We are very pleased to announce that the Archives Hub has joined forces with The University of Brighton Design Archives for an exciting new project, funded by the Arts and Humanities Research Council, ‘Exploring British Design’. The project is funded as one of ten new ‘Amplification Awards’ from the AHRC.
We will be working with Catherine Moriarty, Curatorial Director of the University of Brighton Design Archives and Professor of Art and Design History in the Faculty of Arts. Catherine, myself and others on the project aim to provide you with updates and insights through the Archives Hub blog over the next 12 months.
* * *
The project will explore Britain’s design history by connecting design-related content in different archives. A collaboration between researchers, information professionals, technologists, curators and historians, the aim is to give researchers the freedom to explore the depth of detail held in British design archives.
We will be working with researchers to understand more about their use of archives and methods of archival research within design history. We aim to answer a number of research questions:
1. How can we link digital content and subject expertise in order to make archival content more discoverable for researchers? How can we increase the discoverability of design archives in and beyond the HE sector?
2. How can connected archival data better recover ‘lost moments of design action’? (Dilnot 2013: 337)
3. How might a website co-designed by researchers, rather than a top-down collection-defined approach to archive content, enhance engagement with and understanding of British design? How can we encourage researchers, archive and museum professionals, and the public, to apprehend an integrated and extended rather than collection-specific sense of Britain’s design history?
4. How can the principles of archive arrangement/description be made meaningful and useful to researchers? Are these principles sometimes a hindrance to public understanding, or can they be utilised to better effect to aid interpretation?
We want to use this opportunity to explore ways of presenting archival data beyond the traditional collection level description. We will be working with three main sources of data:
1) We will be utilising and enhancing the data within the Archives Hub, starting with the descriptions of the collections held at Brighton Design Archives, but also utilising other descriptions of archives held all across the UK, covering manufacturing history, art schools, personal perspectives and professional contexts, so that we make the most of the diversity of the archives described on the Hub.
2) We will be creating archival authority records, using the EAC-CPF XML format for ISAAR(CPF) records
3) We will be working with the Design Museum and looking to integrate their object-based data into our data set
We will also be working to integrate other sources of data into our authority records.
We aim to provide a front-end that demonstrates what is possible with rich and connected data sources. Our intention is to be led by researchers in this endeavour. It will give us the opportunity to explore researcher needs and requirements, and to understand more about the importance of familiarity with interfaces compared to the possibilities for ‘disruptive’ approaches that propose more radical solutions to interrogating the data.
We are grateful to the AHRC for giving us the opportunity to explore these important questions and take digital research to another level.
The Archives Hub contains a range of material linked with dance – dancers, choreographers and teachers, schools and companies, ballet, contemporary and other styles of dance. This feature highlights some of these collections.
Dancers and Choreographers
Jack Cole Scrapbook Collection, 1910s-1970s, dancer and choreographer. He was known for his unpredictability and originality, grafting on elements from Indian, Oriental, Carribean, Latin American, Spanish, and African-American dance. He worked on Broadway and in Hollywood as both dancer and choreographer, being popularly remembered for his choreography for Marilyn Monroe. http://archiveshub.ac.uk/data/gb71-thm/106
Ram Gopal Collection, 1930s-2004, dancer, choreographer and teacher. Gopal was trained in classical Indian dance forms of Kathakali, Bharatra Natya and Manipuri. He wanted Eastern and Western dance forms to work together and taught Indian folk dance at the Harlequin Ballet Company. http://archiveshub.ac.uk/data/gb1975-ram
Papers of Diana Gould, 1926-1996, dancer. Diana Rosamund Constance Grace Irene Gould was a British ballerina. Early in her career Sergei Diaghilev spotted her and invited her to join his Ballets Russes but he died before this could be arranged, events said to have been fictionalized in the film ‘The Red Shoes’. Diana married Sir Yehudi Menuhin in 1947. http://archiveshub.ac.uk/data/gb2228-dpdg
Papers relating to the career of Bruce McClure, 1925-1989, dancer and choreographer. Bruce McClure trained as a dancer and worked as a dancer at the Citizens’ Theatre among other places. In the 1960s he moved on to choreography including for television. http://archiveshub.ac.uk/data/gb247-stabmc
Collection of material relating to Margaret Morris, 1891-1980, ballet dancer and choreographer. She established the first national ballet company for Scotland, developed a modern dance technique and a system of movement therapy. http://archiveshub.ac.uk/data/gb247-stabq1
Harry Relph (Little Tich) volumes, 1881-1974, dancer. Known on stage as Little Tich (he was 4 foot 6 inches tall), Harry Relph became one of Britain’s most popular music-hall and variety acts. One of his best known routines was called ‘Big Boots’, which had him dancing in boots that were 28 inches long. http://archiveshub.ac.uk/data/gb71-thm/326
Dance schools, companies and educational organisations
Tap dancing class in the gymnasium at Iowa State College, 1942. Library of Congress, LC-DIG-ppmsc-00250.
Papers relating to the Pushpalata Dance Company, 1991-2005. The company focuses on Odissi and Kathak dance practices, but also performs in a number of collaborations with Western dance forms, most notably investigating the point at which Flamenco and Kathak dance meet. http://archiveshub.ac.uk/data/gb1975-pu
Philip Richardson Archive Collection, Royal Academy of Dance, c1900-1963; c1760-1780; c1800-1900. Richardson’s interest in the history of dancing led him to become an avid collector of rare books on the subject. His personal library collection was bequeathed to the RAD after his death in 1963. http://archiveshub.ac.uk/data/gb3370-rad/pjsr
The Mimi Legat Collection, The Royal Ballet School, White Lodge Museum, 1900-1970. Papers relating to the Russian ballet dancers Sergei Legat, Nicolas Legat, and Nadine Nicolaeva-Legat. http://archiveshub.ac.uk/data/gb3208-rbs/mim
Marie Rambert collection, Rambert Dance Company, 1890s-1980s. Collection of films, costumes, photographs, correspondence, diaries, programmes, press cuttings, personal papers, autobiographical notes, awards and medals owned and collected by Dame Marie Rambert throughout her life as well as papers relating to her death and memorials. http://archiveshub.ac.uk/data/gb2228-mr
Laban Collection, Trinity Laban Conservatoire of Music and Dance, 1918-2001. Papers and other material relating to Rudolf Laban: teacher, philosopher, dancer, choreographer, author, experimentor and the father of modern dance. http://archiveshub.ac.uk/data/gb1701-lc
Ballet
Dance scrapbooks (ballet), c1951-1978. Containing newspaper cuttings of national and international ballet companies and dancers including Margot Fonteyn and Rudolf Nureyev. http://archiveshub.ac.uk/data/gb1701-lz
Ekstrom Collection: Diaghilev and Stravinsky Foundation, 1902-1984. Letters, financial records, and telegrams, which give a unique insight into the day-to-day running of Diaghilev’s Ballets Russes. http://archiveshub.ac.uk/data/gb71-thm/7
Russian Ballet Collection, 1911-1914. Programmes of the Russian Ballet’s seasons at the Theatre du Chatelet, Paris, held by the University of Exeter. Included are many colour illustrations of costume designs, as well as photographs and illustrations of various dancers and text about various ballet productions. http://archiveshub.ac.uk/data/gb29-eulms158
Records of Scottish Ballet, 1952-1999. Programmes, photographs, leaflets, periodicals, press cuttings, posters and other papers relating to the Scottish Ballet and Western Ballet Theatre. http://archiveshub.ac.uk/data/gb247-gb247stasbetc
Valentine Gross Archive, 1700-1960s. Valentine Gross, a.k.a. Valentine Hugo (1887-1968), was a French art ballet enthusiast, illustrator, researcher and painter and still a student at the time of 1909 Saison Russe in Paris. http://archiveshub.ac.uk/data/gb71-thm/165
Contemporary dance
Trinity Laban Conservatoire of Music and Dance logoBonnie Bird Choreography Fund Archive, 1981-2001. The Bonnie Bird Choreography Fund was established in 1984 to support and promote innovative choreographers and dance writers in Britain, Europe and America. http://archiveshub.ac.uk/data/gb1701-d25
Contemporary Dance Trust Archive, 1957-1998. Consists of papers relating to the running of the Contemporary Dance Trust which incorporated the London Contemporary Dance Theatre and the London Contemporary Dance School. http://archiveshub.ac.uk/data/gb71-thm/22
Independent Dance at the Holborn Centre for Performing Arts Archive, 1989-1999. Independent Dance is an artist-led organisation which provides specialist training to contemporary dance artists. It was established in 1990 and has the longest running daily training programme in the UK. http://archiveshub.ac.uk/data/gb1701-d17
