One of the challenges that we face with our Labs project is presentation of the Machine Learning results. We thought there would be many out of the box tools to help with this, but we have not found this to be the case.
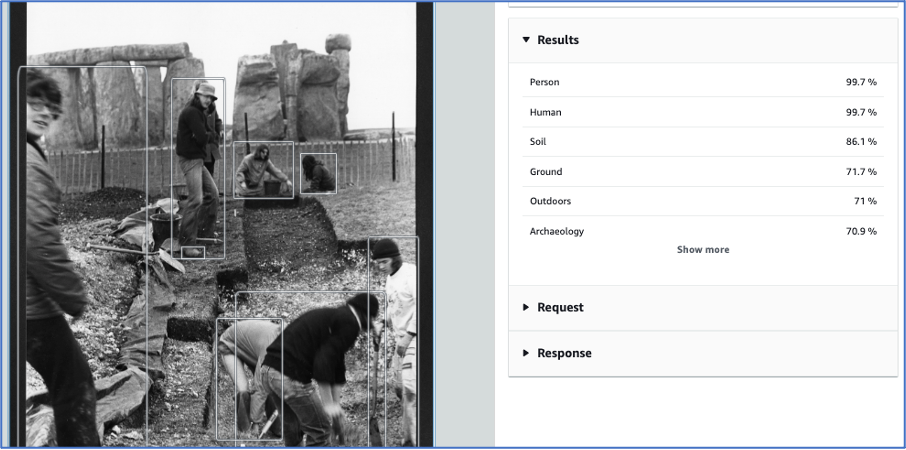
If we use the AWS console Rekognition service interface for example, we get presented with results, but they are not provided in a way that will readily allow us and our project participants to assess them. Here is a screenshot of an image from Cardiff University – an example of out of the box use of AWS Rekognition:
Excavation at Stonehenge, Cardiff University Photographic Archive
This is just one result – but we want to present the results from a large collection of images. Ideally we would run the image recognition on all of the Cardiff images, and/or on the images from one collection, assess the results within the project team and also present them back to our colleagues at Cardiff.
The ML results are actually presented in JSON:
Excerpt from JSON showing ML output
Here you can see some of the terms identified and the confidence scores.
These particular images, from the University archive, are catalogued to item level. That means they may not benefit so much from adding tags or identifying objects. But they are unlikely to have all the terms (or ‘labels’ in ML parlance) that the Rekognition service comes up with. Sometimes the things identified are not what a cataloguer would necessarily think to add to a description. The above image is identified as ‘outdoors’, ‘ground’ and ‘soil. These terms could be useful for a researcher. Just identifying photographs with people in them could potentially be useful.
Another example below is of a printed item – a poem.
Up in the Wind, Papers of Edward Thomas, Cardiff University
Strange formatting of the transcript aside, the JSON below shows the detected text (squirrels), confidence and area of the image where the word is located.
Detected word ‘squirrels’
If this was provided to the end user, then anyone interested in squirrels in literature (surely there must be someone…) can find this digital content.
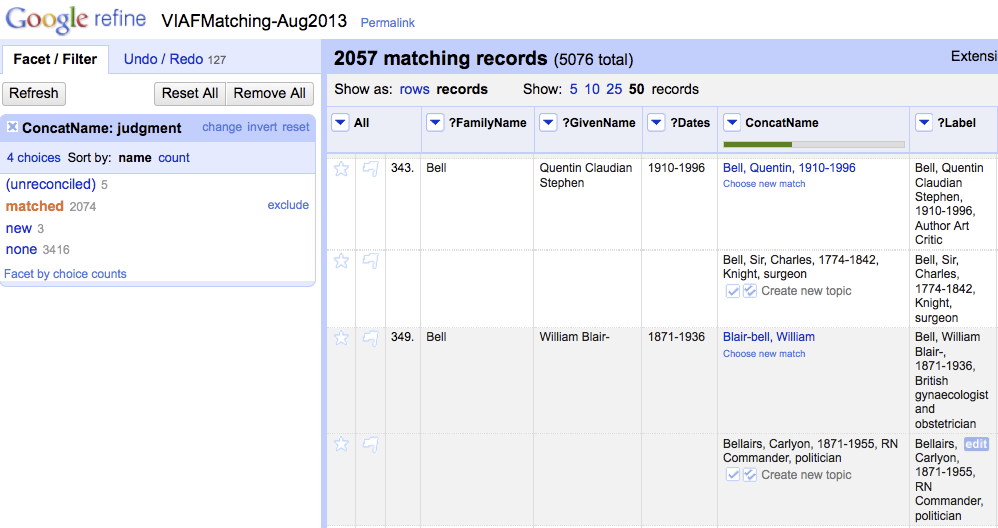
But we have to figure out how to present results and what functionality is required. It reminds me of using Open Refine to assess person name matches. The interface provides for a human eye to assess and confirm or reject the results.
Screenshot of names matching using Open Refine
We want to be able to lead discussions with our contributors on the usefulness, accuracy, bias – lack of bias – and peculiarities of machine learning, and for that a usable interface is essential.
How we might knit this in with the Hub description is something to consider down the line. The first question is whether to use the results of ML at all. However, it is hard to imagine that it won’t play a part as it gets better at recognition and classification. Archvists often talk about how they don’t have time to catalogue. So it is arguable that machine learning, even if the results are not perfect, will be an improvement on the backlogs that we currently have.
AWS Rekognition tools
We have thought about which tools we would like to use and we are currently creating a spreadsheet of the images we have from our participants and which tools to use with each group of images.
Some tools may seem less likely, for example, image moderation. But with the focus on ethics and sensitive data, this could be useful for identifying potentially offensive or controversial images.
Blanked out image
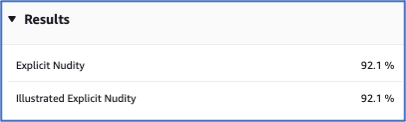
The Image Moderation tool recognises nudity in the above image.
The confidence scores are high that this image represents nudity
This could be carried through to the end user interface, and a user could click on ‘view content’ if they chose to do so.
Art Design and Architecture Collection, Glasgow School of Art (NMC/1137)
The image moderation tool may classify images art images as sensitive when they are very unlikely to cause offence. The tools may not be able to distinguish offensive nudity from classical art nudity. With training it is likely to improve, but when you think about it, it is not always an easy line for a human to draw.
Face comparison could potentially be useful where you want to identify individuals and instances of them within a large collection of photographs for example, so we might try that out.
However, we have decided that we won’t be using ‘celebrity recognition’, or ‘PPE detection’ for this particular project!
Text and Images
We are particularly interested in text and in text within images. It might be a way to connect images, and we might be able to pull the text out to be used for searching.
Suffice to say that text will be very variable. We ran Transkribus Lite on some materials.
Letter from the Papers of Edward Thomas at Cardiff University
We compared this to use of AWS Text Rekognition.
Letter from the Papers of Edward Thomas at Cardiff University
These examples illustrate the problem with handwritten documents. Potentially the model could be trained to work better for handwriting, but this may require a very large amount of input data given the variability of writing styles.
Poem from the Papers of Edward Thomas, Cardiff University
Transkribus has transcribed this short typescript text from the same archive well. One word ‘house’ has been transcribed as ‘housd’ and ‘idea’ caused a formatting issue, but overall a good result.
Poster from the Design Archive, University of Brighton Design Archives
The above example is Transkribus Lite on a poster from the University of Brighton Design Archives. In archives, many digital items are images with text – particularly collections of posters or flyers. Transkribus has not done well with this (though this is just using the Lite version out of the box).
