, which has meant that we have been able to collect these records as they have been created and start uploading them to our digital archive straight away. While some of the records we’re collecting as part of the COVID-19 archive project would have been transferred to us anyway, there are several new record series on our 2020 collecting plan as a result of the pandemic. For example, our first venture in web archiving was a test crawl of the RCN COVID-19 webpages; these are now collected regularly and form an integral part of the COVID-19 archive. Having seen and been inspired by the experiences of other archives already running successful daily web crawls to capture public advice and the public response, we decided to capture our pages daily as well – this ensured that we were keeping up to speed with each piece of new advice and guidance shared on the webpages. As the rate of updates to the pages has slowed, we have since reduced the frequency to weekly, although we continue to monitor them, ready to capture more frequently if needed. This was the pilot web archiving project we didn’t know we were doing until it happened, and it has in turn has sparked interest in a larger web archiving project to capture the whole RCN website, which is well underway.
A video message from Donna Kinnar, General Secretary, on the staff intranet. An example of the range of formats collected for the COVID-19 archive.
Alongside the collecting of material, we have been considering how the records of the COVID-19 archive will fit into our existing catalogue structure. While it would be easy to create a new Fonds for COVID-19, we realised that this view was being skewed by our thoughts about future access to the material, and the ease at which colleagues or researchers would be able to view all the material neatly packaged together. Instead we plan to preserve the context of the records by arranging them by creator, in our case this is mostly the department of origin, to fit within our existing catalogue structure. There will be occasions when it is important to view all COVID-19 records together to get a complete picture of the reaction and response to the pandemic, so using the ‘linked collection’ feature in our digital archive we plan to create a virtual COVID-19 collection containing records from across different record series to allow this level of access. Beyond this we are considering which records from our COVID-19 archive will be shared on our public digital archive website to ensure the transparency and accountability that creating the COVID-19 archive in the first place helps to achieve.
We have certainly learnt a lot this year and the team has upskilled, becoming more proficient and confident in processing a wide range of digital formats, from collection through to access. Our sector has also stepped up by providing online webinars and training events to share our experiences of this extraordinary time. In May we participated in a panel discussion facilitated by Preservica, our digital archive supplier, who generously donated 250GB of storage space for us to store the COVID-19 archive. At the event we shared our plans and projects for collecting COVID-19 records with the archive community alongside colleagues from a wide range of institutions. These included Network Rail, who have been collecting records such as emergency train timetables introduced in response to the falling customer demand, and all the documentation that went into making this happen, and University at Buffalo in the US, who are encouraging students and staff to share their experiences of the pandemic by submitting video diaries and photographs to the archive. Learning about and reflecting on the wide range of collecting projects happening around the world is as informative as it is inspiring.
An example of a publication for the COVID-19 archive. This is the cover of the April 2020 Bulletin RCN members magazine.
It is amazing to think that in the (probably not too distant) future the COVID-19 records we have collected will be catalogued, available to view online through our digital archive and be being used to inform research into, and evaluations of, the response of the UK’s largest independent nursing organisation and our role in how Britain handled the pandemic.
Katherine Chorley, Digital Asst Archivist Royal College of Nursing Archives
Related
Browse all Royal College of Nursing Archives collections on the Archives Hub.
This blog post forms part of History Day 2020, a day of online interactive events for students, researchers and history enthusiasts to explore library, museum, archive and history collections across the UK and beyond.
Use the Archives Hub, a free resource, to find unique sources for your research, both physical and digital. Search across descriptions of archives, held at over 350 institutions across the UK.
History Day 2020 coincides with the Being Human festival, the UK’s national festival of the humanities. Their theme this year is ‘New Worlds’, so taking this as our inspiration, we’re highlighting a range of archive collections – across Travel, Exploration, Space Exploration and Science Fiction.
Travel
Austen Henry Layard’s passport (1) (LAY/1/4/8). Image copyright: University of Newcastle.
Unearthing Family Treasures: The Layard and Blenkinsopp Coulson Archives In 1839 a young lawyer left behind his London office for a post in the Ceylon (now Sri Lanka) Civil Service, thus beginning a series of travels, adventures and discoveries which would result in him achieving world renown for uncovering and shining a light on the ancient civilizations of Mesopotamia, in particularly Assyrian culture. That young man was Austen Henry Layard. Read the feature, by University of Newcastle Special Collections.
