The University of East London (UEL) was founded in 1898 as the West Ham Technical Institute, founded with the aim of supporting local working-class communities through the provision of industry-focused education in subjects including engineering, science and the arts. Established with support from Victorian philanthropist John Passmore Edwards, who was present at the laying of the foundation stone in 1896, the Institute soon become known as `the People’s University’ through the commitment to provide educational opportunities and technical skills to people of the local area.
Opening of the West Ham Institute of Technology including John Passmore Edwards.
Over the subsequent decades, the Institution was to go through several iterations eventually becoming the North-East London Polytechnic in 1970 through a merger of the South East and South West Essex Technical Colleges, before being awarded University status along with other new universities in 1992.
About Us
The UEL Archive was established in November 2002 with the arrival of the Refugee Council Archive. The Archives are predominantly located withing UEL’s Docklands Campus Library which overlooks London City Airport and the Royal Docks.
Our collection strengths focus on refugee and migration studies; Olympic history; Theatre Studies; East London history and the institutional history of the University. Some of our key collections include the British Olympic Association Archive and Library; the Refugee Council Archive and related collections; the Hackney Empire Theatre Archive and collections relating to the history of Newham and East London. UEL’s Docklands Campus, situated adjacent to the Royal Albert Dock and City Airport, opened in 1999 as the first new university campus in London for 50 years. During the London Olympics of 2012, the new UEL SportsDock building served as Team USA’s High Performance Training Centre alongside the Team GB medical team.
Our UEL Institutional Archives date from 1898 and documents our history from the inception of the West Ham Technical Institute through to the present day. Sadly, the collections are not as complete as we would like them to be, and we continue to explore opportunities for building our institutional memory through engagement with alumni, past and present academic staff, and engagement with local archives including Newham Archives in Stratford.
British Olympic Association Archive and Library
Following the awarding of the XXX Olympiad to London for 2012, the University of East London was selected to be the host repository of the British Olympic Association’s (BOA) Archive and Library. The BOA Archive dates from 1906 through to the present day. The Archive document the history of Team GB’s participation in the Summer and Winter Olympic Games alongside the institutional history of the BOA as the National Olympic Committee for Great Britain.
The Archive contains a substantive collection of materials relating to the history of Olympianism within the British context. The Archive includes materials documenting all three London Olympic Games of 1908; 1948 and 2012 respectively alongside the history of Team GB Olympians and records for each of the summer and winter Olympic Games.
BOA Artefacts including 2012 Olympic Torch and Kathryn Long’s Javelin.
In addition to the documentary records, the Archive contains a large collection of Olympic Memorabilia and artefacts dating from the first London Olympics of 1908 through to the present day. Highlights of the collection include several Olympic Torches (including London 2012); a signed vest by Mo Farah; starting pistols and the original football used in the Men’s Olympic Final in 1908 (the British Team won gold beating Denmark 2-0 in the final); Kathryn Long’s javelin from the London 1948 Olympics and one of the gold-medal winning curling stones used by Rhona Martin’s TeamGB squad to win at the Salt Lake City Winter Olympic Games in 2002.
Collection of BOA Artefacts including the Curling Stone from Salt Lake City.
In 2025, UEL received approval from the International Olympic Committee (IOC) to establish an Olympic Studies Research Centre at the University. The focus of the Centre will be to bring together inter-disciplinary Olympic research being undertaken across the University whilst also providing a platform to undertake collaborative events and to help develop research and community engagement with the BOA Archive.
Archives of Displacement
The history of the UEL Archives began with the arrival of the Refugee Council in 2002. The Archive of the Refugee Council documents both the work of the organisation as an active charity working with refugees and asylum seekers, alongside an extensive special collection covering a range of materials including ephemera, published reports, audio-visual materials and press cuttings dating from 1951 onwards.
Over the following two decades, the Archive has developed a strong focus on documenting refugee history and community narratives associated with the lived experience if displacement. We now hold substantive named collections including records of charities and NGO’s including the archives of the Association of Ukrainian Women; Council of At-Risk Academics (CARA); Northern Refugee Centre; ICAR; and the Cambridge Refugee Support Group. These co-exist with community and oral history collections documenting lived experiences including VoKiM (the Voices of Kosovans in Manchester); the From East to West oral history project documenting the Chinese community in Manchester and two oral history archives documenting the 50th anniversary of the Ugandan Asian enforced exodus in 1972.
Banner from Mayapi, a Chilean folk band, part of the Documenting Chile Archive.
Histories of East London
The UEL Archives are also building a strong connection to the history both of our host London Borough of Newham and the wider history of East London. This includes the Hackney Empire Theatre Archive which contains materials documenting the campaign led by the Hackney Empire Preservation Trust to convert the Empire back into a local theatre venue having been converted into a TV studies and then a bingo hall. The campaign was led by Roland Muldoon, who was also responsible for establishing the underground political theatre group CAST (Cartoon Archetypical Slogan Theatre). The Archive contains extensive poster, flyers and playbills alongside CAST plays and scripts.
We also hold a growing East London Studies Collection which sits alongside the Newham Trackside Wall archive which documents the work of the artist Sonia Boyce OBE in creating a public artwork running along a 1.9km stretch of the Elizabeth line in the London Borough of Newham. The project was commissioned by Crossrail and led by Up Projects who worked with Sonia on the development of the artwork in collaboration with residents of North Woolwich, Silvertown and Custom House to draw out the area’s rich and unique cultural history which through the undertaking of oral histories which helped inform the final design work. The Archive includes both the design work created by Sonia Boyce and the oral histories recorded as part of the project.
The Newham Trackside Wall Artwork.
We are also fortunate to hold the Hidden Histories Archive by Eastside Community Heritage. Led by Judith Garfield, Eastside has been instrumental in collecting oral histories of East London life for over two decades and this represents a key resource for understanding the community histories of East London.
Community Engagement
Following the ideal of `the People’s University,’ the UEL Archives has maintained a strong commitment to community engagement supporting the ethical representation of community histories. Over the last decade, we have undertaken several community and participatory-focused projects looking to support communities in documenting, preserving and making accessible their own shared heritage.
Our Living Refugee Archive portal was established as part of our very first engagement project in 2015. We received seed funding from the UEL Civic Engagement Fund to undertake oral histories with displaced communities in London and established an online resource for improving accessibility to our refugee and migration collections whilst also providing a platform for ongoing engagement beyond the lifecycle of the original project.
Our engagement since then has incorporated working with organisations like Qisetna in helping to preserve Syrian cultural heritage and an ongoing project called Documenting Chile, working with Chilean communities across the UK. Documenting Chile is a participatory archiving project to document the community’s history and helping to preserve valuable archival materials. Through this work, we have also published a special issue of our open-access online journal Displaced Voices: A Journal of Migration, Archives and Cultural Heritage (ISSN: ) enabling their contributions to be heard through both writing and poetry.
We have also worked with local communities in the Royal Docks and Newham looking at the history of the Tate Institute, the former sports and social club for the Tate and Lyle Sugar Factory in Silvertown. This led to the creation of the online Tate Lives Trail documenting the lost pubs of Silvertown and North Woolwich.
Tate Lives Treasure Map designed by local artist Elena Juzlenaite.
The Passing the Flame project represented an opportunity to work with colleagues at London Stadium Learning (based at the West Ham Stadium in the Queen Elizabeth Park) to work with local schools in Newham to reflect on the legacy of the London 2012 Olympic Games in Stratford. We have continued to engage with local Newham schools in participating in the Sport In Your Futures Festival programme led by East London Sports at UEL. We are looking forward to working with the National Paralympic Heritage Trust on a project from September 2025 and developing new events and opportunities through the Olympic Studies Research Centre.
Paul V Dudman Archivist, University of East London
During March, the Archives Hub team made a visit to Cambridge, to talk to some of our contributing archivists at Cambridge University and to attend an event!
Cambridge archivists’ session
We ran a session for some of our contributors and other archivists at Cambridge University. This session built on our previous online User Research sessions, but with a focused group from one institution. We asked for some answers on post it notes and large sheets of paper, as well as in a discussion group.
King’s College chapel, Cambridge from Great St Mary’s church. Photo by Jean-Luc Benazet on Unsplash.
The session began with some questions about their archives, how the archivists feel about their work, their archive and their everyday challenges. Highlights mentioned included:
the range of work
helping researchers
the work is very rewarding
Common challenges included:
part time hours
time constraints
issues with uncatalogued materials.
These answers indicate a common factor across the sector – resources are often an issue, but enjoyment is fuelled by day-to-day variety and interactions with researchers. When asked about their archive’s aspirations for the future, improving accessibility to the collections was heavily emphasised.Another positive featured in this section was the ability of the archivist teams to work well together, and to be able to advocate for their individual archives.