We also tried this with the AWS Rekognition Text tool, and it worked well.
Another example of images with text is maps and plans.
19th century map of Clerkenwell, Lambeth Palace Archive
Above are two examples of places identified from the plan output in JSON. If we can take these outputs and add them to our search interface, an end user could search for ‘clerkenwell’ or ‘northampton square’ and find this plan.
Questions we currently have:
How do we present the results back to the project team?
How do we present the results to the participants?
Do we ask participants specific questions in order to get structured feedback?
Will we get text that is useful enough to go to the next step?
Which images provide good text and which don’t?
How might they results be used on the Archives Hub to help with discovery?
As we progress the work, we will start to think about organising a workshop for participants to get their feedback on the ML outputs.
Thanks to Adrian Stevenson, one of the Hub Labs team, who took me through the technical processes outlined in this post.
Edge Hill University’s history dates back to the 1880s when a committee was formed in 1882 to establish a teacher training college for women in Liverpool. Students would be instructed “in the Christian Religion upon a Scriptural but undenominational basis.”
The minutes of the first meeting of the Edge Hill Training College Committee, February 1882. Ref: EHU/GOV/1/12.
The College was opened on Durning Road in the Edge Hill district of Liverpool in January 1885, with just 41 students. Sarah Jane Yelf was appointed as the College’s first Principal, with the intention of producing ‘a superior class of Elementary School Mistresses’. Sarah Jane Hale took over as principal in 1890 and the institution began a gradual expansion. Miss Hale died in 1920 and by the end of her tenure the College had trained 2,071 girls, of whom 213 were Head Mistresses, 178 First Assistants, and 30 science mistresses. Miss Hale’s successor in 1920 was Eva Marie Smith and she would continue with the ambitious expansion of the College, with it by now having a firmly established reputation for excellence.
Postcard showing the original Edge Hill College on Durning Road, Liverpool.
Miss Smith and her colleagues had begun to feel that the Durning Road site was not suitable for the growing student and staff population (as well as facing regular problems with the upkeep of the site. In 1925, Edge Hill was placed under the control of Lancashire County Council who would provide a new building for the college, preserving the original name, history and reputation. A site in Ormskirk was chosen and the foundation stone of the new building was laid in 1931, before opening in October 1933.
During the Second World War, the College was evacuated to Bingley Training College while the campus served as a military hospital. The original Durning Road premises were destroyed in a German bombing raid on 28 November 1940, killing 166 people – the worst single incident in the Liverpool Blitz as regards loss of life.
The gradual expansion of the Ormskirk campus resumed after the War and, in 1959, the first male students were welcomed to the College. During the 1960s courses were expanded and diversified, with a rapidly developing range of degree courses on offer.
Watercolour of Edge Hill College, Ormskirk, by an unknown student, 1950s. Ref: EHU/GUAL/3/27/4.
Over the next decades, the institution would maintain its reputation for excellence in teacher training while also steadily expanding a range of successful degree courses in other areas. This acceleration of curriculum, infrastructure and institutional development has continued to the present day, with the University Title awarded in 2006.
The Edge Hill University archives offer a wealth of potential areas for research. The collections have vast potential for the history of teacher training, women’s education and the changing lives of women in the late 19th and early 20th centuries. The expansion of Edge Hill in recent decades means its history has a great deal to tell us about the development of higher education in Britain as well as the changing experiences of those who studied and were employed here. Each milestone changed and broadened the horizons of what Edge Hill University is today.
Photograph of a page from a student’s autograph album portraying the highs and lows of Test Week, c. 1904. Ref: EHU/GUAL/3/12/1.
It would be fantastic to see this collection being used more for research. It has already proven a fantastic resource for historians of women’s suffrage, with a number of Edge Hill’s alumni having been active in the fight for equality and some becoming particularly well-known figures such as the barrister and women’s rights campaigner, Helena Normanton and the socialist, feminist and human rights campaigner, Ethel Snowden. Discussions around women’s suffrage and equality were often covered and reported on in the annual Edge Hill College magazines – a wonderfully rich series of documents that reveal much about the cultural shifts in the lives of women during the late 19th and early 20th centuries.
Four Edge Hill students, 1922.
The dedicated cataloguing of the archive only began in late 2019, so there is a huge amount of material yet to be catalogued, as well as a constant flow of new accessions arriving at the archive, so researchers are encouraged to contact us if they cannot find things that they might expect to find listed, would like to find out more about the collections or have a specific enquiry we might be able to support them with. Get in touch and discover an archive collection that is overflowing with untapped potential!
Given that Hub Labs is looking at AI and we’re also writing blog posts, it seemed like a good opportunity to try out one of the AI blog post writing applications that keep appearing in my various streams. The one that seems to get the best recommendations and is also free to trial is Writesonic. I’ve been meaning to write a post about our initial steps to build the AWS cloud infrastructure for Labs, so I thought I would use this as the basis for the experiment. You essentially provide a title, in this case I chose ‘Getting Started with Machine Learning in the Cloud’, and it will then provide some intros and outlines that you can accept or reject before it goes on to produce some copy. The best copy I could get it to produce given the options provided is pasted in below. You can see it’s a bit marketing speak and it was no great surprise that it’s not proved to be of much use for my experiment at least. For some reason it wanted to assume we are using Google Cloud and didn’t offer any AWS copy. It was interesting to try it though, and I could see it might be useful for more general posts.
The AI generated copy (italised by me) including the image is pasted below:
Getting Started with Machine Learning in the Cloud
Image Source: Freepik
The practice of machine learning involves training computer algorithms to recognize patterns in data and make predictions based on those patterns. It takes a lot of resources to implement machine learning in your business. There are many different datasets, tools, and software packages that you need to understand and choose from before you canput them to work analyzing your data and building your algorithm. This blog post discusses how you can use cloud services for machine learning with an example using Google Cloud Machine Learning (Cloud ML) and its APIs for Natural Language Processing (NLP).
What is Machine Learning?
There are many definitions of machine learning, including the IEEE’s “A computer program is said to learn from experience E with respect to some class of tasks T and some performance measure P if its performance at tasks in T, as measured by P, improves with experience E.” Or, as silly as it sounds, you can think about machine learning as a computer program that takes a bunch of data and spits out a prediction. You’re the one that has to tell the program how to do it.
Cloud ML with its APIs for NLP
Google Cloud Machine Learning workflows let you build and manage machine learning models in Google Cloud. Cloud ML supports a variety of machine learning frameworks, including TensorFlow, Caffe 2, and Apache MXNet. Cloud ML also provides a set of Natural Language APIs to support natural language processing (NLP) tasks, including sentiment analysis and entity extraction. Cloud ML’s NLP APIs can be accessed programmatically through its REST APIs.
Create a dataset using BigQuery
When you’re collecting data for machine learning, it’s important that your data be as accurate as possible. Google’s BigQuery lets you create a dataset in the cloud, and then you can use Google’s Natural Language API to analyze that dataset and get a breakdown of the different parts of speech. BigQuery is Google’s fully managed, enterprise data warehouse for business analytics. With BigQuery, you can query large data sets using standard SQL and get results in seconds. It’s also fully integrated with Google’s other analytical and collaboration tools, such as Google Sheets, Google Data Studio, and Google Cloud Platform.
Create a model using TensorFlow
With your dataset collected and a model for the Natural Language API built, you can create the model with TensorFlow. In this example, you’ll be building a model for sentiment analysis, which means you’ll be using the API’s sentiment analysis functionality. If you’re new to TensorFlow, don’t worry. There are some libraries out there that make it super easy to get started. One of them is tf-python-client, which is a library that allows you to write python code that uses TensorFlow.