Papers of Elizabeth Thomson, 1847-1918, teacher, missionary, traveller and suffragette, c1914 Throughout the 1890s and 1900s Thomson travelled the world with her sister, Agnes, working as teachers and missionaries. The countries they visited include India, Japan, the USA, Germany and Italy. In the summer of 1899 Thomson reports that she visited Faizabad in India to learn Urdu but could not stand the heat and left for Almora in 1902. In 1907 she sailed to Bombay to complete missionary work, before teaching English in Sangor for the winter. In 1909 she travelled back to the UK, via Vienna, Prague, Dresden and Berlin, to settle in Edinburgh. Material held by University of Glasgow Archive Services – see the full collection description.
Sentimental Journey: a focus on travel in the archives The hundreds of collections relating to travel featured in the Archives Hub shed light on multiple aspects of travel, from royalty to the working classes, and encompassing touring, business, exploration and research, the work of missionaries and nomadic cultures. Read the feature.
An abstract of a voyage from England to the Mediteranian: the diary of an anonymous English naval victualler, 1694-1696 Contains the log of an anonymous English naval victualler on a voyage from Gravesend in England to Cadiz in the Mediterranean between 31 December 1694 and 29 October 1696. Material is in English Spanish Latin Hebrew. Written in a single neat late seventeenth-century English hand with the text on each page set within faint ruled lines. There are many tables, diagrams, and quite finely-drawn illustrations of places en route, especially in Spain, and interesting objects, such as keys and seals. Material held by University of Leeds Special Collections – see the full collection description.
Bodiwan Papers, 1634-1923 The papers of Michael D. Jones and his family, which include numerous letters to Michael D. Jones from the Welsh settlers in Patagonia or relating to them, prior to the sailing of the Mimosa and after. Amongst them is a letter from Charles de Gaulle, the eminent Breton and Celticist, expressing his interest in the scheme to found a Welsh colony in Patagonia. Also, amongst the correspondents are L. Patagonia Humphreys, Rev. D. Lloyd Jones, Rhuthun and Mihangel ap Iwan and Llwyd ap Iwan. The papers reflect the hardship suffered by the new settlers as well as the investment made by Michael D. Jones in the venture. There are bills and receipts relating to the Mimosa, share certificates, statistics regarding population for 1879. Also, a bank pass book of the Welsh Colonising and General Trading Company Ltd, 1870-1883, and a register of the Welsh applicants to Patagonia, 1875-1876. The collection is held by Archifdy Prifysgol Bangor / Bangor University Archives – see the full collection description.
The London to Istanbul European Highway Part of The National Motor Museum Trust Motoring Archive‘s Bradley Collection, including striking illustrations by Margaret Bradley. Read the feature.
The handsome blue car, by Margaret Bradley. ‘With apologies…this being a rough sketch…made somewhere in the middle of no mild channel’. Sketch by Margaret Bradley, copyright the National Motor Museum Trust.
Exploration
Cambridge Svalbard Exploration Collection, 1933-1992 The collection documents many decades of scientific work undertaken by (mostly) Cambridge researchers from 1938 until the early 1990s. These were mostly led by Walter Brian Harland (1917-2003), who also became the collator of the materials collected in Spitsbergen. The documentary archive complements the physical collection of geological specimens collected during those expeditions. Svalbard is located in the north-western corner of the Barents Shelf 650km north of Norway, and is named after the Dutch Captain, Barents, who is credited with the modern discovery of the islands in 1596 and after whom the Barents Sea is named. Collection held by Sedgwick Museum of Earth Sciences, University of Cambridge – see the full collection description.
Online Resource: Old Maps Online – provided by Great Britain Historical GIS Project, Maps Online is a search portal that combines the historical map collections of several organisations around the world. Users can search across collections through a single interface and easily locate multiple maps of a geographical area. The interface is free and access is open to all users. A wide range of different types of map are available, including: land maps; sea charts; boundary and estate maps; military and political maps; and town plans. Historical maps of many countries are available – including South and Central America from the 16th to the 20th centuries; Britain and particularly London, up to 1860; North America in the 18th and 19th centuries; pre-1900 Dutch Maps; the North West of England; and Moscow. More details.
