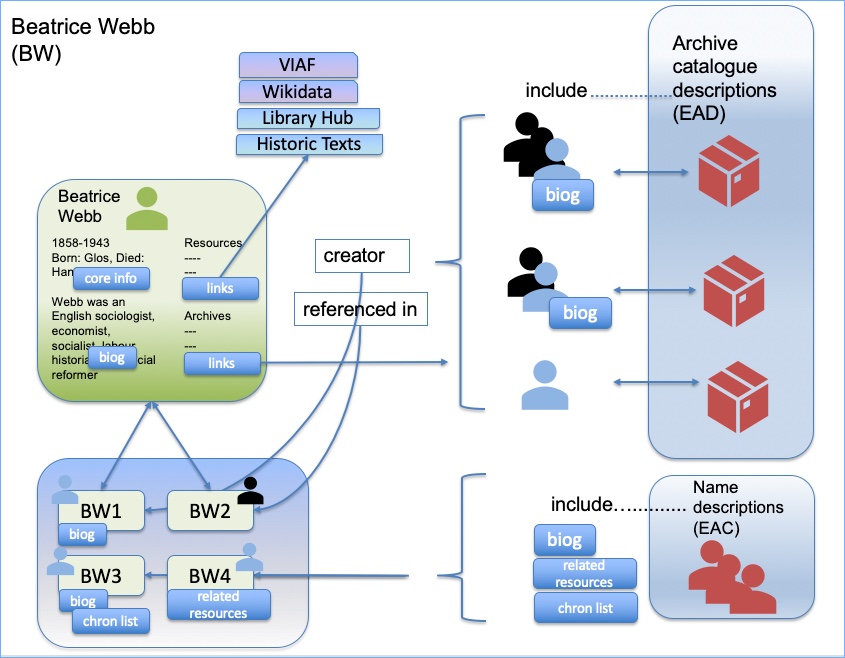
In the last Names post I wrote about the 4-step process that covers ‘matching and meaning’. Step 2 was ‘Structuring data’, which means implementing a process to structure the elements that form part of a name string.
Many names are not structured. But if we can process the data to create better structure, we have a much better chance of matching it to other entries.
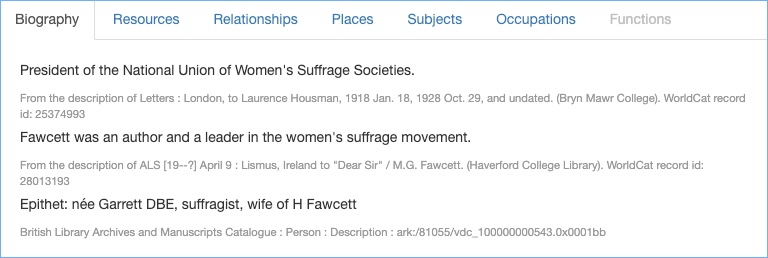
Here is a table showing some name entries around ‘J Watson’ (my examples are taken from real data, but sometimes tweaked a bit in order to cover different types of patterns – all the patterns will be found within the data).
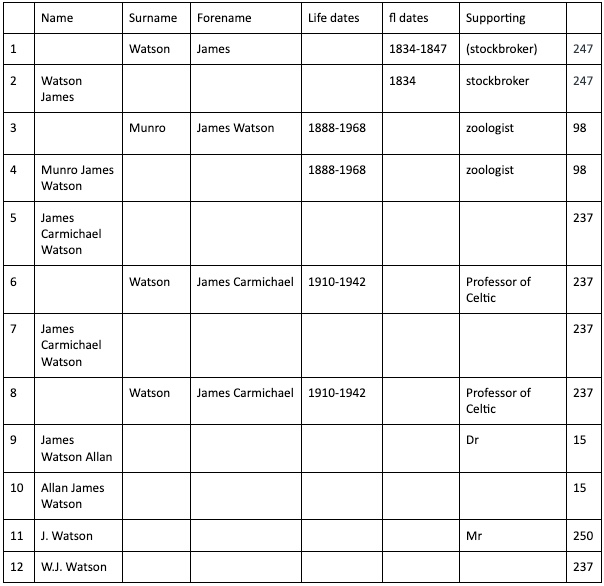
The elements have been put into columns, and this is the idea with our structuring process. Some names are still strings – we cannot always know which part is a surname and which part a forename; and some names do not have that kind of structure anyway. We hope to identify floruit dates, and categorise them as distinct from life dates. We don’t want to match ‘1888-1938’ with ‘fl 1888-1938’ (although we might want to see this as a potential match). We will aim do something similar with birth and death dates. We want to gather all the information that is not a name or a date as ‘supporting information’.