Bob Lockyer Collection, 1970-1995. Photographs and scripts from various dance programmes produced for the British Broadcasting Company (BBC) by Bob Lockyer. http://archiveshub.ac.uk/data/gb1701-d8
Dorothy Madden Collection, 1912-2002. Dr Dorothy Gifford Madden, former Professor Emerita of the University of Maryland, United States of America who was responsible for bringing American modern dance practice to the United Kingdom. http://archiveshub.ac.uk/data/gb1701-d23
Transitions Dance Company Archive, c1985-2009. Established in 1983, Transitions Dance Company was among the first graduate performance companies in the United Kingdom. http://archiveshub.ac.uk/data/gb1701-d24
Clubs, societies and other dance-related collections
Dance theatre programmes collection, c1950-1999. A collection of over 3,000 dance theatre programmes from over 500 national and international dancers and dance companies. http://archiveshub.ac.uk/data/gb1701-ld
Papers of the Foundation for Community Dance and predecessors, 1984-2011. Papers of the Foundation for Community Dance and its predecessors the Community Dance and Mime Foundation and the National Association of Dance and Mime Animateurs. http://archiveshub.ac.uk/data/gb3071-d/036
Henry Rolf Gardiner: Letters to Margaret Gardiner, 1921-1960. 34 letters from Gardiner (businessman and author) to his sister Margaret Gardiner, on his time at Cambridge. Topics include folk-dancing, morris-dancing and work on a dance-book. http://archiveshub.ac.uk/data/gb012-ms.add.8932
Sadler’s Wells Theatre Archive, c1712-2012. The Sadler’s Wells site has been occupied by six different theatres since 1683. The current theatre, which opened in 1998, is dedicated to international dance. http://archiveshub.ac.uk/data/gb1032-s/swt
Peter Williams Collection, c1950-1980. Williams was the editor of the journal Dance and Dancers. The collection includes c40,000 black and white photographs of dancers and dance companies from all over the world. http://archiveshub.ac.uk/data/gb1701-d11
We’re delighted to announce that we now have more than 250 UK institutions and organisations contributing to the Archives Hub! That amounts to:
* over 26,000 collection-level descriptions
* over 350,000 lower-level descriptions
Our contributors include universities, businesses, local authorities, museums, cathedrals, charities and other organisations. The wide range of archives covered by the Hub is demonstrated by the latest descriptions, received from:
Barclays Group
Barclays Group Archives is one of the principal financial and business archives in the UK. The parent company, Barclays PLC, has been providing banking services continuously since 1690, with records dating mainly from the early 1700s onwards. Collections include: Barclays Bank, Lombard Street (London): board, management and head office records (1896-1985) and Goslings and Sharpe: private bankers, Fleet Street (London): branch records including customer ledgers (1717-1972). http://archiveshub.ac.uk/contributors/barclays.html
Doncaster Archives, Local Studies and Family History
The Archives and Local Studies services collect, preserve and provide access to a comprehensive collection of historical and contemporary information relating to the town of Doncaster, its metropolitan district and some adjacent areas. Collections include records of the Yorkshire Archaeological Society: Doncaster Group (1948-1986). http://archiveshub.ac.uk/contributors/doncaster.html
Feminist Webs Archive
Set up in 2008 by a group of young women, their female youth workers and allies, the Feminist Webs Archive is held at Manchester Metropolitan University. It is both a physical resource and an online resource. The collection is ever-growing with contributions from older feminist youth workers and consists of photographs, banners, leaflets, magazines, oral “her-stories” with older feminist youth workers carried out by young women, and various other documents that are related to feminist youth work with girls and young women. http://archiveshub.ac.uk/contributors/feministwebsarchive.html
Marks and Spencer
Marks and Spencer Company Archive logo
Marks & Spencer began in 1884 when Michael Marks set up a market stall in Leeds. In 1894 he went into partnership with Tom Spencer and a famous high street name was born. Based in Leeds, the M&S Company Archive collects, preserves and utilises material relating to all aspects of the history and development of the company. The Company Archive contains a range of materials from 1884 onwards, including written records, staff publications, photographs and films, garments and household products, design and advertising material. http://archiveshub.ac.uk/contributors/marksandspencer.html
National Jazz Archive
Founded in 1988, the National Jazz Archive is the specialist repository for the history of Jazz in the UK, in addition to the USA and Europe. The collection, comprising mainly 20th century material, includes 2,500 books from 1914 onwards, over 600 periodicals and journals dating from 1927 photographs personal papers, ephemera and a small number of objects. http://archiveshub.ac.uk/contributors/nationaljazzarchive.html
National Railway Museum
The library and archive collections at the National Railway Museum form one of the largest resources of railway and transport history in the world. Collections include technical archives containing drawings of locomotives, carriages and wagons; business records of large companies such as the North British Locomotive company, the Pullman Car Company and The General Electric Company; personal and business papers of prominent railway individuals such as George and Robert Stephenson and their families; railway ephemera and semi-published material including advertising, publicity and design records. http://archiveshub.ac.uk/contributors/nationalrailwaymuseum.html
Paul Mellon Centre for Studies in British Art
The Paul Mellon Centre for Studies in British Art is an educational charity set up to promote original research into the history of British art and architecture. http://archiveshub.ac.uk/contributors/paulmelloncentre.html
Queen Square Archive
The Queen Square Archives are housed in and managed by the Queen Square Library. They comprise the archives belonging to the National Hospital for Neurology and Neurosurgery (named The National Hospital for the Paralysed and Epileptic during the period covered by the Archive) and those of UCL Institute of Neurology. Collections include: 1500 bound volumes of case notes, including many examples of early medical photography (1863-1946); administrative records for the Hospital (1859-1946); employment records (1860-1946); patient admission registers and other health records; approximately 3000 photographs. http://archiveshub.ac.uk/contributors/queensquarearchive.html
Rambert Dance Company
Rambert Dance Company logo
The Rambert Archive holds significant collections documenting the evolution of British dance via the development of Britain’s oldest dance company as we moved from pure classical ballet, through embracing modern American influences, into the future of dance. Collections include: Arts Theatre Ballet (1930s-1941), Company History (1900s-2000s), Marie Rambert Collection (1890s-1980s) and Rambert Dance Company Archive: Productions (1920s-2010s). http://archiveshub.ac.uk/contributors/rambert.html
Royal Ballet School
The Royal Ballet School Collections trace the activities of the institution from its founding in 1926 as the Academy of Choreographic Art to the present day. The Collections include School records; collections relaing more broadly to the development of British Ballet, with substantial collections of lithographs, periodicals, programmes, press cuttings and books; personal collections of international significance, such as Ninette de Valois, the Founder of The Royal Ballet School and Companies, and the class notes of the great teacher, Vera Volkova, among whose students were Margot Fonteyn, Erik Bruhn and Rudolf Nureyev. http://archiveshub.ac.uk/contributors/royalballetschool.html
Royal College of Nursing
Royal College of Nursing logo
Founded in 1916 the Royal College of Nursing has evolved into a successful professional UK-membership body and union. The Royal College of Nursing Archives’ collects across all fields of nursing in the UK and some overseas. The largest and most significant archive is that of the College itself. Other archives include: 30 deposited nursing archives dating back to the 1880s; over 700 personal archives dating from 1815; photographic and postcard collections from the 1880s onwards and 28 handwritten letters written by or addressed to Florence Nightingale (1830-1862). http://archiveshub.ac.uk/contributors/royalcollegeofnursing.html
Salvation Army
The Salvation Army is a worldwide Christian church and registered charity. Founded by William Booth in East London in 1865, The Salvation Army now works in 126 countries. In the United Kingdom, The Salvation Army is one of the largest providers of social services. The Salvation Army International Heritage Centre is the repository for the official records of the organisation’s International and Territorial Headquarters. Collections include: William Booth College (1883-2012), The Salvation Army International Headquarters (1875-2013), papers relating to Catherine Booth (c1847-1995) and The Musical Instrument Factory (1893-1972). http://archiveshub.ac.uk/contributors/salvationarmy.html
In January 2013 the Archives Hub became the UK ‘Country Manager’ for the Archives Portal Europe.