St John’s College, Cambridge. Photo by Molly McTater on Unsplash.
Having established this background context, we looked at experiences of the archivists as users of Archives Hub. We first approached this by asking the archivists in attendance to finish some sentences. These focused on reasons for using the Hub, how they get to the Hub website and the most useful part of the Hub.
The most common way of reaching the Hub was via search engine, with reasons for using the Hub including:
to improve accessibility to their collections as a contributing archive
to find individuals relevant to their college archive
For the most useful part of the Hub, the search facility was the unanimous choice, as it allows a search of archives nationwide in one place.
Following this, we turned to the idea of Archives Hub in practice. We asked how the archivist team use Archives Hub internally, in teaching and learning or their perceptions of the Hub. More than one of the archivists mentioned signposting to the Hub for solutions to more general enquiries.
We also addressed issues facing Cambridge specifically, the main one being that there are multiple collections across the institution spread out across the different colleges. The archivists were keen to stress that the college archives are separate but interconnected, so being able to reflect that would be great. Using Archives Hub via ArchivesSpace (archive management application) will allow for multiple contributors to use one system, making it easier to contribute records via one harvesting method. This will also have a benefit for researchers highlighted by the archivists – the opportunity to search multiple college archives through one search!
Cambridge Archives and Collections Fair
Our trip to Cambridge also included co-hosting a stall during the Cambridge Archives and Collections Fair with the Library Hub team – talking to students, other stall holders and of course, more archivists.
Archives Hub team.
Archives of the different colleges are spread across the University of Cambridge campus. Archives Hub currently has 12 contributors from the University, and we will be onboarding 13 more when the ArchivesSpace project is live. This is an exciting opportunity to unite the archives in one place and improve the harvesting of their data to Archives Hub to boost discovery for researchers, members of the public and academics alike.
This blog post forms part of History Day North (at DCDC 2025), a day of online interactive events for students, researchers and history enthusiasts to explore library, museum, archive and history collections across the UK and beyond.
Use Archives Hub, a free resource provided by Jisc, to find unique sources for your research, both physical and digital. Search across over 3.3 million descriptions of archives, held at over 400 institutions and organisations across the UK.
The Great Britain Steam Train. Photo by Christopher More on Pexels.
History Day North 2025 takes place in Durham, in the North-East of England, which is very fitting for our theme! Railway 200 celebrates rail history, beginning with a landmark journey that took place in the NE region:
“on 27 September 1825, George Stephenson’s steam-powered Locomotion No. 1 travelled 26 miles between Shildon, Darlington and Stockton, carrying hundreds of passengers to great fanfare. It set in motion a train of events that changed the world forever.” Rail 200 timeline
So, we’re exploring a fascinating range of archives relating to railways, train travel and more – all board!
Collections of George Stephenson and Robert Stephenson (1790-1883): George Stephenson, the ‘Father of the Railways’, was an English civil engineer and mechanical engineer who built the first public inter-city railway line in the world to use steam locomotives, the Liverpool and Manchester Railway which opened in 1830. His son, Robert Stephenson, worked with him and also developed his own independent career in civil and mechanical engineering. His work took him to South America where he helped to develop infrastructure there. George Robert Stephenson, was George Stephenson’s nephew and also an engineer. Held by the Institution of Mechanical Engineers Archive.
Richard Badnall Papers (1832-1834): Badnall and his collaborator Richard Gill interested many prominent people, including George and Robert Stephenson and the Directors of the Liverpool and Manchester Railway, in his eccentric invention, ‘The Undulating Railway’. Comprises letters written to and by Richard Badnall, correspondence with the Patent Office including the original patent, and other documents relating to the invention. Held by University of Salford Archives & Special Collections.
Brunel Collection: Isambard Kingdom Brunel (1806-1859) papers: In 1833, Brunel was appointed Engineer for the Great Western Railway Company, where he carried into effect his plans for a broad gauge railway system. Despite the controversy of his decision, his work brought him great renown, and he was asked to design railways in Italy and to advise upon the construction of the Victorian Lines in Australia and the Eastern Bengal Railway. He worked on the system of atmospheric propulsion and attempted to use it on the South Devon railway in 1844, though it did not work in practice. Held by University of Bristol Special Collections.
Thomas Edmondson Collection (1831-1988): in 1836, he became station master at Milton (now Brampton) station on the Newcastle and Carlisle Railway. Milton was not a busy station, and Edmondson had plenty of time to apply his craftsman’s training to the improvement of ticket issue. At the time, railway staff would fill out tickets by hand, which proved impractical once passenger numbers grew significantly. A more efficient method of creating tickets was required, which would also ensure that fraud was limited. Edmondson decided to create an automated system. The Edmondson ticket became universal; in the UK, it was endorsed by the Railway Clearing House set up in 1842 as a condition of its membership and by the end of the 1840s nearly all major companies had joined. Edmondson himself died in 1851, but his family continued to run the highly-profitable business. Edmondson tickets continued to be used in the UK into the 1980s and are still issued by some heritage lines. Held by University of Manchester Library.
Online Resource:IMechE Virtual Archive (c 1720-1985): you can access the story of the world’s first railway to rely exclusively on steam power – the Liverpool and Manchester Railway. Photographs reveal how the Bhore Ghat incline, India was constructed and show where workers lived. Artefacts include unique carved railway tokens used by George Stephenson to travel the railway lines he helped to build. Provided the by Institution of Mechanical Engineers Archive.
Railway Companies and Rail Magnates
Records of the Glasgow District Subway Co, Glasgow, Scotland (1894): Glasgow was the third city in the world to build an underground rail system, after London, England, and Budapest, Hungary. In August 1890, the Glasgow District Subway Co was given authority to build a 6.5 mile long route under the streets of Glasgow. The circular line is formed of parallel pair of tunnels built by tunnelling or cut and cover. The system uses an unusual gauge of 4 feet (about 1200mm), with the tunnels just 11 feet in diameter. The underground was opened on 14 December 1896, but a collision that day meant that the network did not open again until 21 January 1897. Held by University of Glasgow Archive Services.
United Railways of the Havana & Regla Warehouse Records (1871-1975): Records of the United Railways of the Havana & Regla Warehouses Ltd. This company, which went into voluntary liquidation in 1954 after the purchase of its property by the Cuban Government, incorporated a number of smaller Cuban railway enterprises. Records for these subsidiary companies are included in the collection: Cuban Central Railways Ltd, Havana Terminal Railroad Company, Mariano & Havana Railway Company Ltd, Matanzas Terminal Railway Company, Western Railway of Havana Ltd. Held by: University College London Archives.
Railways collection (1856-1987), forming part of the Oury Archive (1897-1977): The Oury Archive holds material related to the life and business activities of Libert Oury (1869-1939), specifically during his time as the London office director of the Mozambique Company, and his involvement in the development of the Port of Beira, the Trans-Zambezi Railway (TZR), and the lower Zambezi bridge. Additional material relates to the directorships and business interests inherited by his only son Vivian (1912-1988). Held by: Borthwick Institute for Archives, University of York.
Stations, Lines and Networks
London underground train, Photo by Dom J on Pexels.
Drawings of the Midland Railway Extension to London St Pancras (1867-1871): the collection comprises 33 architectural and engineering drawings as used or designed by contractors to the Midland Railway, covering architectural elements of St Pancras and Finchley Road Stations, various bridges and approaches and the design and emplacement of working equipment such as cranes and traversers. It represents a very small part of what must have been a much more extensive set of drawings. Held by: National Railway Museum Archive.
Online Resource:Rail Map Online (circa 1750 – to date): a free website that provides interactive maps of past and present to explore UK and Ireland railways, US West railroads and UK and Irish canals and more. There are options for exploring via layers (such as narrow guage, Metro, historic tramways), legend (companies) and places (stations). The resource also features a range of tools, including ability to select which coordinate system to display positions with.
Jonathan Backhouse & Company, Darlington (1774-1896): Jonathan Backhouse died in 1826, leaving the business to his sons. The eldest, another Jonathan (1779-1842), is remembered best for his involvement in the pioneering Stockton and Darlington Railway. He argued in favour of a railway during a public meeting at Darlington town hall in 1818, stressing its commercial advantages over those of the conventional option, a canal. The first track was laid in May 1821, and the completed railway opened on 27th September 1825. Jonathan served as the company’s first treasurer until 1833. Held by: Barclays Group Archives.
Railway Image Collection (1904-1930): Edward Alan Chard was chief locomotive draughtsman Eastleigh Works, British Railways, Southern Region. He was an avid collection of railway items. 29 series of postcards and some drawings of British and international locomotives. Held by: Institution of Mechanical Engineers Archive.
