There are many ways of utilising the International Image Interoperability framework (IIIF) in order to deliver high-quality, attributed digital objects online at scale. One of the exploratory areas focused on in Images and Machine Learning – a project which is part of Archives Hub Labs – is how to display the context of the archive hierarchy using IIIF alongside the digital media.
Two of the objectives for this project are:
to explore IIIF Manifest and IIIF Collection creation from archive descriptions.
to test IIIF viewers in the context of showing the structure of archival material whilst viewing the digitised collections.
We have been experimenting with two types of resource from the IIIF Presentation API. The IIIF Manifest added into the Mirador viewer on the collection page contains just the images, in order to easily access these through the viewer. This is in contrast to a IIIF Collection, which we have been experimenting with. The IIIF Collection includes not only the images from a collection but also metadata and item structure within the IIIF resource. It is defined as a set of manifests (or ‘child’ collections) that communicate hierarchy or gather related things (for example, a set of boxes that each have folders within them, and photographs within those folders). We have been testing whether this has the potential to represent the hierarchy of an archival structure within the IIIF structure.
Creating a User Interface
Since joining the Archives Hub team, one of the areas I’ve been involved in is building a User Interface for this project that allows us to test out the different ways in which we can display the IIIF Images, Manifests and Collections using the IIIF Image API and the IIIF Presentation API. Below I will share some screenshots from my progress and talk about my process when building this User Interface.
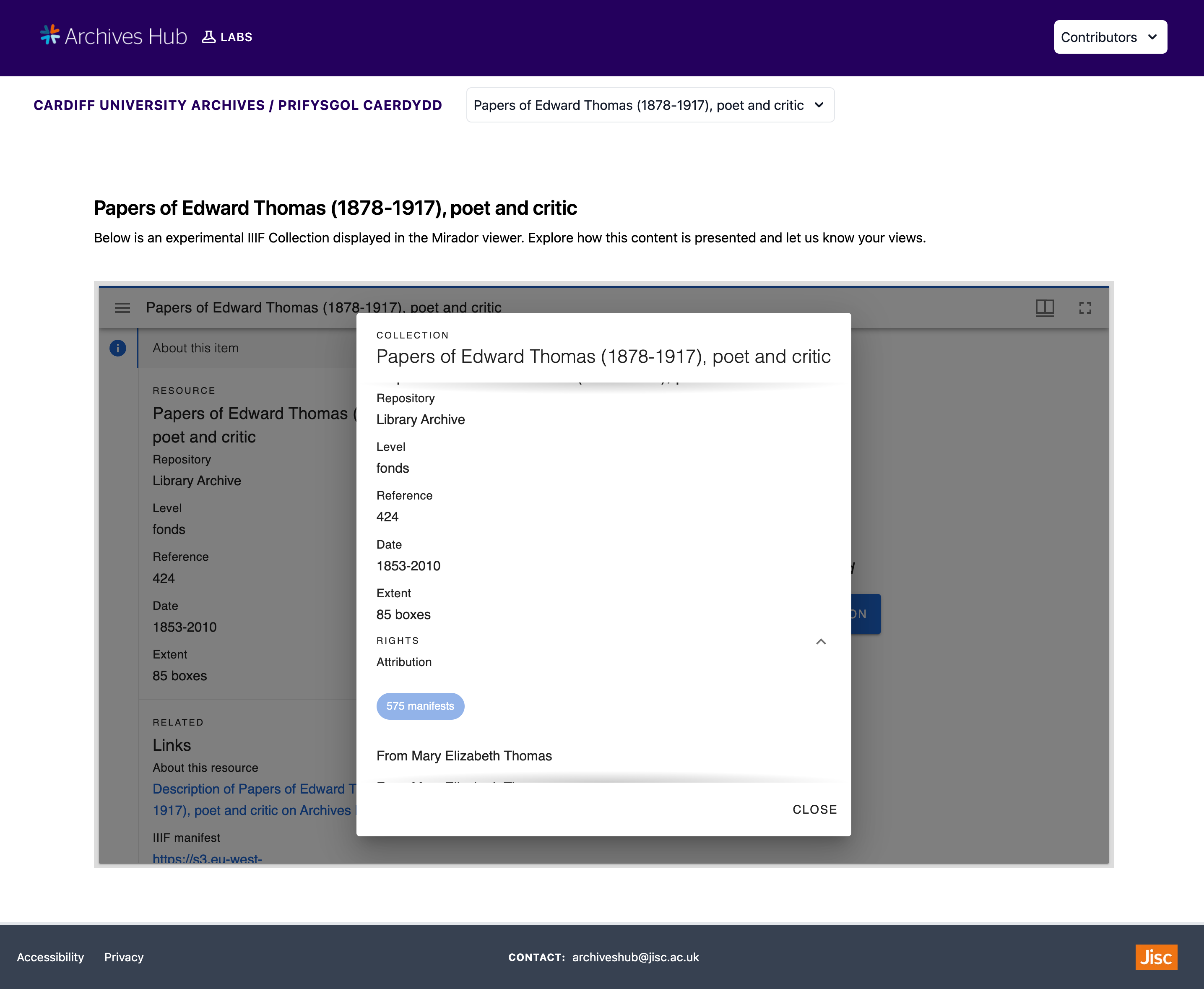
The homepage for the UI showing the list of contributors for this project.