Challenger Expedition Photographs, 1870s-1885; 1981-1983 HMS Challenger set out to collect specimens from different depths of water across the globe. The voyage took place between 1872 and 1876. It is thought that this was the first expedition to routinely use photography to document the journey. There was a darkroom on board so photographs could be developed on the ship. Material held by National Museums Scotland – see the full collection description.
Shackleton’s Endurance Expedition Centenary 27th October 1915: Antarctic expedition ship Endurance was abandoned on the orders of Sir Ernest Shackleton and their expedition became fight for survival. Read the feature by the Scott Polar Research Institute, University of Cambridge.
Space Exploration
Herschel’s 40-foot telescope, circular glass plate photograph. The telescope’s wooden scaffolding is seen here on 9 September 1839, at Observatory House in Slough, England. It was photographed by the astronomer John Herschel (1792-1871) before its demolition. The telescope was designed by John’s father, the German-born British astronomer William Herschel (1738-1822). The tube was 40 feet (12 metres) long. The first observations with this telescope were carried out 50 years earlier on 28 August 1789, when two new moons of Saturn (Enceladus and Mimas) were discovered. 50 years later, by 1839, John Herschel and W H Fox Talbot had invented the process we now know as photography. This is one of the earliest surviving glass plate photographs. Image copyright: Royal Astronomical Society Archives
Russian Space Exploration, 1903 Drawings, documents, photographs, ephemeral objects and memorabilia relating to early Russian space exploration. Objects include domestic items such as cigarette cases, ashtrays, cigarette ornamental dispensers, desk thermometers, ornamental lamps and tea glass holders. Included in the collection are photo albums and a press cutting album made by a school child as well as stamp collections. The collection boasts rare drawings by Konstantin Tsiolkovsky in which he envisaged the exit from a spacecraft into the vacuum of space as well as a drawing of a Reactive engine (Rocket engine); one of the first designs of its kind from c.1930. The collection is held by De Montfort University Archives and Special Collections – see the full collection description.
Jodrell Bank Observatory Archive, c.1924-1993 The Jodrell Bank Observatory is one of the world’s largest radio-telescope facilities. Originally known as the Jodrell Bank Experimental Station, it was renamed the Nuffield Radio Astronomy Laboratories in 1966, and changed to its current name in 1999. The first radar transmitter and receiver was installed by Bernard Lovell, then working as a physicist at the University of Manchester, at Jodrell Bank, Cheshire, in December 1945 (the University campus had proved unsuitable because of the high level of electrical interference). At this period Lovell was researching cosmic rays under the direction of Patrick Blackett, professor of physics at the University of Manchester. Lovell’s work involved studying radio echoes from large cosmic ray showers in the Earth’s atmosphere, using old military radars. As a result of this, Lovell went on to make important discoveries in meteoric astronomy. The collection is held by University of Manchester Library – see the full collection description.
The Herschel archive at the Royal Astronomical Society The Royal Astronomical Society is the custodian of a significant collection of the astronomy-related papers of William, Caroline and John Herschel. Read the feature.
Caroline Lucretia Herschel (1750-1848), German- born British astronomer, in 1847, pointing at the orbit of a comet on a map of the solar system. The map shows all the planets out to Saturn. Uranus had been discovered in 1781 by William Herschel, but was at first thought to be a comet. Neptune was discovered in 1846. The map also shows the asteroids Ceres (discovered in 1801), Pallas (1802), Juno (1804) and Vesta (1807). Caroline was the sister of William Herschel, and worked with him in England. She discovered eight new comets between 1786 and 1797. After her brother’s death in 1822, Caroline returned to Hanover, where she died at the age of 98. This artwork shows Herschel in Hanover in 1847, the year before she died. Image copyright: Royal Astronomical Society Archives
Science Fiction
Papers of Douglas Noël Adams, 1952-2001 (Circa.) Douglas Noël Adams was born in Cambridge in 1952. He was awarded an exhibition to read English at St John’s College, Cambridge, obtaining his BA in 1974. While at Cambridge, Adams occupied himself chiefly in writing, performing in, and producing comedy sketches and revues, establishing connections that were to be integral to his future work. His career took off with ‘The Hitchhiker’s Guide to the Galaxy’, a six-part comic science-fiction radio series commissioned by the BBC in 1977 and broadcast in 1978. Novelisation and a second series were followed by further books in what became billed as ‘the increasingly inaccurately named Hitchhiker’s Trilogy’. The ‘Hitchhiker’s Guide’ series has taken many forms, including audio recordings; stage adaptations; a television series; a computer game; publication of the original radio scripts; radio adaptations of the remaining novels, and a film. Adams’s other creative work included writing and script-editing for BBC Television’s ‘Doctor Who’. Material held by St John’s College Library Special Collections, University of Cambridge – see the full collection description.