Once we have the structure, it is far more likely we can match the name, and also control our level of confidence about matching. Here is a shorter table based on some of the entries from above:
| name | surname | forename | dates | fl dates | info |
| Watson | James | 1834-1847 | stockbroker | ||
| Watson James | 1834- | stockbroker | |||
| Watson | J | b 1834 | Mr | ||
| James Watson | 1840-1847 |
You can see that two of the names are simply name strings. We may not be able to identify a surname and forename in ‘James Watson’ or ‘Watson James’. With the structure that we have imposed, it is possible to write a name matching process that provides a match between the first and second entries in the above table, because we can say with some confidence that a name that includes ‘James Watson’ and that has the birth date of ‘1834’ and the additional information ‘stockbroker’ refers to the same person. We might say this is a ‘definite’ match, or a ‘probable’ match. The third entry could be a ‘possible’ match, as it includes ‘Watson’ and ‘J’ with the same birth date of 1834. If the fourth entry had ‘stockbroker’, for example, then we might consider a possible match, but as things stand, it would not be a match.
It is very important that the interface we develop indicates to end users that we are matching name strings. There is a distinction between matching name strings and simply stating that X and Y are the same person. This will help us with introducing the idea of likely, probable and possible matches.
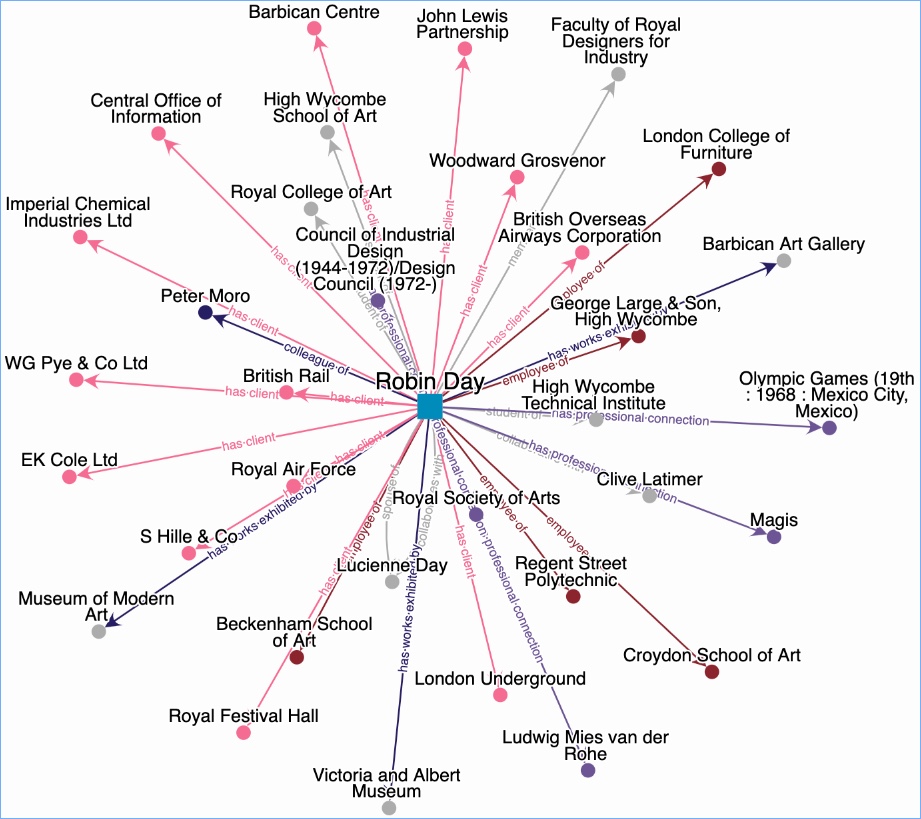
This structuring work is absolutely at the heart of creating a name interface, and enabling researchers to look up ‘James Watson’ and then potentially go in many different directions through the connections, finding ways that archives may be related. But it is really challenging. We will not ‘get it right’. Even if we had really substantial resources and time, we could not make it perfect. Archivists, as information professionals, are keen on ‘getting it right’, which is usually a good thing; but pulling together information using names created over decades, by thousands of cataloguers, in different systems, without a clear standard to work to….it ain’t ever going to be perfect. The key question is, whether this will substantially enhance the researcher experience and allow new connections to be made. And whether it will enable us to create connections outside of the archives domain. We have to have a change of mindset to accept that it is not perfect, but it is still hugely beneficial to research.