The collections from all of our contributors that are being displayed within the UI using IIIF manifests and collections.
This web application is currently a prototype and further development will be happening in the future. The programming language I am using is Typescript. I began by creating a Next.js React application and I am also using Tailwind CSS for styling. My first task was to use the Mirador viewer to display IIIF Collections and Manifests, so I installed the mirador package into the codebase. I created dynamic pages for every contributor to display their collections.
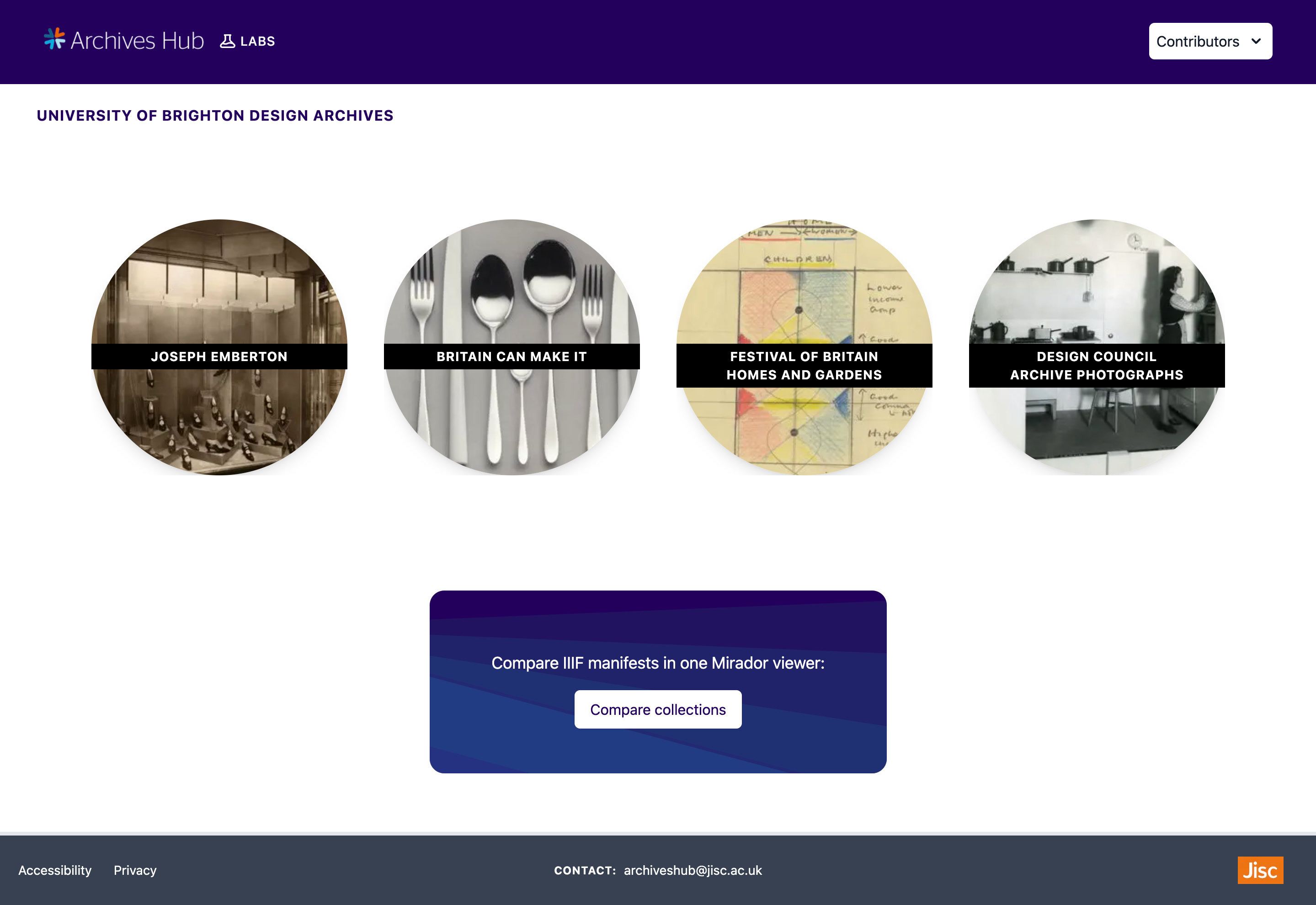
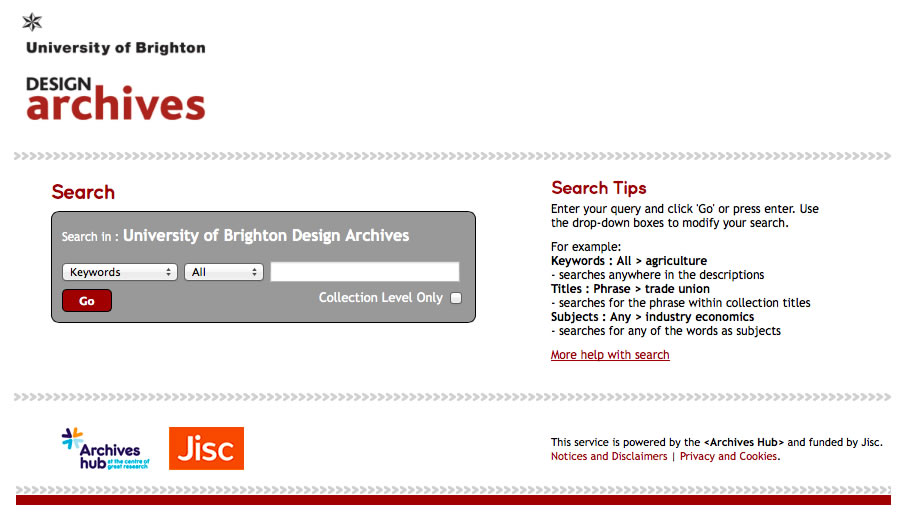