Run the model in a Cloud Dataflow job
At this point, you’ve built a model and have everything ready to go. All that’s left to do is plug everything into Cloud Dataflow. Cloud Dataflow is Google’s fully managed, distributed framework for executing streaming data pipelines. Cloud Dataflow lets you build scalable, easy-to-manage data processing pipelines that transform and enrich your data. With Dataflow, you can build data processing and machine learning pipelines in a single, unified programming model. This means that you can build a model that performs data analysis, trains the model, and then deploys it in one workflow instead of three different ones.
Run the model in an API server
Your model is ready to go. Now you’re just missing the code to plug into an API server that can handle your data and send it to BigQuery. The Google Cloud Natural Language API lets you understand the meaning of text. You can use the API to detect entities, sentiments, and other linguistic properties of text. The API supports 82 languages.
Conclusion
Now that you know what machine learning is and have gotten started with Cloud ML and its NLP APIs, you can put this knowledge to use. You can use the NLP APIs to perform sentiment analysis or entity extraction on a dataset. This can be helpful for creating articles, social media posts, or marketing materials that are more effective.
With Cloud ML and its NLP APIs, you can create machine learning models that are more accurate and make more informed predictions. It takes a lot more effort to create models without cloud services, and it’s often difficult to keep track of all of the resources needed. With cloud services, you can focus on the model and not worry about the infrastructure and resources needed to run it.
This month we explore the recently digitised Stanley Houghton Collection held by the University of Salford and made accessible on Salford Digital Archives. 2022 marks 110 years since the first performance of Houghton’s best-known dramatic work, Hindle Wakes.
Photograph from a Hindle Wakes production in 1912, Ref: SHC/4/2.
About Houghton
William Stanley Houghton (1881-1913) was born in 1881 in Ashton-upon-Mersey, Cheshire and during his short life would become one of a group of playwrights known as the ‘Manchester School’.
It would seem Houghton had a standard middle-class upbringing. His father was a cotton cloth merchant in Manchester and in 1896 the family moved to Alexandra Park, a middle-class residential area south of the city from where Houghton attended Manchester Grammar School. On finishing school, Houghton went straight into his father’s cotton business, where he worked as a ‘grey-cloth’ salesman. It was during this time whilst working in the city that Houghton was developing his skills as a playwright and supplemented his income by writing critical reviews for the Manchester Guardian.
Houghton was one of several playwrights championed by Annie Horniman for his focus on what she called ‘real life’. Horniman was proprietor of Manchester’s Gaiety Theatre, the first repertory theatre outside of London with its own company of actors and a rotating programme of plays by local writers. It was through the association with the Gaiety that Houghton’s work was performed to audiences in London and America.
Hindle Wakes
Houghton’s best and most successful work was Hindle Wakes (1912), a comedy about the freedom of the young and the ‘double standard’ of morality. Written in 1911 and premiered at the London Aldwych Theatre in 1912, the play was controversial at the time for its portrayal of a mill girl who shocks the older generation by choosing independence rather than marriage to the mill owners’ son. The play both appealed and shocked audiences but ultimately proved a hit on an international level. The financial success of the play, coupled with the production of Houghton’s earlier work The Younger Generation (1909) enabled him to leave the cotton trade and take to writing full time.
However, Houghton’s career as a full-time writer was short lived. After moving to London and then Paris, Houghton returned to Manchester in ill health where he died in 1913 at the age of 32.
Highlights from the collection
Purchased by the university of Salford in 1983, the Stanley Houghton Collection is largely made up of unpublished manuscripts of plays which give insight into his working methods and character. It was through a ‘chance check in a Manchester telephone directory’ that a PhD student at the University interested in the life and work of the writer discovered Houghton’ living descendants. It turned out that they had kept a collection of previously unseen manuscripts by Houghton and photographs of early performances ‘wrapped in brown paper…in various suitcases in the house and garage’.
Page from Ginger, Ref: SHC/1/5.
Plan of stage layout for Ginger, Ref: SHC/1/5.
The works are a mixture of comedies, such as Pearls (c1910) which was designed for the music hall, and melodramas such as The Intriguers(c1906) that demonstrate his development as a writer and working method. Ginger (c1910) is evidence of Houghton’s approach to planning and plot development. I particularly like Houghton’s handwritten note on the page opposite the start of Act 2, to ‘focus Ginger a bit’, which makes me think of Houghton, pencil in hand reviewing his work. The typescript of Act 3 of Trust the People includes handwritten stage prompts to get the ‘gramophone ready’, giving a sense of how the work might have been produced on stage.
Page from Trust the People Act 3, Ref: SHC/1/3.
There are also published first edition translations of some of his works including Twixt Cup and Lip, a version of Houghton’s play The Dear Departed in Scots dialect by Felix Fair.
Front cover of Twixt Cup and Lip, Ref: SHC/2/4.
My favourite items in the collection are two sets of photographs of early 20th century theatre productions of Hindle Wakesand The Younger Generation. They include actors from the Gaiety Repertory Theatre who first performed Hindle Wakes some 110 years ago at the London Aldwych Theatre. The photos not only capture the sets and costumes of a theatre production at a particular point in time, but are also portraits of early 20th century actresses, including Ada King, Sybil Thorndike and Edyth Goodall.
Photograph from a Hindle Wakes production in 1912, Ref: SHC/4/2.
Photograph from a Hindle Wakes production in 1912, Ref: SHC/4/2.
I would love to see the Stanley Houghton Collection used more for teaching and research. Houghton was writing and dramatizing the life and society of the young just before the start the 1914 Great War which of course would have an enormous impact on his own generation.
Salford Digital Archives
The Houghton manuscripts and photographs are one of several collections now available on Salford Digital Archives, the University of Salford’s new platform to access digital archive content online.
Other collections on the platform include Brass Band News, a unique newspaper about brass bands from the 1880s up to the 1950s, alongside photographs from the Working Class Movement Library and the Bridgewater Canal. We are adding new collections to the platform in due course including a set of architectural drawings and plans for the University campus and two series of Salford Student Union newspapers. We welcome ideas for new collections and opportunities to work in partnership to curate content from our own and other archives.
Alexandra Mitchell Archivist, The University of Salford
This is the true love story of Geoffrey Griffiths (1906-1993) and Ida Carroll (1905-1995).
Griff
Referred to as “Griff” by many alumni, the lasting memories of this charming chap are primarily as the pipe-smoking first impression of the Northern School of Music. Stepping into the school off Sydney Street (where the Manchester Metropolitan University’s sport centre is now) his lugubrious voice would greet you amid a stain of smoke.
He was the school’s bursar. He typed up the daily notices on the school’s stairwell pillars, he drove the van full of the larger instruments (and their carefully balanced players) to the concert halls for orchestral performances and he kept everything squared away with the balance sheets.
What many did not know, is that he was in a dedicated relationship with the school’s principal Ida Carroll, for about 60 years. The only reason we know it now is due to the treasure chest of incredible love letters he sent her.
The letters
He wrote his Christmas letters to her at 1 min past midnight on the 24th so he could technically be the first to wish her Merry Christmas.
Geoffrey wrote letters, beautiful love letters, to Ida throughout their relationship. He would write multiple times a week, often just after getting home late at night from visiting her in order to tell her how much he already missed and loved her.
His writing to her was so prolific it seemed only to continue the conversations they had started when meeting face to face, undoubtedly to be picked up again when they next met. Most are merely introduced as “Monday afternoon”, and “Tuesday evening”. No need to put down such frivolous details as dates when he’s seeing her again by the end of the week.