The Archives Portal Europe (APE) is a European aggregator for archives. The website provides more information about the APE vision:
Borders between European countries have changed often during the course of history. States have merged and separated and it is these changing patterns that form the basis for a common ground as well as for differences in their development. It is this tension between their shared history and diversity that makes their respective histories even more interesting. By collating archival material that has been created during these historical and political evolutions, the Archives Portal Europe aims to provide the opportunity to compare national and regional developments and to understand their uniqueness while simultaneously placing them within the larger European context.
The portal will help visitors not only to dig deeper into their own fields of interest, but also to discover new sources by giving an overview of the jigsaw puzzle of archival holdings across Europe in all their diversity.
For many countries, the Country Manager role is taken on by the national archives. However, for the UK the Archives Hub was in a good position to work with APE. The Archives Hub is an aggregation of archival descriptions held across the UK. We work with and store content in Encoded Archival Description (EAD), which provides us with a head start in terms of contributing content.
Jane Stevenson, the Archives Hub Manager, attended an APE workshop in Pisa in January 2013, to learn more about the tools that the project provides to help Country Managers and contributors to provide their data. Since then, Jane has also attended a conference in Dublin, Building Infrastructures for Archives in a Digital World, where she talked about A Licence to Thrill: the benefits of open data. APE has provided a great opportunity to work with European colleagues; it not just about creating a pan-European portal, it is also about sharing and learning together. At present, APE has a project called APEx, which is an initiative for “expanding, enriching, enhancing and sustaining” the portal.
How Content is Provided to APE
The way that APE normally works is through a Country Manager providing support to institutions wishing to contribute descriptions. However, for the UK, the Archives Hub takes on the role of providing the content directly, as it comes via the Hub and into APE. This is not to say that institutions cannot undertake to do this work themselves. The British Library, for example, will be working with their own data and submitting it to APE. But for many archives, the task of creating EAD and checking for validity would be beyond their resources. In addition, this model of working shows the benefits of using interoperable standards; the Archives Hub already processes and validates EAD, so we have a good understanding of what is required for the Archives Portal Europe.
All that Archives Hub institutions need to do to become part of APE is to create their own directory entry. These entries are created using Encoded Archival Guide (EAG), but the archivist does not need to be familiar with EAG, as they are simply presented with a form to fill in. The directory entry can be quite brief, or very detailed, including information on opening hours, accessibility, reprographic services, search room places, internet access and the history of the archive.
Fig 1: EAG entry for the University of East London
Once the entry is created, we can upload the data. If the data is valid, this takes very little time to do, and immediately the archive is part of a national aggregation and a European aggregation.
APE Data Preparation Tool
The Data Preparation Tool allows us to upload EAD content and validate it. You can see on the screen shot below a list of EAD files from the Mills Archive that have been uploaded to the Tool, and the Tool will allow us to ‘convert and validate’ them. There are various options for checking against different flavours of EAD and there is also the option to upload EAC-CPF (which is not something the Hub is working with as yet) and EAG.
Fig 2: Data Preparation Tool
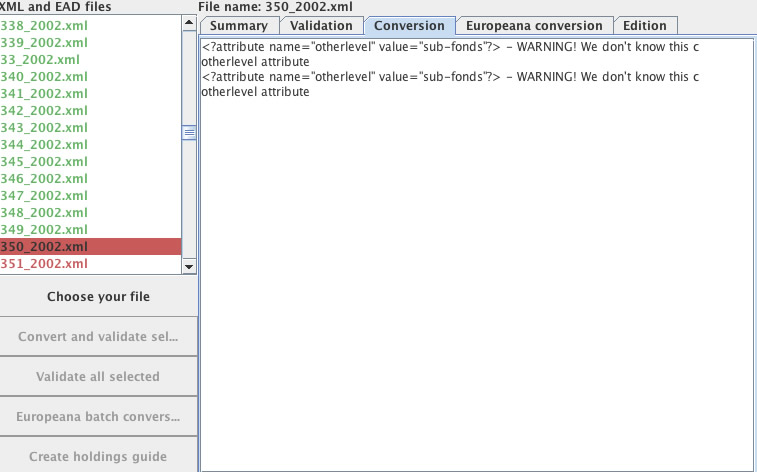
If all goes according to plan, the validation results in a whole batch of valid files, and you are ready to upload the data. Sometimes there will be an invalid file and you need to take a look at the validation message and figure out what you need to do (the error message in this screenshot relates to ‘example 2’ below).
Fig 3: Data Preparation Tool with invalid files
APE Dashboard
The Dashboard is an interface provided to an APE Country Manger to enable them to administer their landscape. The first job is to create the archival landscape. For the UK we decided to group the archives into type:
Fig 4: Archival Landscape
The landscape can be modified as we go, but it is good to keep the basic categories, so its worth thinking about this from the outset. We found that many other European countries divide their archives differently, reflecting their own landscape, particularly in terms of how local government is organised. We did have a discussion about the advantages of all using the same categories, but it seemed better for the end-user to be presented with categories suitable for the way UK archives are organised.
Within the Dashboard, the Country Manager creates logins for all of the archive repositories contributing to APE. The repositories can potentially use these logins to upload EAD to the dashboard, validate and correct if necessary and then publish. But at present, the Archives Hub is taking on this role for almost all repositories. One advantage of doing this is that we can identify issues that surface across the data, and work out how best to address these issues for all repositories, rather than each one having to take time to investigate their own data.