This is the contributor page for the University of Brighton Design Archives.
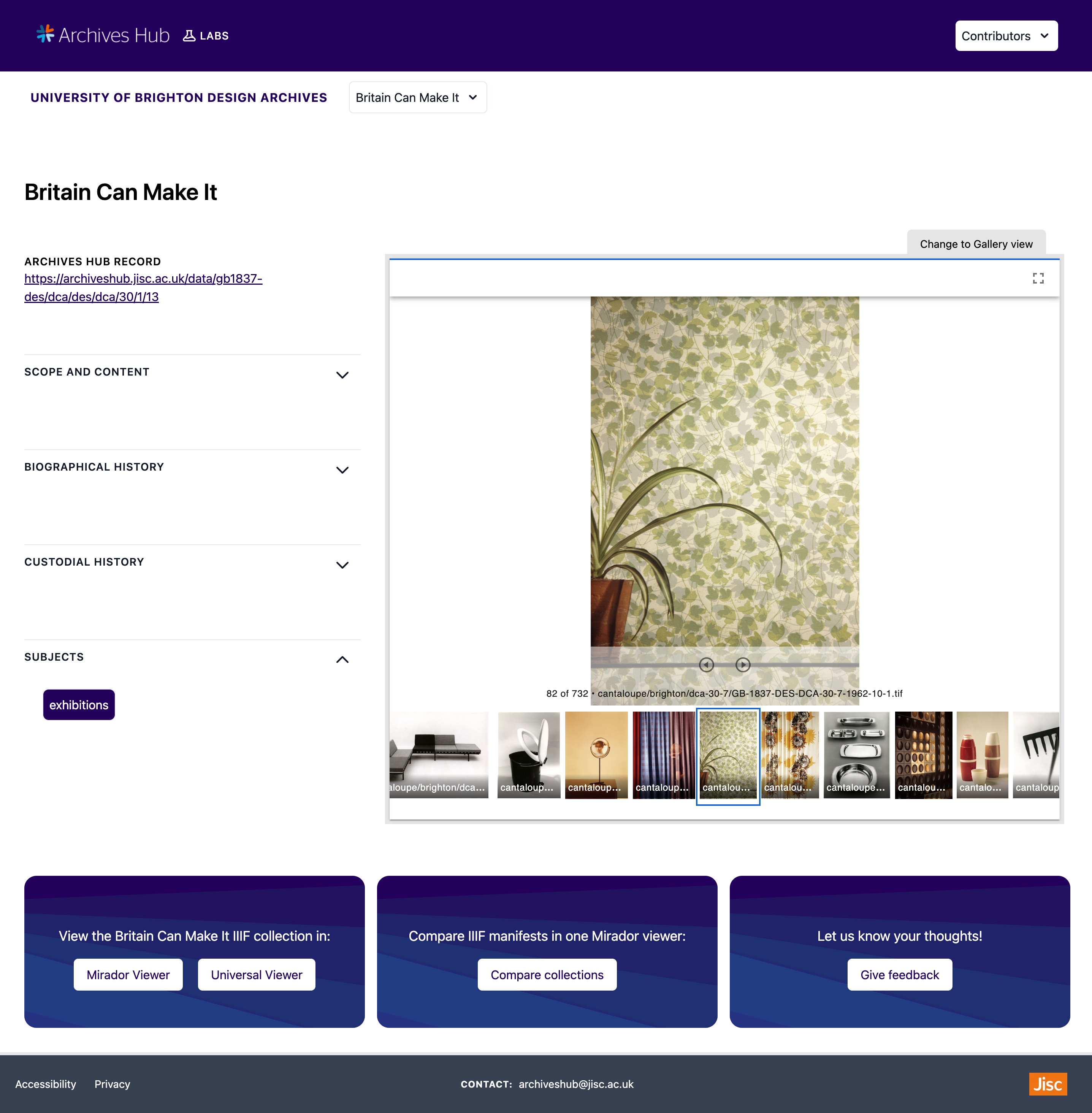
I also created dynamic collection pages for each collection. Included on the left-hand side of a collection page is the archives hub record link and the metadata about the collection taken from the archival EAD data – these sections displaying the metadata can be extended or hidden. The right-hand side of a collection page features aMirador viewer. A simple IIIF Manifest has been added for all of the images in each collection. This Manifest is used to help quickly navigate through and browse the images in the collection.