There are some incredible references the Second World War when he’s had to hastily put down his pen, pick up his papers and pipe (priorities), and make his way to crouch under the stairs or in the nearest bomb shelter. He is very put out as he continues his letter writing in the cramped din, often cursing Herr Hitler for getting in the way of their love affair, which was apparently damned inconsiderate of him.
Griff pours out his war and wedding anxieties to Ida, 1939 (1).
Ida was an Air Raid Precaution Warden for the Didsbury area of Manchester. Griff was part of the Auxiliary Fire Service in Ashton-under-Lyne, spending many nights in the rooms of a bar parlour with a handful of other chaps, waiting for air raids and the inevitable fires that came after. Many long nights of boredom led to some very interesting letters, full of wartime musings, pining for more time with her, and pages upon pages agonising over details such as the merits of joining a journalism course, the exact details of the journey home, and Whist tactics.
Griff pours out his war and wedding anxieties to Ida, 1939 (2).
The couple apart
However, despite their devotion to one another, they didn’t traditionally exist as a couple. Indeed, they never actually lived together. One reason for this, it would seem, was Walter Carroll.
Walter was Ida’s father, and a firm fan of Griff for all it would appear. Griff worked in the travel agency frequented by Walter for his many trips to London. Over time, they got friendly and upon discovering Griff’s interest in singing and music (he had a cello called Boris), Walter enrolled Griff into his own choir at Birch Church. It’s likely that this is when he got to know and fall in love with Ida.
He would visit her at her family home and seemed openly intimidated by her father who, despite his appreciation of Griff’s musical passion, did not appreciate any other passion of Griff’s finding focus in his daughter.
The majority of their friends were also unaware of their affair. Both avid Hallé concert goers, they would arrange tickets to go with friends, fully intending to casually meet up at the concert, sit together or near, and meet up together after. A sort of stealth date night.
Getting closer and closer was all well and good, but still they never made the marriage/cohabitation plunge. Even though at one time they had planned to get married and were actively hunting for flat to take together. His letters describe in detail their dreams, just as the Second World War was being announced. Unfortunately, Griff’s mother died shortly after their plans were made. Moving out would have meant leaving his father alone in the family home through war and through grief. It seemed that Walter’s unwillingness to support the union and this tragic weight of family duty, led Griff to write a heart-breaking letter explaining why he needed to call off the engagement.
The couple together
Griff and Ida on holiday c.1960.
After the war, he quickly took up the opportunity to work as the Bursar of the Northern School of Music (where Ida was Secretary and later Principal) in 1946. Typical of the Northern School of Music and of Ida’s method of career advice, he was not expected to interview but simply to show up and never leave. Which is pretty much what happened.
They remained dedicated to each other, but never married. Their relationship continued for many years, almost in a perpetuating stage of courting. Griff later fell severely ill and Ida nursed him through to the end of his life, almost moving into the nursing home where he lived his final days.
Griff and Ida c.1990.
A lovely side-note here that shares some of the effectiveness of the school’s teaching. A friend and former student of Ida would visit her at Griff’s nursing home. The building was all locks and electronic key codes and it became a bit of a faff. Ida, having taught aural skills for decades had learned the key codes to the door locks simply based on the melody they made. She would relay this to her old friend in “tonic sol-far” (you know the one: do re mi fa sol…), singing the code notes to her, to allow freer movement in and out of the building when she visited.
While not dramatic opera-esque, or reminiscent of soaring symphony crescendos, this was a quiet, steadfast, romantic love of the ages. To read all the letters, head over to the Manchester Digital Music Archive with a cup of tea and sigh ready in your heart.
Heather Roberts RNCM College Archivist Royal Northern College of Music
A recent OCLC paper by Thomas Padilla highlights the need for ‘Pilot collaborations between institutions with representative collections’ and working ‘to share source data and produce “gold standard” training data.‘
We think that the Archives Hub Labs project exemplifes Tom’s suggested approach by working with ten of our contributing institutions from across the UK, reflecting a variety of archives.
However, it is also surely true that cultural heritage will need to engage with the broader AI and ML communities to understand and benefit fully from the range of ML services such as translation, transcription, object identification and facial recognition:
‘Advances in all of these areas are being driven and guided by the government or commercial sectors, which are infinitely better funded than cultural memory; for example, many nation-states and major corporations are intensively interested in facial recognition. The key strategy for the cultural memory sector will be to exploit these advantages, adapting and tuning the technologies around the margins for its own needs.’ From a short blog post by Dr Clifford Lynch from the CNI which is well worth reading.
People often criticise Machine Learning for being biased. But bias and mis-representation is essentially due to embedded bias in the input training data. The algorithm learns with what it has. So one of the key tasks for us as an archives community is to think about training data. We need algorithms that are trained to work for us to give us useful outputs.
Gathering training data in order to create useful models is going to be a challenge. Machine Learning is not like anything else that we have done before – we don’t actually know what we’ll get – we just know that we need to give the algorithm data that educates it in the way that we want. A bit like a child in school, we can teach it the curriculum, but we don’t know if it will pass the exam.
It certainly seems a given that we will need to use well labelled archival material as training data, so that the model is tailored specifically to the material we have. We will need to work together to provide this scale of training data. We have many wonderfully catalogued collections, with detail down to item level; as well as many collections that are catalogued quite basically, maybe just at collection level. If we join together as a community and utilise the well-catalogued content to train algorithms, we may be able to achieve something really useful to help make all collections more discoverable.
If an algorithm is trained on a fairly narrow set of data, then it is questionable whether it will have broad applicability. For example, if we train an algorithm on letters written in the 18th century, but just authored by two or three people, then it is unlikely to learn enough to be of real use with transcription; but if we train it on the handwriting of fifty people or more, then it could be a really useful tool for recognising and transcribing 18th century letters To do this training, we will need to bring content together. We will need to share the Machine Learning journey. The benefits could be massive in terms of discoverability of archives; effective discovery for all those materials that we currently don’t have time to catalogue. The main danger is that the resulting identification, transcription, tagging or whatever, is not to the standard that we want. We can only experiment and see what happens if we trial ML with a set of data (which is what we are doing now with our Labs project). One benefit could actually be much more consistency across collections. As someone working on aggregating data from 350 organisations, I can testify that we are not consistent! – and this lack of consistency impairs discovery.
Archival content is likely to be distinct in terms of both quality and subject. Typescripts might be old and faded, manuscripts might be hard to read, photographs might be black and white and not as high resolution as modern prints. Photographs might be of historical artefacts that are not recognised by most algorithms. We have specific challenges with our material, and we need the algorithms to learn from our material, in order to then provide something useful as we input more content.
In terms of subject, the Lotus and Delta shoe shops are a good example of a specific topic. They are represented in the Joseph Emberton papers, at the University of Brighton Design Archives, with a series of photographs. Architecture is potentially an interesting area to focus on. ML could give us some outputs that provide information on architectural features. It could be that the design of Lotus and Delta shops can be connected to other shops with similar architectures and shop fronts. ML may pick out features that a cataloguer may not include. On the other hand, we may find that it is extremely hard to train an algorithm on old black and white and potentially low resolution photographs in order for it to learn what a shop is, and maybe what a shoe shop is.
In this collection a number of the photographs are of exteriors. Some are identified by location, and some are not yet identified.
Harrogate
Edinburgh
Unidentified shop
These photographs have been catalogued to item level, and so researchers will be able to find these when searching for ‘shops’ and particularly ‘shoe shops’ on the Hub, e.g. a search for ‘harrogate shoe shop‘ finds the exterior of a shop front in Harrogate. There may not be much more that could be provided for searching this collection, unless machine learning could label the type of shop front, the type of windows and signage for example. This seems very challenging with these old photographs, but presumably not impossible. With ML it is a matter of trying things out. You might think that if artificial intelligence can master self-driving cars it can master shop exteriors….but it is not a foregone conclusion.