Working with the Data
When the Archives Hub started to work with APE, we began by undertaking a comparison of Hub EAD and APE EAD. Jane created a document setting out the similarities and differences between the two flavours of EAD. Whilst the Hub and APE both use EAD, this does not mean that the two will be totally compatible. EAD is quite permissive and so for services like aggregators choices have to be made about which fields to use and how to style the content using XSLT stylesheets. To try to cover all possible permutations of EAD use would be a huge task!
There have been two main scenarios when dealing with data issues for APE:
(1) the data is not valid EAD or it is in some way incorrect
(2) the data is valid EAD but the APE stylesheet cannot yet deal with it
We found that there were a combination of these types of scenarios. For the first, the onus is on the Archives Hub to deal with the data issues at source. This enables us to improve the data at the same time as ensuring that it can be ingested into APE. For the second, we explain the issue to the APE developer, so that the stylesheet can be modified.
Here are just a few examples of some of the issues we worked through.
Example 1: Digital Archival Objects
APE was omitting the <daodesc> content:
<dao href=”http://www.tate.org.uk/art/images/work/P/P78/P78315_8.jpg” show=”embed”><daodesc><p>’Gary Popstar’ by Julian Opie</p></daodesc></dao>
Content of <daodesc><p> should be transferred to <dao@xlink:title>. It would then be displayed as mouse-over text to the icons used in the APE for highlighting digital content. Would that solution be ok?
In this instance the problem was due to the Hub using the DTD and APE using the schema, and a small transformation done by APE when they ingested the data sufficed to provide a solution.
Example 2: EAD Level Attribute
Archivists are all familiar with the levels within archival descriptions. Unfortunately, ISAD(G), the standard for archival description, is not very helpful with enforcing controlled vocabulary here, simply suggesting terms like Fonds, Sub-fonds, Series, Sub-series. EAD has a more definite list of values:
collection
fonds
class
recordgrp
series
subfonds
subgrp
subseries
file
item
otherlevel
Inevitably this means that the Archives Hub has ended up with variations in these values. In addition, some descriptions use an attribute value called ‘otherlevel’ for values that are not, in fact, other levels, but are recognised levels.
We had to deal with quite a few variations: Subfonds, SubFonds, sub-fonds, Sub-fonds, sub fonds, for example. I needed to discuss these values with the APE developer and we decided that the Hub data should be modified to only use the EAD specified values.
For example:
<c level=”otherlevel” otherlevel=”sub-fonds”>
needed to be changed to:
<c level=”subfonds”>
At the same time the APE stylesheet also needed to be modified to deal with all recognised level values. Where the level was not a recognised EAD value, e.g. ‘piece’, then ‘otherlevel’ is valid, and the APE stylesheet was modified to recognise this.
Example 3: Data within <title> tag
We discovered that for certain fields, such as biographical history, any content within a <title> tag was being omitted from the APE display. This simply required a minor adjustment to the stylesheet.
Where are we Now?
The APE developers are constantly working to improve the stylesheets to work with EAD from across Europe. Most of the issues that we have had have now been dealt with. We will continue to check the UK data as we upload it, and go through the process described above, correcting data issues at source and reporting validation problems to the APE team.
The UK Archival Landscape in Europe
By being part of the Archives Portal Europe, UK archives benefit from more exposure, and researchers benefit from being able to connect archives in new and different ways. UK archives are now being featured on the APE homepage.
Certificates for Cocoa, Chocolate and Sugar Confectionary Manufacture, 1960 and 1962. Two City & Guilds of London Institute certificates presented to Hubert Walter Graham. http://archiveshub.ac.uk/data/gb2110-lsbu/lsbu/3/14/1
Handrawn Valentine’s card sent to Pontecorvo from his students at the University of Glasgow, 14 February 1950. Included in the papers of Guido Pellegrino Arrigo Pontecorvo (1907-1999: geneticist and Professor of Genetics, University of Glasgow). http://archiveshub.ac.uk/data/gb0248-ugc198-9?page=1#gb-0248-ugc-198-9-1-3
Papers and correspondence of Robert William Ditchburn, 1903-1987. Chair of Physics at Reading University, Ditchburn was instrumental in forming the De Beers-supported international Diamond Research Committee which he chaired from its inception in 1956 until 1982. http://archiveshub.ac.uk/data/gb006-ms4621:ditchburn
Will you be my Valentine? Drawing
[undated]. Papers of André Charlot Archive. The drawing includes the name “Joan Charlot”, Charlot’s daughter. http://archiveshub.ac.uk/data/gb71-thm/336
Valentines of Dundee Ltd, 1896-1975.
Established in 1851, the firm began as early exponents of photography, became pioneers in the postcard industry and later developed the production of greetings cards, novelties, calendars and illustrated children’s books. http://archiveshub.ac.uk/data/gb227-ms38562
Barclays Group Archives is a living business archive, with material being managed, made available, interpreted, and added to, by a small team of in-house archivists. We encourage external access to our collections, where possible, bearing in mind any necessary restrictions imposed by customer, commercial and third-party confidentiality.
Some history…
Today Barclays PLC is one of the world’s largest financial services providers, offering banking services to customers in over 50 countries. It has come a long way from its foundation in 1690 by two goldsmith bankers, John Freame and Thomas Gould, in Lombard Street, London. In 1736 James Barclay entered the partnership, and the Barclay name has been a presence in the business ever since. In 1896, 19 smaller banks (all but two being private country partnerships) joined Barclays to form a new joint stock bank – Barclay and Company Limited.
David Barclay the Younger
Many of the founding banks had been established by families who were members of the Society of Friends (also known as Quakers). As a result, a business and social network already existed between several of the banks, one that was strengthened by marriage ties. Their Quakerism also helped to contribute towards the success of their banks, as Quakers were renowned for their sobriety and trustworthiness. David Barclay (1728-1809) epitomised the Quaker banker with a social conscience, being active in the anti-slavery movement.
The businesses from which the country banks had developed included brewing, iron trading, shipping and shop-keeping, but the most common route to a successful country bank was via the textile industry. The Gurneys, who had founded their first bank in Norwich in 1775, had originally been woollen merchants. Their banks were spread across East Anglia and accounted for eight of the twenty firms that took part in the 1896 amalgamation.
Similarly, the Backhouses of Darlington established their bank in 1774 on wealth accumulated in linen manufacturing. It was the Gurneys and the Backhouses, together with Barclays, who formed the driving force behind the new bank.
In 1896 Barclays had 182 branches and 806 staff. The next 20 years saw a spectacular series of takeovers, such that by 1920 Barclays was ranked third amongst Britain’s ‘Big Five’ clearing banks and with a national branch network. The new bank was organised into a network of Local Head Offices based on the old head offices of the original partnership banks. This helped to ensure a degree of continuity for customers and the retention of local knowledge and experience built up by local staff and partners.
Barclays’ ambitions also lay beyond home shores. Under the chairmanship of Frederick Goodenough Barclays acquired the Colonial Bank, with branches in the Caribbean and West Africa; the Anglo-Egyptian Bank; and the National Bank of South Africa. In 1925 these were brought together to form a new international subsidiary – Barclays Bank (Dominion, Colonial and Overseas). Subsequently Barclays established itself in North America and Western Europe, and in more recent decades has expanded into fresh international fields, with a major presence in Asia and the Gulf.
Advert for the fourth of six prototypes of the world’s first through-the-wall cash dispenser,1967
Barclays has been in the forefront of innovation, introducing the UK’s first cash machines, credit and debit cards; was the first bank to order a mainframe computer for customer accounts, and more recently has pioneered contactless card payments and mobile banking.