This is the collection page for the University of Brighton Design Archives ‘Britain Can Make It’ collection.
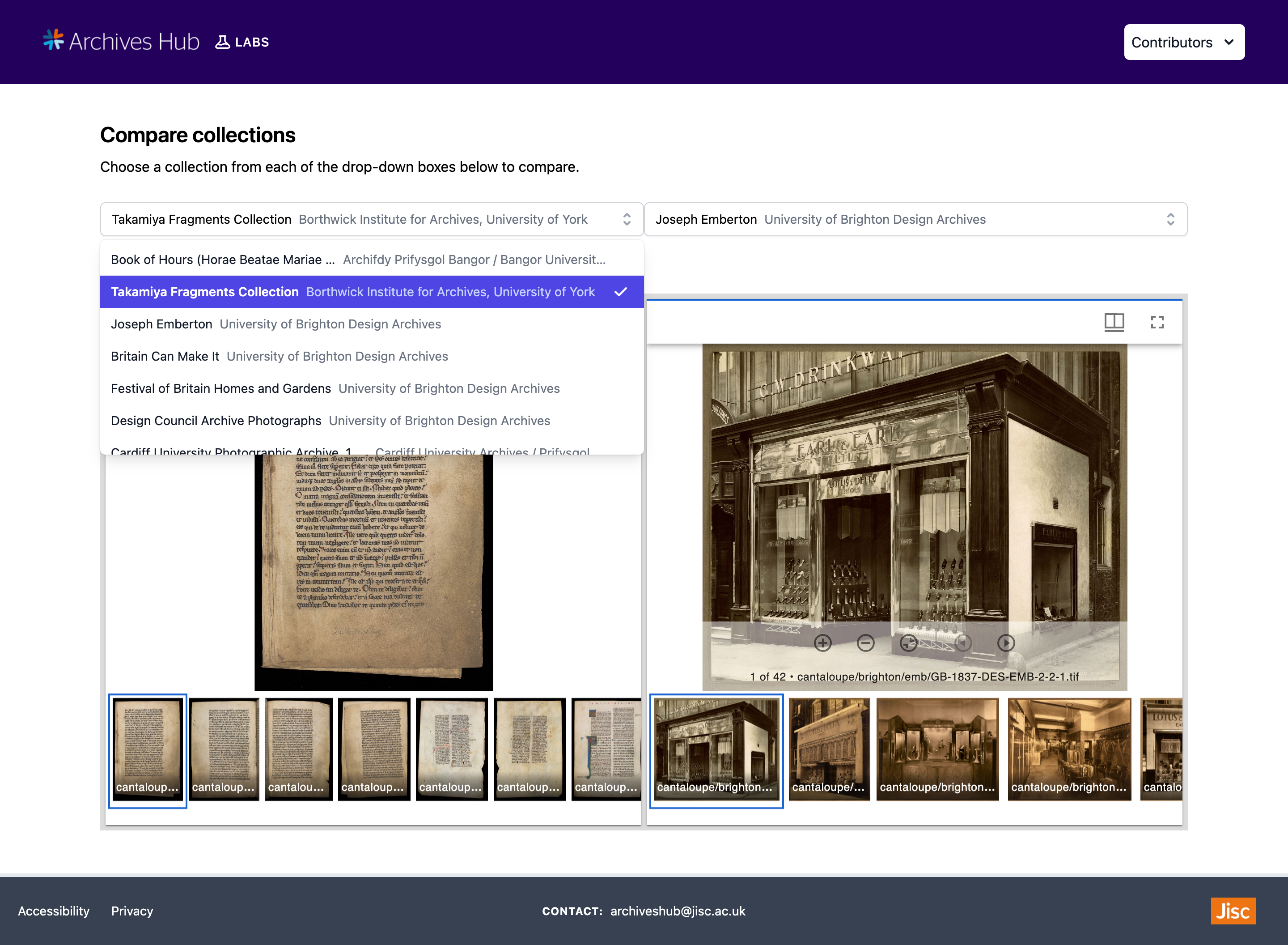
Mirador has the ability to display multiple windows within one workspace. This is really useful for comparison of images side-by-side. Therefore, I have also created a ‘Compare Collections’ page where two Manifests of collection images can be compared side-by-side. I have configured two windows to display within one Mirador viewer. Then, two collections can be chosen for comparison using the dropdown select boxes seen in the image below.