If the model was trained with this set of photographs, then other shop fronts could potentially be identified in photographs that aren’t catalogued individually. We could potentially end up with collections from many different archives tagged with ‘shop front’ and potentially with ‘shoes’. Whether an unidentified shop front could be be identified is less certain, unless there are definite contextual features to work with.
Interior of ladies’ dept.
Interior of men’s dept.
Shop interiors are likely to be even more of a challenge. But it will be exciting to try things like this out and see what we get.
Commercial providers offer black box solutions, and we can be sure they were not trained to work well with archives. They may be adapted to new situations, but it is unlikely they can ever work effectively for archival content. I explored this to an extent in my last blog post. However, it is worth considering that a model not trained on archival material may highlight objects or topics that we would not think of including in a catalogue entry.
The Archives Hub and Jisc could play a pivotal role in co-ordinating work to create better models for archival material. Aggregation allows for providing more training material, and thus creating more effective models.
‘To date, most ML projects in libraries have required bespoke data annotation to create sufficient training data. Reproducing this work for every ML project, however, risks wasting both time and labor, and there are ample opportunities for scholars to share and build upon each other’s work.’ (R. Cordell, LC Labs report)
We can have a role to play in ‘data gathering, sharing, annotation, ethics monitoring, and record-keeping processes‘ (Eun Seo Jo, Timnit Gebru, https://arxiv.org/abs/1912.10389). We will need to think about how to bring our contributors into the loop in order to check and feedback on the ML outputs. This is a non-trivial part of the process that we are considering at the moment. We need an interface that displays the results of our ML trials.
One of the interesting aspects of this is that collections that have been catalogued in detail will provide the training data for collections that are not. Will this prove to be a barrier, or will it bring us together as a community? In theory the resources that some archives have, which have enabled them to catalogue to item level, can benefit those with minimal resources. Would this be a free and open exchange, or would we start to see a commercial framework developing?
It is also important that we don’t ignore the catalogue entries from our 350 contributors. Catalogues could provide great fodder for ML – we could start to establish connections and commonalities and increase the utility of the catalogues considerably.
The issue of how to incorporate the results of ML into the end user discovery interface is yet another challenge. Is it fundamentally important that end users know what has been done through ML and what has been done by a human? I can’t help thinking that over time the lines will blur, as we become more comfortable with AI….or as AI simply becomes more integrated into our world. It is clear that many people don’t realise how much Artificial Intelligence sits behind so many systems and processes that we use on an everyday basis. But I think that for the time being, it would be useful to make that distinction within our end user interfaces, so that people know why something has been catalogued or described in a certain way and so that we can assess the effectiveness of the ML contribution.
In subsequent posts we aim to share some initial findings from doing work at scale. We will only be able to undertake some modest experiments, but we hope that we are contributing to the start of what will be a very big adventure for archives.
For the 30,000 traumatised refugees from Nazi-occupied Austria living in the UK at the start of the Second World War, the Austrian exile theatre the Laterndl was a beacon of light and hope during the dark days of the Third Reich. Refugees were living with the loss of their homes, the uncertain fate of families left behind, and the poverty and isolation of exile life. At the theatre they could laugh, weep and mourn together over stories, music and poetry presented by performers who shared the same experiences. For the artists themselves, the theatre allowed them to escape the daily grind of refugee life, provide a home for Austrian culture and contribute to the fight against Nazism.
Laterndl publicity leaflet, 1939 (Miller/6/1/1)
Members of the Research Centre for German and Austrian Exile Studies at the University of London have begun to piece together the history of the theatre using the papers of Austrian Jewish refugees Martin Miller and Hannah Norbert Miller, key figures at the Laterndl. Their papers are one of a growing number of archives of German-speaking exiles held at Senate House Library on behalf of the Institute of Modern Languages Research. A programme to catalogue and promote the collections has been funded in recent years by the Martin Miller and Hannah Norbert Miller Trust and the records have now been added to the Archives Hub. This feature for the Hub marks Women’s History Month by considering the role of women in the theatre and how they contributed to its aim to keep alive the spirit of resistance to the Nazis.
Five of the 16 artists who contributed to the opening production of the Laterndl in June 1939 were female artists, all experienced professionals. They played an important role both on stage and behind the scenes from the offset. The cast of the first production ‘Unterwegs’ included seasoned theatre performers Lona Cross, Marianne Walla and Greta Hartwig. Cross had performed in regional Austrian theatre and Walla and Hartwig were active in anti-fascist political cabaret in Vienna in the mid-1930s. ‘Unterwegs’ offered a wide range of strong female roles and included one scene, ‘Bow Street’ which was singled out for particular praise by reviewers. Standing on trial at Bow Street court before ‘General Bias’ and ‘Mrs Charity’, Walla, playing the ‘Eternal Woman’ alongside the ‘Eternal Jew’ and the ‘Eternal Revolutionary’, made a powerful plea for leniency and understanding from the British authorities for women who had taken a stand against Nazism.
Greta Hartwig and Martin Miller watching a Laterndl rehearsal, June 1939 (Miller/3/1/1/1)
In early 1940 another Viennese actor already familiar to Austrian theatre audiences joined the troupe, Hannah Norbert Miller (then Hanne Norbert). Norbert soon became one of the leading performers, appearing in over ten productions in three years. She also acted with other exile theatre groups and had a wide network of contacts which helped connect the Laterndl players with the wider German-speaking theatre scene. Norbert’s excellent English enabled her to act as commere, communicating the theatre’s message of resistance against Nazism to British audience members, who included well-known cultural figures like J.B. Priestly and Richard Crossman of the BBC.
Hanne Norbert’s commere script introducing two scenes at the Laterndl, 1940 (Miller/1/2/1/5)
Theatre programmes in the archive indicate that female artists also worked in a range of non-acting roles over the course of the theatre’s existence. Kaethe Knepler was a musician and pianist from Germany who worked as director of music at the Laterndl in 1941 and 1942 together with her husband, Georg, a musicologist. The couple regularly performed as a duo, and in 1940 Kaethe Knepler composed the setting for a song by Jura Soyfer, a young Austrian writer who had died in Buchenwald a year before.
Laterndl programme for a production of Johann Nestroy’s ‘Der Talisman’, 1941 (Miller/5/1/9)
Costumes for the first three productions were the responsibility of two Viennese designers, Hertha Winter and Kaethe Berl. Little is known about Winter’s background, but Berl had studied design at art school and in the post-war era she would became a pioneer in enamel art in New York. With wartime shortages and the Laterndl’s tiny budget, the pair had to summon all their creativity to produce costumes, improvising them out of old garments or purchasing them cheaply here and there, including in the East End’s Petticoat Lane. Berl also designed the distinctive red logo for the theatre shown on the programme (above).
‘Trip to Paradise’ by Jura Soyfer, performed by the Laterndl Theatre, showing costume designed by HertaWinter, with Marianne Walla as Fritzi on the right, 1940 (Miller/3/1/1/5)
One of the most powerful anti-Nazi plays produced by the Laterndl was written by the theatre’s only female writer, journalist and Communist activist Eva Priester. Priester’s ‘The Verdict’, performed in the autumn of 1942, saw Norbert and Walla play two women imprisoned in a cell together in an unknown location in Nazi Europe. The women unite against their male guard and anticipate the liberation of Europe with the declaration: ‘We are not alone. They will come over the sea, by ship, any moment now they could come and land in France and open our doors. Can you hear them – soon they will break down the iron doors – soon they will be here!’
