Municipal Archive of Girona, Thursday, April 27, 2023
Yesterday I checked out some of the ‘Artificial Intelligence and Archives Seminar‘ hosted by the Municipal Archive of Girona “within the framework of the Faber-Llull Residency (Olot, Catalonia) and the project InterPARES Trust AI of the University of British Columbia (Vancouver, Canada), and with the collaboration of the Society of Catalan Archivists“. There were some useful things discussed in this still quite new area of AI, so thought I’d share my notes.
Identify specific AI technologies that can address critical records and archives challenges
Determine the benefits and risks of using AI technologies on records and archives
Ensure that archival concepts and principles inform the development of responsible AI
Validate outcomes from Objective 3 through case studies and demonstrations
Muhammad focussed on trustworthiness as an issue for Archives. They are looking at using AI to assess and verify the authenticity of Archives through time. The essential research question: Can we develop artificial intelligence for carrying out competently and efficiently all records and archives functions while respecting the nature and ensuring the continuing trustworthiness of the record.
He noted that a fundamental difference between analog and digital records is the fact that analogue materials can be proven and verified on face value and rarely need extrinsic evidence. However for digital materials, extrinsic elements such as metadata are needed. They rely on ‘circumstantial’ evidence such as the integrity of the hosting system as well as the politics, procedures and technology surrounding the digital record.
Muhammad suggests that off-the-shelf tools are not well suited to archives, so within the Archives profession we will have to develop the systems ourselves. We are the only ones who know what to do because we are the professionals. Developers need to talk to archives professionals to find out what they want and design appropriate AI tools for them. The tools need to respect the trustworthiness of the records. The project is looking to influence the development of responsible tools.
The project looks to provide a wealth of tools and code. A very important aspect of the project is training the community. Muhammad suggested that the Archives profession will have to do a great deal of training to engage with AI tools and its possibilities.
Linking AI to Archives and Records, Peter Sullivan
The aim of the talk was to look at combining archival concepts and principles with AI. Peter used the lens of Diplomatic to consider AI solutions and how AI may interact with different components of the record including the context, act, persons, procedure, form and archival bond. Which parts of the archival record are impacted by AI and how does this inform the design of AI tools that respect diplomatic theory?
The most important component is the ‘archival bond’ which covers how aspects of records are related to each other. AI may be poor at looking at records in context of other records, and may not be able to respect the archival bond. Also, AI may not respect the context of the creation of the records and may not be aware of different levels of appraisal used.
AI may be helpful where there are different variations of names and fuzzy matching can be used to reconcile names. This aligns with the Archives Hub Names project. Dealing with records in aggregate may be somewhere AI is able to help, using topic modelling and clustering techniques. This is a use case we have identified ourselves and something we are looking at with the Archives Hub Labs Project. Finally he mentioned the interesting question of how we will archive the artefacts of AI developments themselves.
Model for an AI-Assisted Digitisation Project, Peter Sullivan
Peter talked about how AI is being used to help with the archiving of audio recordings, providing AI generated metadata enrichment. He noted this is very time-consuming to do by hand. Different types of recordings create very different challenges to AI to analyse . For UNESCO audio they are using four models, one for language translation and three for text extraction and text summarisation.
AI and Archives: Basic Requirements, Pilar Campos and Eloi Puertas
The project is aiming to provide a resource for archive professionals to assess AI solutions to help guide decision-making and create recommendations. They will provide a check list to assess AI tool performance. The rationale behind this is that there is a huge amount of interest and concern regarding AI, but a scarcity of implementation examples, along with a lack of knowledge of AI solutions for the professionals in the archives domain. There is also a degree of mistrust of the results of AI.
The expected results of the project are to provide AI knowledge in the archive domain and a list of potential risks for archivists. A SWOT analysis about AI from the Archives viewpoint will be provided, along with an assessment of the balance between our expectations of risk.
Automated Transcription: Palaeography and AI, Thiara Alves and Leonardo Fontes
The talk was essentially about using AI for automated transcription. The speakers talked about using Transkribus for transcription of text from images of documents. They found that most algorithms weren’t good at detecting old versions of Portuguese and Spanish words. The speakers felt that the context provided by the archivist was necessary for the transcribers transcriptions to be useful.
First Steps and Main Expectations from CRDI’s Experience of AI, David Inglésias
David talked about a project looking at being able to search images that haven’t been catalogued, so they don’t have metadata unless it is created by using AI. This ability is very useful for a photographic archive. They work with the Europeana Kaleidoscope project to attempt to provide archival context for images.
AI also allows for innovative new approaches to presenting photographs in addition to the standard historical ways of doing so. AI can be used for clustering photos that appear to be similar or related in someway. This could be something that the Archives Hub could look at also.
I imagine many of you have tried asking ChatGPT questions like these, but we thought it was worth providing this blog, for those who haven’t tried it out. For anyone who has managed to avoid the headlines around this technology, ChatGPT is an artificial intelligence chatbot developed by OpenAI and released in November 2022.
First of all, we wanted to try a question that focussed on using one archive, so we asked:
Can you give me advice on how to write a dissertation on Stanley Kubrick using primary sources or archives?
ChatGPT answered:
Certainly, here are some tips for writing a dissertation on Stanley Kubrick using primary sources or archives:
Choose a research question: The first step in writing a dissertation is to identify a research question that you want to explore. This could be anything from analyzing Kubrick’s use of color in his films to examining his working methods and creative process. Make sure that your research question is focused enough to be manageable within the scope of your dissertation.
Identify relevant primary sources and archives: Once you have a research question, you need to identify primary sources and archives that are relevant to your topic. This could include Kubrick’s personal papers, scripts, storyboards, correspondence, and production notes. You can also look for archives and collections related to Kubrick’s collaborators and contemporaries, such as other film directors, writers, or actors.
Conduct a literature review: Before diving into primary sources and archives, conduct a thorough literature review to see what has already been published on your topic. This will help you identify any gaps in the existing research and refine your research question further. It will also give you a sense of the debates and issues within the field that your dissertation will need to address.
Plan your research visits: Before visiting archives, you need to plan ahead and make sure that you have enough time to access and review the materials you need. Some archives have strict access requirements or limited opening hours, so check this in advance. Make a list of the specific documents or materials you need to examine, and plan your research visits accordingly.
Analyze and evaluate primary sources: Once you have access to primary sources, you will need to analyze and evaluate the materials carefully. Make notes of important details, such as dates, locations, and people involved. Look for patterns, themes, and connections in the materials, and identify any contradictions or inconsistencies. Keep in mind the broader research question you are trying to answer, and look for evidence that can support your argument.
Write your dissertation: Once you have reviewed and analyzed your primary sources, you can start writing your dissertation. Make sure to frame your analysis within the broader context of existing scholarship, and use primary sources to support your arguments and interpretations. Use quotations and examples from primary sources to illustrate your points and make your argument more convincing.
Writing a dissertation on Stanley Kubrick using primary sources and archives can be a rewarding and challenging task. Make sure to plan ahead, conduct thorough research, and use primary sources effectively to support your arguments and interpretations.
*****
We then wanted to see how well ChatGPT would summarise the role and value of Archives Hub, so we asked:
How do I use Archives Hub to help with my research?
ChatGPT answered:
The Archives Hub can be a valuable resource for researchers who are looking to explore archival collections held in institutions across the UK. Here are some tips on how to use Archives Hub to help with your research:
Search the Archives Hub database: Start by using the search bar on the Archives Hub homepage to search for keywords, names, or locations that are relevant to your research topic. This will bring up a list of archives and collections that match your search terms. You can then click on each archive or collection to view more detailed information, including a description of the materials held, contact information for the holding institution, and links to related collections.
Refine your search: You can refine your search results using the menus on the left-hand side of the page. These menus allow you to narrow your search by institution, keyword, date range, or subject. Use these filters to focus your search on the most relevant materials.
Contact the holding institution: Once you have identified an archive or collection that seems relevant to your research, contact the holding institution to confirm the availability of the materials and to arrange a research visit if necessary. The contact information for each institution is listed on the Archives Hub website.
Plan your visit: Before visiting an archive, make sure to plan ahead and think about what materials you want to examine. Familiarize yourself with the archive’s policies on access and handling of materials, and bring any necessary equipment, such as a camera or laptop. Make sure to take detailed notes during your visit, as well as copies or photographs of any relevant documents or materials.
Follow ethical guidelines: When conducting research in archives, it is important to follow ethical guidelines and practices. This means properly citing your sources, respecting the privacy and confidentiality of individuals mentioned in archival materials, and obtaining permission to use any copyrighted materials. This will help to maintain the trust and cooperation of archival repositories and their staff.
By using the Archives Hub to identify collections and institutions that are relevant to your research, you can gain access to a vast array of archival materials held across the UK. Be sure to plan ahead, follow ethical guidelines, and take detailed notes during your research visits to make the most of these valuable resources.
*****
Both answers are very convincing and it is hard to argue that we would have done better if we had written them ourselves, though we might want to add more information to what is there. The guide for using the Archives Hub seems to utilise text from different parts of our website, including our Guide for Beginners, access information and search help. But the text is not lifted directly – it is far more sophisticated than that. There are many examples of text that does not echo anything we have said on our website and I can’t find the text elsewhere. For example, ChatGPT refers to possible dissertation subjects for Kubrick: ‘analyzing Kubrick’s use of color in his films to examining his working methods and creative process’. There are sentences that widen the scope, for example: ‘Make sure to frame your analysis within the broader context of existing scholarship, and use primary sources to support your arguments and interpretations.’ There are sentiments that I don’t recall seeing stated in quite the same way that ChatGPT has done, for example: ‘This means properly citing your sources, respecting the privacy and confidentiality of individuals mentioned in archival materials, and obtaining permission to use any copyrighted materials. This will help to maintain the trust and cooperation of archival repositories and their staff.’
It is easy to see why ChatGPT is seen as a means to write effectively. Maybe there are questions around what is left out of the above answers, but I would certainly be happy to use them as a basis for our own guidelines.
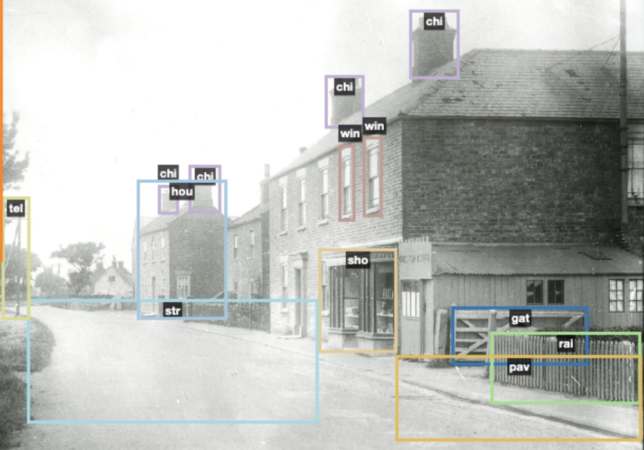
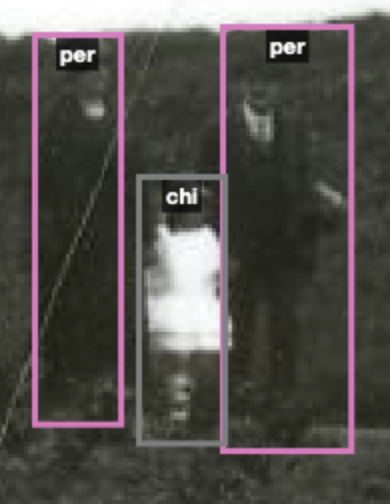
In this post I will go through the steps we took to create a human labelled dataset (i.e. naming objects within images), applying the labels to bounding boxes (showing where the objects are in the image) in order to identify objects and train an ML model. Note that the other approach, and one we will talk about in another post, is to simply let a pre-trained tool do the work of labelling without any human intervention. But we thought that it would be worthwhile to try the human labelling out before seeing what the out-of-the-box results are.