The ‘Compare Collections’ page.
Next steps
There are three key next steps for developing the User Interface –
We have experimented with the Mirador viewer, and now we will be looking at how the Universal Viewer handles IIIF Collections.
From the workshop feedback and from our exploration with the display of images, we will be looking at how we can offer an alternative experience of these archival images – distinct from their cataloguing hierarchy – such as thematic digital exhibitions and linking to other IIIF Collections and Manifests that already exist.
As part of the Machine Learning aspect of this project, we will be utilising the additional option to add annotations within the IIIF resources, so that the ML outputs from each image can be added as annotations and displayed in a viewer.
Labs IIIF Workshop
We recently held a workshop with the Archives Hub Labs project participants in order to get feedback on viewing the archive hierarchy through these IIIF Collections, displayed in a Mirador viewer. In preparation for this workshop, Ben created a sample of IIIF Collections using the images kindly provided by the project participants and the archival data related to these images that is on the Archives Hub. These were then loaded into the Mirador viewer so our workshop participants could see how the collection hierarchy is displayed within the viewer. The outcomes of this workshop will be explored in the next Archives Hub Labs blog post.
Thank you to Cardiff University, Bangor University, Brighton Design Archives at the University of Brighton, the University of Hull, the Borthwick Institute for Archives at the University of York, Lambeth Palace (Church of England) and Lloyds Bank for providing their digital collections and for participating in Archives Hub Labs.
As part of the Archives Hub Labs ‘Images and Machine Learning’ project we are currently exploring the challenges around implementing IIIF image services for archival collections, and also for Archives Hub more specifically as an aggregator of archival descriptions. This work is motivated by our desire to encourage the inclusion of more digital content on Archives Hub, and to improve our users’ experience of that content, in terms of both display and associated functionality.
Before we start to report on our progress with IIIF, we thought it would be useful to capture some of our current ideas and objectives with regards to the presentation of digital content on Archives Hub. This will help us to assess at later stages of the project how well IIIF supports those objectives, since it can be easy to get caught up in the excitement of experimenting with new technologies and lose sight of one’s starting point. It will also help our audience to understand how we’re aiming to develop the Hub, and how the Labs project supports those aims.
Crucial part of modern research and engagement with collections, especially after the pandemic
Another route into archives for researchers
Contributes to making archives more accessible
Will enable us to create new experiences and entry points within Archives Hub
To support contributing archives which can’t host or display content themselves
The poet Edward Thomas, ‘Wearing hat, c.1904’
The Current Situation
At the moment our contributors can include digital content in their descriptions on Archives Hub. They add links to their descriptions prior to publication, and they can do this at any level, e.g. ‘item’ level for images of individually catalogued objects, or maybe ‘fonds’ or ‘collection’ level for a selection of sample images. If the links are to image files, these are displayed on the Hub as part of the description. If the links are to video or audio files, or documents, we just display a link.
There are a few disadvantages to this set up: it can be a labour-intensive process adding individual links to descriptions; links often go dead because content is moved, leading to disappointment for researchers; and it means contributing archives need to be able to host content themselves, which isn’t always possible.
Where images are included in descriptions, these are embedded in the page as part of the description itself. If there are multiple images they are arranged to best fit the size of the screen, which means their order isn’t preserved.
If a user clicks on an image it is opened in a pop out viewer, which has a zoom button, and arrows for browsing if there is more than one image.
The embedded image and the viewer are both quite small, so there is also a button to view the image in fullscreen.
The viewer and the fullscreen option both obscure all or part of the decription itself, and there is no descriptive information included around the image other than a caption, if one has been provided.
As you can see the current interface is functional, but not ideal. Listed below are some of the key things we would like to look at and improve going forwards. The list is not intended to be exhaustive, but even so it’s pretty long, and we’re aware that we might not be able to fix everything, and certainly not in one go.
Documenting our aims though is an important part of steering our innovations work, even if those aims end up evolving as part of the exploration process.
Display and Viewing Experience
❐ The viewer needs updating so that users can play audio and video files in situ on the Hub, just as they can view images at the moment. It would be great if they could also read documents (PDF, Word etc).
❐ Large or high-resolution image files should load more quickly into the viewer.
❐ The viewer should also include tools for interacting with content, e.g. for images: zoom, rotate, greyscale, adjust brightness/contrast etc; for audio-visual files: play, pause, rewind, modify speed etc.