Papers of Brian Aldiss, 1966-1995 Brian Aldiss was born in 1925 in Dereham, Norfolk. After war service in the Royal Corps of Signals he entered the bookselling trade, working at Sanders & Co. in Oxford. His first work as a writer was The Brightfount Diaries, a fictionalised diary of a bookseller first published as a column in The Bookseller during 1954 and 1955 and published as one volume by Faber & Faber in 1955. The following year he became a full-time writer, and in 1957 his first science fiction book, the short story collection Space, Time and Nathaniel was published. His first science fiction novel, Non-Stop was published in 1958. Since then Aldiss has been a prolific writer, best known for his science fiction novels, novellas and short stories, including the award-winning Helliconia trilogy. He has also been a historian and critic of the genre, and has edited many science fiction collections. In addition, his ‘mainstream’ writing has included the novels The Male Response, Forgotten Life and the semi-autobiographical Horatio Stubbs sequence. He was elected a Fellow of the Royal Society of Literature in 1989. In 1990 he published his autobiography, Bury my heart at W.H. Smith’s. the collection is held by the University of Reading Special Collections Services – see the full collection description.
Other ‘New Worlds’
Pan-African Congress 1945 and 1995 Archive The Pan-African Congress was a series of meetings, held throughout the world. In 1945 Manchester hosted the 5th Pan-African Congress. The Pan-African Congress was successful in bringing attention to the decolonization in Africa and in the West Indies. The Congress gained the reputation as a peace maker and made significant advance for the Pan-African cause. One of the demands was to end colonial rule and end racial discrimination, against imperialism and it demanded human rights and equality of economic opportunity. The manifesto given by the Pan-African Congress included the political and economic demands of the Congress for a new world context of international cooperation. material is held by the Ahmed Iqbal Ullah Race Relations Resource Centre – see the full collection description.
Records of the British Union for the Abolition of Vivisection, 1865-1996 The British Union for the Abolition of Vivisection (BUAV) was founded in 1898 by Miss Frances Power Cobbe (1822-1904). Concern for the welfare of animals was not a new phenomena, the first wave of anti-vivisection feeling in England commenced around the middle of the nineteenth century. The Second World War appeared to foster greater ideas of cooperation within the animal welfare movement. The Conference of anti-vivisection Societies first met on 20 November 1942. Five societies were represented at the invitation of BUAV ‘for the purpose of discussing and making plans for a joint intensive campaign, after the war, to claim the total abolition of vivisection as a necessary step towards securing for animals their rightful place in the new world order, which it is generally believed will follow the peace’. The immediate post war period began to see a rise in public demonstrations as a medium to spread the anti-vivisection message, in particular these were held outside vivisection laboratories. The collection is held by Hull University Archives, Hull History Centre – see the full collection description.
The Percy Johnson-Marshall Collection, 1931-1993 Percy Edwin Alan Johnson-Marshall (1915-1993) was one of the most energetic of a generation of town-planners who began their careers in the 1930s and, after the Second World War, dedicated their lives to the creation of a new world of social equity through the radical transformation of the human environment. Material held by Edinburgh University Library Special Collections – see the full collection description.
Join our mailing list: to receive updates about what is on the Hub and tips for using archives in your research, please visit our jiscmail list to sign up.