Mumbles Railway Records (1804-1959): The Swansea and Mumbles railway ran from Swansea to Mumbles. In 1804 the Oystermouth Railway and Tramroad Company was incorporated and work began on building the line. In 1806 goods traffic began to pass over the line in waggons pulled by horses. The main cargo was limestone at this stage. However, as Mumbles began to lose its industrial character and started to develop as a tourist resort, freight lessened and in 1807 the line became unique as providing the first regular rail passenger service in the world. Held by: Swansea University Archives.
Bridges and Tunnels
Forth Bridge, Edinburgh, Scotland, Great Britain. Photo by Keith Proven on Pexels.
Records of P & W MacLellan Ltd, steel stockholders, Glasgow, Scotland (1626-1989): In 1878 the whole of Glasgow was shaken by the collapse of the City of Glasgow Bank, with whom P & W MacLellan had an account. Fortunately, orders began to pick up again in 1879 with Indian State Railways ordering 48 bridges and William Arrol & Co, a Glasgow bridge builder, placing an order for 12,000 tons of steel for the Forth Railway Bridge, Scotland. The Forth Bridge contract however was cancelled when a storm hit and destroyed the Tay Bridge, Scotland. The demand for railway bridges was not greatly dented by the Tay Bridge disaster and in February 1880 the South Indian Railways ordered a further 48. It was also in this year that Walter MacLellan purchased the Carntyne Iron Co, Glasgow, in order to ensure a steady supply of iron. In 1883, the firm won the contract to supply the approaches for a completely redesigned Forth Bridge. Held by: University of Glasgow Archive Services.
Beachley – Aust Ferry and Severn Rail Tunnel Timetables and Correspondence: The Beachley – Aust Ferry provided a crossing over the River Severn between South Wales and England from Beachley and Aust, Gloucestershire. From 1931 the ferry was run by Old Passage Severn Ferry Company Ltd. The ferry service was replaced by the Severn Bridge in 1966. The construction of the Severn Rail Tunnel began in 1873 and the tunnel was opened in 1886. Timetables of Beachley – Aust Ferry and trains ferrying cars through the Severn Tunnel with correspondence, 1966. Held by Gwent Archives / Archifau Gwent.
The “railway tunnel” at Harlaxton Manor was built at the same time as the north wing of the house (completed 1845-1850). The tunnel is on two levels meeting the north wing at the 2nd and 3rd floors. The presence of coal dust in the service shafts provides witness that the tunnel was in use for some time and in the 1937 Contents Sales Catalogue Lot 855 describes a railway coal trolley 4ft. 6ins. by 3ft. by 3ft. 6in. high. What seems to be unique about the service tunnel at Harlaxton is that it joins the house at high level, using gravity to deliver the goods rather than the use of expensive and time consuming hoisting equipment to haul goods up to the higher level. The tunnels are also home to several species of bats, with surveys of hibernating bats carried out annually, in January and February, by the Lincolnshire Bat Group. During the hibernation season (November to March) visitors are not allowed to enter the tunnels. The folder of material forms part of the collection ‘Harlaxton Manor Gardens, Conservatory, Walled Garden and Railway Tunnel‘ (1838 to present), held by Harlaxton Manor Archives.
Souvenir of the inauguration of the railway bridge over the South Channel of the River Niger by H.E. Sir Frederick Lugard at Jebba, Nigeria, West Africa (1916): Album containing general views of the bridge at Jebba, photographs taken during the opening and of the wreck of the ‘Dayspring’ which sank in 1857. Railway construction started in earnest in Nigeria in 1893 with the building of the Lagos Railway running north from Lagos to Ibadan. In 1907 work was started by the Northern Nigeria Administration on the Baro-Kano line which was completed in 1911. The Lagos line was then extended northwards to join the Baro-Kano line at Minna, but until the completion of the bridge at Jebba, trains still had to be ferried across the Niger. The opening of the bridge by Sir Frederick Lugard on January 31 1916 finally connected Lagos and Kano on a direct line of 705 miles. Held by: Royal Commonwealth Society Library.
Travel Journal of Rev. John Warner: a detailed travel journal from 1890, compiled by Rev. John Warner (1860-1933), describing a voyage aboard the SS. City of Chicago from Liverpool to New York, and a subsequent tour of the north-eastern United States and Canada, encompassing Dayton (Ohio), Buffalo, Niagara Falls, Toronto, Montreal, Lake Champlain, Saratoga Springs, etc., between May and November 1890. The journal is an important source for nineteenth-century American studies, offering a perceptive visitor’s comments on the condition of the north-eastern United States and Canada during a period of rapid industrial, economic, social development. The journal is also valuable for studies of trans-Atlantic passenger shipping and the railways of the U.S. and Canada. Held by: University of Manchester Library.
The Records of the Traveller’s Aid Society (1885-1939): The Travellers’ Aid Society was initiated in 1885 by the Young Women’s Christian Association to aid female passengers arriving at ports and railway stations, where they were met by accredited station workers who reported to the Travellers Aid Society Committee. Held by: Women’s Library Archives.
The diaries of Thomas Sopwith (1803-1879), mining engineer, land surveyor and philanthropist in the north-east of England, cover the period 1828-1879. The collection includes both the original diaries, and a copy of the material held on 16 reels of microfilm. They form a meticulous account of the professional life of Sopwith, detailing his work, projects and his travels both for business and for enjoyment. The diaries also include sketches and illustrations of people, views, and buildings and often include descriptions of lectures and conversations with people Sopwith met on his travels. A particularly notable aspect of the diaries is Sopwith’s descriptions of journeys he made by rail, often along newly-opened railway lines in a period where rail travel was in its early stages. Held by Newcastle University Special Collections and Archives.
The Montparnasse derailment, 22 October 1895. The Granville–Paris Express overran the buffer stop at its Gare Montparnasse terminus. Photo by Pixabay on Pexels.
Railway Accidents Book (1922-1930): The London, Midland and Scottish Railway Co.Ltd. was created in 1923 from a merger of several railway companies, most notably the London and North Western Railway and the Midland Railway. The LMS was the largest of the four UK railway companies created under the terms of the Railways Act 1921, and it was the second biggest employer in the UK after the General Post Office. The LMS also claimed to be the largest joint-stock company in the World. A volume containing records of accidents to LMS employees during the period 1923-1930. Accident returns were required under the terms of the Factories Acts, and each report provides details of the employee, the nature of the accident and its consequences, the date and time of the accident, and a decision on the category of accident (misadventure, negligence by injured party or other party, and “other cause” – nearly all cases were judged to be misadventure). Held by University of Manchester Library.
National Union of Railwaymen (1894-1992): The collection, 87 volumes and 14 boxes, comprises 5 series: proceedings and reports, 1894-1987; Executive Committee minutes, 1966-1992; other papers; Branch papers including Norwich, Stockport district and Manchester. Held by: Working Class Movement Library.
International Transport Workers’ Federation: Reports on Africa, 1952-1975: The International Transport Workers’ Federation was founded in London in 1886 by European seafarers and dockers’ union leaders who realised the need to organize internationally against strike breakers. In 2001 it is a Federation of 570 trade unions in 132 countries, representing around 5 million workers. The ITF represents transport workers at world level and promotes their interests through global campaigning and solidarity. It is dedicated to the advancement of independent and democratic trade unionism, and to the defence of fundamental human and trade union rights. It is opposed to any form of totalitarianism, aggression and discrimination. Held by: Institute of Commonwealth Studies Library, University of London.
Associated Society of Locomotive Engineers and Firemen (ASLEF) 1861-2018: The Engine Drivers’ and Firemen’s United Society was founded in 1865 and claimed a membership of over 10,000 by 1866 when they made initial demands for a 10 hour day and payment of overtime as well as an increase in pay. With the establishment of the ASRS in 1872, there was some dilution of membership but the ASRS was regarded as too conciliatory and eventually the demand for a more militant and focused union led to the Associated Society of Locomotive Engineers and Firemen which was formed in Leeds in February 1880. Held by: Modern Records Centre, University of Warwick.
Photograph: Steam Engine “Lady of the Lake” at Crewe: The London and North Western Railway (LNWR) 7 ft 6 in Single 2-2-2 class was a type of express passenger locomotive designed by John Ramsbottom. The class is better known as the Problem class for the first locomotive built, or the Lady of the Lake class for the example that was displayed at the International Exhibition of 1862. The first examples were built shortly after the acquisition of the Chester and Holyhead Railway by the LNWR, and primarily saw use on the Irish Mail route from London to Holyhead. They were the first locomotives to be fitted with water scoops, which could refill the tender from water troughs between the tracks without stopping. Item (photograph) held by: Archifau Ynys Môn / Anglesey Archives.