Recent decades have seen two major domestic acquisitions. Martins Bank, acquired in1968, was itself the result of a 1918 amalgamation between Martins Bank of London, which traced its history back to Elizabeth I’s financial agent Sir Thomas Gresham, and the Bank of Liverpool, a new joint stock bank founded in 1831. In 2000, Barclays acquired The Woolwich, a former building society founded in 1847.
In 1986, Barclays established an investment banking operation, which has since developed into Barclays Capital, a major division of the bank that manages larger corporate and institutional business.
Martins partners’ letter books, 18th century (mentions South Sea Bubble)
Goslings of Fleet Street: customer ledgers, 1717-1900s: one of a handful of surviving complete banking ledger sets for the 18th-19th centuries
Private banking partnership agreements and papers, 18th-19th centuries
Gurney/Barclay letters: social, political and banking life, c1770-c1870
Complete runs of company minute books from the early days of joint stock banking
Langton letters (Bank of England and the financial crisis of 1837)
Bank amalgamation records, 1896 onwards
Visit and inspection reports, UK and overseas, 19th-20th century
Staff magazines and internal communications, 20th century
Photographs of bank premises (including interiors), many showing high street views, over a period of 100 years
Barclays’ main branch and local head office in Canterbury, c1939 (mid-left); the photo also shows St. George’s Street before it suffered extensive bomb damage in the blitz, 1942
Photographs of overseas bank premises, including views of pioneering bank operations in overseas territories, early 1900s onwards
Woolwich: one of a handful of readily accessible building society archives, 1847 onwards
Research potential…
As well as contributing to the documentation of British banking over three centuries, the archives offer potential for the following broad fields of research:
economic history
company and organization history
local and community history
accounting history
investment
biography
commercial architecture
government regulation
colonial and post-colonial development
social history
employment, training and equal opportunities
family history
One interesting recent use of the archives has been by two local historians who have for the last few years been examining the income and expenditure of the earls of Warrington during the late-18th and early-19th centuries, contained in our best surviving set of customer ledgers.
Since the archives service was put on a professional footing in 1990 the collections have been used for a broad variety of research, either wholly or as part of wider projects:
Women in banking and as investors
Architecture and building history for Buildings of England series
Furniture commissioned by Clive of India
Account of Charles Dodgson (Lewis Carroll, author of Alice in Wonderland)
Clients of Alan Ramsay, 18th century Scottish portrait painter
History of agricultural finance
Quaker business and family networks
Decolonisation and post-colonial development in Africa
Development of English building societies
Account of Edward Gibbon, historian
The usury laws in the 1830s
Banking philanthropy, 1870-1912
Banking elites
Emergence and development of professional accountancy in Libya
Employee casualties in World War One
Wallpaper makers, suppliers and their clients, 1700 – 1820
Evidence for women using heavy machinery, early 20th century
Terms of business and commercial bank lending in UK, 1885-1925
International financial regulation and supervision, 1960-1980
Financial crises at the outbreak of the two World Wars
Marriage bar in UK employment history
The public debate about Barclays’ presence in apartheid-era South Africa
History of commercial advertising
Further information and resources…
Detailed database catalogues are available to consult in person, and bespoke catalogues may be generated on request.
In 2013 BGA has become a contributor to The Archives Hub, and intends to add collection-level descriptions, suitably indexed, to supplement its own detailed database catalogues and indexes.
Official published histories of the Group:
M Ackrill & L Hannah, Barclays: the business of banking 1690-1996 (Cambridge University Press 2001); this volume won the Wadsworth Prize for business history
A W Tuke & R J H Gillman, Barclays Bank Limited 1926-1969 (Barclays 1972)
P W Matthews & A W Tuke, History of Barclays Bank Limited: including the many private and joint stock banks amalgamated and affiliated with it (Blades, East & Blades 1926)
Sir J Crossley & J Blandford, The DCO Story: a history of banking in many countries 1925-71 (Barclays 1975)
[R H Mottram, comp] A Banking Centenary: Barclays Bank (Dominion, Colonial & Overseas) 1836-1936 (Barclays, private circulation [1937])
anon., A Bank in Battledress: being the story of Barclays Bank (Dominion, Colonial & Overseas) during the second world war 1939-45 (Barclays, private circulation 1948)
G Chandler, Four Centuries of Banking: as illustrated by the bankers, customers and staff associated with the constituent banks of Martins Bank Limited (Batsford 2 vols. 1964, 1968)
B Ritchie, We’re with the Woolwich 1847-1997: the story of the Woolwich Building Society (James & James 1997)
see also: J Orbell & A Turton, British Banking: a guide to historical records (Ashgate 2001)
Barclays’ history and archives web pages include:
Woolwich Equitable Building Society advert, 1945
summary histories of the Group including major acquisitions – Martins Bank and Woolwich Building Society
In the ArchivesGrid analysis, the <unitdate> field use is around 72% within the high-level (usually collection level) description. The Archives Hub does significantly better here, with an almost universal inclusion of dates at this level of description. Therefore, a date search is not likely to exclude any potentially relevant descriptions. This is important, as researchers are likely to want to restrict their searches by date. Our new system also allows sorting retrieved results by date. The only issue we have is where the dates are non-standard and cause the ordering to break down in some way. But we do have both displayed dates and normalised dates, to enable better machine processing of the data.
Collection Title
“for sorting and browsing…utility depends on the content of the element.”
Titles are always provided, but they are very varied. Setting aside lower-level descriptions, which are particularly problematic, titles may be more or less informative. We may introduce sorting by title, but the utility of this will be limited. It is unlikely that titles will ever be controlled to the extent that they have a level of consistency, but it would be fascinating to analyse titles within the context of the ways people search on the Web, and see if we can gauge the value of different approaches to creating titles. In other words, what is the best type of title in terms of attracting researchers’ attention, search engine optimisation, display within search engine results, etc?
Lower-level descriptions tend to have titles such as ‘Accounts’, ‘Diary’ or something more difficult to understand out of context such as ‘Pigs and boars’ or ‘The Moon Dragon’. It is clearly vital to maintain the relationship of these lower-level descriptions to their parent level entries, otherwise they often become largely meaningless. But this should be perfectly possible when working on the Web.
It is important to ensure that a researcher finding a lower-level description through a general search engine gets a meaningful result.
A search result within Google
The above result is from a search for ‘garrick theatre archives joanna lumley’ – the sort of search a researcher might carry out. Whilst the link is directly to a lower -level entry for a play at the Garrick Theatre, the heading is for the archive collection. This entry is still not ideal, as the lower-level heading should be present as well. But it gives a reasonable sense of what the researcher will get if they click on this link. It includes the <unitid> from the parent entry and the URL for the lower-level, with the first part of the <scopecontent> for the entry. It also includes the Archives Hub tag line, which could be considered superfluous to a search for Garrick Theatre archives! However, it does help to embed the idea of a service in the mind of the researcher – something they can use for their research.
Extent
“It would be useful to be able to sort by size of collection, however, this would require some level of confidence that the <extent> tag is both widely used and that the content of the tag would lends itself to sorting.”
This was an idea we had when working on our Linked Data output. We wanted to think about visualizations that would help researchers get a sense of the collections that are out there, where they are, how relevant they are, and so on. In theory the ‘extent’ could help with a weighting system, where we could think about a map-based visualization showing concentrations of archives about a person or subject. We could also potentially order results by size – from the largest archive to the smallest archive that matches a researchers’ search term. However, archivists do not have any kind of controlled vocabulary for ‘extent’. So, within the Archives Hub this field can contain anything from numbers of boxes and folders to length in linear metres, dimensions in cubic metres and items in terms of numbers of photographs, pamphlets and other formats. ISAD(G) doesn’t really help with this; the examples they give simply serve to show how varied the description of extent can be.