I used the photographs in the Claude William Jamson archive, kindly provided by Hull University Archives. This is a collection with a variety of content that lends itself to this kind of experiment.
An image from the Jamson archive
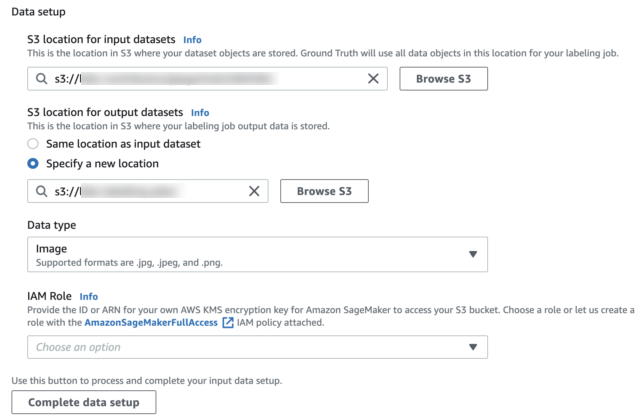
I used Amazon SageMaker for this work. In SageMaker you can set up a labelling job using the Ground Truth service, by giving the location of the source material – in this case, the folder containing the Jamson photographs. Images have to be jpg, or png, so if you have tif images, for example, they have to be converted. You give the job a name and provide the location of the source material (in our case an S3 bucket, which is the Amazon Simple Storage Service).
Location and output information are added – I have specified that we are working with images.
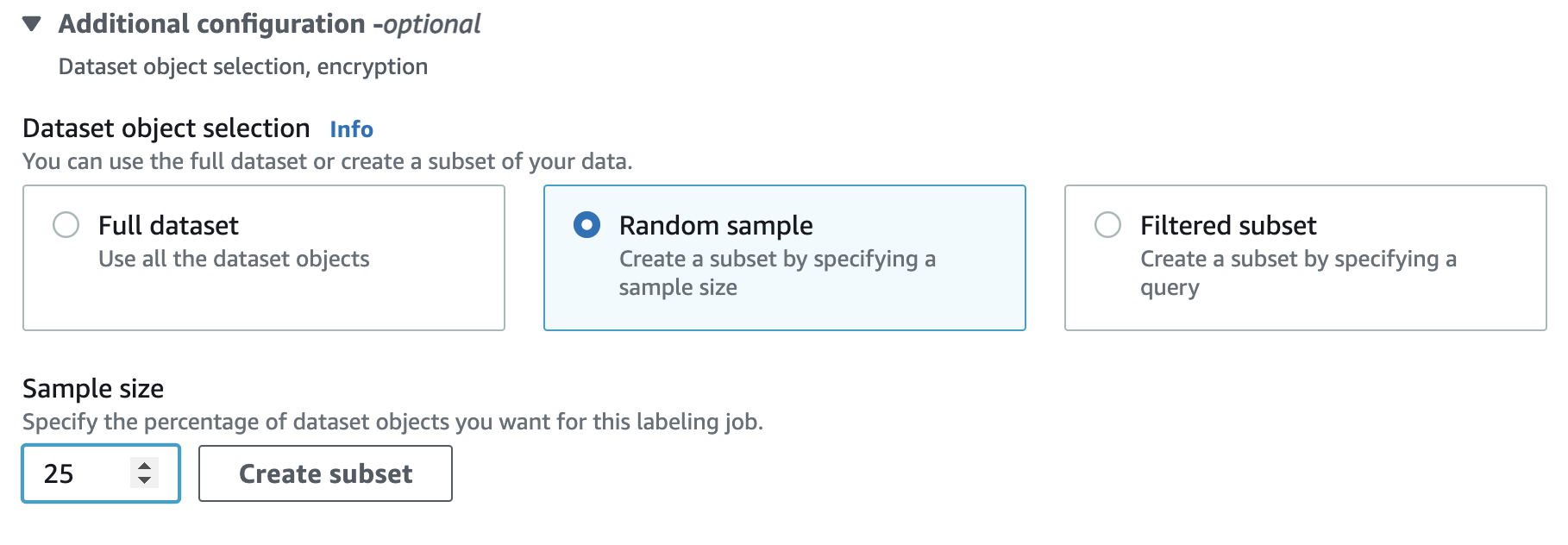
I then decide on my approach. I trained the algorithm with a random sample of images from this collection. This is because I wanted this sample to be a subset of the full Jamson Archive dataset of images we are working with. We can then use the ML model created from the subset to make object detection predictions for the rest of the dataset.
Random sample is selected, and I can also specify the size of the sample, e.g. 25%.
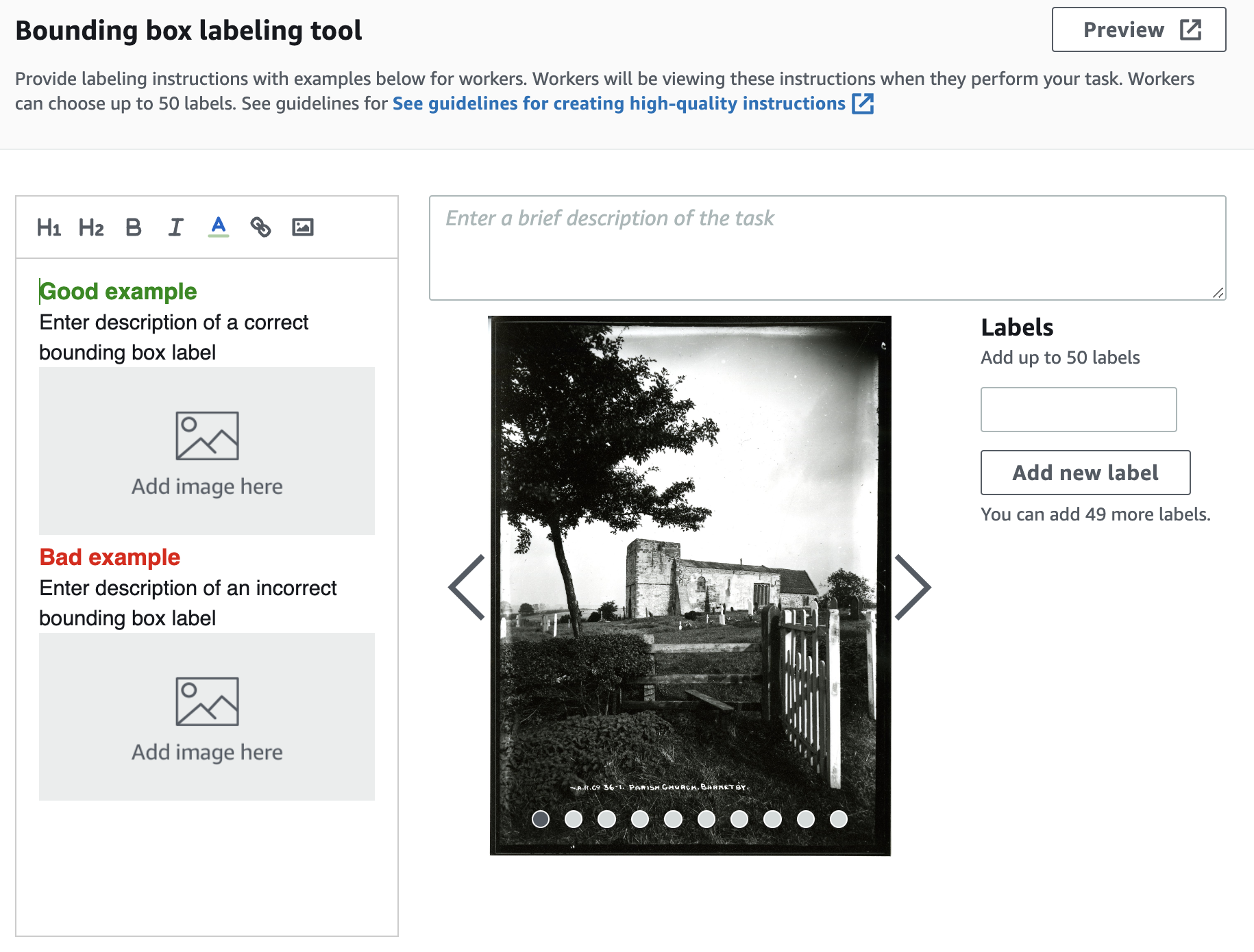
Once I had these settings completed, I started to create the labels for the ‘Ground Truth’ job. You have to provide the list of labels first of all from which you will select individual labels for each image. You cannot create the labels as you go. This immediately seemed like a big constraint to me.
Interface for adding labels, and a description of the task
I went through the photographs and decided upon the labels – you can only add up to 50 labels. It is probably worth noting here that ‘label bias’ is a known issue within machine learning. This is where the set of labelled data is not fully representative of the entirety of potential labels, and so it can create bias. This might be something we come back to, in order to think about the implications.
Creating a list of labels that I can then apply to each individual image
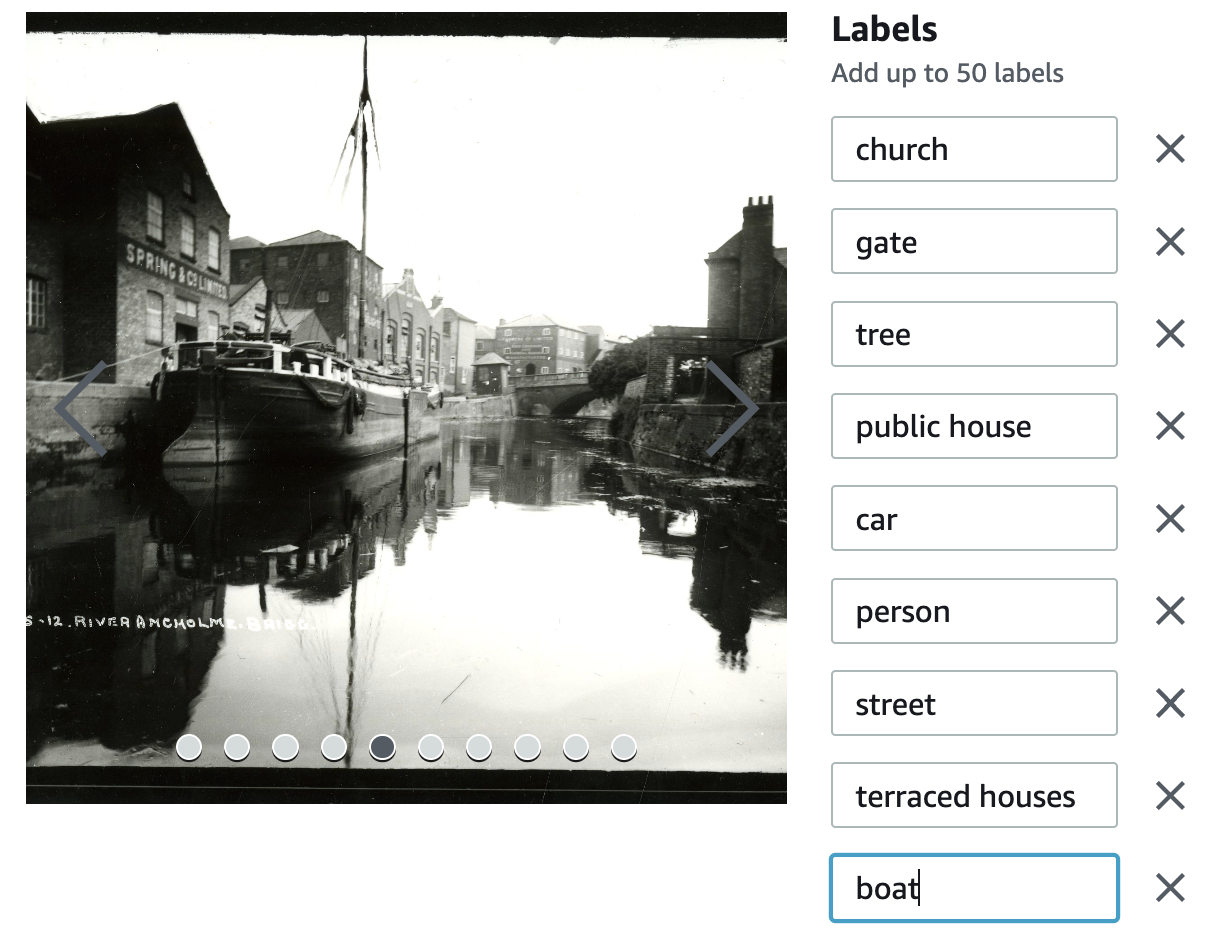
I chose to add some fairly obvious labels, such as boat or church. But I also wanted to try adding labels for features that are often not described in the metadata for an image, but nonetheless might be of interest to researchers, so I added things like terraced house, telegraph pole, hat and tree, for example.