Eva Priester’s ‘The Verdict’, performed by the Laterndl Theatre, with Marianne Walla (left) and Hanne Norbert (right), 1942 (Miller/3/1/1/10)
By the end of the war over 40 women refugees had worked at the theatre, some of them over several years. How many of them managed to rebuild their careers as artists in the post-war world is not recorded these archives, though for a lucky few, at least, the Laterndl was a stepping stone to a career in the performing arts in the UK, such as the BBC. What is clear is that, despite the hardship and pain of their situation, women played a central role in the theatre, helping to keep alive the hopes of the community in a better post-war world and an independent and democratic Austria.
Dr Clare George Archivist (Martin Miller and Hannah Norbert-Miller Trust) Research Centre for German and Austrian Exile Studies Institute of Modern Languages Research University of London School of Advanced Study Senate House Library
Machine Learning is a sub-set of Artificial Intelligence (AI). You might like to look at devopedia.org for a short introduction to Machine Learning (ML).
Machine Learning is a data-oriented technique that enables computers to learn from experience. Human experience comes from our interaction with the environment. For computers, experience is indirect. It’s based on data collected from the world, data about the world.
Definition of Machine Learning from devopedia.org
The idea of this and subsequent blog posts is to look at machine learning from a specifically archival point of view as well as update you on our Labs project, Images and Machine Learning. We hope that our blog posts help archivists and other information professionals within the archival or cultural heritage domain to better understand ML and how it might be used.
At the Archives Hub we are particularly focussed on looking at Machine Learning from the point of view of archival catalogues and digital content, to aid discoverability, and potentially to identify patterns and bias in cataloguing.
Machine Learning to aid discoverability can be carried out as supervised or unsupervised learning. Supervised learning may be the most reliable, producing the best results. It requires a set of data that contains both the inputs and the desired outputs. By ‘outputs’ we mean that the objective is provided by labelling some of the input data. This is often called training data. In a ‘traditional’ scenario, code is written to take input and create output; in machine learning, input and output is provided, and the part done by human code is instead done by machine algorithms to create a model. This model is then used to derive outputs from further inputs.
The machine learning model, or program, is the outcome of learning from data (source: Advani 2020)
So, for example, taking the Vickers instruments collection from the Borthwick: https://dlib.york.ac.uk/yodl/app/collection/detail?id=york%3a796319&ref=browse. You may want to recognise optical instruments, for example, telescopes and microscopes. You could provide training data with a set of labelled images (output data) to create a model. You could then input additional images and see if the optical instruments are identified by the model.
Of course, the Borthwick may have catalogued these photographs already (in fact, they have been catalogued), so we know which are telescopes and which are micrometers or lenses or eye pieces. If you have a specialist collection, essentially focused on a subject, and the photographs are already labelled, then there may be less scope for improving discoverability for that collection by using machine learning. If the Borthwick had only catalogued a few boxes of photographs, they might consider using machine learning to label the remaining photographs. However, a big advantage is that the enhanced telescope recognising model can now be used on all the images from the Archives Hub to discover and label images containing telescopes from other collections. This is one of the great advantages of applying ML across the aggregated data of the Archives Hub. The results of machine learning are always going to be better with more training data, so ideally you would provide a large collection of labelled photographs in order to teach the algorithm. Archive collections may not always be at the kind of scale where this process is optimised. Providing good training data is potentially a very substantial task, and does require that the content is labelled. It is possible to use models that are already available without doing this training step, but the results are likely to be far less useful.
Another scenario that could lend itself to ML is a more varied collection, such as Borthwick’s University photograph collection. These have been catalogued, but there is potential to recognise various additional elements within the photographs.
Construction of the J.B. Morrell Library, University of York
The above photograph has been labelled as a construction site. ML could recognise that there are people in the photograph, and this information could be added, so a researcher could then look for construction site with people. Recognising people in a photograph is something that many ML tools are able to do, having already been trained on this. However, archive collections are often composed of historic documents and old photographs that may not be as clear as modern documents. In addition, the models will probably have been trained with more current content. This is likely to be an issue for archives generally. For models to be effective, they need to have been trained with content that is similar to the content we want to catalogue.
The benefits of adding labels to photographs via ML to potentially enhance the catalogue and help with discoverability is going to depend upon a number of factors: how well the image is already catalogued, whether training data can be provided to improve the algorithm, how well ML can then pick out features that might be of use.
The drawings of fossil fish at the Geological Society are another example of a very subject specific collection. We put a few of these through some out-of-the-box ML tools. These tools have been pre-trained on large diverse datasets, but we have not done any additional training ourselves yet, so you could see them as generalists in recognising entities rather than specialists with any particular material or topic.
Fossil tortoise from Oeningen
In this case the drawing has been tagged with ‘fossil’, which could be useful if you wanted to identify fossil drawings from a varied collection of drawings. It has also tagged this with archaeology and art, both of which could potentially be useful, again depending upon the context. The label of soil is a bit more problematic, and yet it is the one that has been added with 99.5% certainty. However, a bit of training to tell the algorithm that ‘soil’ is not correct may remove this tag from subsequent drawings.
This example illustrates the above point that a subject specific collection may be tagged with labels that are already provided in the catalogue description. It also shows that machine learning is unlikely to ever be perfectly accurate (although there are many claims it outperforms humans in a number of areas). It is very likely to add labels that are not correct. Ideally we would train the model to make less mistakes – though it is unlikely that all mistakes will be eliminated – so that does mean some level of manual review.
Tagging an image using ML may draw out features that would not necessarily be added to the catalogue – maybe they are not relevant to the repository’s main theme, and in the end, it is too time-consuming for cataloguers themselves to describe each photo in great detail as part of the cataloguing process.
Queen’s University Belfast: Hart Collection – China Photographs
The above image is a simple one with not too much going on. It will be discoverable on the Queen’s website through a search for ‘china’ or ‘robert hart’ for example, but tagging could make it discoverable for those interested in plants or architectural features. Again, false positives could be a problem, so a key here is to think about levels of certainty and how to manage expectations.
As mentioned above, archival images are often difficult to interpret. They may be old and faded, and they may also represent features or items that an algorithm will not recognise.
Design Council Archive: Things in their home setting – detail of a living room
In the above example from Brighton Design Archives, the photograph is from a set made of an exhibition of 1947, Things In Their Home Setting. The AWS image Rekognition service has no problem with the chair, but it has confidently identified the oven as a refrigerator. This could probably be corrected by providing more training data, or giving feedback to improve the understanding of the algorithm and its knowledge of 1940’s kitchen furniture. But by the time you have given enough training data for the model to recognise a cooker from a fridge from a washing machine, it might have been easier simply to do the cataloguing manually.
Another option for machine learning is optical character recognition. This has been around for a while, but it has improved substantially as a result of the machine learning approach. Again, one of the challenges for archives is that many items within the collections are handwritten, faded, and generally not easily readable. So, can ML prove to be better with these items than previous OCR approaches?
A tool like Transkribus can potentially offer great benefits to archives, and is seen as a community-driven effort to create, gather and share training data. We hope to try out some experiments with it in the course of our project.