Dinorwic Quarry Records (1809-1970): Slate quarrying at Dinorwig, Caernarfonshire, dates back to the 18th century. In 1787, Thomas Assheton-Smith (1752-1828) of the Faenol estate, leased his workings to the Dinorwig Slate Company, a partnership of two solicitors, Ellis and Wright, and Mr Bridges, a merchant. By 1809, only Wright remained, but he was joined by Hugh Jones, a Dolgellau banker, and Assheton-Smith himself. In 1824, the Dinorwig Tramway was opened, and the Padarn Tramway in 1843, allowing greater amounts of slate to be transported to Port Dinorwic on the Menai Strait. Railways to Porth Penrhyn and Y Felinheli, Caernarfonshire, were completed by 1852. Held by: Gwynedd Archives Service – Caernarfon Record Office / Gwasanaeth Archifau Gwynedd, Archifdy Caernarfon.
William Jack Collection: William Jack worked for the Chatterley Whitfield Colliery Ltd, 1928-1957. His family connections with the Chatterley firm go back to 1870. Jack wrote a history of the colliery, History of Chatterley Whitfield Railways. William Jack photographed and also collected photographs of North Staffordshire collieries, railways and mineral workings. Held by: Keele University Archives and Special Collections.
Fiction and Film
Train with smoke, [Highlands] Photo by Gabriela Palai on Pexels.
Papers of Brian Tinley Shepherd Simpson (1936-1963): Brian Tinley Shepherd Simpson (1912-1997), was a priest of the Scottish Episcopal Church, and was Canon of St John’s Cathedral, Oban 1978-80. He retired in 1980, thereafter being Honorary Canon of Oban Cathedral until his death on 10 February 1997. The collection comprises his voluminous correspondence, and wealth of material, including photographs and correspondence with the Rev. W. Awdry, author of Thomas the Tank Engine stories, relating to his passionate interest in railway transport. Held by: University of St Andrews Special Collections.
‘Orient Express’ (1991-2007), part of the Gavin Mark Stamp Archive: Gavin Mark Stamp (1948-2017) was a British architectural historian, writer, journalist, and campaigner. Stamp presented a number of television programmes for Channel 5, including a five-part architectural travel series ‘Gavin Stamp’s Orient Express‘, in which he travelled by train from London, via Vienna to Istanbul. The show examines art and architecture alongside the cities’ historical and political contexts, to present how the history of Eastern Europe is told through its buildings. WagTV produced the series with Steven Green as Director, and Eliya Aman as Producer. The series was filmed between 12 Jun-15 Jul 2006, and aired on Channel 5 in 2007. Held by: Paul Mellon Centre for Studies in British Art.
Photographs from Alfred Hitchcock’s film The Lady Vanishes, starring Michael Redgrave and Margaret Lockwood (1938): 1 folder of material, part of the Sir Michael Redgrave Archive. (1890-1996). Michael Redgrave was born on 20 March 1908, the child of actors Margaret (Daisy) Scudamore and Roy Redgrave. He studied at Cambridge University before becoming a teacher of modern languages at Cranleigh School, Surrey, where he spent much of his time directing and acting in amateur dramatic productions. His professional acting career began at the Liverpool Playhouse in 1934, where he met and married actress Rachel Kempson. Redgrave moved into films in 1938, starring in Hitchcock’s The Lady Vanishes. Held by V&A Theatre and Performance Collections.
More train-related collections!
The Great Train Robbery, 1963: material consists of manuscripts, typescripts, correspondence, press cuttings and list of banknotes recovered. Forms part of the Lord Edmund-Davies Papers (1908-1992) reflecting his career as a barrister and High Court judge, including papers deriving from court cases in which he was involved, 1936-1983; including the Great Train Robbery and the Aberfan Disaster Tribunal, 1966-1967, 1974. Held by: National Library of Wales / Llyfrgell Genedlaethol Cymru.
Timelapse Photography of Tunnel. Photo by Pixabay on Pexels.
Records of the Railtrack Private Shareholders Action Group (RPSAG, 2001-2006): RPSAG was formed at a meeting of Railtrack shareholders on 19 October 2001. The RPSAG website stated that the mission of the group was to ‘obtain a fair and just settlement for the 255, 000 private shareholders of Railtrack who lost millions when their company was forced into administration by the government’. Railtrack was a group of companies that owned track, signalling, tunnels, bridges, level crossings and stations that made up the British Railway System. It was placed into railway administration under the Railways Act 1993 on 7 October 2001 following an application to the High Court by the then Transport Secretary Stephen Byers. Held by National Railway Museum Archive.
Join our mailing list: to receive updates about the latest collections and contributors on Archives Hub and tips for using archives in your research – visit our jiscmail list to sign up
Aberlour Children’s Charity began as an orphanage in 1875, founded by Canon Charles Jupp in Aberlour, Scotland. Originally established to care for “mitherless bairns,” the orphanage grew into one of Scotland’s largest children’s institutions, housing up to 500 children at its peak. Over time, the charity evolved, shifting from large-scale residential care to more tailored support services for vulnerable children, young people, and families across Scotland.
Exhibition panels on the University Library walls.
The archive of the Trust, dating right back to the foundation of Aberlour Orphanage, was transferred to the University of Stirling in 2021 as part of a research project between the University of Stirling and the University of Osnabrück entitled ‘Back to the Future: Archiving Residential Children’s Homes’ (ARCH). This research project was supported by the Arts and Humanities Council and the German Research Foundation (Deutsche Forschungsgemeinschaft DFG) and aimed to explore and improve how the everyday group care experiences of children and young people in residential care are captured and preserved. To fully explore the possibilities, the project team worked in active partnership with young people and care experienced adults as well as using the Aberlour Archive as an example of the kinds of records which have historically been created, kept and made available to those who are care experienced.
Part of the Aberlour Children’s Charity Archive in our stores.
The cataloguing of the collection was made possible through the ‘Archives Revealed’ funding scheme, which was jointly awarded by The National Archives, The Pilgrim Trust and the Wolfson Foundation in 2021 and allows archive services to make significant collections accessible that otherwise would be difficult to catalogue using existing resources. After two fantastic Project Archivists, Jenny and Jennifer, had sorted, conserved and created a full catalogue for the archive, it was launched officially in 2022 with the donation of the personal collection of a former resident of the orphanage.
During this project we were also able to digitise sets of key historical records in the collection to support research. These records can be found embedded in our online catalogue, including files in the photograph series which contain a striking visual record of Aberlour and issues of the subscriber publication Aberlour Orphanage Magazine, rich in detail and notorious for being rose-tinted despite its blue colour, earning it the nickname ‘the little blue book of lies’ among the children!
In 2025, this incredible organisation proudly celebrates its 150th anniversary and the University Archive and Special Collections is supporting a range of activities and events planned by Aberlour throughout the year. It has been wonderful to support the present day charity in using the archive to tell the story of Aberlour and the tens of thousands of children and young people who have been supported by the organisation in its long history.
Key among the anniversary celebrations is an exhibition entitled ‘Aberlour: Now and Then’ which opened at the Strathspey Visitor Centre in Aberlour. Combining historic photographs and unique and striking objects from the archive – including the original clock from the orphanage in Aberlour – the exhibition speaks to the rich history of the institution and hints at its role in providing records for care experienced people with which they can evidence their lives and relate their childhood.
The exhibition closed at Strathspey and is now open to all in the University of Stirling Library until 31st August 2025. For a sneak preview of material on display, you can watch a video of Aberlour staff visiting the archive to conduct some research for their anniversary celebrations.
Some of the wonderful items from the archive on display in the University Library, chosen by Aberlour staff to tell their story.
Rosie Al-Mulla Taylor Assistant Archivist University of Stirling Archives & Special Collections
2025 marks 200 years of technical and professional education in Huddersfield, celebrating the establishment of Huddersfield’s Scientific and Mechanic Institute in 1825. This organisation was set up to bring the “acquisition of useful knowledge” within the reach of all, particularly the trading and working classes. Whilst our institution was not founded in 1825 (the University’s oldest predecessor dates back to 1841), Heritage Quay, as the holder of the University archives, is well placed to help tell the broader story.
Poster advertising classes at the Huddersfield Mechanics Institute, a predecessor of the University.
Whenever there is a significant anniversary related to the University the archive team are usually involved. For the University’s 175th birthday in 2016 one of the team worked with the Vice-Chancellors Office and academic researchers to support the production of reference materials, tours and a pop-up exhibition. We worked on a printed trail of campus, and timeline. Whilst our contribution was significant, it was supplementary to the rest of the activities.