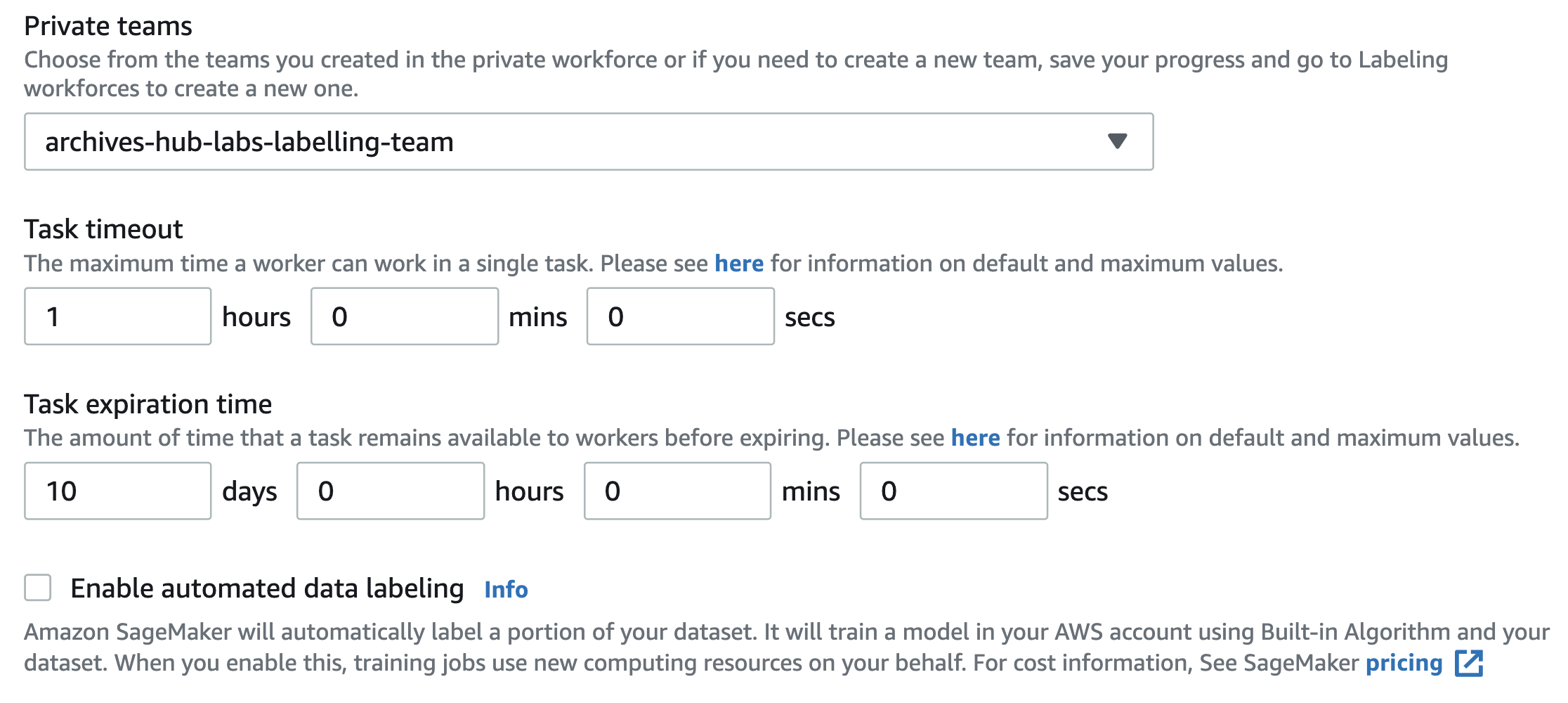
Once you have the labels, there are some other options. You can assign to a labelling team, and make the task time bound, which might be useful for thinking about the resources involved in doing a job like this. You can also ask for automated data labelling, which does add to the cost, so it is worth considering this when deciding on your settings. The automated labelling uses ML to learn from the human labelling. As the task will be assigned to a work team, you need to ensure that you have the people you want in the team already added to Ground Truth.
Confirming the team and the task timeout
Those assigned to the labelling job will receive an email confirming this and giving a link to access to the labelling job.
Workers assigned to the job can now start to work to create the bounding boxes and add the labels
You can now begin the job of identifying objects and applying labels.
The interface for adding labels to images
First up I have a photograph showing rowing boats. I didn’t add the label ‘rowing boat’ as I didn’t go through every single photograph to find all the objects that I might want to label, so not a good start! ‘Boat’ will have to do. As stated above, I had to work with the labels that I created, I can’t add more labels at this stage.
I added as many labels as I could to each photograph, which was a fairly time intensive exercise. For example, in the image below I added not only boat and person but also hat and chimney. I also added water, which could be optimistic, as it is not really an object that is bound within a box, and it is rather difficult to identify in many cases, but it’s worth a try.
Adding labels using bounding boxes
I can zoom in and out and play with exposure and contrast settings to help me identify objects.
Bounding boxes with labels
Here is another example where I experimented with some labels that seem quite ambitious – I tried shopfront and pavement, for example, though it is hard to classify a shop from another house front, and it is hard to pin-point a pavement.
The more I went through the images, drawing bounding boxes and adding labels, the more I could see the challenges and wondered how the out-of-the-box ML tools would fare identifying these things. My aim in doing the labelling work was partly to get my head into that space of identification, and what the characteristics are of various objects (especially objects in the historic images that are common in archive collections). But my aim was also to train the model to improve accuracy. For an object like a chimney, this labelling exercise looked like it might be fruitful. A chimney has certain characteristics and giving the algorithm lots of examples seems like it will improve the model and thus identify more chimneys. But giving the algorithm examples of shop fronts is harder to predict. If you try to identify the characteristics, it is often a bay window and you can see items displayed in it. It will usually have a sign above, though that is indistinct in many of these pictures. It seems very different training the model on clear, full view images of shops, as opposed to the reality of many photographs, where they are just part of the whole scene, and you get a partial view.
There were certainly some features I really wanted to label as I went along. Not being able to do this seemed to be a major shortcoming of the tool. For example, I thought flags might be good – something that has quite defined characteristics – and I might have added some more architectural features such as dome and statue, and even just building (I had house, terraced house, shop and pub). Having said that, I assume that identifying common features like buildings and people will work well out-of-the-box.
Running a labelling job is a very interesting form of classification. You have to decide how thorough you are going to be. It is more labour intensive than simply providing a description like ‘view of a street’ or ‘war memorial’. I found it elucidating as I felt that I was looking at images in a different way and thinking about how amazing the brain is to be able to pick out a rather blurred cart or a van or a bicycle with a trailer, or whatever it might be, and how we have all these classifications in our head. It took more time than it might have done because I was thinking about this project, and about writing blog posts! But, if you invest time in training a model well, then it may be able to add labels to unlabelled photographs, and thus save time down the line. So, investing time at this point could reap real rewards.
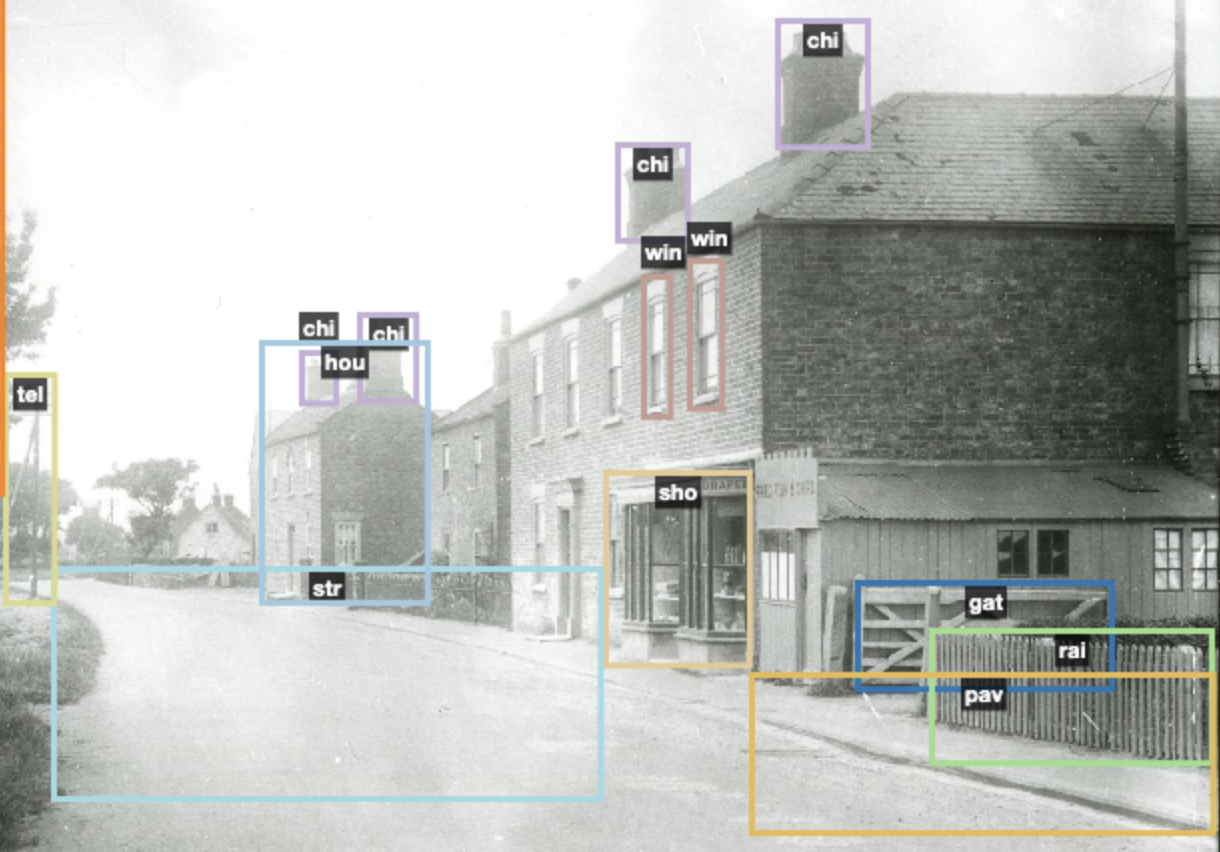
Part of a photograph with labels added
In the above example, I’ve outlined an object that i’ve identified as a telegraph pole. One question I had is whether I am are right in all of my identifications, and I’m sure there will be times when things will be wrongly identified. But this is certainly the type of feature that isn’t normally described within an image, and there must be enthusiasts for telegraph poles out there! (Well, maybe more likely historians looking at communications or the history of the telephone). It also helps to provide examples from different periods of history, so that the algorithm learns more about the object. I’ve added a label for a cart and a van in this photo. These are not all that clear within the image, but maybe by labelling less distinct features, I will help with future automated identification in archival images.