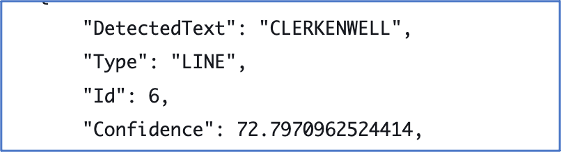
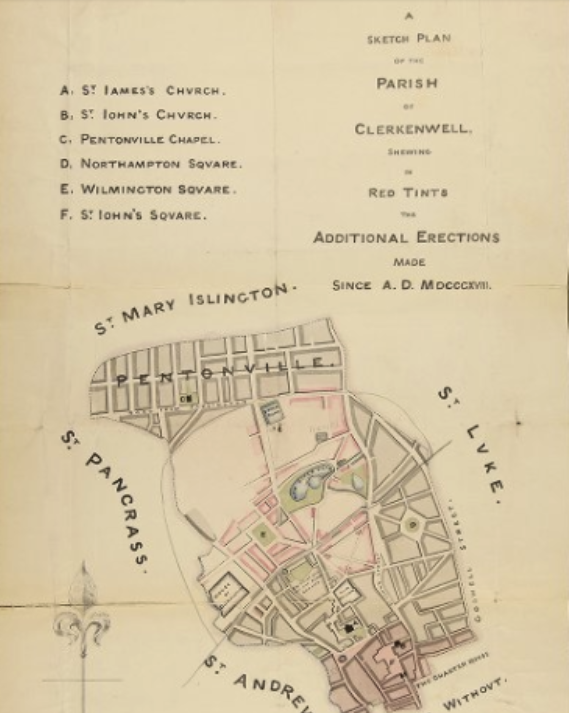
Clerkenwell St James Parish, General Plan
The above plan is from Lambeth Palace Library’s 19th century ecclesiastical maps. It can already be found searching for ‘clerkenwell’ or ‘st james parish’. But ML could potentially provide more searchable information.
OCR using Azure
The words here are fairly clear, so the character recognition using the Microsoft Azure ML service is quite good. Obviously the formatting is an issue in terms of word order. ‘James’ is recognised as ‘Iames’ due to the style of writing. ‘Church’ is recognised despite the style looking like ‘Chvrch’ – this will be something the algorithm has learnt. This analysis could potentially be useful to add to the catalogue because an end user could then search for ‘pentonville chapel’ or ‘northampton square’ and find this plan.
As well as looking at digital archives, we will be trying out examples with catalogue text. A great deal of archival cataloguing is legacy data, and archivists do not always have the time to catalogue to item level or to add index terms, which can substantially aid discoverability. So, it is tempting to look at ML as a means to substantially improve our catalogues. For example, to add to our index terms, which provide structured access points for end users searching for people, organisations, places and subjects.
In a traditional approach to adding subject terms to a catalogue, you might write rules. We have done this in our Names Project – we have written a whole load of rules in order to identify name, life dates, and additional data within index terms. We could have written even more rules – for example, to try to identify forename and surname. But it would be very difficult because the data does not present the elements of names consistently. We could potentially train an ML model with a load of names, tagging the parts of the name as forename, surname, dates, titles, epithets. But could an algorithm then successfully work out the parts of any subsequent names that we feed into it? It seems unlikely because there is no real consistency in how cataloguers input names. The algorithm might learn, for example, that a word, then a comma, then another word is surname, forename (Roberts, Elizabeth). But two words followed by a comma and another word could be surname + forename or forename + surname, (Vaughan Williams, Ralph; Gerald Finzi, composer). In this scenario, the best option may be to aim to use source data (e.g. the Virtual International Authority File) to compare our data to, rather than try to train a machine to learn patterns, when there really isn’t a model to provide the input.
We may find that analysing text within a catalogue offers more promise.
Part of the admin history for the British Linen Company archive at Lloyds
Here is an example from an administrative history of the British Linen Group, a collection held by Lloyds Banking Group. The entity recognition is pretty good – people’s names, organisations, dates, places, occupations and other entities can be picked out fairly successfully from catalogues. Of course that is only the first step; it is how to then use that information that is the main issue. You would not necessarily want to apply the terms as index terms for example, as they may not be what the collection is substantially about. But from the above example you could easily imagine tagging all the place names with a ‘place’ tag, so that a place search could find them. So, a general search for Stranraer would obviously find this catalogue entry, but if you could identify it as a place name it could be included in the more specific place name search.
With machine learning it is very difficult and sometimes impossible to understand exactly what is happening and why. By definition, the machine learns and modifies its output. Whilst you can provide training data to give inputs and desired outputs, machine learning will always be just that….a machine learning as it goes along, and not simply working through a programme that a human has written. Supervised learning provides for the most control over the outputs. Unsupervised learning, and deep learning, are where you have much less control (we’ll come onto those in later posts).
It is only by understanding the algorithms and what they are doing that you can set up your environment for the best results. But that is where things can get very complicated. We are going to try to run some experiments where we do prepare the data, but learning how to do this is a non-trivial task. Hence one of the questions we are asking is ‘is Machine Learning worth the effort required in order to improve archival discoverability?’ We hope to get at least some way along the road to answering that question.
There are, of course, other pressing questions, not least the issue of bias, and concerns about energy use with machine learning as well as how to preserve the processes and outputs of ML and document the decision making. But there could be big wins in terms of saving time that can then be dedicated to other tasks. The increasing volumes of data that we have to process may make this a necessity. We hope to touch upon some of these areas, but this is a fairly small scale project and Machine Learning it is one huge topic.
In 1984 reports of an unfolding famine crisis in East Africa began to reach the international community. Band Aid’s ‘Feed the World’ charity song and the Live Aid concerts are probably the most well-known of the responses to the situation, but these were by no means the only efforts. In Birmingham a group of young Muslim volunteers led by Dr Hany El Bana OBE, then a medical student at University of Birmingham, began to fundraise in mosques, though friends and family and local Islamic associations. They were successful in raising enough funds to implement a project to build two chicken farms in Sudan along with two other projects to distribute biscuits and multivitamins (also to Sudan) and flour to Mauritania in one year. As fundraising efforts took off the name ‘Islamic Relief’ was adopted and a small one-room office was rented from which the group coordinated their growing operations.
Photographs of Islamic Relief’s first project, two chicken farms in Sudan, 1984
Volunteers receive donations for the Sudan Food Crisis and Bangladesh Flooding Appeals in Birmingham, 1988
Fundraising around the seasonal observance of Ramadan (a sacred month of fasting in Islam) soon became a mainstay. The group organised tours of national mosques selling prayer mats and other small items in a van they called the ‘Caravan’. Raising money through the Islamic principles of zakat (a form of alms-giving and religious tax) and sadaqah (voluntary charity giving) were also a key part of the work and remain so at Islamic Relief to this day. This evidence of Muslim community based voluntary action is one part of what makes the Islamic Relief Archive truly unique and significant. Today Islamic Relief Worldwide has grown to one of, if not the world’s largest Islamic faith-inspired NGOs currently working in over 40 countries. Islamic Relief was founded with a single donation of 20p, in 2020 we had and income of over £149 million.
Ramadan Appeal flyer, 1980s
Humanitarian and development work has always been at the heart of what Islamic Relief does. The archive documents major humanitarian responses to some of the most notable global events of the last four decades. This includes conflict in Bosnia and Chechnya in the 1990s, crises in Iraq and Afghanistan in the 2000s, tsunami in Asia 2004, genocide in Rwanda in 1994 and earthquake in Pakistan in 2006. The ‘International Programmes’ series (IRW/IP) contains a wealth of materials relating to both emergency responses and also development work in countries such as India, Bangladesh, Mali, Niger and Occupied Palestinian Territories. Here you can find records such as project reports, country strategy documents and case studies. You can also find related photographic materials in the ‘Audio Visual’ (IRW/AV) series, publications such as emergency update reports, country annual reports and newsletters in the ‘Publications and ephemera’ series (IRW/PUB). Within the fundraising the ‘Emergency appeals’ sub-series (IRW/FU/2/3) will also yield results on IRW’s fundraising efforts in relation to specific international situations. Today, Islamic Relief is present at crises in Afghanistan, Syria and Yemen. The archive continues to collect materials relating to these significant global events.