On the Archives Hub we have plenty of name entries without dates. Here is an example of the name string ‘Elizabeth Roberts’ (picked entirely randomly) from several different contributors:
Richard and Elizabeth Roberts Roberts, Elizabeth fl. 1931 Elizabeth Grace Roberts Roberts, Elizabeth Grace Elizabeth Roberts Roberts, Elizabeth ROBERTS, Elizabeth Grace ROBERTS, Mrs Elizabeth Grace
The challenge we have is how to work this names like this. Let me modify this list into an imaginary but nonetheless realistic list of names that we might have on the Hub, just to provide a useful example (apologies to any Elizabeth Roberts’ out there):
Elizabeth Roberts 1790-1865 Elizabeth Roberts, 1901-1962 Elizabeth Roberts b 1932 Elizabeth Roberts fl. 1958 Elizabeth Roberts, artist Elizabeth Roberts Elizabeth Roberts Elizabeth Roberts
How should we treat these names in the Archives Hub display? If we can make decisions about that, it may influence how we process the names.
These names can be separated into two types (1) name strings that identify a person (2) name strings that don’t identify a person. This is a fundamental difference. It effectively creates two different things. One is an identifier for a person; one is simply a string that we can say is a name, but nothing more.
If we put two descriptions together because they are both a match to Elizabeth Roberts, 1790-1865, then we are stating that we think this is the same person, so the researcher can easily see collections and other information about them.
If we put two descriptions together that are both related to Elizabeth Roberts we are not doing the same thing. We are simply matching two strings.
Which of these names is an identifier? That depends upon levels of confidence, and that is why being able to set and modify levels of confidence is crucial.
Elizabeth Roberts 1790-1865 – this is enough to identify a person. In theory, there could be two people with the same life dates, but the chances are very low. So, we would bring together two entries and represented them on one name page.
Elizabeth Roberts b 1932– Is a birth or death date enough? It allows for some measure of certainty with identity, and we would probably deem this to be enough to identify a person and match to another Elizabeth Roberts born in 1932, but it is not certain. If this Elizabeth Roberts was the creator, and she has several mentions of ‘art’, ‘artist’ and ‘painting’ in her biography, it is more likely that she is the same as Elizabeth Roberts, artist and might be useful to create a link, but would it be enough for a match?
Elizabeth Roberts fl 1931 – whilst a floruit date helps place the person in a time period, it is not enough to confidently identify a person.
Elizabeth Roberts, artist – occupation or other epithet enough is not usually enough to identify someone. If there is a biographical history, there is more information about the person, but this is not enough to be sure.
If we had an entry such as Elizabeth Roberts, Baroness Wood of Foxley (completely imaginary and just for the purposes of example), then the epithet is more helpful. We might decide that this identifies a person enough for a match with any other instances of Elizabeth Roberts with baroness wood and foxley in the name string.
If we had MacAlister, Sir Donald, 1st Baronet, physician and medical administrator then ‘1st baronet’ alongside the name should give enough confidence for a match with another entry for 1st Baronet.
Display behaviour
So, how might we reflect this in the display? It can be useful to think about the display and researcher requirements and expectations and work back from there to how we actually process the data.
Firstly we might group two entries if they have the same date.
But this does not offer much benefit to the end user. They still see eight entries for this name string. So, we might bring together the entries that match exactly on the name string.
But there are still two entries that are essentially just name strings – the fl. and the ‘artist’ entry are essentially the same as those without any additional information in that they are name strings and they do not identify a person, so it makes sense to group all of these entries.
We now have a short set of entries. We can’t merge any more of them.
However, this does leave us with a problem. The end user is likely to assume that these all represent different people. That ‘Elizabeth Roberts’ is a different person from ‘Elizabeth Roberts 1901-1962’. The tricky thing is that she might be….and she might not be. It is likely that a user wanting Elizabeth Roberts with dates 1790-1865 would see the above list and click on the matching entry, not realising that the last three entries could also refer to the same person. We don’t want to exclude these from the researcher’s thinking without hinting that they may represent the same person.
We might give the list a heading that hints at the reality, such as ‘We have found the following matches:’. Maybe ‘matches’ would have a tool tip to say that the entries without dates could match the entries with dates. It is quite hard to even find a way to say this succinctly and clearly.
The identifiable names would link to name pages. We might provide information on the name pages to again emphasise that other Elizabeth Roberts entries could be of interest. We haven’t yet decided what would be best in terms of behaviour for the non-identifiable names – they might simply link to a description search – it does not make much sense to have a full name page for an unidentified person where all you have is one link to one archive description. We can’t provide links to any other resources for a non-identifiable name; unless we simply provide e.g. a Wikipedia lookup on the name. But again, we face the issue of misleading the end user; implying a ‘same as’ link when we do not have enough grounds to do that.