I’ve added hat as a label, but it strikes me that my boxes also highlight heads or faces in many cases, as the people in these photos are small, and it is hard to distinguish hat from head. I also suspect that the algorithm might be quite good with hats, though I don’t yet know for sure.
person and child labels
I used ‘person’ as a label, and also ‘child’, and I tended not to use ‘person’ for ‘child’, which is obviously incorrect, but I thought that it made more sense to train the algorithm to identify children, as person is probably going to work quite well. But again, I imagine that person identification is going to be quite successful without my extra work – though identifying a child is a rather more challenging task. In the end, it may be that there is no real point in doing any work identifying people as that work has probably been done with millions of images, so adding my hundred odd is hardly going to matter!
I had church as a label, and then used it for anything that looked like a church, so that included Beverly Minster, for example. I couldn’t guarantee that every building I labelled as a church is a church, and I didn’t have more nuanced labels. I didn’t have church interior as a label, so I did wonder whether labelling the interior with the same label as the exterior would not be ideal.
I was interested in whether pubs and inns can be identified. Like shops, they are easy for us to identify, but it is not easy to define them for a machine.
Green Dragon at Welton
A pub is usually a larger building (but not always) with a sign on the facade (but not always) and maybe a hanging sign. But that could be said for a shop as well. It is the details such as the shape of the sign that help a human eye distinguish it. Even a lantern hanging over the door, or several people hanging around outside! In many of the photos the pub is indistinct, and I wondered whether it is better to identify it as a pub, or whether that could be misleading.
I found that things like street lamps and telegraph poles seemed to work well, as they have clear characteristics. I wanted to try to identify more indistinct things like street and pavement, and I added these labels in order to see if they yield any useful results.
I chose to label 10% of the images. That was 109 in total, and it took a few hours. I think if I did it again I would aim to label about 50 for an experiment like this. But then the more labels you provide, the more likely you will get results.
The next step will be to compare the output using the Rekognition out of the box service with one trained using these labels. I’m very interested to see how the two compare! We are very aware that we are using a very small labelled dataset for training, but we are using the transfer learning approach that builds upon existing models, so we are hopeful we may see some improvement in label predications. We are also working on adding these labels to our front end interface and thinking about how they might enhance discoverability.
Thanks to Adrian Stevenson, one of the Hub Labs team, who took me through the technical processes outlined in this post.
There are many ways of utilising the International Image Interoperability framework (IIIF) in order to deliver high-quality, attributed digital objects online at scale. One of the exploratory areas focused on in Images and Machine Learning – a project which is part of Archives Hub Labs – is how to display the context of the archive hierarchy using IIIF alongside the digital media.
Two of the objectives for this project are:
to explore IIIF Manifest and IIIF Collection creation from archive descriptions.
to test IIIF viewers in the context of showing the structure of archival material whilst viewing the digitised collections.
We have been experimenting with two types of resource from the IIIF Presentation API. The IIIF Manifest added into the Mirador viewer on the collection page contains just the images, in order to easily access these through the viewer. This is in contrast to a IIIF Collection, which we have been experimenting with. The IIIF Collection includes not only the images from a collection but also metadata and item structure within the IIIF resource. It is defined as a set of manifests (or ‘child’ collections) that communicate hierarchy or gather related things (for example, a set of boxes that each have folders within them, and photographs within those folders). We have been testing whether this has the potential to represent the hierarchy of an archival structure within the IIIF structure.
Creating a User Interface
Since joining the Archives Hub team, one of the areas I’ve been involved in is building a User Interface for this project that allows us to test out the different ways in which we can display the IIIF Images, Manifests and Collections using the IIIF Image API and the IIIF Presentation API. Below I will share some screenshots from my progress and talk about my process when building this User Interface.
The homepage for the UI showing the list of contributors for this project.
The collections from all of our contributors that are being displayed within the UI using IIIF manifests and collections.
This web application is currently a prototype and further development will be happening in the future. The programming language I am using is Typescript. I began by creating a Next.js React application and I am also using Tailwind CSS for styling. My first task was to use the Mirador viewer to display IIIF Collections and Manifests, so I installed the mirador package into the codebase. I created dynamic pages for every contributor to display their collections.
This is the contributor page for the University of Brighton Design Archives.
I also created dynamic collection pages for each collection. Included on the left-hand side of a collection page is the archives hub record link and the metadata about the collection taken from the archival EAD data – these sections displaying the metadata can be extended or hidden. The right-hand side of a collection page features aMirador viewer. A simple IIIF Manifest has been added for all of the images in each collection. This Manifest is used to help quickly navigate through and browse the images in the collection.
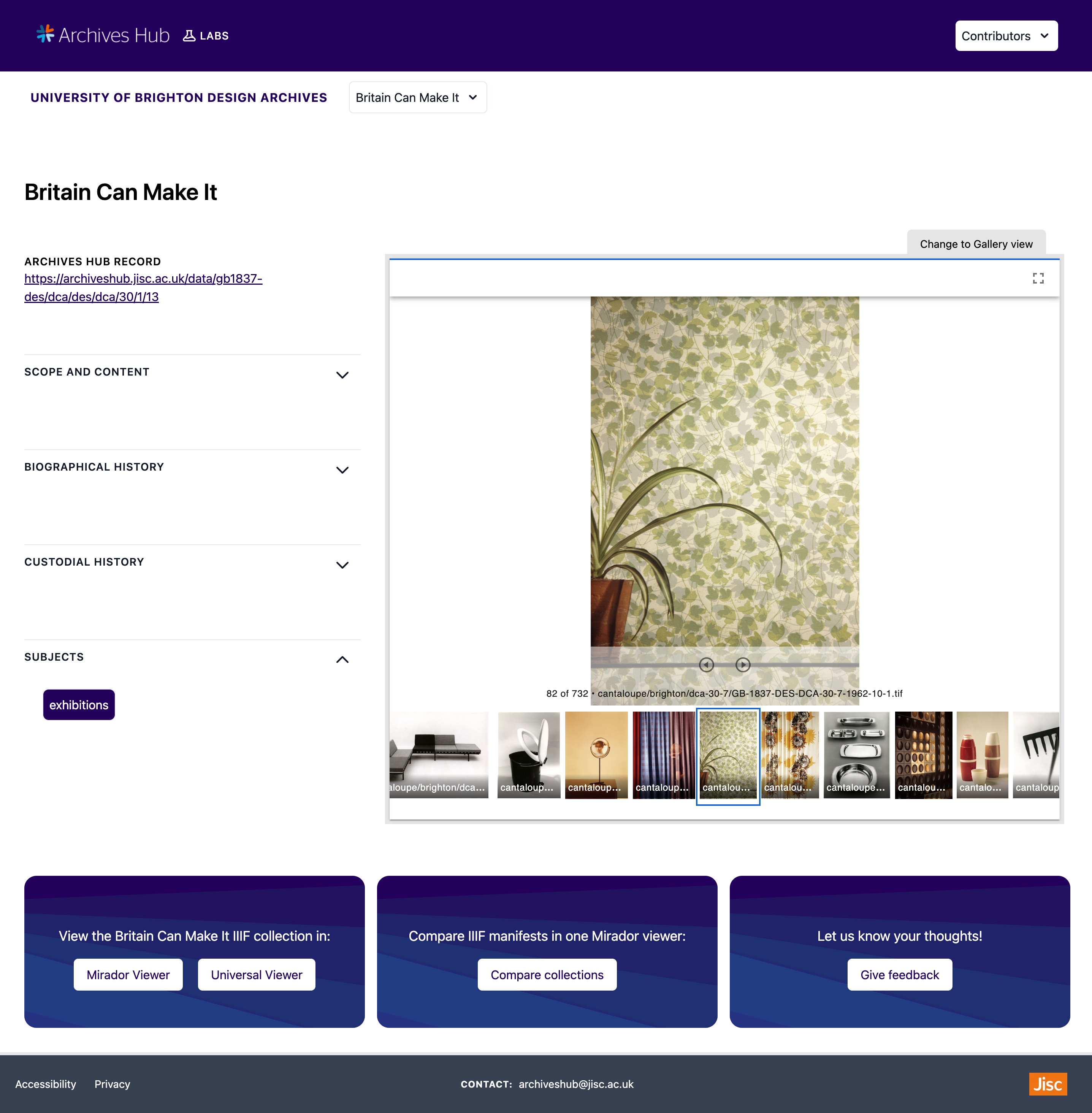
This is the collection page for the University of Brighton Design Archives ‘Britain Can Make It’ collection.
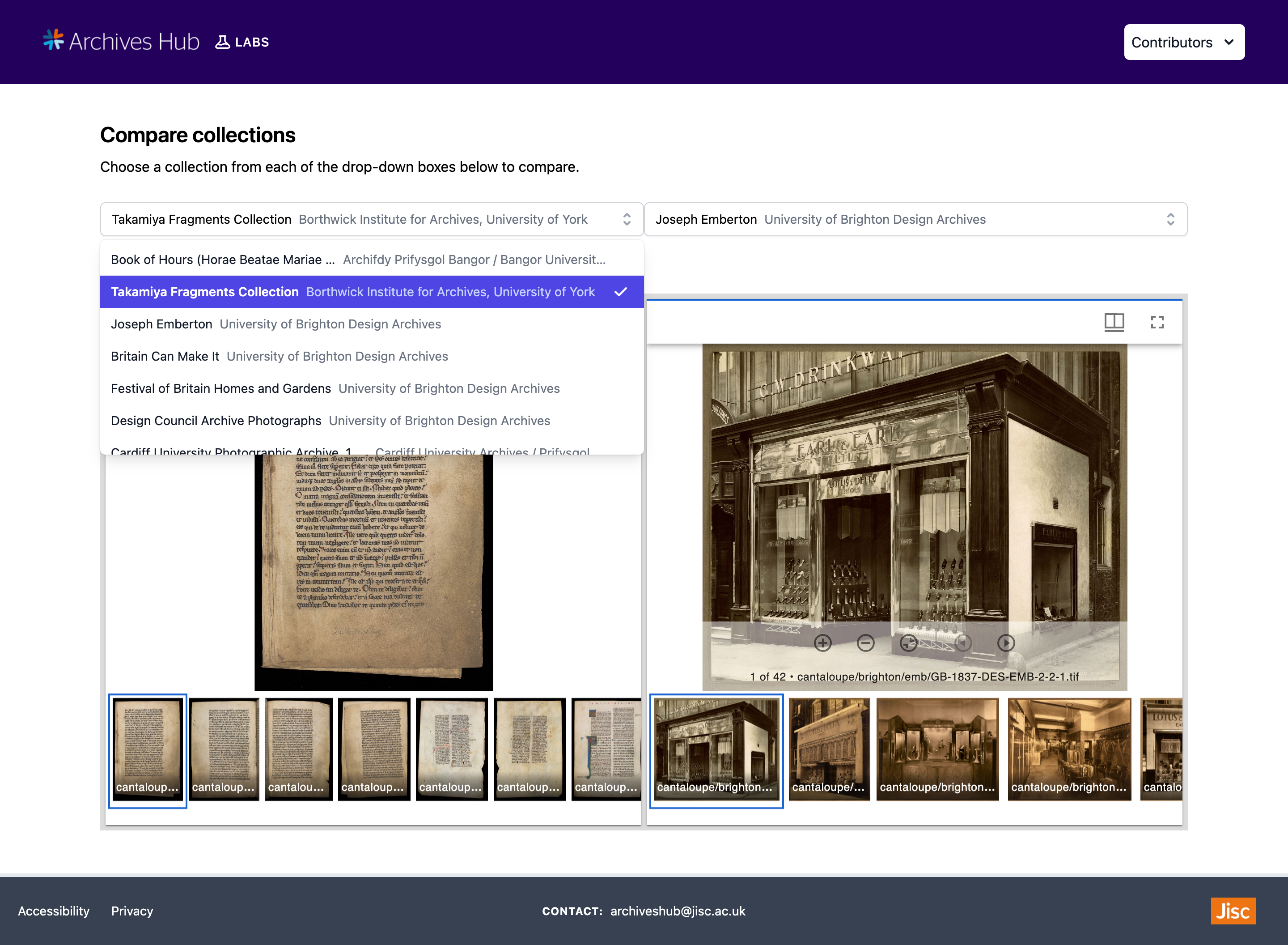
Mirador has the ability to display multiple windows within one workspace. This is really useful for comparison of images side-by-side. Therefore, I have also created a ‘Compare Collections’ page where two Manifests of collection images can be compared side-by-side. I have configured two windows to display within one Mirador viewer. Then, two collections can be chosen for comparison using the dropdown select boxes seen in the image below.