Genre
“Other examples of desired functionality include providing a means in the interface to limit a search to include only items that are in a certain genre (for example, photographs)”.
This is something that could potentially be useful to researchers, but archivists don’t tend to provide the necessary data. We would need descriptions to include the genre, using controlled vocabulary. If we had this we could potentially enable researchers to select types of materials they are interested in, or simply include a flag to show, e.g. where a collection includes photographs.
The problem with introducing a genre search is that you run the risk of excluding key descriptions, because the search will only include results where the description includes that data in the appropriate location. If the word ‘photograph’ is in the general description only then a specific genre search won’t find it. This means a large collection of photographs may be excluded from a search for photographs.
Subject
In the Bron/Proffitt/Washburn article <controlaccess> is present around 72% of the time. I was surprised that they did not choose to analyse tags within <controlaccess> as I think these ‘access points’ can play a very important role in archival descrpition. They use the presence of <controlaccess> as an indication of the presence of subjects, and make the point that “given differences in library and archival practices, we would expect control of form and genre terms to be relatively high, and control of names and subjects to be relatively low.”
On the Archives Hub, use of subjects is relatively high (as well as personal and corporate names) and use of form and genre is very low. However, it is true to say that we have strongly encouraged adding subject terms, and archivists don’t generally see this as integral to cataloguing (although some certainly do!), so we like to think that we are partly responsible for such a high use of subject terms.
Subject terms are needed because they (1) help to pull out significant subjects, often from collections that are very diverse, (2) enable identification of words such as ‘church’ and ‘carpenter’ (ie. they are subjects, not surnames), (3) allow researchers to continue searching across the Archives Hub by subject (subjects are all linked to the browse list) and therefore pull collections together by theme (4) enable advanced searching (which is substantially used on the Hub).
Names (personal and corporate)
In Bron/Proffitt/Washburn the <origination> tag is present 87% of the time. The analysis did not include the use of <persname> and <corpname> within <origination> to identify the type of originator. In the Archives Hub the originator is a required field, and is present 99%+ of the time. However, we made what I think is a mistake in not providing for the addition of personal or corporate name identification within <origination> via our EAD Editor (for creating descriptions) or by simply recommending it as best practice. This means that most of our originators cannot be distinguished as people or corporate bodies. In addition, we have a number where several names are within one <origination> tag and where terms such as ‘and others’, ‘unknown’ or ‘various’ are used. This type of practice is disadvantageous to machine processing. We are looking to rectify it now, but addressing something like this in retrospect is never easy to do. The ideal is that all names within origination are separately entered and identified as people or organisations.
We do also have names within <controlaccess>, and this brings the same advantages as for <subjects>, ensuring the names are properly structured, can be used for searching and for bringing together archives relating to any one individual or organisation.
Repository
“Use of this element falls into the promising complete category (99.46%: see Table 7). However, a variety of practice is in play, with the name of the repository being embellished with <subarea> and <address> tags nested within <repository>.”
On the Archives Hub repository is mandatory, but as yet we do not have a checking system whereby a description is rejected if it does not contain this field. We are working towards something like this, using scripts to check for key information to help ensure validity and consistency at least to a minimum standard. On one occasion we did take in a substantial number of descriptions from a repository that omitted the name of repository, which is not very useful for an aggregation service! However, one thing about <repository> is that it is easy to add because it is always the same entry. Or at least it should be….we did recently discovery that a number of repositories had entered their name in various ways over the years and this is something we needed to correct.
Scope and content, biographical history and abstract
It is notable that in the US <abstract> is widely used, whereas we don’t use it at all. It is intended as a very brief summary, whereas <scopecontent> can be of any length.
“For search, its worth noting that the semantics of these elements are different, and may result in unexpected and false “relevance””
One of the advantages of including <controlaccess> terms is to mitigate against this kind of false relevance, as a search for ‘mason’ as a person and ‘mason’ as a subject is possible through restricted field searching.
The Bron/Proffitt /Washburn analysis shows <bioghist> used 70% of the time. This is lower than the Archives Hub, where it is rare for this field not to be included. Archivists seem to have a natural inclination to provide a reasonably detailed biographical history, especially for a large collection focussed on one individual or organisation.
Digital Archival Objects
It is a shame that the analysis did not include instances of <dao>, but it is likely to be fairly low (in line with previous analysis by Wisser and Dean, which puts it lower than 10%). The Archives Hub currently includes around 1,200 instances of images or links to digital content. But what would be interesting is to see how this is growing over time and whether the trajectory indicates that in 5 years or so we will be able to provide researchers with routes into much of the Archives Hub content. However, it is worth bearing in mind that many archives are not digitised and are not likely to be digitised, so it is important for us not to raise expectations that links to digital content will become a matter of course.
The Future of Discovery
“In order to make EAD-encoded finding aids more well suited for use in discovery systems, the population of key elements will need to be moved closer to high or (ideally) complete.”
This is undoubtedly true, but I wonder whether the priority over and above completeness is consistency and controlled vocabulary where appropriate. There is an argument in favour of a shorter description, that may exclude certain information about a collection, but is well structured and easier to machine process. (Of course, completeness and consistency is the ideal!).
The article highlights geo-location as something that is emerging within discovery services. The Archives Hub is planning on promoting this as an option once we move to the revised EAD schema (which will allow for this to be included), but it is a question of whether archivists choose to include geographical co-ordinates in their catalogues. We may need to find ways to make this as easy as possible and to show the potential benefits of doing so.
In terms of the future, we need a different perspective on what EAD can and should be:
“In the early days of EAD the focus was largely on moving finding aids from typescript to SGML and XML. Even with much attention given over to the development of institutional and consortial best practice guidelines and requirements, much work was done by brute force and often with little attention given to (or funds allocated for) making the data fit to the purpose of discovery.”
However, I would argue that one of the problems is that archivists sometimes still think in terms of typescript finding aids; of a printed finding aid that is available within the search room, and then made available online….as if they are essentially the same thing and we can use the same approach with both. I think more needs to be done to promote, explain and discuss ‘next generation finding aids’. By working with Linked Data, I have gained a very different perspective on what is possible, challenging the traditional approach to hierarchical finding aids.
Maybe we need some ‘next generation discovery’ workshops and discussions – but in order to really broaden our horizons we will need to take heed of what is going on outside of our own domain. We can no longer consider archival practice in isolation from discovery in the most general sense because the complexity and scale of online discovery requires us to learn from others with expertise and understanding of digital technologies.
Explore Your Archive, http://www.exploreyourarchive.org, developed by The Archives and Records Association (UK and Ireland) and The National Archives, is the biggest ever public awareness campaign by the archives sector of the UK and Ireland.
From 16 November there will be hundreds of events and activities taking place in all kinds of archives. Those who work in archives will also be sharing some of their wonderful stories and amazing treasures. The public are being encouraged not just to visit an archive or explore archival collections online, but to understand more of the vital role which archives play in education, business, transparency and identity.
How the Hub fits in
The Archives Hub is a gateway to archives held at over 220 institutions and organisations across the UK.
A rich variety of content: The breadth of content on the Hub highlights how archives are integral to historical and cultural awareness. Our contributors include Universities, business archives, charities, local government, libraries, museums and cathedrals.