Names as creators
We may decide to treat creator names differently. Archival creator does have a significant meaning – it emphasises that this is a collections about that person or organisation (though even the nature of the about-ness is difficult to convey). But many users do not necessarily appreciate what an archival creator is, and many descriptions don’t provide biographical histories, so could this end up creating confusion? Also, in the end a creator name is far more likely to include life dates, so then they would have a full name page anyway. What would be the benefit of treating a creator name with no life dates and no biographical history differently from an index term and giving it a name page? You would just be linking to one archive, albeit ‘their’ archive.
What about if a name string record, say the Elizabeth Roberts fl 1931, has been ingested as an EAC record, i.e. a name record that was created by one of our contributors? It is likely that name records will include a full date of birth, or at least a birth or death date, but this is not certain. Whilst we are not currently set up to take in EAC-CPF name records, we do plan to do this in the future. If the name is provided through an EAC record and they are a creator, they may have a detailed biography, and may have other useful information, such as a chronology, so a name page would be worthwhile.
This short analysis shows some of the problems with providing a name-based interface. We will undoubtedly encounter more thorny issues. The challenge, as is so often the case, is just as much about how to convey meaning to end users when they are not necessarily familiar with archival perspectives, as it is about how to process the data.
And we haven’t even got to thinking about Eliza Roberts or Lizzy Roberts…..
Birkbeck was founded as the London Mechanics’ Institute on the evening of the 11th November 1823, when approximately 2,000 people listened to Dr George Birkbeck speak on the importance of education for working Londoners at the Crown and Anchor Tavern on the Strand. Supporters there that evening included Jeremy Bentham, the philosopher and originator of Utilitarianism, Sir John Hobhouse, a Radical MP who held several important government posts across his career, and Henry Brougham, a liberal MP, anti-slavery campaigner and educational reformer.
Birkbeck has been transforming lives by helping people access higher education for nearly 200 years. This year, 2020, we celebrate our 100th anniversary of our membership of the University of London. When Birkbeck joined the University of London, it was on the condition that it should continue to provide evening teaching, and this remains our central mission.
As we move toward our 200th anniversary in 2023, part of the Birkbeck archive was rediscovered in an offsite storage facility. This has proved to be a rich source, not only providing insights not into our institutional history but also stories of both staff and students allowing us glimpses into their lives. We now find ourselves in the position of having two sections of the archive, each telling our story from different perspectives.
One section of the archive is held in the main Birkbeck building and is comprised of records pertaining to the history of Birkbeck from an organisational context, including minutes of various committees, published student journals and newsletters, annual reports, calendars, early student registers and staff information.
The second section is held offsite and is made up of a range of material including; war correspondence, departmental papers, estates documents, all of which demonstrate Birkbeck’s unique aim and how that aim has held strong through changing political, economic and cultural times.
To date one Birkbeck academic, Professor Joanna Bourke, has explored this material, along with two of her PhD students. They have found it to be an excellent source for their research. One of the themes that runs through the archive is around trends in education such as educational policies and practices. This includes charting the life cycle of different academic disciplines as well as documenting different approaches to teaching and the broader aspects student life.
Art class at the Birkbeck Literary and Scientific Institution, Breams Buildings, circa 1915, Birkbeck, University of London. Birkbeck Image Collection.
Like many university archives, we have records of notable Birkbeckians who worked or studied with Birkbeck. We can now develop more of a picture of the lives of people such as; JD Bernal (Crystallography), Eric Hobsbawm (History), Nikolaus Pevsner (History of Art), Helen Gwynne-Vaughan (Botany). We can also learn more about those who were less well-known who studied here and made an impact like the playwright Arthur Wing Pinero and socialist, women’s rights activist Annie Besant. The library is creating an online timeline to highlight the life and work of various Birkbeck academics as part of the celebrations in the lead up to our 200th anniversary.
Helen Gwynne Vaughan in her Botany Laboratory with students circa 1923, Birkbeck, University of London. Birkbeck Image Collection.