2002 Emergency Appeal flyer
A sample from Kosova Shelter Project report, 1999 (page 1)
A sample from Kosova Shelter Project report, 1999 (page 2)
In 2021 Islamic Relief made its archive accessible to the public for the first time with our catalogues newly available through Archives Hub. The records have meaning at a local, national and international level and we believe that in making them accessible they will not only contribute to research in the fields of humanitarianism and histories of the charity sector, they will also importantly increase the representation of Muslims and Muslim communities in the shared archival landscape. As the archive continues to grow and further cataloguing is undertaken we hope that researchers and a wide public audience will be able to benefit from this rich and valuable source of local and global memory.
Elizabeth Shuck, Archivist Islamic Relief Worldwide
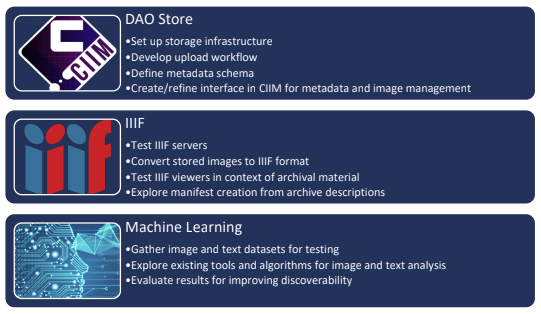
Under our new Labs umbrella, we have started a new project, ‘Images and Machine Learning’ it has three distinct and related strands.
The three themes of the project
We will be working on these themes with ten participants, who already contribute to the Archives Hub, and who have expressed an interest in one or more of these strands: Cardiff University, Bangor University, Brighton Design Archives at the University of Brighton, Queens University Belfast, the University of Hull, the Borthwick Institute for Archives at the University of York, the Geological Society, the Paul Mellon Centre, Lambeth Palace (Church of England) and Lloyds Bank.
This project is not about pre-selecting participants or content that meet any kind of criteria. The point is to work with a whole variety of descriptions and images, and not in any sense to ‘cherry pick’ descriptions or images in order to make our lives easier. We want a realistic sense of what is required to implement digital storage and IIIF display, and we want to see how machine learning tools work with a range of content. Some of the participants will be able to dedicate more time to the project, others will have very little time, some will have technical experience, others won’t. A successful implementation that runs beyond our project and into service will need to fit in with our contributors needs and limitations. It is problematic to run a project that asks for unrealistic amounts of time from people that will not be achievable long-term, as trying to turn a project into a service is not likely to work.
DAO Store
Over the years we have been asked a number of times about hosting content for our contributors. Whilst there are already options available for hosting, there are issues of cost, technical support, fit for purpose-ness, trust and security for archives that are not necessarily easily met.
Jisc can potentially provide a digital object store that is relatively inexpensive, integrated with the current Archives Hub tools and interfaces, and designed specifically to meet our own contributors’ requirements. In order to explore this proposal, we are going to invest some resource into modifying our current administrative interface, the CIIM, to enable the ingest of digital content.
We spent some time looking at the feasibility of integrating an archival digital object store with the current Jisc Preservation Service. However, for various reasons this did not prove to be a practical solution. One of the main issues is the particular nature of archives as hierarchical multi-level collections. Archival metadata has its own particular requirements. The CIIM is already set up to work with EAD descriptions and by using the CIIM we have full control over the metadata so that we can design it to meet the needs of archives. It also allows us to more easily think about enabling IIIF (see below).
The idea is that contributors use the CIIM to upload content and attach metadata. They can then organise and search their content, and publish it, in order to give it web address URIs that can be added to their archival descriptions – both in the Archives Hub and elsewhere.
It should be noted that this store is not designed to be a preservation solution. As said, Jisc already provides this service, and there are many other services available. This is a store for access and use, and for providing IIIF enabled content.
The metadata fields have not yet been finalised, but we have a working proposal and some thoughts about each field.
Title
mandatory? individual vs batch?
Dates
preferably structured, options for approx. and not dated.
Licence
possibly a URI. option to add institution’s rights statement.
Resource type
controlled list. values to be determined with participants. could upload a thesaurus. could try ML to identify type.
Keywords
free text
Tagging
enable digital objects to be grouped e.g by topic or e.g. ‘to do’ to indicate work is required
Status
unpublished/published. May refer to IIIF enabled.
URL
unique URI of image (at individual level)
Proposed fields for the Digital Object Store
We need to think about the workflow and user interface. The images would be uploaded and not published by default, so that they would only be available to the DAO Store user at that point. On publication, they would be available at a designated URL. Would we then give the option to re-size? Would we set a maximum size? How would this fit in with IIIF and the preference for images of a higher resolution? We will certainly need to think about how to handle low resolution images.
International Image Interoperability Framework
IIIF is a framework that enables images to be viewed in any IIIF viewer. Typically, they can be sequenced, such as for a book, and they are zoomable to a very high resolution. At the heart of IIIF is the principle that organisations expose images over the web in a way that allows researchers to use images from anywhere, using any platform that speaks IIIF. This means a researcher can group images for their own research purposes, and very easily compare them. IIIF promotes the idea of fully open digital content, and works best with high resolution images.
There are very good reasons for the Archives Hub to get involved in IIIF, but there are challenges being an aggregator that individual institutions don’t face, or at least not to the same degree. We won’t know what digital content we will receive, so we have to think about how to work with images of varying resolutions. Our contributors will have different preferences for the interface and functionality. On the plus side, we are a large and established service, with technical expertise and good relationships with our contributors. We can potentially help smaller and less well-resourced institutions into this world. In addition, we are well positioned to establish a community of use, to share experiences and challenges.
One thing that we are very convinced by: IIIF is a really effective way to surface digital content and it is an enormous boon to researchers. So, it makes total sense for us to move into this area. With this in mind, Jisc has become a member of the IIIF Consortium, and we aim to take advantage of the knowledge and experience within the community – and to contribute to it.
Machine Learning
This is a huge area, and it can feel rather daunting. It is also very complicated, and we are under no illusions that it will be a long road, probably with plenty of blind alleys. It is very exciting, but not without big challenges.
It seems as if ML is getting a bad reputation lately, with the idea that algorithms make decisions that are often unfair or unjust, or that are clearly biased. But the main issue lies with the data. ML is about machines learning from data, and if the data is inadequate, biased, or suspect in some way, then the outcomes are not likely to be good. ML offers us a big opportunity to analyse our data. It can help us surface bias and problematic cataloguing.
We want to take the descriptions and images that our participants provide and see what we can do with ML tools. Obviously we won’t do anything that affects the data without consulting with our contributors. But it is best with ML to have a large amount of data, and so this is an area where an aggregator has an advantage.
This area is truly exploratory. We are not aiming for anything other than the broad idea of improved discoverability. We will see if ML can help identify entities, such as people, places and concepts. But we are also open to looking at the results of ML and thinking about how we might benefit from them. We may conclude that ML only has limited use for us – at least, as it stands now. But it is changing all the time, and becoming more sophisticated. It is something that will only grow and become more embedded within cultural heritage.
Over the next several months we will be blogging about the project, and we would be very pleased to receive feedback and thoughts. We will also be holding some webinar sessions. These will be advertised to contributors via our contributors list, and advertised on the JiscMail archives-nra list.