Here are just a few of the collections you can find:
The collection of records of Canterbury Cathedral includes material dating from the early Middle Ages right up to the present day. The material relates to the Cathedral’s estates and reflects the activities of the Dean and Chapter and its staff.
Launched in February 2006 and billing itself as a ‘theatre without walls’, the National Theatre of Scotland has no building of its own and operates within the existing infrastructure of Scottish theatre. Material is held at Glasgow University Library and includes programmes, press-cuttings, reviews and scripts.
With around one kilometre of material, the records consist of all the surviving historical paper records of the Royal Observatory. Collections include: papers of the Astronomers Royal and telescope construction projects, management and observations, including the William Herschel Telescope and Radcliffe Observatory.
One reel of microfilm comprising images of 23 original Gaelic manuscripts, relating to Ireland and to the activities of Irishmen at home and abroad, held at Queen’s University Belfast. It consists largely of fragments of both religious and secular verse, topographical poems and other tracts and tales dating mainly from the 18th and 19th centuries.
The Children’s Society Archive comprises the records created and managed by The Children’s Society (titled The Waifs and Strays Society from 1881 to 1946). The majority of the collections date from the organisation’s founding in 1881. This includes a large quantity of visual material in the form of photographs and publicity material, as well as some audio-visual material.
This collection comprises six scrapbooks, containing newspaper cuttings on the Barking and Dagenham Branch of Age Concern, relating to events, as well as issues affecting elderly people in the borough.
Thomas S Muir (1802-1888) worked for most of his life as a book-keeper in Edinburgh. All his spare time was devoted to his passion for early Scottish churches, visiting all the locations where ruins were to be found, including even the most inaccessible islands. The volume, ‘Ecclesiological notes on some of the islands of Scotland’, comprises detailed architectural descriptions, with line drawings, of features of churches and other ecclesiastical remains.
The States of Jersey collection includes the minutes, correspondence, reports and acts of the States of Jersey. Also, the minutes of the different Committee’s of the States including Agriculture, Education, Defence, Housing, Social Security, Finance, Harbours and Airports, Health and Social Services, Tourism, Home Affairs, Planning and Environment, Economic Development and Policy and Resources.
Africa 95 was founded in 1992 to initiate and organise a nationwide season of the arts of Africa to be held in the UK in the last quarter of 1995. Printed material, photographs, and slides of the work of artists from Algeria, Egypt, Ethiopia, Ghana, Ivory Coast, Kenya, Morocco, Nigeria, Senegal, South Africa, Sudan, Uganda,Tanzania, Tunisia, Zambia, Zimbabwe, and the USA.
The Fire Brigades Union (FBU) was founded in 1918 as the Firemen’s Trade Union. The union began its life as a body very much based around the London area but soon expanded to include provincial brigades. The collection includes: Executive Council minutes, annual accounts, subject files (including Sizewell Public Inquiry, 1980s) and the national strike, 1977.
The collection comprises a full series of indexed bound minute books (1899-1974) containing annual statements of accounts, and other specific reports. Also, maps and plans relate to specific elements of intended works such as the building of Ladybower Reservoir in Derbyshire.
The Lawrence Collection contains extensive materials by and about D.H. Lawrence, ranging in date from his childhood and including original manuscripts and his correspondence.
This collection contains river and lake data in rivers in Britain, and correspondence regarding flows, inflows, chemical analyses and chemical stratification. It also includes mud samples!
Diaries of Daniel Dougal, which detail his service as an army doctor on the Western Front during the First World War. Dougal rose to become Deputy Assistant Director of Medical Services, 34th Division of the British Army, and his diaries provide important information on the operation of Army medical services.
The Campaign for Nuclear Disarmament (CND) is a non party-political British organisation advocating the abolition of nuclear weapons worldwide. Includes papers relating to the CND’s constitution, minutes of National Council, National Executive Committee annual conference papers and papers relating to Aldermaston marches and other demonstrations.
These are selected descriptions: there’s much more to discover by exploring the Hub! And we’re adding more descriptions every week. If you’d like to add your descriptions to the Hub, now’s a great time! See Be part of something bigger for information on how we can help you expose your collections to a worldwide audience.
Also of interest:
Work in an archive and want to be involved in the Explore Your Archive campaign?
The recent Digital Humanities @ University of Manchester conference presented research and pondered issues surrounding digital humanities. I attended the morning of the conference, interested to understand more about the discipline and how archivists might interact with digital humanists, and consider ways of opening up their materials that might facilitate this new kind of approach.
Visualisation within digital humanities was presented in a keynote by Dr Massimo Riva, from Brown University. He talked about the importance of methodologies based on computation, whether the sources are analogue or digital, and how these techniques are becoming increasingly essential for humanities. He asked whether a picture is worth one million words, and presented some thought-provoking quotes relating to visualisation, such as a quote by John Berger: “The relation between what we see and what we know is never settled.” (John Berger, Ways of Seeing, 1972).
Riva talked about how visual projection is increasingly tied up with who we are and what we do. But is digital humanities translational or transformative? Are these tools useful for the pursuit of traditional scholarly goals, or do they herald a new paradigm? Does digital humanities imply that scholars are making things as they research, not just generating texts? Riva asked how we can combine close reading of individual artifacts and ‘distant reading’ of patterns across millions of artifacts. He posited that visualisation helps with issues of scale; making sense of huge amounts of data. It also helps cross boundaries of language and communication.
Riva talked about the fascinating Cave Writing at Brown University, a new kind of cognitive experience. It is a four-wall, immersive virtual reality device, a room of words. This led into his thoughts about data as a type of artifact and the nature of the archive.
“On the cusp of the twenty–first century…we speak of an ex–static archive, of an archive not assembled behind stone walls but suspended in a liquid element behind a luminous screen; the archive becomes a virtual repository of knowledge without visible limits, an archive in which the material now becomes immaterial.” This change “has altered in still unimaginable ways our relationship to the archive”. (Voss & Werner, 1999)
The Garibaldi panorama is a 276 feet long, a panorama that tells the story of Garibaldi, the Italian general and politician. It is fragile and cannot be directly consulted by scholars. So, the whole panorama was photographed in 91 digital images in 2007. The digital experience is clearly different to the physical experience. But the resulting digital panorama can be interacted with it many various ways and it is widely available via the website along with various tools to help researchers interpret the panorama. It is interesting to think about how much this is in itself a curated experience, and how much it is an experience that the user curates themselves. Maybe it is both. If it is curated, then it is not really the archivists who are curators, but those who have created the experience those with the ability to create such technical digital environments. It is also possible for students to create their own resources, and then for those resources to become part of the experience, such as an interactive timeline based on the panorama. So, students can enhance the metadata as a form of digital scholarship.
Riva showed an example of a collaborative environment where students can take parts of the panorama that interests them and explore it, finding links and connections and studying parts of the panorama along with relevant texts. It is fascinating as an archivist to see examples like this where the original archive remains the basis of the scholarly endeavour. The artifact is at a distance to the actual experience, but the researcher can analyse it to a very detailed level. It raises the whole debate around the importance of studying the original archive. As tools and environments become more and more sophisticated, it is possible to argue that the added value of a digital experience is very substantial, and for many researchers, preferable to handling the original.
Riva talked about the learning curve with the software. Scholars struggled to understand the full potential of it and what they could do and needed to invest time in this. But an important positive was that students could feedback to the programmers, in order to help them improve the environment.