2025 project
This time we are taking the lead through a new exhibition ‘The Town that Taught Itself’, which tells the story of the University, its predecessors, and the connection with the people of Huddersfield. This article will explore the approach we have taken and the impact of the work.
Broadly, we have used allocated exhibition development time to go back to the archives and conduct new research in aid of telling a richer and more diverse story about our origins. This has taken a few forms; we have confirmed every key institutional date with a link to the appropriate place in the catalogue, undertaken archival research and conducted a location audit of the main University collection (which is around 1,100 boxes).
The Ramsden Building, the first space that the University built on its Queensgate campus in the 1880s.
Exhibition development
The curator’s approach to exhibition development has not merely been to provide a synthesis of previous histories, illustrated with archival documents, but instead to produce new research.
There are three notable examples:
They have identified the names of the five original founders of the University for the first time using archival collections, secondary sources and digitised census returns. Previously histories of the institution have focussed on their benefactor Frederick Schwann but for the first time the real people behind the story have been put in the spotlight. You can read more about that here.
The exhibition will feature a map of around 30 locations across Huddersfield which the University and its predecessors have used since 1841, highlighting the importance of the institution to the town.
The exhibition acknowledges all of the University’s predecessor organisations. Research time has been dedicated to investigating the relationships between the six organisations identified as merging to form the University across a 110-year period. These connections have been clarified, and in some cases, celebrated properly for the first time.
Placements
Underpinning the project is the contributions of two placement students: one from the University (who undertook the locations audit) and one external. The external placement, which was for 16 weeks, was particularly essential to the success of the project as they were able to spend significant time researching and confirming facts and details of the University’s history and flagging them for the exhibition. You can read more about the student’s experience here.
External Placement Student George who undertook research into the University’s administrative history.
Impact
As the year has developed, the University has looked to the archive service for material for news stories, for general information and for support relating to the history of the University. The effect of this has been to place the archive and the collections at the heart of the programme. The exhibition will be signposted during graduation and in the 2025/6 welcome week for new students in September, which will raise our profile internally.
The original research has resulted in a Zooniverse project which will improve knowledge about the collection and the University’s history. This project would not have been initiated without the curator’s research. The outcome of this will be that the catalogue will be more accessible and representative of the collections.
Front cover of 1884 Members Book for the Huddersfield Mechanics Institute (HUD/SR/1).
These are all positives, but the resources dedicated to the project have had an impact on the service. Before the project began, there was an acknowledgement that significant resources would be required for it to be rigorous and of sufficient quality. The use of a placement student to underpin the historical research and catalogue development was thus a key requirement; but the service also made the decision that the exhibition curator’s time would be dedicated to the project, reducing capacity in other areas. The subsequent impacts and the benefits to the service will be a useful model as we work with the Students’ Union on their centenary in 2027.
Research for the exhibition will be used to improve catalogue data on our online catalogue. In the future, this information will also be exported to Archives Hub to reach more researchers.
The Town that Taught Itself
The exhibition opened to the public on Tuesday 27 May and will be on display until the end of September. Find out more about how to visit.
Dave Smith, Public Engagement Officer Heritage Quay University of Huddersfield
Related
Collection descriptions on Archives Hub related to the University’s history or archives:
The Stationers Company started out as a ‘mystery’, or craft association, in 1403. This was late for a traditional City company, reflecting the relatively lowly status of the Stationers’ trades: scribes, limners and book-binders were considerably less essential to the economy than workers of metal and leather, or provisioners of meat and salt. By the end of the century, however, the Stationers’ fortunes had been transformed by an unforeseen turn of events: Caxton’s introduction of the printing-press to England.
The print revolution meant that ideas could be disseminated at an unprecedented rate, and its political implications were not lost on the authorities. In 1557, Mary Tudor, anxious to shore up her precarious reign, granted the Stationers a royal charter of incorporation which not only allowed them the civic privileges enjoyed by other Livery Companies, but also awarded them extraordinary control over English print.
Leaf of the Inspeximus Exemplification of Charter of Incorporation issued at the request of Charles II, 1667. The Company’s copy of its original Charter has been lost. Stationers’ Company Archive, TSC/A/01/01/02
Integral to the Stationers’ policing of the printing trade was the maintenance of a register, listing all titles officially licensed for publication, alongside the name of the publisher and date of publication. This established the publisher’s right to print (or ‘copy’) a work, and is often cited as an early version of copyright. It also commodified that right, which could be sold, transferred or inherited. Spanning several volumes and nearly four centuries, the Stationers’ Register has survived to provide us with an unparalleled record of early English print culture. Here we look at a selection of entries to understand how concepts of naming, anonymity and authorship developed over time.
This first example shows the entry of copy of the first printed work which we know to be written by Shakespeare. This is the long poem Venus and Adonis, registered in 1593, while London theatres were closed due to an outbreak of bubonic plague. Significantly, Shakespeare’s name does not appear in the entry. At this period, the writer of a literary work was a relatively minor player in its production, selling the title to the publisher for a one-off fee. From then on, it was entirely the property of the publisher (in this case Richard Field) with whose name the work was linked.
Venus and Adonis entered for Richard Field, 18 April 1593. Stationers’ Company Archive, TSC/F/01/01
While the Stationers’ Register secured the publisher’s financial interests in a work, it also fulfilled the surveillance role envisioned by Mary Tudor and her successors. This crossed-out entry is a case in point. William Prynne’s Histriomastix, a turgid diatribe against Restoration theatre, was originally registered in 1630. However, Prynne didn’t send it to press until late 1632, timing his virulent attack on female actors to coincide with the stage debut of Charles I’s consort, Henrietta Maria. Not noted for his sense of humour, Charles responded by having Prynne fined, pilloried, imprisoned and mutilated. Joining him on the pillory was the publisher named in the Register, Michael Sparke, who was also heavily fined and suspended from the Livery of the Stationers’ Company. And, as the Register shows, the license for publication was firmly withdrawn.
Histriomastix by William Prynne, entered for Michael Sparkes, 16 October 1630. Stationers’ Company Archive, TSC/E/06/03
By the end of the seventeenth century, political changes removed the legal obligation to register publications with the Stationers’ Company. Entry in the Stationers’ Register still offered legal protection from plagiarism, however, and possibly also reputational gain. The Interesting Narrative of the Life of Olaudah Equiano, Or Gustavus Vassa, The African was registered at Stationers’ Hall on its first publication in 1789. Olaudah Equiano (c. 1745–1797) was born in west Africa, the son of an Igbo dignitary. At the age of eight he was kidnapped by slave raiders, and subsequently enslaved several times before he managed to buy his emancipation. In the late 1760s he came to London, where he campaigned for the abolition of slavery, and for fairer conditions for London’s Black community.
The Interesting Narrative of the Life of Olaudah Equiano, Or Gustavus Vassa, The African, entered for the author, 25 March 1789. Stationers’ Company Archive, TSC/E/06/11
Equiano’s use of two names in his authoring of the book is significant. In the book, he explains that Gustavus Vassa was the name given to him by his ‘captain and master’ on board the slave ship that first carried him to England. But he also recounts that as a child he was named ‘Olaudah, which in our language, signifies vicissitude or fortune, also, one favoured, and having a loud voice and well spoken’. Reclaiming that name is part of reclaiming his identity and dignity from the dehumanising narrative enacted by enslavement.
Frankenstein, or, The Modern Prometheus, entered for Lackington & Company, 15 January 1818. Stationers’ Company Archive, TSC/E/06/18
Our last entry from the Stationers’ Register is for another seminal work: Frankenstein, or, The Modern Prometheus, registered on 15 January 1818. One of the most influential works of literature in the English language, spawning numerous adaptations and re-imaginings in every medium and genre (including over sixty films), the book was originally published anonymously. This was not unusual for novels at the time, particularly those written by women, whose work faced an additional level of critical hostility. An early review of Frankenstein typifies the prevailing attitude: ‘We need scarcely say, that these volumes have neither principle, object, nor moral… The writer of it is, we understand, a female; this is an aggravation of that which is the prevailing fault of the novel; but if our authoress can forget the gentleness of her sex, it is no reason why we should; and we shall therefore dismiss the novel without further comment.’ (British Critic: And Quarterly Theological Review, ser.2 v.09 yr.1818. London: Printed for F. and C. Rivington, digitised by the Hathi Trust and accessed at https://hdl.handle.net/2027/uc1.aa0001508613). Ironically, the subsequent disclosure of Mary Shelley’s authorship was greeted with disbelief by other critics, who refused to accept that this young woman was capable of writing such an imaginative and well-executed book.