In terms offering different perspectives, this part of the archive also holds accounts of the wider Birkbeck community, beyond the academic staff and students, those members of staff working in catering and hospitality roles, administrative staff, laboratory technicians. This provides an opportunity to explore social history through those lived experiences documented through various formats, such as letters and photographs.
It’s an exciting time at Birkbeck as we continue to uphold the ethos and pursue the central mission of providing access to education for all. Birkbeck is still London’s only specialist provider of part-time evening higher education as well as being a world-class research institution. The archive will continue to tell the story of Birkbeck as an institution as well as all those who work, study and research here. You can follow Birkbeck’s journey to its 200th anniversary.
Emma Illingworth Subject Librarian for Science (Biological, Earth & Planetary, Psychological) Library Services, Birkbeck, University of London
Related
Browse all Birkbeck Library Archives and Special Collections, University of London descriptions available to date on the Archives Hub.
All images copyright Birkbeck Library Archives and Special Collections, University of London. Reproduced with the kind permission of the copyright holders.
Having written several blogs setting out ideas and thoughts about challenges with names, this post sets out some of our plans going forwards in order to create name records for a national aggregator; something that can work at scale and in a sustainable way. The technical work is largely being undertaken by Knowledge Integration, our system suppliers, though working closely with the Archives Hub team.
Consider one repository – one Hub contributor. They have multiple archives described on the Archives Hub, and maybe hundreds or thousands of agents (people and organisations) included in those descriptions. All of this information will be put into a ‘management index‘. This will be done for all contributors. So, the management index will include all the content, from all levels, including all the names. A huge bucket of data to start us off.
A names authority source such as VIAF or any other names data that we would like to work with will not be treated any differently to Archives Hub data at this stage. In essence matching names is matching names, whatever the data source. So, matching Archives Hub names internally is the same as matching Archives Hub names to VIAF, or to Library Hub, for example. However, this ‘names authority’ data will not go into our big bucket of Archives Hub data, because, unless we create a match with a name on the Hub, the authority data is not relevant to us. Putting the whole of VIAF into our bucket of data would create something truly huge. It is only if we think that this external data source has a name that matches a person or organisation on the Hub that it becomes important. So data from external sources are stored in separate reference indexes (buckets) for the purposes of matching.
Tokenisation
Knowledge Integration are employing a method known as tokenization, which allows us to group the data from the indexes into levels (It is quite technical and I’m not qualified to go into it in detail, so I only refer briefly to the basic principles here. Wikipedia has quite a good description of tokenization). With this process, we can establish levels that we believe will suit our purposes in terms of confidence. Level 1 might be for what we think is a guaranteed match, such as where an identifier matches. So, for example, Wikidata might have the VIAF identifier included, so that the VIAF and Wikidata name can be matched. In some cases, the Archives Hub data includes VIAF IDs, so then the Hub data can be matched to VIAF. We also hope to work with and create matches to Library Hub data, as they also have VIAF ID’s.
If all versions of a name have the same ID then they can be matched.
Level 2 might be a more configurable threshold based around the name. We might say that a match on name and date of birth, for example, is very likely an indication of a ‘same as’ relationship. We might say that ‘James T Kirk’ is the same person as ‘James Kirk’ if we have the same date of birth. This is where trial and error is inevitable, in order to test out degrees of confidence. Level 3 might bring in supporting information, such as biographical history or information about occupation or associated places. It is not useful by itself, but in conjunction with the name, it can add a degree of certainty.
Biographical information may be used to help match names
We are also thinking about a Level 4 for approaches that are Archives Hub specific. For example, if the same name is provided by the same repository, could we say it is more likely to be the same person?
This tokenisation process is all about creating a configurable process for deduplication. Tokens are created only for the purposes of matching. Once we have our levels decided, we can create a deduplication index and run the matching algorithm to see what we get.
Approaches to indexing
For deduplication indexing, the first thing to do is to convert to lower case and remove all of the non-alpha characters. (NB: For non-latin scripts, there are challenges that we may not be able to tackle in this phase of the project).
The tokens within the record will be indexed in multiple ways within the deduplication index to facilitate matching. This includes indexing all words in order that they appear, and also individual word matches.