We had short presentations on a diverse range of projects, all of which showed how digital humanities is helping to reveal history to us in many ways. Dr Guyda Armstrong made the point that library catalogues are more than they might seem – they are a part of cultural history. This is reflected in a bid for funding for a Digging into Data project, metaSCOPE, looking at bibliographical metadata as datamassive cultural history. The questions the project hopes to answer are many: how are different cultures expressed in the data? How do library collections data reflect the epistemic values, national and disciplinary cultures and artifacts of production and dissemination expressed in their creation? This project could help with mapping the history of publishing in space and time, as well as showing the history of one book over time.
We saw many examples of how visual work and digital humanities approaches can bring history to life and help with new understanding of many areas of research. I was interested to hear how the mapping of the Caribbean during the 18th century opened up the coastline to the slave traders, but the interior, which was not mapped in any detail, remained in many ways a free area, where the slave traders did not have control. The mapping had a direct influence on many people’s lives in very fundamental ways.
Another point that really stood out to me was the danger of numbers averaging out the human experience – a challenge with digital humanities approach, as, at the same time, numbers can give great insights into history. Maybe this is a very good reason why those who create tools and those who use them benefit from a shared understanding.
“All archaeological excavation is destruction”, so what actually lives on is the record you create, says Dr Stuart Campbell. Traditional monographs synthesize all the data. They represent what is created through the process of excavation. It is a very conventional approach. But things are changing and digital archiving creates new ways of working in the virtual world of archaeological data. Dr Campbell made the point that interpretation is often privileged over the data itself in traditional methods, but new approaches open up the data, allowing more narratives to be created. The process of data creation becomes apparent, and the approach scales up to allow querying that breaks out beyond the boundaries of archaeological sites. For example, he talked about looking at pattens on ancient pottery and plotting where the pottery comes from. New sophisticated tools allow different dimensions to be brought into the research. Links can now be created that bring various social dimensions to archeological discoveries, but the understanding of what these connections really represent is less well understood or theorised.
Seemingly a contrast to many of the projects, a project to recreate the Gaskell house in Manchester is more about the physical experience. People will be able to take books down from the shelves, sit down and read them. But actually there is a digital approach here too, as the intention is to add value to the experience by enabling visitors to leaf through digital copies of Gaskell’s works and find out more about the process of writing and publishing by showing different versions of the same stories, handwritten, with annotations, and published. It is enhancing the physical experience with a tactile experience through digital means.
To end the morning we had a cautionary tale about the vulnerability of Websites. A very impressive site, allowing users to browse in detail through an Arabic manuscript, is to be taken down, presumably because of changes in personnel or priorities at the hosting institution.The sustainability of the digital approach is in itself a huge topic, whether it be the data or the dissemination approaches.
On 24th October, the Archives Hub was delighted to host a meeting of our colleagues from Sweden here in Manchester. The visitors were archivists with a particular interest in business and industry, and so we were very happy that Nicholas Webb from Barclays’ Group Archive and Stacy Capner, Business Archives Development Officer for Wales, both agreed to come along and speak.
Jane Stevenson opened with a presentation on the UK archival landscape. A topic that sounded easy in theory, but in practice is somewhat broad in scope! However, we tried to give our colleagues an overview of the professional bodies, standards training and career opportunities and concerns and challenges that make up the UK archives scene.
Per-Ola Karlsson, Head of Archives at the Swedish Center for Business History gave a talk on his work with the Centre for Business Archives. It was a shame that more colleagues from the business sector couldn’t join us because it was fascinating to hear about this approach to managing business archives. Per-Ola informed us that the Centre is the world’s largest private archive. The basic model is to hold business archives centrally; the centre will take in any business archive, and includes some of the leading businesses in Sweden, such as Ericsson, H&M and Unilever.
Per-Ola gave us some context to the formation of the Centre. Originally the assumption was that companies should take responsibility for their own archives, but this changed during the 1960’s, when companies were ceasing to exist and the archives were under threat. It was interesting to hear that the Government waded in on the debate, pressing for a solution (but reluctant to stump up any funds!). Eventually regional business archives were established, and now the National Centre operates as a centre of expertise in business archives. Sweden has the most private business archives of any of the Nordic countries, and the contrast between the Swedish approach and Norwegian approach is marked, with Norway selecting companies’ archives, and Sweden encouraging all companies to deposit.
The pricing for the use of the Centre is by shelf metres. The depositor retains ownership and control, which in itself is a risk when the staff at the Centre invest so much time and effort in curating the collections. But they see their role as advocates and persuaders – they need to convince businesses that it makes good business sense to have an archive. It means that requests for access can be vetted by the company, but many archives are fully open for researchers. Per-Ola talked about his role – in many ways serving the companies first, because the essence of the work is to attract archives; this is what will make the centre successful as a research centre.
It seemed to be a really positive thing to have this kind of model in so far as it promotes the importance of business archives and ensures there is a centre for advocating the vital importance of these archives for future research. The UK does great work through the Business Archives Council, but we wonder what business archivists would think of this kind of model for the UK? A central store for business archives, and a central pool of expertise. It means that in Sweden, archivists working within a business are much less common.
Stacy took us through the landscape of Wales, as told through its archives of industry. Coal, steel, iron, lager production, nuclear power – they are all quite localised, and tied in with local history in Wales. In the 1960’s, with the decline of heavy industry, many archives ended up in local record offices, but collection was not systematic. There are no private business archives in Wales that are professionally managed.
Stacy pointed out that business archives are often more likely to be left uncatalogued – they are hard to deal with and understand, and more ‘attractive’ archives may take priority. Yet projects such as ‘Wales: Powering the World‘ show how business archives can be successfully used. One of the project’s outputs was a project by two Swansea University students encouraging others to use the archives (and especially business archives) to find research material.
We moved on to look at the archive at Barclays. Nick Webb gave us a thought-provoking talk that highlighted the role of an archive in a company that is struggling to regain its reputation. He gave very persuasive arguments around the vital role of an archive in providing transparency and, if not an objective view of history, at least a view that can be supported by documentary evidence. For instance, the archive shows Barclays’ true relationship to the slave trade, which is not as has often been portrayed. Whatever else the bank might be accused of, they had quite a strong Quaker history and campaigned against slavery. His lovely turn of phrase about archives being ‘a force against corporate amnesia’ really summed this up well. It was interesting to note how much the archive is used by employees – it really seemed that it has an important role to play and that this is properly recognised within the bank, especially since the team often put a monetary value on what they do! Nick has a great anecdote about a student who came into the archive to plough through archives about Barclays’ work in Libya. He declared that the archive was the best source on pre-Gaddaffi Libyan history that he had come across. A great example of the surprises that are hidden within collections.
We ended with Bethan Ruddock and Jane Stevenson talking a bit about ‘the online archivist’ and expanding on some of the challenges archivists face in the digital age.
Altogether we had a great day. It was a great opportunity to hear about how another country approaches the challenges of business archives, and for us it was also a means to get a better understanding of the landscape of business archives within the UK.




























![Diamond ring photo [by Ruby Ran – My Ring]](http://commons.wikimedia.org/wiki/File%3ADiamond_ring_photo_by_Ruby_Ran.jpg){kind=link}
{kind=link}
{kind=link}
![papaver in High Wood, [tinelot@pobox.com Tinelot Wittermans]](http://en.wikipedia.org/wiki/File:High_Wood_cemetery ,_France.jpg){kind=link}