Volumes of the Stationers’ Register for the years 1554 to 1842 are held at the Stationers’ Company Archive, alongside a wealth of other records bringing print history – and London’s history – to life. Records can be consulted at the Tokefield Centre, the Company’s dedicated archive centre. For more information on our collection, and on how to access the Stationers’ Company Archive, visit our website and our online catalogue.
Dr Ruth Frendo, Archivist The Worshipful Company of Stationers and Newspaper Makers
“It’s only when one is obliged to ask oneself quite fresh questions about what one is doing, that one really starts to learn.” Reginald Revans
Action learning is an approach to problem solving which continues today to be an effective and well-used method. Rather than prioritising ‘expert knowledge’ handed down from higher-ups, the action learning approach values knowledge exchange, asking questions, and reflection.
Reginald Revans (1907-2003) pioneered the action learning movement and continued to preach its values, travelling and lecturing far into his old age. Although it has had lasting power, action learning wasn’t met with praise at the time of its conception, when business minds in the UK looked up to academic principles and expert knowledge. In this environment, Revans’ idea of a meeting of minds across the business hierarchy wasn’t highly favoured. However, his ideas endure and today the principles of action learning are used in the fields of business, industry, education, social work and many more.
The University of Salford archives holds The Revans Collection for Action Learning, a wide collection of materials about Revans, including his published books, personal papers and correspondence. The full catalogue for this collection can be found online. Among the collection are dozens of large flipcharts which Revans himself drew and used during lectures and meetings to display his data and figures. These flipcharts have recently been digitised and are now available on Salford Digital Archives.
Archive image of Reginald Revans, pioneer of the Action Learning movement.
The flipcharts take us on a journey through the many sectors Revans applied action learning to, beginning with the coal mining industry in the late 1940s. Revans was the Director of Education for the National Coal Board, and this is where he developed the theory of action learning. Rather than holing up in boardrooms having meetings, Revans wanted to get first-hand experience and knowledge from the miners and chose to begin his work at the coalface instead.
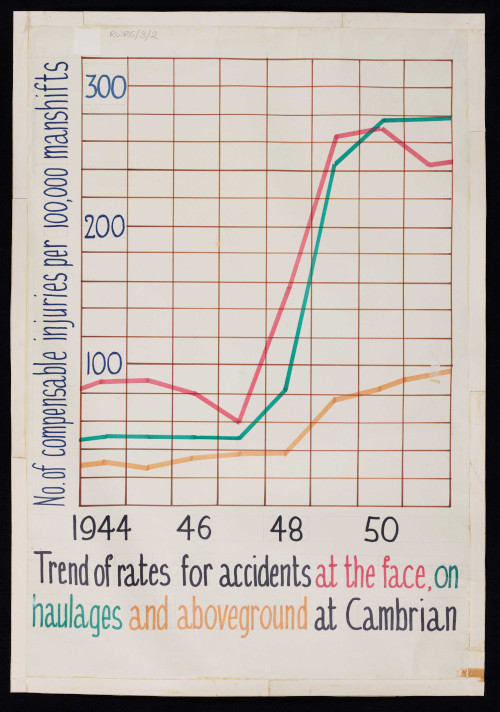
Revans encouraged pitworkers and managers to interface together and learn from each other’s experiences. He tracked trends in figures such as wages costs, number of accidents, and tonnage per man lost in disputes. But we can see from the collection that he was also interested in more qualitative data, such as responses of coal miners to different types of task structures or working group sizes. Pits that adopted an action learning approach were able to boost their productivity by up to 30%.
Digitised graph showing rates of accidents and compensable injuries at Cambrian coalmine.
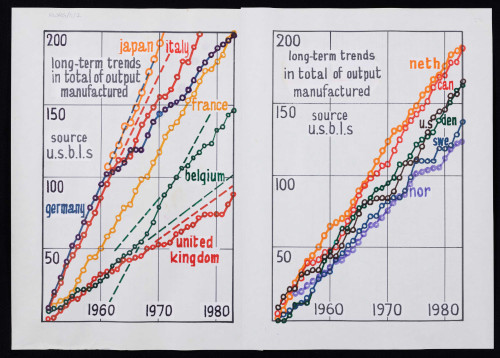
The next stop in Revans’ career takes us across to Belgium, where he headed up the Inter-University Programme. This was a project to increase Belgium’s economic productivity, which was low at the time. Revans worked with major universities and corporations to adopt an action learning approach to economics which majorly boosted the nation’s economy. Revans was later honoured by the King of Belgium for his efforts. During this project, the flipcharts become incredibly detailed and meticulous. As he tracks the economic progress of several countries, we can see his artistic side shining through in these colourful displays of data.
Digitised graphs showing manufacturing trends from the 1950s to the 1980s in various countries.
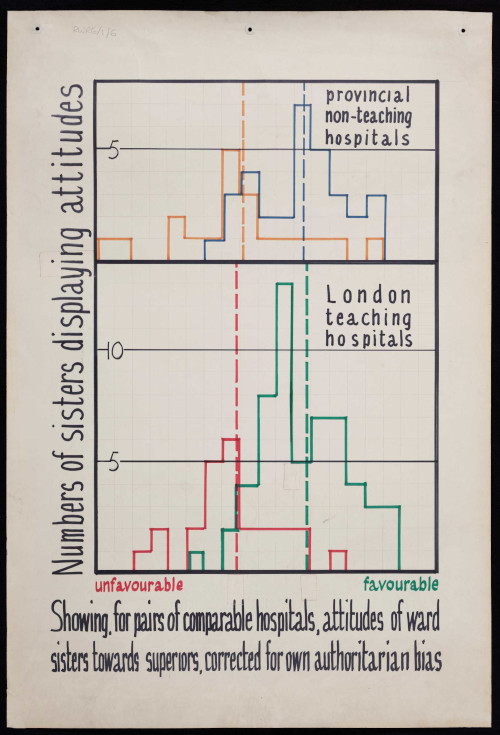
The Hospitals Internal Communications Programme saw Revans bring action learning theories into hospitals in London to improve both patient and staff experience. Like in the mines, Revans looked at numbers and figures, as well as opinions and feelings, to gather the data he needed. The collection includes graphs tracking trends such as ward sisters’ attitudes, length of patient stays and volunteer management.
Digitised bar chart showing attitudes of ward sisters in different types of hospitals.
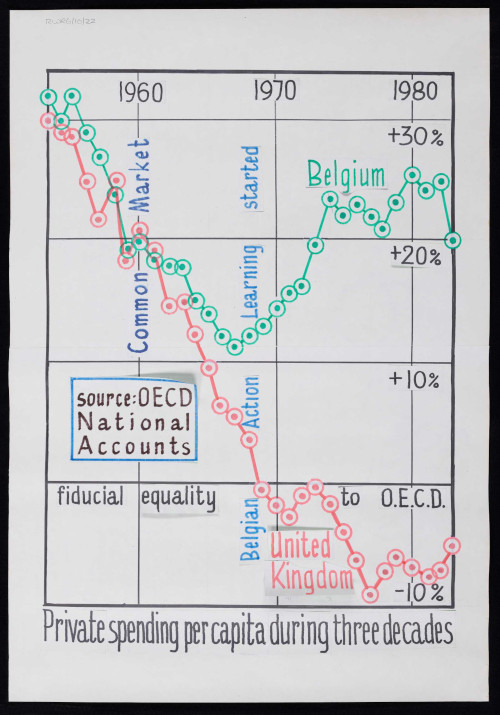
The collection also contains two videos of Revans being interviewed at 83 years old about action learning. We presume, due to the presence of a cat in his lap, that the interview takes place in his own home. Revans talks through the basic principles of action learning and uses some of his flipcharts (including the one below) to show how he has applied it in various fields. His quick wit and sense of humour can be seen in these videos, showing a personal side to a great academic mind.
Digitised graph comparing private spending per capita in Belgium and the UK from the 1950s to the 1980s.
Through The Revans Collection for Action Learning, we can gain an insight into the work and personality of Reginald Revans. The data alone shows the improvements to efficiency he was able to implement in several different fields, however the drawings themselves also show us a lot. His artistic nature is revealed through the diligently hand-drawn, consistent graphs and tables, which contain such detail. In a time where we can produce a visualisation of data at the click of a button, it’s hard to imagine the time Revans must have spent on them, showing his real passion and dedication to his model of action learning.
On its shelves can be found a rich assortment of documents, photographs, drawings, maps and plans that primarily document British-led archaeological projects from World War II onwards. These include excavations at Hellenistic and Roman sites in Libya like Euesperides (Benghazi), Sidi Khrebish (Berenice), Cyrene, Lepcis Magna, and Sabratha. The archive also holds valuable material from ground-breaking multi-disciplinary surveys in the pre-desert valleys of Tripolitania and the Saharan oases of Fazzan, as well as excavations at Islamic Barca (El Merj) and Medinet Sultan.