Then, particularly when considering using text such as biographies to help identify matches, we can use bigrams and trigrams. These essentially divide text into two and three words chunks. A search can then identify how many groups of two and three words have matched. Generally, this is a useful method of ascertaining whether documents are about the same thing. It may help us with identifying name matches based upon supporting information. This is very much an exploratory approach, and we don’t know if it will help substantially with this project, but certainly it will be worth trying out this approach, and also considering using it for future data analysis projects.
Character trigrams break down individual words into groups of three characters and may be useful for the actual names. This should be useful for a more fuzzy matching approach, and it help to deal with typos. It can also help with things like plurals, which is relevant for working with the supporting information.
We are also going to explore hypocorisms. This means trying out matches for names such as Jim, Jimmy and James or Ned, Ed, Ted and Edward. A hypocorism is often defined as a pet name or term of endearment, but for us it is more about forename variations. Obviously Jim Jones is not necessarily the same person as James Jones, but there is a possibility of it, so it is useful to make that kind of match on name synonyms. It is often defined as a pet name or term of endearment.
Hypocorisms refers to pet names or terms of endearment
From this indexing approach we can try things out and see what works. There is little doubt that it will require an iterative and flexible approach. We can’t afford to set up a whole process that proves ineffective so that we have to start again. We need an approach that is basically sound and allows for infinite adjustments. This is particularly vital because this is about creating a framework that will be successful on an on-going basis, for a national-scale service. That is an entirely different challenge to creating a successful outcome for a finite project where you are not expecting to implement the process on an on-going basis. Apart from anything else, a project with a defined timescale and outcome gives you more leeway to have a bit of human intervention and tweak things manually to get a good result.
Group records
Using the tokenisers and matching methods we can try processing the data for matches. When records are matched with a degree of certainty, a group record is created in the deduplication index. It is allocated a group id and contains the ids of all of the linked records. This is used as the basis for the ‘master record’ creation.
Primary or master records
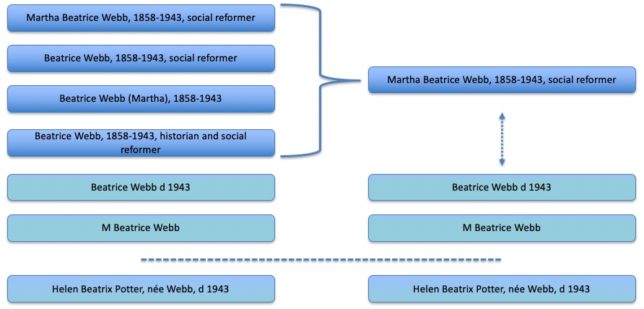
I have previously blogged some thoughts about the ‘master record’ idea. Our current proposal is that every Archives Hub name is a primary record, unless it is matched. So, if we start out with six variations of Martha Beatrice Webb, 1858-1943, then at that point they are all primary records and they would all display. If we match four of them, to a confidence threshold that we are happy with, then we have three primary records. One of the primary records covers four archives. We may be able to still link the other two instances of this name to the aggregated record, but we can assign a lower confidence threshold to this.
Deduplication for ‘Beatrice Webb’
In the above example (which is made up, but reflects some of the variations for this particular name) four of the instances of the name have been matched, and so that creates a new primary record, with child records. Two of the instances have not been matched. We might link them in some way, hence the dotted line, or they might end up as entirely separate primary records. The instance of Beatrix Potter, nee Webb, has not been matched (these two individuals are often confused, especially as they have the same death date). If we set levels of confidence wrongly, this name could easily be matched to ‘Beatrice Webb’.
The reasoning behind this approach is that we aggregate where we can, but we have a model that works comfortably with the impossibility of matching all names. Ideally we provide end users with one name record for one person – a record that links to archive collections and other related resources. But we have to balance this against levels of confidence, and we have to be careful about creating false matches. Where we do create a match, the records that were previously primary records become ‘child records’ and they no longer display in the end user interface. This means we reduce the likelihood of the end user searching for ‘william churchill’ and getting 25 results. We aim for one result, linking to all relevant archives, but we may end up with two or three results for names that have many variations, which is still a vast improvement.
If we have several primary records for the same person (due to name variations) then it may be that new data we receive will help us create a match. This cannot be a static process; it has to be an effective ongoing workflow.





























.jpg){kind=link}