The ‘Compare Collections’ page.
Next steps
There are three key next steps for developing the User Interface –
We have experimented with the Mirador viewer, and now we will be looking at how the Universal Viewer handles IIIF Collections.
From the workshop feedback and from our exploration with the display of images, we will be looking at how we can offer an alternative experience of these archival images – distinct from their cataloguing hierarchy – such as thematic digital exhibitions and linking to other IIIF Collections and Manifests that already exist.
As part of the Machine Learning aspect of this project, we will be utilising the additional option to add annotations within the IIIF resources, so that the ML outputs from each image can be added as annotations and displayed in a viewer.
Labs IIIF Workshop
We recently held a workshop with the Archives Hub Labs project participants in order to get feedback on viewing the archive hierarchy through these IIIF Collections, displayed in a Mirador viewer. In preparation for this workshop, Ben created a sample of IIIF Collections using the images kindly provided by the project participants and the archival data related to these images that is on the Archives Hub. These were then loaded into the Mirador viewer so our workshop participants could see how the collection hierarchy is displayed within the viewer. The outcomes of this workshop will be explored in the next Archives Hub Labs blog post.
Thank you to Cardiff University, Bangor University, Brighton Design Archives at the University of Brighton, the University of Hull, the Borthwick Institute for Archives at the University of York, Lambeth Palace (Church of England) and Lloyds Bank for providing their digital collections and for participating in Archives Hub Labs.
For our Machine Learning experiments we are using Amazon Web Services (AWS). We thought it would be useful to explain what we have been doing.
AWS, like most Cloud providers, gives you access to a huge range of infrastructure, services and tools. Typically, instead of having your own servers physically on your premises, you instead utlitise the virtual servers provided in the Cloud. The Cloud is a cost effective solution, and in particular it allows for elasticity; dynamically allocating resources as required. It also provides a range of features, and that includes a set of Machine Learning services and tools.
The AWS console lists the services available. For Machine Learning there are a range of options.
One of the services available is Amazon Rekognition. This is what we have used when writing our previous blog posts.
Amazon Rekognition enables you to analyse images
One of the things Rekognition does is object detection. We have written about using Rekognition in a previous post.
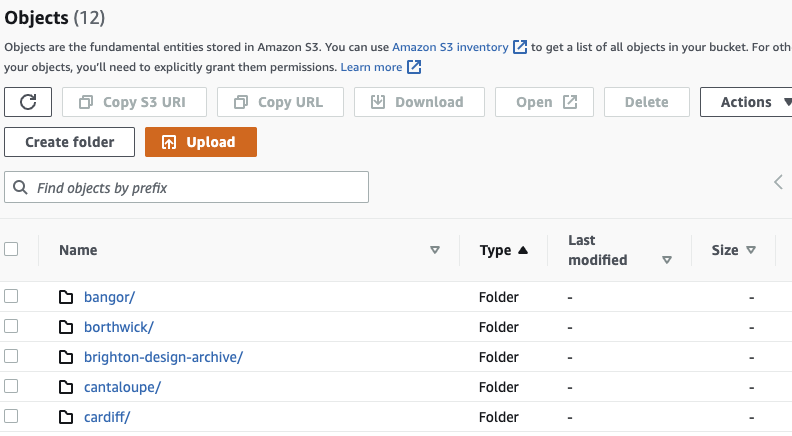
Our initial experiments were done on the basis of uploading single images at a time and looking at the output. The next step is to work out how to submit a batch of images and get output from that. AWS doesn’t have an interface that allows you to upload a batch. We have batches of images stored in the Cloud (using the ‘S3’ service), and so we need to pass sets of images from S3 to the Rekognition service and store the resulting label predictions (outputs). We also need to figure out how to provide these predictions to our contributors in a user friendly display.
S3 provides a storage facility (‘buckets’), where we have uploaded images from our Labs participants
After substantial research into approaches that we could take, we decided to use the AWS Lambda and DynamoDB services along with Rekognition and S3. Lambda is a service that allows you to run code without having to set up the virtual machine infrastructure (it is often referred to as a serverless approach). We used some ‘blueprint’ Lambda code (written in Python) as the basis, and extended it for our purposes.
One of the blueprints is for using Rekognition to detect faces
Using something like AWS does not mean that you get this type of facility out of the box. AWS provides the infrastructure and the interfaces are reasonably user friendly, but it does not provide a full blown application for doing Machine Learning. We have to do some development work in order to use Rekognition, or other ML tools, for a set of images.
A slice of the code – the images are taken from the S3 bucket and Rekognition provides a response with levels of confidence.
Lambda is set up so the code will run every time an image is placed in the S3 bucket. It then passes the output (label prediction) to another AWS service, called DynamoDB, which is a ‘NoSQL’ database.
DynamoDB output
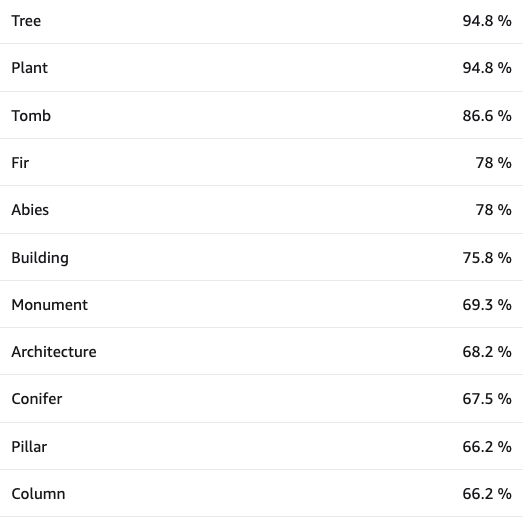
In the above image you can see an excerpt from the output from running the Lambda code. This is for image U DX336-1-6.jpg (see below) and it has predicted ‘tree’ with a confidence level of 94.51 percent. Ideally we wanted to add the ‘bounding box’ which provides the co-ordinates for where the object is within the image.
Image from the Royal Conservatoire of Scotland showing bounding boxes to identify person and chair
We spent quite a bit of time trying to figure out how to add bounding boxes, and eventually realised that they are only added for some objects – Amazon Rekognition Image and Amazon Rekognition Video can return the bounding box for common object labels such as cars, furniture, apparel or pets, but the information isn’t returned for less common object labels. Quite how things are classed as more or less common is not clear. At the moment we are working on passing the bounding box information (when there is any) to our database output.
Image from Hull University ArchivesLabel predictions for the above image
Clearly for this image, it would be useful to have ‘memorial’ and ‘cross’ as label predictions, but these terms are absent. However, sometimes ML can provide terms that might not be used by the cataloguer, such as ‘tree’ or ‘monument’.
So we now have the ability to submit a batch of images, but currently the output is in JSON (the above output table is only provided if you upload the image individually). We are hoping to read the data and place the labels into our IIIF development interface.
The next step is to create a model using a subset of the images that our participants have provided. A key thing to understand is that in order to train a model so that it makes better predictions you need to provide labelled images. Therefore, if you want to try using ML, it is likely that part of the ML journey will require you to undertake a substantial amount of labelling if you don’t already have labelled images. Providing labelled content is the way that the algorithm learns. If we provided the above image and a batch of others like it and included a label of ‘memorial’ then that would make it more likely that other non-labelled images we input would be identified correctly. We could also include the more specific label ‘war memorial’ – but it would seem like a tall order for ML to distinguish war memorials from other types. Having said that, the fascinating thing is that often machines learn to detect patterns in a way that surpasses what humans can achieve. We can only give it a go and see what we get.
Thanks to Adrian Stevenson, one of the Hub Labs team, who took me through the technical processes outlined in this post.
One of the challenges that we face with our Labs project is presentation of the Machine Learning results. We thought there would be many out of the box tools to help with this, but we have not found this to be the case.
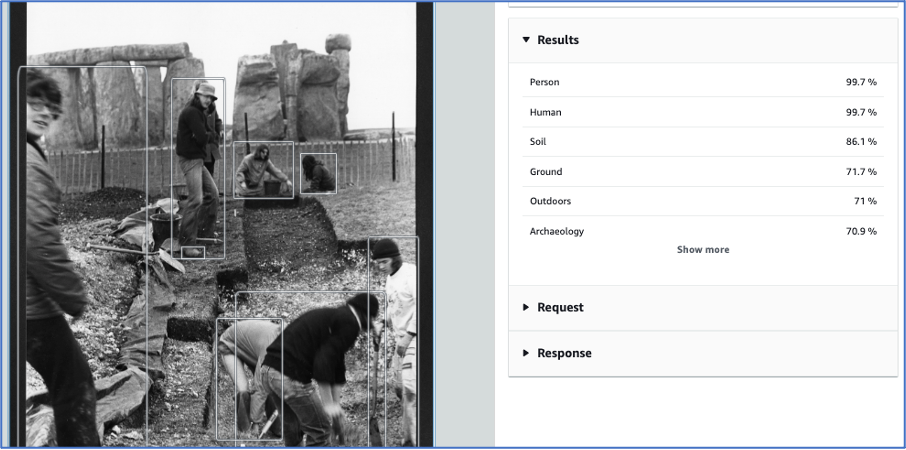
If we use the AWS console Rekognition service interface for example, we get presented with results, but they are not provided in a way that will readily allow us and our project participants to assess them. Here is a screenshot of an image from Cardiff University – an example of out of the box use of AWS Rekognition:
Excavation at Stonehenge, Cardiff University Photographic Archive
This is just one result – but we want to present the results from a large collection of images. Ideally we would run the image recognition on all of the Cardiff images, and/or on the images from one collection, assess the results within the project team and also present them back to our colleagues at Cardiff.
The ML results are actually presented in JSON:
Excerpt from JSON showing ML output
Here you can see some of the terms identified and the confidence scores.
These particular images, from the University archive, are catalogued to item level. That means they may not benefit so much from adding tags or identifying objects. But they are unlikely to have all the terms (or ‘labels’ in ML parlance) that the Rekognition service comes up with. Sometimes the things identified are not what a cataloguer would necessarily think to add to a description. The above image is identified as ‘outdoors’, ‘ground’ and ‘soil. These terms could be useful for a researcher. Just identifying photographs with people in them could potentially be useful.
Another example below is of a printed item – a poem.
Up in the Wind, Papers of Edward Thomas, Cardiff University
Strange formatting of the transcript aside, the JSON below shows the detected text (squirrels), confidence and area of the image where the word is located.
Detected word ‘squirrels’
If this was provided to the end user, then anyone interested in squirrels in literature (surely there must be someone…) can find this digital content.
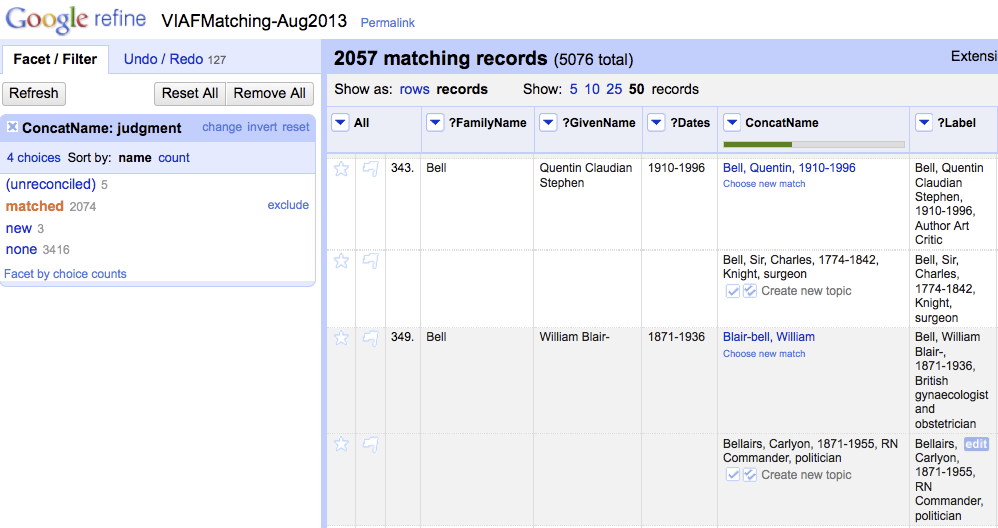
But we have to figure out how to present results and what functionality is required. It reminds me of using Open Refine to assess person name matches. The interface provides for a human eye to assess and confirm or reject the results.