The British Institute for Libyan and Northern African Studies [BILNAS] Archive, University of Leicester.
To mark International Women’s Day, BILNAS is celebrating two influential archaeologists whose important work in North Africa forms part of its archive: Dame Kathleen Kenyon and Lady Olwen Brogan.
Dame Kathleen Kenyon
BILNAS/D5/12/7/8, Kathleen Kenyon and unidentified men at the basilica, Sabratha (1949-1951). The Kathleen Kenyon and John Ward Perkins Papers on Sabratha (1932 – 1992). The British Institute for Libyan and Northern African Studies [BILNAS] Archive.
Dame Kathleen Mary Kenyon (b. 1906 – d. 1978), was a leading British archaeologist known for her significant work at Jericho (Tell es-Sultan) and the Jewry Wall in Leicester, as well as her contribution to the development of excavation and recording techniques along with Sir Mortimer Wheeler.
The BILNAS Archive holds the records of Kenyon’s work at the site of Sabratha, a key Punic and Roman trading port on the Libyan Coast. There, alongside John Bryan Ward-Perkins, she refined stratigraphic excavation techniques to establish a chronological framework for the site.
BILNAS/D5/12/1/14/2/18, Panoramic view of Sabratha (1949). The Kathleen Kenyon and John Ward Perkins Papers on Sabratha (1932 – 1992). The British Institute for Libyan and Northern African Studies [BILNAS] Archive.
By developing a typology of pottery corresponding to different strata, Kenyon successfully reconstructed the site’s occupational history. This approach allowed her to trace the evolution of Sabratha’s central area, from its earliest Phoenician trading encampments to the emergence of a more permanent settlement around the fifth century B.C.E. This work not only demonstrated the effectiveness of stratigraphic dating but also provided a crucial training ground for students, many of whom had been unable to gain hands-on experience in the field since the 1930s.
BILNAS/D5/12/6/4/1, Photograph of pottery finds from Sabratha (1948-1951). The Kathleen Kenyon and John Ward Perkins Papers on Sabratha (1932 – 1992). The British Institute for Libyan and Northern African Studies [BILNAS] Archive.
Kenyon was deeply committed to archaeological education, the training of women in particular, as reflected in the composition of the expedition team at Sabratha. Many of the 25 students working at the Sabratha site did so under Kenyon’s direct guidance, and would later work with her again in Jericho. Kenyon’s emphasis on rigorous training and stratigraphic methods was shared by her colleague Olwen Brogan, who worked alongside her at Sabratha.
BILNAS/D5/12/7/19, Photograph of the excavation team assembled (1949-1951). The Kathleen Kenyon and John Ward Perkins Collection. The British Institute for Libyan and Northern African Studies [BILNAS] Archive.
BILNAS/D5/3/1/1, List of personnel for Sabratha exhibition (1948). The Kathleen Kenyon and John Ward Perkins Papers on Sabratha (1932 – 1992). The British Institute for Libyan and Northern African Studies [BILNAS] Archive.
Lady Olwen Brogan
BILNAS/D41/2/7/2/58, Photograph of Olwen Brogan with Dr Vergara-Caffarelli at Ghirza (1950s-1970s). The Olwen Brogan Papers (19th cent-1989). The British Institute for Libyan and Northern African Studies [BILNAS] Archive.
Lady Olwen Phillis Frances Brogan (later Hackett) (b. 1900 – d. 1989), was a pioneering British archaeologist whose meticulous field work reshaped the study of classical sites in Libya. Renowned for her contributions to excavation methodology and historical interpretation, she played a pivotal role in documenting North Africa’s rich archaeological heritage. She was also instrumental in establishing and managing the Society for Libyan Studies (now BILNAS).
Brogan’s first expedition to North Africa was in 1948 with the British School at Rome. Under the direction of Kathleen Kenyon, she supervised the excavation of a residential block behind the East Forum Temple at Sabratha. Applying the stratigraphic techniques, she had learned under the direction of Sir Mortimer Wheeler at St. Albans (Verulamium) and alongside Kenyon – Brogan produced some of the most well-dated sequences on the site. The ‘Casa Brogan’, as it came to be known, remains one of the finest examples of meticulous excavation from its time, setting a benchmark for future excavations in the region.
BILNAS/D5/12/1/15/4, Photograph of mosaic flooring and wall at Casa Brogan, Sabratha (1984). The Kathleen Kenyon and John Ward Perkins Papers on Sabratha (1932 – 1992). The British Institute for Libyan and Northern African Studies [BILNAS] Archive.
Building on her work at Sabratha, Brogan returned to Libya in the 1950s, conducting work at the Roman city of Lepcis Magna alongside John Bryan Ward-Perkins. However, it was in the less-explored frontier regions of Tripolitania, rather than its great coastal cities, that Brogan would make her most enduring scholarly contribution.
Shifting her focus to the pre-desert region in 1953, Brogan dedicated considerable time to surveying, excavating and documenting the Romano-Libyan settlement at Ghirza. Her meticulous stratigraphic work provided ground-breaking evidence that challenged prevailing scholarly assumptions. She successfully argued that Ghirza was a Libyan settlement during the Roman Period, identifying earlier phases of construction and emphasising the contribution of the local Libyan population in shaping this site. Her research continues to inform contemporary studies of Libya’s classical and indigenous heritage.
BILNAS/D41/2/7/8/3/2/46, Photograph of Olwen Brogan making a squeeze of inscription at Ghriza (1950s-1970s). The Olwen Brogan Papers (19th cent-1989). The British Institute for Libyan and Northern African Studies [BILNAS] Archive.
Throughout the 1960s, Brogan was instrumental in advocating for a society that would encourage and coordinate the work of British Scholars in Libya. Her efforts culminated in the establishment of the Society for Libyan Studies in 1969, where she served as its first Secretary. The Society’s mission was to ‘‘encourage, support and undertake the study of, and research relating to, the history, antiquities, cultural and natural history of Libya and fields connected therewith’. This commitment to fostering scholarship on Libya and the wider Northern African region continues today under the society’s new name, BILNAS.
BILNAS/D25/1, The Society for Libyan Studies, First Annual Report (1970). Libyan Studies – The Journal of BILNAS (1969 – 2011), The British Institute for Libyan and Northern African Studies [BILNAS] Archive.
Exploring the Archives
The BILNAS Archive is located within the School of Archaeology and Ancient History, at the University of Leicester. To access physical collections, please contact the BILNAS Archivist, Dr Anne Marie Williamson, at [email protected]. You can explore the archive catalogue via the University of Leicester here.
Digitised Collections
Kenyon’s Sabratha papers are now available online and open-access through the Archaeology Data Service, making these invaluable resources accessible not only to UK researchers, but also North African heritage professionals, academics, students and anyone interested in the region’s rich history. Brogan’s papers from Ghirza will be added to the online collection soon, and the digitisation of further collections is underway.
Stay Connected
Stay updated on news and events by visiting our website here.
Dr Anne Marie Williamson, Archivist British Institute for Libyan and Northern African Studies School of Archaeology and Ancient History University of Leicester
All images copyright The British Institute for Libyan and Northern African Studies [BILNAS] Archive, except the first image which is copyright University of Leicester. Reproduced with the kind permission of the copyright holders.
Next month, on March 8th – we celebrate International Women’s Day and to celebrate that we’ll be exploring how our archive informed us of the lack of female representation in our collection, and how we, at Ffotogallery, have used that information to make informed decisions going forward.
In April 2024, Ffotogallery appointed its first Archive Project Officer, and with the help of volunteers and local archivists – began to catalogue and digitise the gallery’s archive collection to make the history of Ffotogallery available via an online catalogue. None of this could have been possible without the generous funding from The National Lottery Heritage fund.
One of our cabinets, storing exhibition marketing materials, press clippings and paperwork, August 2024. Reproduction of copyrighted works is not permitted.
This digitisation project has allowed us to explore deep into our collections, something we did not have the resources to do before receiving the funding. It allowed us to look into the entire archive that Ffotogallery holds with material from Ffotogallery’s conception in 1978 to today, uncovering new information and details about Ffotogallery’s history, its relationship with photographers and its legacy.
Our student intern Amira scanning in press clippings, August 2024. Reproduction of copyrighted works is not permitted.
For the first time, The Valleys Project archive – a collection of over 400 photographs documenting the South Wales Valleys over five years (1985-1990) has been presented in the form of an online catalogue and can be viewed, in its entirety, all in one place. The Valleys Project collection has been available to view via in-person appointments to the Ffotogallery archive but now the public can access the full collection online for the first time since its conception in 1985.