Just to emphasise the variation in data that we have, here are some EAD names, given as they are structured. They are all fine displayed within a description, suitable for a human reader, but they create challenges in terms of name matching. When you look at these, you have to think of the structure and semantics – essentially, how can we write an algorithm that allows us to truly identify the person (or that they are not a person!):
<persname>Barron, Lilias Mary Watson (b1912 : science graduate : University of Glasgow, Scotland)</persname>
<origination label=”Creator: “><persname role=”author”>Name of Author: various </persname></origination>
<persname source=”nra”>
<emph altrender=”surname”>Blore</emph>
<emph altrender=”forename”>Edward</emph>
<emph altrender=”dates”>1787-1879</emph>
<emph altrender=”epithet”>Architect Artist Antiquary</emph>
</persname>
<origination>Gerald and Joy Finzi</origination>
<origination>Walls Family – Tom Kirby Walls and Tom Kenneth Walls</origination>
<origination>National Union of Railwaymen; Associated Society of Locomotive Engineers and Firemen; National Busworkers’ Association.</origination>
<origination>
<persname authfilenumber=”https://viaf.org/viaf/61775126″ role=”creator” rules=”ncarules” source=”viaf”>
<emph altrender=”surname”>actor</emph>
<emph altrender=”forename”>dramatist and criticJohn Whiting English</emph>
</persname>
The last one was actually taken directly from VIAF and imported into the Archives Hub, which is, in principle, a really good way to create a structured name. Unfortunately, the process of pulling it into the Hub using the VIAF APE did not go quite according to plan. VIAF has just the same challenges as we do – there will be structural mistakes. However, it has the VIAF ID, so funnily enough, it is easier to match than many other names.
Many of the above examples are names added as archival creator names (‘origination’). Unfortunately, there has been a tendency for cataloguers to add creator names in a very unstructured way. The old Archives Hub Editor used to encourage this, and most archival systems have a free text field for name of creator. (Now, our Editor structures the creator name and adds it as an index term – so they are both identical).
We are currently looking at the challenge of matching origination name with the index term within the same description. That may sound like an easy task, but very often they are really quite different. For example, for the name of creator you may get:
<origination>Name of Authors: various but include Reverend<persname role=”author”>Thomas Frognall Dibdin</persname>,<persname role=”author”>Richard Bentley</persname>,<persname role=”author”>Philip Bliss </persname>and<persname role=”author”>Frederick James Furnivall</persname></origination>
This is nicely structured, so that it is easy to see that they are separate names, although the lack of life dates makes unique identification more difficult. If these individual names are also added as index terms, then we want to create just one entry for e.g. ‘Thomas Frognall Dibdin’ – we don’t want two entries for the one name (taken from the ‘origination’ and the ‘controlaccess’ index area) that both represent the same archive collection.
A common pattern is something like:
<origination label=”name of creator:”>Frances Dennis</origination>
With an index term of:
<persname rules=”ncarules”><emph altrender=”surname”>Dennis</emph><emph altrender=”forename”>Frances Mary</emph><emph altrender=”dates”>b 1874</emph><emph altrender=”epithet”>missionary</emph></persname>
‘Frances Dennis’ as a name string is very likely to be a match with ‘Frances Mary Dennis b1847 missionary’ when it is within the same collection. If these two entries were in different descriptions, we would not match them.
Our pre-match structuring will go a long way to increasing the number of matches, and hence the intellectual bringing together of knowledge through names. Matching creator name and index term name will reduce the amount of duplication. The framework will be tweakable, so that we can constantly review and improve.