❐ When opened, any content viewer should expand to a more usable size than the current one.
❐ Should the viewer also support the display of descriptive information around the content, so that if the archive description itself is obscured, the user still has context for what they’re looking at? Any viewer should definitely clearly display rights and licensing information alongside content.
‘Now for a jolly ride at Bridlington’
Search and Navigation
❐ The Archives Hub search interface should offer users the option to filter by the type of digital content included in their search results (e.g. image, video, PDF etc).
❐ The search interface should also highlight the presence of digital content in search results more prominently, and maybe even include a preview?
❐ When viewing the top level of a multi-level description, users should be able to identify easily which levels include digital content.
❐ Users should also be able to jump to the digital content within a multi-level description quickly – possibly being able to browse through the digital content separately from the description itself?
❐ Users should be able to begin with digital content as a route into the material on Archives Hub, rather than only being able to search the text descriptions as their starting point.
Contributor Experience
Britain Can Make It: ‘Things for children’ (1946)
❐ Perhaps Archives Hub should offer some form of hosting service, to support archives, improve availability of digital content on the Hub, and allow for the development of workflows around managing content?
❐ Ideally, we would also develop a user-friendly method for linking content to descriptions, to make publishing and updating digital content easy and time-efficient.
❐ Any workflows or interfaces for managing digital content should be straightforward and accessible for non-technical staff.
❐ The service could give contributors access to innovative but sustainable tools, which drive engagement by highlighting their collections.
❐ If possible, any resources created should be re-usable within an archive’s own sites or resources – making the most of both the material and the time invested.
Future Possibilities
❐ We could look at offering options for contributors to curate content in creative and inventive ways which aren’t tied to cataloguing alone, and which offer alternative ways of experiencing archival material for users.
❐ It would be exciting for users to be able to ‘collect’, customise or interact with content in more direct ways. Some examples might include:
Creating their own collections of content
Creating annotations or notes
Publicly tagging or commenting on content
❐ Develop the experience for users with things like: automated tagging of images for better search; providing searchable OCR scanned text for text within images; using the tagging or classification of content to provide links to information and resources elsewhere.
The back end of a new system usually involves a huge amount of work and this was very much the case for the Archives Hub, where we changed our whole workflow and approach to data processing (see The Building Blocks of the new Archives Hub), but it is the front end that people see and react to; the website is a reflection of the back end, as well as involving its own user experience challenges, and it reflects the reality of change to most of our users.
We worked closely with Knowledge Integration in the development of the system, and with Gooii in the design and implementation of the front end, and Sero ran some focus groups for us, testing out a series of wireframe designs on users. Our intention was to take full advantage of the new data model and processing workflow in what we provided for our users. This post explains some of the priorities and design decisions that we made. Additional posts will cover some of the areas that we haven’t included here, such as the types of description (collections, themed collections, repositories) and our plan to introduce a proximity search and a browse.
Speed is of the Essence
Faster response times were absolutely essential and, to that end, a solution based on an enterprise search solution (in this case Elasticsearch) was the starting point. However, in addition to the underlying search technology, the design of the data model and indexing structure had a significant impact on system performance and response times, and this was key to the architecture that Knowledge Integration implemented. With the previous system there was only the concept of the ‘archive’ (EAD document) as a whole, which meant that the whole document structure was always delivered to the user whatever part of it they were actually interested in, creating a large overhead for both processing and bandwidth. In the new system, each EAD record is broken down into many separate sections which are each indexed separately, so that the specific section in which there is a search match can be delivered immediately to the user.
To illustrate this with an example:-
A researcher searches for content relating to ‘industrial revolution’ and this scores a hit on a single item 5 levels down in the archive hierarchy. With the previous system the whole archive in which the match occurs would be delivered to the user and then this specific section would be rendered from within the whole document, meaning that the result could not be shown until the whole archive has been loaded. If the results list included a number of very large archives the response time increased accordingly.
In the new system, the matching single item ‘component’ is delivered to the user immediately, when viewed in either the result list or on the detail page, as the ability to deliver the result is decoupled from archive size. In addition, for the detail page, a summary of the structure of the archive is then built around the item to provide both the context and allow easy navigation.
Even with the improvements to response times, the tree representation (which does have to present a summary of the whole structure), for some very large multi-level descriptions takes a while to render, but the description itself always loads instantly. This means that that the researcher can always see they have a result immediately and view it, and then the archival structure is delivered (after a short pause for very large archives) which gives the result context within the archive as a whole.
The system has been designed to allow for growth in both the number of contributors we can support and the number of end-users, and will also improve our ability to syndicate the content to both Archives Portal Europe and deliver contributors own ‘micro sites‘.