The first issue we identified was how only one female photographer, Francesca Odell, was commissioned as part of the Valley Project over those five years, in comparison to the nine male photographers who were also commissioned as part of this project.
We then went through the number of female photographers and male photographers who have been exhibited at Ffotogallery since 1978, the lack of female photographers that had been exhibited was visibly noticeable.
Press cutting (1) from Ffotogallery’s archive, featuring articles on ‘The Womenshow’, an exhibition held at Ffotogallery in 1981. Reproduction of copyrighted works is not permitted.
Press cutting (2) from Ffotogallery’s archive, featuring articles on ‘The Womenshow’, an exhibition held at Ffotogallery in 1981. Reproduction of copyrighted works is not permitted.
To think about Ffotogallery’s future, its impact on photography and the legacy for future generations it’s crucial to look back at the gallery’s past, how Ffotogallery came to exist and the journey taken to get to where we are today. We look back with a critical eye, photography and how society regards women has come a long way from where we were when Ffotogallery first existed in 1978, but the issues that present themselves in our archive are still relevant today. As an organisation, we are always working on new ways to challenge these issues and break barriers and provide opportunities for underrepresented artists.
In October 2024, we celebrated the first Ffoto Cymru: Wales International Festival of Photography which opened in venues across Wales. In a society where women artists and photographers are still regularly overlooked, the first Ffoto Cymru pointed the spotlight towards female photographers and artists using photography. With the theme What You See is What You Get? The festival questioned how we see, understand and use images and how they shape our identities and culture, from historical archives to AI and modern technologies.
At the centre of Ffoto Cymru was a major survey of work from the last 50 years by Marian Delyth showing at Ffotogallery in Cardiff. Titled Darnau | Fragments, it examined the profound impact of Delyth’s photographic journey over the past five decades, documenting Welsh life and culture, and featured activism, social justice, and peace campaigns in Wales and beyond. The intimate look at Delyth’s work, seeked to solidify her position as one of Wales’s most influential artists and celebrates her significant contributions to the artistic and visual identity of Wales.
The other associated venues presented newly commissioned work by four younger female Welsh or Wales-based photographic artists – Ada Marino, Adéọlá, Holly Davey and Jessie Edwards-Thomas, who used archives from galleries and museums around Wales to inform their commissioned pieces . Finally, a collaboration with the Foto Féminas network (which provides a platform to increase the visibility of Latin American and Caribbean female/non-binary photographers) showcases work by Luiza Possamai Kons from Brazil and Julieta Anaut from Argentina and Lorena Marchetti, also from Argentina.
Our archive collection consists of Ffotogallery’s exhibition prints, artist books, marketing and promotional materials and press cuttings – from 1978 to the present day, we are always adding new items to our collections with each new exhibition.
As we continue to explore our collection and uncover new information about our past, we look forward to digisiting these materials and sharing our findings with you.
The archive is open Wednesday – Friday from 11.00am – 4.00pm, by appointment only. To arrange a visit please email [email protected].
Bethlem Museum of the Mind is dedicated to using the historic collections of the South London and Maudsley NHS Foundation Trust to display and discuss issues in mental health, and to celebrate the achievements of people dealing with severe mental health issues.
Raving and Melancholy (by Gaius Cibber, c.1676) in the atrium of the Museum.
The Museum is based in the former administration building of Bethlem Royal Hospital, today located in a 200 acre site in Beckenham, south London. Since 1948 the Hospital has been a specialist NHS psychiatric hospital, and today supplies 400 beds to the South London and Maudsley NHS Foundation Trust, which provides modern psychiatric care to those in need in the London Boroughs of Lambeth, Southwark, Lewisham and Croydon, as well as certain national services.
However, the Hospital has a past that stretches back over 750 years as Europe’s oldest specialist psychiatric hospital, across four different sites in London. Although there are many phases in Bethlem’s history, it’s early reputation for cruel treatment saw it christened ‘Bedlam’ by the Londoners living around it, and the entwining histories of the real place and the imagined place of chaos and confusion is something the Museum tries to unpick.
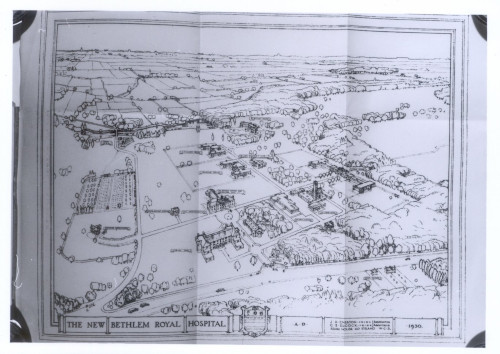
Drawing in black ink on white paper of hospital site and surrounding countryside.
The Museum of the Mind’s archive collections consist of the historic records of Bethlem Royal Hospital; The Maudsley Hospital, a specialist acute psychiatric hospital in south London which dates from 1923; and Warlingham Park Hospital, the Borough Asylum for Croydon, founded in 1903 and closed in 1999. These have been managed by a specialist archivist since the 1960s, and coexist in the Museum collections together with a collection of over 1000 artworks by patients, (viewable here), and more than 800 objects that reflect the history of the Trust.
The records for Bethlem date back to its incorporation as a civic charity in 1557 under the watchful eye of the Board of Governors of Bridewell and Bethlem Hospitals, a set of grandees drawn from the ranks of the City of London Corporation. The oldest set of records are the minutes of the Board of Governors, held under our reference BCB, and our oldest record of any patients of Bethlem is a rather unassuming list from 1598.
BCB-04, the first patient list from 4 December 1598.
As record keeping practices developed, one can see the emergence of something like a modern psychiatric hospital at Bethlem – admission records are created from the 1680s, and casebooks arrive in 1815. However all these records are in some ways problematic, as they express the patient experience through the lens of the Hospital, very often using out of date terminology and a contemporary attitude that seems woefully short of best practice today.
The Museum has therefore made the choice to try and address these shortcomings. One of the sections in the permanent displays looks at the limitations of language and medical jargon, especially around diagnosis. When the archives are used in the displays it is not done uncritically, but with an acknowledgement of the shortcomings of them as sources. Where we can, we have extracted the patient voice from smaller items in the casebooks, like letters and photographs, where a different, more personal, story can be found. The Museum also utilises the artwork it has collected to display, and celebrate, the voices of people with lived experience. Sometimes this voice directly clashes with the professional tone of the organisational record, but we believe that it is important to recognise a multiplicity of experience in this area. It’s also important to recognise that elements like ‘restraint’ (another section in the Museum) have both a past and a present in mental health treatment, and to speak of these issues as if they have vanished would be to hide a more complicated, if troubling, truth.
The ‘Labelling and Diagnosis’ section of the Museum.
The records in the archive cover 450 years of mental health treatment, and take up some 250 metres of shelving for plans, images, patient and staff records, as well as the committee records of the groups that administrated the hospitals. The records are catalogued to the Australian Series System, which is a little different to standard UK cataloguing practices, so what is on Archives Hub is really an indicator of what we hold rather than a comprehensive list – see the catalogue here.
In providing safe and professional storage and access the archivist fulfils the public records function for the NHS Trust, but also supports the displays of the Museum, the learning and outreach programme which spoke to over 3,000 students in 2023, and bespoke history projects like Change Minds, which worked with people with lived experience to investigate the lives of people who were treated in the Victorian Bethlem. We feel this work, in re-examining and investigating the lives of people who were in the hospital outside of the context of their mental health issues, to be amongst the most important things we do. You can see some of our blogs on this project here.
Letters taken from the casebook displayed in the Museum’s ‘Recovery’ section.
The Museum has put a wealth of historical resources online. The patient and staff records up to 1918 have been digitised and indexed on Find My Past and British Online Archives, allowing remote access to thousands of genealogists and academic researchers. The Museum has digitised some of its archives itself, most notably the Board of Governors Minute Books up to the 1800s, and the collection of Lantern slides of the Edward O’Donoghue, the Chaplain and first historian of the Hospital, which can be viewed via the catalogue under the series references BCB and LSC. There are also digital resources linked to the main website of the Museum, particularly in the ‘learning’ section, which deal with different times and hospitals: https://museumofthemind.org.uk/learning .
The Museum building onsite at Bethlem Royal Hospital.
The Museum is open Wednesday to Saturday 9.30am to 5.00pm without appointment and free to all visitors (last admission at 4.30pm). The archives are available by appointment with the archivist, potentially Monday to Friday 10am to 4.30pm. Our website covers all of this at https://museumofthemind.org.uk/ , and you can reach the archivist at https://museumofthemind.org.uk/contact (select ‘archives’ from the drop down menu).
David Luck, Archivist Bethlem Museum of the Mind Bethlem Royal Hospital