Screenshot of names matching using Open Refine
We want to be able to lead discussions with our contributors on the usefulness, accuracy, bias – lack of bias – and peculiarities of machine learning, and for that a usable interface is essential.
How we might knit this in with the Hub description is something to consider down the line. The first question is whether to use the results of ML at all. However, it is hard to imagine that it won’t play a part as it gets better at recognition and classification. Archvists often talk about how they don’t have time to catalogue. So it is arguable that machine learning, even if the results are not perfect, will be an improvement on the backlogs that we currently have.
AWS Rekognition tools
We have thought about which tools we would like to use and we are currently creating a spreadsheet of the images we have from our participants and which tools to use with each group of images.
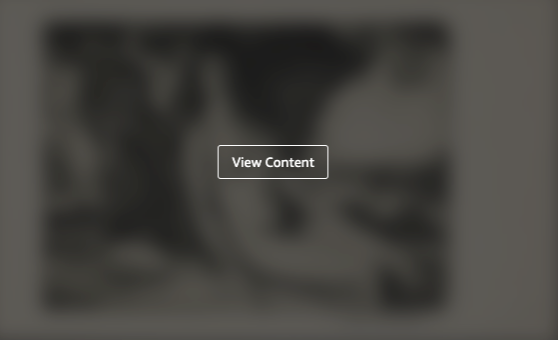
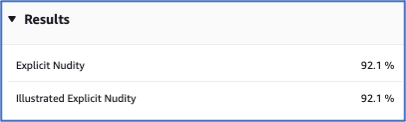
Some tools may seem less likely, for example, image moderation. But with the focus on ethics and sensitive data, this could be useful for identifying potentially offensive or controversial images.
Blanked out image
The Image Moderation tool recognises nudity in the above image.
The confidence scores are high that this image represents nudity
This could be carried through to the end user interface, and a user could click on ‘view content’ if they chose to do so.
Art Design and Architecture Collection, Glasgow School of Art (NMC/1137)
The image moderation tool may classify images art images as sensitive when they are very unlikely to cause offence. The tools may not be able to distinguish offensive nudity from classical art nudity. With training it is likely to improve, but when you think about it, it is not always an easy line for a human to draw.
Face comparison could potentially be useful where you want to identify individuals and instances of them within a large collection of photographs for example, so we might try that out.
However, we have decided that we won’t be using ‘celebrity recognition’, or ‘PPE detection’ for this particular project!
Text and Images
We are particularly interested in text and in text within images. It might be a way to connect images, and we might be able to pull the text out to be used for searching.
Suffice to say that text will be very variable. We ran Transkribus Lite on some materials.
Letter from the Papers of Edward Thomas at Cardiff University
We compared this to use of AWS Text Rekognition.
Letter from the Papers of Edward Thomas at Cardiff University
These examples illustrate the problem with handwritten documents. Potentially the model could be trained to work better for handwriting, but this may require a very large amount of input data given the variability of writing styles.
Poem from the Papers of Edward Thomas, Cardiff University
Transkribus has transcribed this short typescript text from the same archive well. One word ‘house’ has been transcribed as ‘housd’ and ‘idea’ caused a formatting issue, but overall a good result.
Poster from the Design Archive, University of Brighton Design Archives
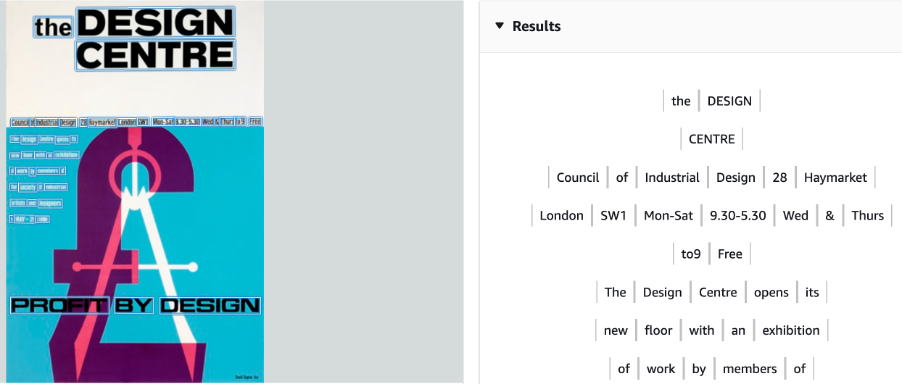
The above example is Transkribus Lite on a poster from the University of Brighton Design Archives. In archives, many digital items are images with text – particularly collections of posters or flyers. Transkribus has not done well with this (though this is just using the Lite version out of the box).
We also tried this with the AWS Rekognition Text tool, and it worked well.
Another example of images with text is maps and plans.
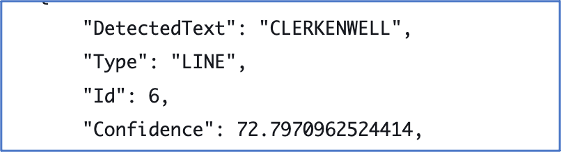
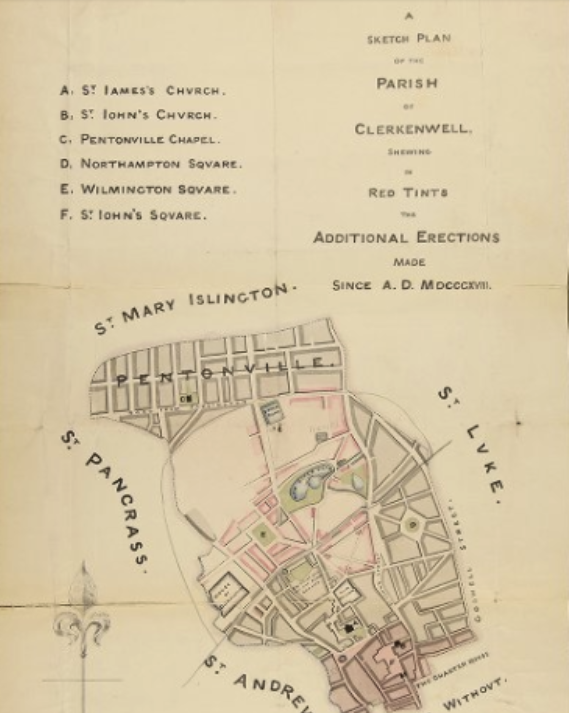
19th century map of Clerkenwell, Lambeth Palace Archive
Above are two examples of places identified from the plan output in JSON. If we can take these outputs and add them to our search interface, an end user could search for ‘clerkenwell’ or ‘northampton square’ and find this plan.
Questions we currently have:
How do we present the results back to the project team?
How do we present the results to the participants?
Do we ask participants specific questions in order to get structured feedback?
Will we get text that is useful enough to go to the next step?
Which images provide good text and which don’t?
How might they results be used on the Archives Hub to help with discovery?
As we progress the work, we will start to think about organising a workshop for participants to get their feedback on the ML outputs.
Thanks to Adrian Stevenson, one of the Hub Labs team, who took me through the technical processes outlined in this post.
Machine Learning is a sub-set of Artificial Intelligence (AI). You might like to look at devopedia.org for a short introduction to Machine Learning (ML).
Machine Learning is a data-oriented technique that enables computers to learn from experience. Human experience comes from our interaction with the environment. For computers, experience is indirect. It’s based on data collected from the world, data about the world.
Definition of Machine Learning from devopedia.org
The idea of this and subsequent blog posts is to look at machine learning from a specifically archival point of view as well as update you on our Labs project, Images and Machine Learning. We hope that our blog posts help archivists and other information professionals within the archival or cultural heritage domain to better understand ML and how it might be used.
At the Archives Hub we are particularly focussed on looking at Machine Learning from the point of view of archival catalogues and digital content, to aid discoverability, and potentially to identify patterns and bias in cataloguing.
Machine Learning to aid discoverability can be carried out as supervised or unsupervised learning. Supervised learning may be the most reliable, producing the best results. It requires a set of data that contains both the inputs and the desired outputs. By ‘outputs’ we mean that the objective is provided by labelling some of the input data. This is often called training data. In a ‘traditional’ scenario, code is written to take input and create output; in machine learning, input and output is provided, and the part done by human code is instead done by machine algorithms to create a model. This model is then used to derive outputs from further inputs.
The machine learning model, or program, is the outcome of learning from data (source: Advani 2020)
So, for example, taking the Vickers instruments collection from the Borthwick: https://dlib.york.ac.uk/yodl/app/collection/detail?id=york%3a796319&ref=browse. You may want to recognise optical instruments, for example, telescopes and microscopes. You could provide training data with a set of labelled images (output data) to create a model. You could then input additional images and see if the optical instruments are identified by the model.
Of course, the Borthwick may have catalogued these photographs already (in fact, they have been catalogued), so we know which are telescopes and which are micrometers or lenses or eye pieces. If you have a specialist collection, essentially focused on a subject, and the photographs are already labelled, then there may be less scope for improving discoverability for that collection by using machine learning. If the Borthwick had only catalogued a few boxes of photographs, they might consider using machine learning to label the remaining photographs. However, a big advantage is that the enhanced telescope recognising model can now be used on all the images from the Archives Hub to discover and label images containing telescopes from other collections. This is one of the great advantages of applying ML across the aggregated data of the Archives Hub. The results of machine learning are always going to be better with more training data, so ideally you would provide a large collection of labelled photographs in order to teach the algorithm. Archive collections may not always be at the kind of scale where this process is optimised. Providing good training data is potentially a very substantial task, and does require that the content is labelled. It is possible to use models that are already available without doing this training step, but the results are likely to be far less useful.
Another scenario that could lend itself to ML is a more varied collection, such as Borthwick’s University photograph collection. These have been catalogued, but there is potential to recognise various additional elements within the photographs.
Construction of the J.B. Morrell Library, University of York
The above photograph has been labelled as a construction site. ML could recognise that there are people in the photograph, and this information could be added, so a researcher could then look for construction site with people. Recognising people in a photograph is something that many ML tools are able to do, having already been trained on this. However, archive collections are often composed of historic documents and old photographs that may not be as clear as modern documents. In addition, the models will probably have been trained with more current content. This is likely to be an issue for archives generally. For models to be effective, they need to have been trained with content that is similar to the content we want to catalogue.
The benefits of adding labels to photographs via ML to potentially enhance the catalogue and help with discoverability is going to depend upon a number of factors: how well the image is already catalogued, whether training data can be provided to improve the algorithm, how well ML can then pick out features that might be of use.
The drawings of fossil fish at the Geological Society are another example of a very subject specific collection. We put a few of these through some out-of-the-box ML tools. These tools have been pre-trained on large diverse datasets, but we have not done any additional training ourselves yet, so you could see them as generalists in recognising entities rather than specialists with any particular material or topic.
Fossil tortoise from Oeningen
In this case the drawing has been tagged with ‘fossil’, which could be useful if you wanted to identify fossil drawings from a varied collection of drawings. It has also tagged this with archaeology and art, both of which could potentially be useful, again depending upon the context. The label of soil is a bit more problematic, and yet it is the one that has been added with 99.5% certainty. However, a bit of training to tell the algorithm that ‘soil’ is not correct may remove this tag from subsequent drawings.