Look and Feel
Some of the feedback that we received suggested that the old website design was welcoming, but didn’t feel professional or academic enough – maybe trying to be a bit too cuddly. We still wanted to make the site friendly and engaging, and I think we achieved this, but we also wanted to make it more professional looking, showing the Hub as an academic research tool. It was also important to show that the Archives Hub is a Jisc service, so the design Gooii created was based upon the Jisc pattern library that we were required to use in order to fit in with other Jisc sites.
We have tried to maintain a friendly and informal tone along with use of cleaner lines and blocks, and a more visually up-to-date feel. We have a set of consistent icons, on/off buttons and use of show/hide, particularly with the filter. This helps to keep an uncluttered appearance whilst giving the user many options for navigation and filtering.
In response to feedback, we want to provide more help with navigating through the service, for those that would like some guidance. The homepage includes some ‘start exploring’ suggestions for topics, to help get inexperienced researchers started, and we are currently looking at the whole ‘researching‘ section and how we can improve that to work for all types of users.
Navigating
We wanted the Hub to work well with a fairly broad search that casts the net quite widely. This type of search is often carried out by a user who is less experienced in using archives, or is new to the Hub, and it can produce a rather overwhelming number of results. We have tried to facilitate the onward journey of the user through judicious use of filtering options. In many ways we felt that filtering was more important than advanced search in the website design, as our research has shown that people tend to drill down from a more general starting point rather than carry out a very specific search right from the off. The filter panel is up-front, although it can be hidden/shown as desired, and it allows for drilling down by repository, subject, creator, date, level and digital content.
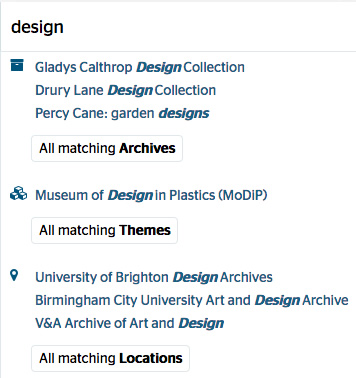
Another way that we have tried to help the end user is by using typeahead to suggest search results. When Gooii suggested this, we gave it some thought, as we were concerned that the user might think the suggestions were the ‘best’ matches, but typeahead suggestions are quite a common device on the web, and we felt that they might give some people a way in, from where they could easily navigate through further descriptions.
A search for ‘design’ with suggested results
The suggestions may help users to understand the sort of collections that are described on the Hub. We know that some users are not really aware of what ‘archives’ means in the context of a service like the Archives Hub, so this may help orientate them.
Suggested results also help to explain what the categories of results are – themes and locations are suggested as well as collection descriptions.
We thought about the usability of the hit list. In the feedback we received there was no clear preference for what users want in a hit list, and so we decided to implement a brief view, which just provides title and date, for maximum number of results, and also an expanded view, with location, name of creator, extent and language, so that the user can get a better idea of the materials being described just from scanning through the hit list.
Expanded mode gives the user more information
With the above example, the title and date alone do not give much information, which is particularly common with descriptions of series or items, of so the name of creator adds real value to the result.
Seeing the Wood Through the Trees
The hierarchical nature of archives is always a challenge; a challenge for cataloguing, processing and presentation. In terms of presentation, we were quite excited by the prospect of trying something a bit different with the new Hub design. This is where the ‘mini map’ came about. It was a very early suggestion by K-Int to have something that could help to orientate the user when they suddenly found themselves within a large hierarchical description. Gooii took the idea and created a number of wireframes to illustrate it for our focus groups.
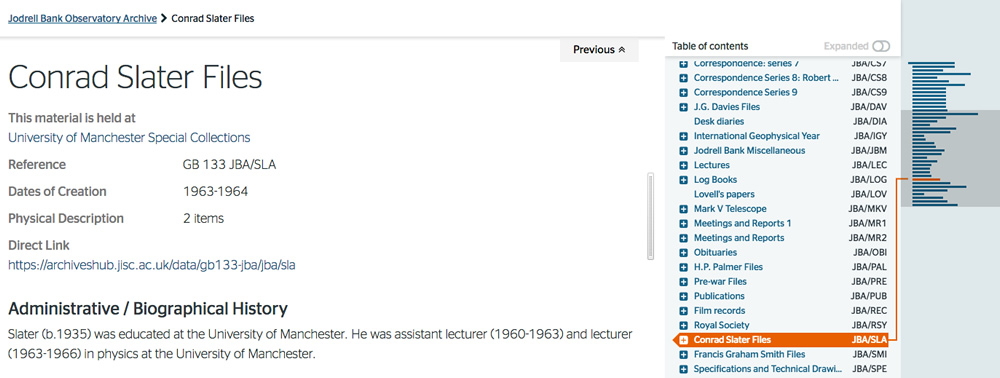
For instance, if a user searches on Google for ‘conrad slater jodrell bank’ then they get a link to the Hub entry:
Result of a search on Google
The user may never have used archives, or the Archives Hub before. But if they click on this link, taking them directly to material that sits within a hierarchical description, we wanted them to get an immediate context.