This example illustrates the above point that a subject specific collection may be tagged with labels that are already provided in the catalogue description. It also shows that machine learning is unlikely to ever be perfectly accurate (although there are many claims it outperforms humans in a number of areas). It is very likely to add labels that are not correct. Ideally we would train the model to make less mistakes – though it is unlikely that all mistakes will be eliminated – so that does mean some level of manual review.
Tagging an image using ML may draw out features that would not necessarily be added to the catalogue – maybe they are not relevant to the repository’s main theme, and in the end, it is too time-consuming for cataloguers themselves to describe each photo in great detail as part of the cataloguing process.
Queen’s University Belfast: Hart Collection – China Photographs
The above image is a simple one with not too much going on. It will be discoverable on the Queen’s website through a search for ‘china’ or ‘robert hart’ for example, but tagging could make it discoverable for those interested in plants or architectural features. Again, false positives could be a problem, so a key here is to think about levels of certainty and how to manage expectations.
As mentioned above, archival images are often difficult to interpret. They may be old and faded, and they may also represent features or items that an algorithm will not recognise.
Design Council Archive: Things in their home setting – detail of a living room
In the above example from Brighton Design Archives, the photograph is from a set made of an exhibition of 1947, Things In Their Home Setting. The AWS image Rekognition service has no problem with the chair, but it has confidently identified the oven as a refrigerator. This could probably be corrected by providing more training data, or giving feedback to improve the understanding of the algorithm and its knowledge of 1940’s kitchen furniture. But by the time you have given enough training data for the model to recognise a cooker from a fridge from a washing machine, it might have been easier simply to do the cataloguing manually.
Another option for machine learning is optical character recognition. This has been around for a while, but it has improved substantially as a result of the machine learning approach. Again, one of the challenges for archives is that many items within the collections are handwritten, faded, and generally not easily readable. So, can ML prove to be better with these items than previous OCR approaches?
A tool like Transkribus can potentially offer great benefits to archives, and is seen as a community-driven effort to create, gather and share training data. We hope to try out some experiments with it in the course of our project.
Clerkenwell St James Parish, General Plan
The above plan is from Lambeth Palace Library’s 19th century ecclesiastical maps. It can already be found searching for ‘clerkenwell’ or ‘st james parish’. But ML could potentially provide more searchable information.
OCR using Azure
The words here are fairly clear, so the character recognition using the Microsoft Azure ML service is quite good. Obviously the formatting is an issue in terms of word order. ‘James’ is recognised as ‘Iames’ due to the style of writing. ‘Church’ is recognised despite the style looking like ‘Chvrch’ – this will be something the algorithm has learnt. This analysis could potentially be useful to add to the catalogue because an end user could then search for ‘pentonville chapel’ or ‘northampton square’ and find this plan.
As well as looking at digital archives, we will be trying out examples with catalogue text. A great deal of archival cataloguing is legacy data, and archivists do not always have the time to catalogue to item level or to add index terms, which can substantially aid discoverability. So, it is tempting to look at ML as a means to substantially improve our catalogues. For example, to add to our index terms, which provide structured access points for end users searching for people, organisations, places and subjects.
In a traditional approach to adding subject terms to a catalogue, you might write rules. We have done this in our Names Project – we have written a whole load of rules in order to identify name, life dates, and additional data within index terms. We could have written even more rules – for example, to try to identify forename and surname. But it would be very difficult because the data does not present the elements of names consistently. We could potentially train an ML model with a load of names, tagging the parts of the name as forename, surname, dates, titles, epithets. But could an algorithm then successfully work out the parts of any subsequent names that we feed into it? It seems unlikely because there is no real consistency in how cataloguers input names. The algorithm might learn, for example, that a word, then a comma, then another word is surname, forename (Roberts, Elizabeth). But two words followed by a comma and another word could be surname + forename or forename + surname, (Vaughan Williams, Ralph; Gerald Finzi, composer). In this scenario, the best option may be to aim to use source data (e.g. the Virtual International Authority File) to compare our data to, rather than try to train a machine to learn patterns, when there really isn’t a model to provide the input.
We may find that analysing text within a catalogue offers more promise.
Part of the admin history for the British Linen Company archive at Lloyds
Here is an example from an administrative history of the British Linen Group, a collection held by Lloyds Banking Group. The entity recognition is pretty good – people’s names, organisations, dates, places, occupations and other entities can be picked out fairly successfully from catalogues. Of course that is only the first step; it is how to then use that information that is the main issue. You would not necessarily want to apply the terms as index terms for example, as they may not be what the collection is substantially about. But from the above example you could easily imagine tagging all the place names with a ‘place’ tag, so that a place search could find them. So, a general search for Stranraer would obviously find this catalogue entry, but if you could identify it as a place name it could be included in the more specific place name search.
With machine learning it is very difficult and sometimes impossible to understand exactly what is happening and why. By definition, the machine learns and modifies its output. Whilst you can provide training data to give inputs and desired outputs, machine learning will always be just that….a machine learning as it goes along, and not simply working through a programme that a human has written. Supervised learning provides for the most control over the outputs. Unsupervised learning, and deep learning, are where you have much less control (we’ll come onto those in later posts).
It is only by understanding the algorithms and what they are doing that you can set up your environment for the best results. But that is where things can get very complicated. We are going to try to run some experiments where we do prepare the data, but learning how to do this is a non-trivial task. Hence one of the questions we are asking is ‘is Machine Learning worth the effort required in order to improve archival discoverability?’ We hope to get at least some way along the road to answering that question.
There are, of course, other pressing questions, not least the issue of bias, and concerns about energy use with machine learning as well as how to preserve the processes and outputs of ML and document the decision making. But there could be big wins in terms of saving time that can then be dedicated to other tasks. The increasing volumes of data that we have to process may make this a necessity. We hope to touch upon some of these areas, but this is a fairly small scale project and Machine Learning it is one huge topic.
As mentioned in my last post, we’re looking at the possibilities Artificial Intelligence and Machine Learning can offer the Archives Hub and the archives community in general. I also now have a wider role in Jisc as a ‘Technical Innovations Manager’, so my brief is to consider the wider technical and strategic possibilities of AI/ML for the Digital Resources directorate and Jisc as a whole. We continue to work behind the scenes, but we also keep a watch on cultural heritage and wider sector activities. As part of this I participated in the Aeolian Project’s ‘Online Workshop 1: Employing Machine Learning and Artificial Intelligence in Cultural Institutions’ yesterday.
‘Visual AI and Printed Chapbook Illustrations at the National Library of Scotland’ – Dr Giles Bergel (University of Oxford / National Library of Scotland)
Giles’ team have been using machine learning (ML) on data from data.nls.uk. He outlined their three part approach. First they find illustrations in manuscripts using Google’s EfficientDet object detection convolutional neural network seeded by manually pre-annotated images. They found the object detector worked extremely well after relatively few learning passes. There were a few false positives such as image ink showing through, marginalia and dog ears that would confuse the model.
False positive ML recognition – ink showthrough
Next they matched and grouped the illustrations using their “state of art” image search engine. Giles believes this shows that AI simplifies the task of finding things that are related in images. The final step was to apply classification alogorithms with the VGG Image Classification Engine which uses Google as a source of labelled images. The lessons learned were:
AI requires well-curated data
Tools for annotating data are no less important than classifiers
Generic image models generalize well to printed books
‘Classical’ computer vision still works
AI software development benefits from end-to-end use-cases including data preparation, refinement, consulting with domain experts, public engagement etc.
‘Machine Learning and Cultural Heritage: What Is It Good Enough For?’ – John Stack (UK Science Museum)
John described how AI is being used as part of the Science Museum’s linked data work to collect data into a central knowledge graph. He noted that the Science Museum are doing a great deal of digitisation but currently they only have what John describes as ‘thin’ object data.
They are looking at using AI for name disambiguation as a first step before adding links to wikidata and using entity recognition to enhance their own catalogue. It stuck me that they, and we at the Hub, have been ‘doing AI’ for a while now with such technologies as entity recognition and OCR before the term AI was used. They are aiming to link through to wikidata such that they can pull in the data and add it to their knowledge graph. This allows them to enhance their local data and apply ML to perform such things as clustering to draw out new insights.
John identified the main benefits of ML currently as suggesting possibilities and identifying trends and gaps. It’s also useful for visualisation and identifying related content as well as enhancing catalogues with new terminology. However there were ‘but’s. ML content needs framing and context. He noted that false positives are not always apparent and usually require specialist knowledge. It’s important to approach things critically and understand what can’t be done. John mentioned that they don’t have any ML driven features in production as yet.
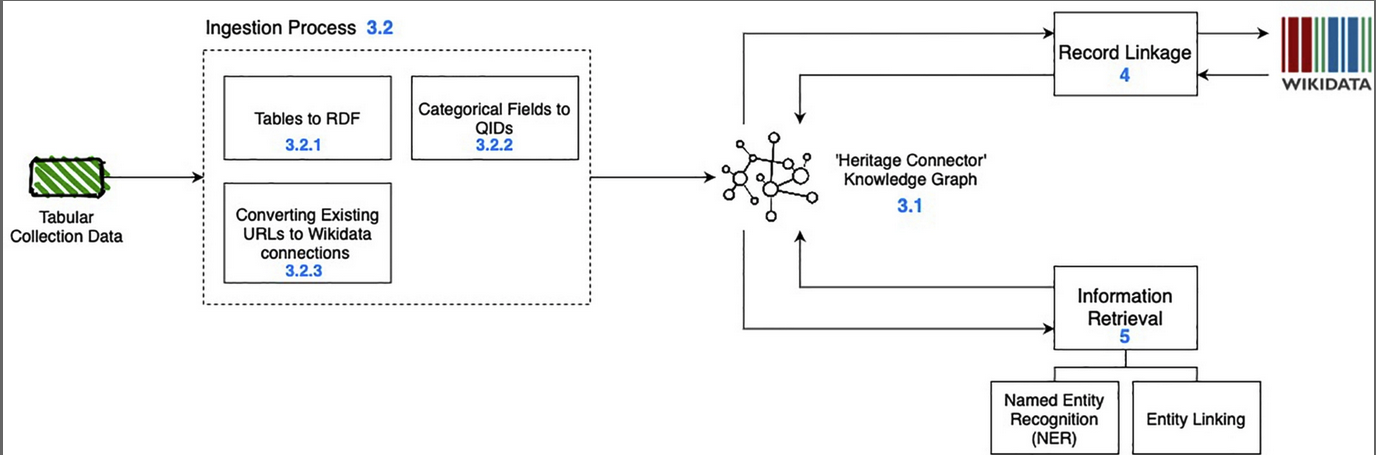
Diagram showing the components of the Heritage Connector software
This was followed by a Q&A where several issues came up. We need to consider how AI may drive new ways/modalities of browsing that we haven’t imagined yet. A major issue is the work needed to feed AI enhancements into user interfaces. Most work so far has been on backend data. AI tools need to integrate into day-to-day workflows for their benefits to be realised. More sector specific case-studies, training materials, tools and models are needed that are appropriate to cultural heritage. See the Heritage Connector blog for more information.
‘AI and the Photoarchive‘ – John McQuaid (Frick Collection), Dr Vardan Papyan (University of Toronto), and X.Y. Han (Cornell University)
The Frick Collection have been using the PyTorchdeep neural network to identify labels for their photo archive collection. They then compared the ML results as a validation exercise with internally crowdsourced data from their staff and curators captured by the Zooinverse software for the same photos.
Frick Collection ML workflow
They found that 67% of the ML labels matched with the crowdsource validations which they considered a good result. They concluded that at present ML is most useful for ‘curatorial amplification’, but much human effort is still needed. This auto-generation of metadata was their main use case so far.
‘Keep True: Three Strategies to Guide AI Engagement‘ – Thomas Padilla (Center for Research Libraries)
Thomas believes GLAMs have an opportunity to distinguish themselves in the AI space. He covered a number of themes, the first being the ’Non-scalability imperative’. Scale is everywhere with AI. There’s a great deal of marketing language about scale, but we need to look at all the non-scalable processes that scale depends on. There’s a problematic dependency where scalability is made possible by non-scalable processes, resources and people. Heterogeneity and diversity can become a problem to be solved by ML. There’s little consideration that AI should be just and fair.
The second theme was ‘Neoliberal traps’ in AI. Who says ethical AI is ethical AI? GLAMs are trying to do the right thing with AI, but this is in the context of neoliberal moral regulation which is unfair and ineffective. He mentioned some of the good examples from the sector including from CILIP, Museums AI Network and his own ‘Responsible Operations‘ paper.
He credited Melissa Terras for asking the question “How are you going to advocate for this with legislation?”. The US doesn’t have any regulations at the moment to get the private sector to get better. I mentioned the UK AI Council who are looking at this in the UK context, and the recent CogX event where the need for AI regulation was discussed in many of the sessions.
The final theme was ‘Maintenance as Innovation’. Information maintenance is a Practice of Care. There is an asserted dichotomy between maintenance and innovation that’s false. Maintenance is sustained innovation and we must value the importance of maintenance to innovation. He appealed to the origin of the word ‘innovation’ which derives from the latin ‘innovare’ which means “to alter, renew, restore, return to a thing, introduce changes in the way something is done or made”. It’s not about creating from new. At the Hub we wholeheartedly endorse this view. We feel there’s far too much focus on the latest technology meme and we’ve had tensions within our own organisation along these lines. There may appear to be some irony here given the topic of this post, but we have been doing AI for a while as noted above. He referred us to https://themaintainers.org/ for more on this.
Roundtable discussion with the AEOLIAN Project Team
Dr Lise Jaillant, Dr Annalina Caputo, Glen Worthey (University of Illinois), Prof. Claire Warwick (Durham University), Prof. J. Stephen Downie (University of Illinois), Dr Paul Gooding (Glasgow University), and Ryan Dubnicek (University of Illinois).
Stephen Downie talked about the need for standardisation of ML extracted features so we can re-use these across GLAMs in a consistent way. The ‘Datasheets for Datasets’ paper was mentioned that proposes “a short document to accompany public datasets, commercial APIs, and pretrained models”. This reminded me of Yves Bernaert’s talk about the related need for standardisation of carbon consumption measures. Both are critical issues and possible areas for Jisc to be involved in providing leadership. Another point that Stephen made is that researchers are finding they can’t afford the bill for ML processing. Finding hardware and resources is a big problem. As noted by ML guru Andrew Ng, we have a considerable data issue with AI and ML work . It may be that we need to work more on the data rather than wasting time, electricity and money re-creating expensive ML models. A related piece of work, ‘Lessons from Archives‘ was also mentioned in this regard. There is a case for sharing model developments across the sector for efficiency and sustainability here.
I attended the ‘CogX Global Leadership Summit and Festival of AI’ last week, my first ‘in-person’ event in quite a while. The CogX Festival “gathers the brightest minds in business, government and technology to celebrate innovation, discuss global topics and share the latest trends shaping the defining decade ahead”. Although the event wasn’t orientated towards archives or cultural heritage specifically, we are doing work behind the scenes on AI and machine learning with the Archives Hub that we’ll say more about in due course. Most of what’s described below is relevant to all sectors as AI is a very generalised technology in its application.
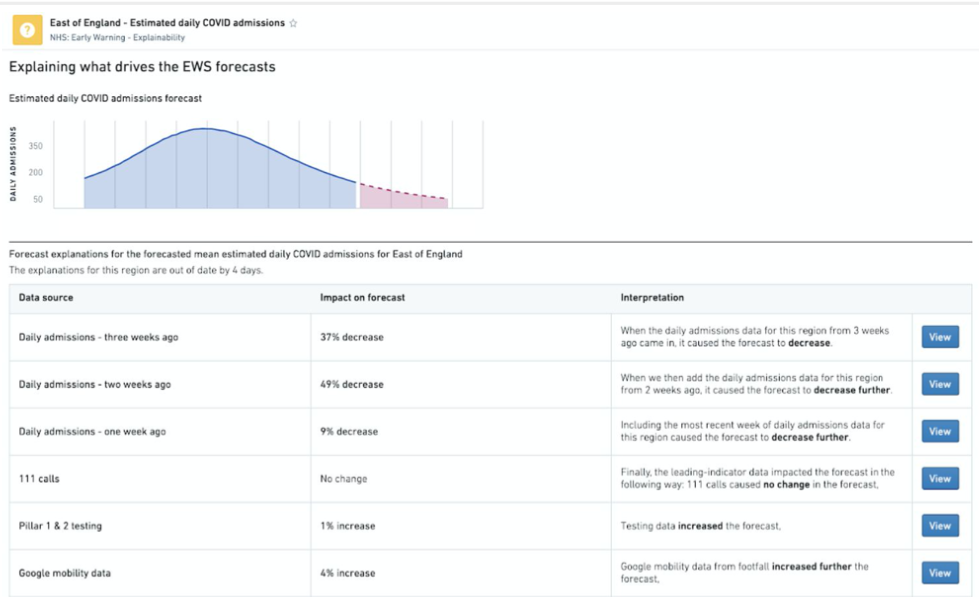
My attention was drawn to the event by my niece Laura Stevenson who works at Faculty and was presenting on ‘How the NHS is using AI to predict demand for services‘. Laura has led on Faculty’s AI driven ‘Early Warning System’ that forecasts covid patient admissions and bed usage for the NHS. The system can use data from one trust to help forecast care for a trust in another area, and can help with best and worst scenario planning with 95% confidence. It also incorporates expert knowledge into the modelling to forecast upticks more accurately than doubling rates can. Laura noted that embedding such a system into operational workflows is a considerable extra challenge to developing the technology.
The system includes an explainability feature showing various inputs and the degree to which they affect forecasting. To help users trust the tool, the interface has a model performance tab so users can see information on how accurate the tool has been with previous forecasts. The tool is continuing to help NHS operational managers make planning decisions with confidence and is expected to have lasting impact on NHS decision making.
Lila works at Deep Mind who are looking to use AI to unlock whole new areas of science. Lila highlighted the role of the AI Council who are providing guidance to UK Government in regard to UK AI research. She talked about Alphafold that has been addressing the 50 year old challenge of protein folding. This is a critical issue as being able to predict protein folding unlocks many possibilities including disease control and using enzymes to break down industrial waste. DeepMind have already created an AI system that can help predict how a protein folding occurs and have a peer reviewed article coming out soon. They are trying to get closer to the great challenge of general intelligence.
Yves focussed on company and corporate responsibility, starting his session with some striking statistics:
100 companies produce 70% of global carbon emissions.
40% of water consumption is by companies.
40% of deforestation is by companies.
There is 80 times more industrial waste than consumer waste.
20% of the acidification of the ocean is produced by 20 companies only.
Yves therefore believes that companies have a great responsibility, and technology can help to reduce climate impact. 2% of global electricity comes from data centres currently and is growing exponentially, soon to be 8%. A single email produces on average 4g of carbon. Yves stressed that all companies have to accept that now is the time to come up with solutions and companies must urgently get on with solving this problem. IT energy consumption needs to be seen as something to be fixed. If we use IT more efficiently, emissions can be reduced by 20-30%. The solution starts with measurement which must be built into the IT design process.
We can also design software to be far more efficient. Yves gave the example of AI model accuracy. More accuracy requires more energy. If 96% accuracy is to be improved by just 2%, the cost will be 7 times more energy usage. To train a single neural network requires the equivalent of the full lifecycle energy consumption of five cars. These are massive considerations. Interpreted program code has much higher energy use than compiled code such as C++.
A positive note is that 80% of the global IT workload is expected to move to the cloud in the next 3 years. This will reduce carbon emissions by 84%. Savings can be made with cloud efficiency measures such as scaling systems down and outwards so as not to unneccessarily provision for occasional workload spikes. Cloud migration can save 60 million tons carbon per year which is the equivalent of 20 million full lifecycle car emissions. We have to make this happen!
On where are the big wins, Yves said this is also in the IT area. Companies need to embed sustainability into their goals and strategy. We should go straight for the biggest spend. Make measurements and make changes that will have the most effect. Allow departments and people to know their carbon footprint.
* Update 28th June 2021 * – It was remiss of me not to mention that I’m working on a number of initiatives relating to green sustainable computing at Jisc. We’re looking at assessing the carbon footprint of the Archives Hub using the Cloud Carbon Footprint tool to help us make optimisations. I’m also leading on efforts within my directorate, Digital Resources, to optimise our overall cloud infrastructure using some of the measures mentioned above in conjuction with the Jisc Cloud Solutions team and our General Infrastructure team. Our Cloud CTO Andy Powell says more on this in his ‘AI, cloud and the environment‘ blog post.
‘Future of Research’ – Prof. Dame Ottoline Leyser, CEO, UK Research and Innovation (UKRI)
Ottoline believes that pushing the boundaries of how we support research needs to happen. Research is now more holistic. We draw in what we need to create value. The lone genius is a big problem for research culture and it has to go. Research is insecure and needs connectivity.
Ottoline believes AI will change everything about how research is done. It’s initially replacing mundane tasks but will some more complex tasks such as spotting correlations. Eventually AI will be used as a tool to help understanding in a fundamental way. In terms of the existential risk of AI, we need to embed research as collective endeavour and share effort to mitigate and distribute this risk. It requires culture change, joining up education and entrepreneurship.
We need to fund research in places that are not the usual places. Ottoline likes a football analogy where people are excited and engaged at all levels of the endeavour, whether in the local park or at the stadium. She suggests research at the moment is more like elitist Polo not football.
Ottoline mentioned that UKRI funding does allow for white spaces research. Anyone can apply. However, we need to create wider white spaces to allow research in areas not covered by the usual research categories. It will involve braided and micro careers, not just research careers. Funding is needed to support radical transitions. Ottonline agrees that the slow pace of publication and peer review is a big problem that undermines research. We need to broaden ways we evaluate research. Peer Review is helpful but mustn’t slow things down.
Rob suggests we are in an era with AI where there are no clear rules of the road yet. The task for AI is to make it safe to ‘drive’ with regulations. We can’t stop facial recognition any more than we can stop gravity. We need datasets for governance so we can check accuracy against these for validation. Transparency is also required so we can validate algorithms. A big AI concern is the tribalism on social media.
Matt Hancock believes we are at a key moment with healthcare and AI technology where it’s now of vital importance. Data saves lives! The next thing is how to take things forward in NHS. A clinical trials interoperability programme is starting that will agreed standards to get more out of data use, and the Government will be updating it’s Data strategy soon. He suggests we need to remove silos and commercial incentives (sic). On the use of GP data he suggests we all agree on the use of data, but the question is how it’s used. The NHS technical architecture needs to improve for better use and building data into the way the NHS works. GPs don’t own patient data, it is the citizen.
He said a data lake is being built across the NHS. Citizen interaction with health data is now greater than ever before and NHS data presents a great opportunity for research, and an enormous opportunity for the use of data to advance health care. He suggested we need to radically simplify the NHS information governance rules. On areas where not enough progress has been made, he mentioned the lack of separation of data layers is currently a problem. So many applications silo their data. There has also been a culture of Individual data with personal curation. The UK is going for a TRE first approach: ‘Trusted Research Environment service for England‘. Data is the preserve of the patient who will allow accredited researchers to use the data through the TRE. The clear preference of citizens is sharing data if they trust the sharing mechanism. Every person goes through a consent process for all data sharing. Acceptance requires motivating people with the lifesaving element of research. If there’s trust, the public will be on side. Researchers in this domain with have to abide by new rules to allow us to build on this data. He mentioned that Ben Goldacre will look at the line where open commons ends and NHS data ownership begins in the forthcoming Goldacre Review.