Jodrell Bank Observatory Archives: Conrad Slater Files
The page shows the description itself, the breadcrumb to the top level, the place in the tree where these particular files are described and a mini map that gives an instant indication of where this entry is in the whole. It is intended (1) to give a basic message for those who are not familiar with archive collections – ‘there is lots more stuff in this collection’ and (2) to provide the user with a clearly understandable expanding tree for navigation through this collection.
One of the decision we made, illustrated here, was to show where the material is held at every level, for every unit of description. The information is only actually included at the top level in the description itself, but we can easily cascade it down. This is a good illustration of where the approach to displaying archive descriptions needs to be appropriate for the Web – if a user comes straight into a series or item, you need to give context at that level and not just at the top level.
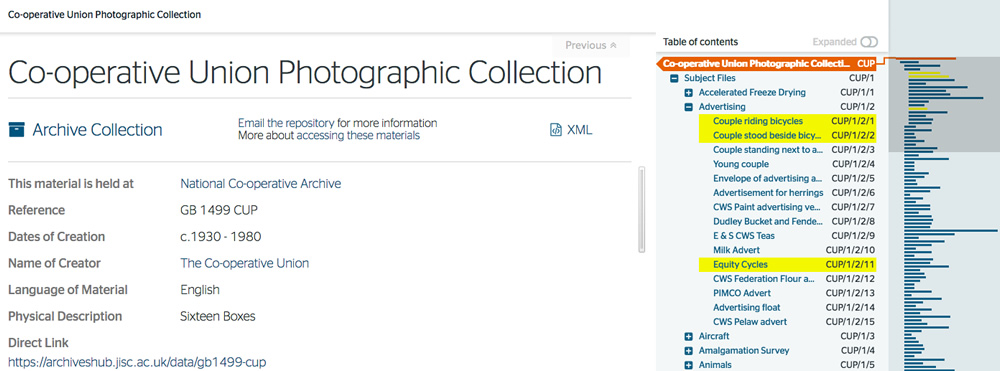
The design also works well for searches within large hierarchical descriptions.
Search for ‘bicycles’ within the Co-operative Union Photographic Collection
The user can immediately get a sense of whether the search has thrown up substantial results or not. In the example above you can see that there are some references to ‘bicycles’ but only early on in the description. In the example below, the search for ‘frost on sunday’ shows that there are many references within the Ronnie Barker Collection.
Search within the Ronnie Barker Collection for ‘frost on sunday’
One of the challenges for any archive interface is to ensure that it works for experienced users and first-time users. We hope that the way we have implemented navigation and searching mean that we have fulfilled this aim reasonably well.
Small is Beautiful
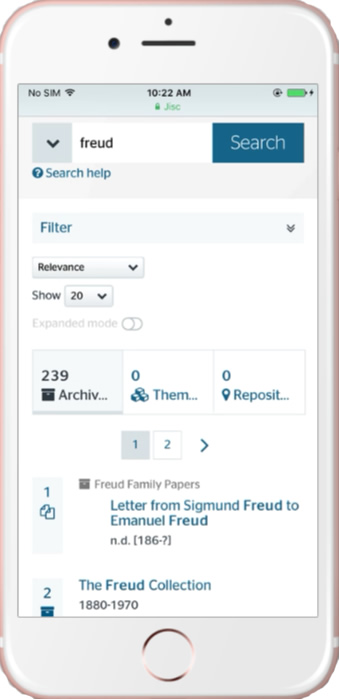
The Archives Hub on an iPhone
The old site did not work well on mobile devices. It was created before mobile became massive, and it is quite hard to retrospectively fit a design to be responsive to different devices. Gooii started out with the intention of creating a responsive design, so that it renders well on different sized screens. It requires quite a bit of compromise, because rendering complex multi-level hierarchies and very detailed catalogues on a very small screen is not at all easy. It may be best to change or remove some aspects of functionality in order to ensure the site makes sense. For example, the mobile display does not open the filter by default, as this would push the results down the page. But the user can open the filter and use the faceted search if they choose to do so.
We are particularly pleased that this has been achieved, as something like 30% of Hub use is on mobiles and tablets now, and the basic search and navigation needs to be effective.
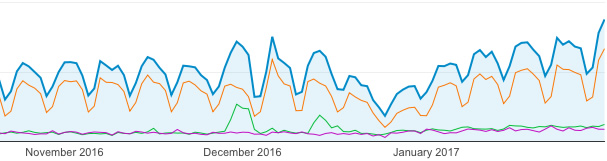
Devices used to view the Hub site over a three month period
In the above graph, the orange line is desktop, the green is mobile and the purple is tablet. (the dip around the end of December is due to problems setting up the Analytics reporting).
Cutting Our Cloth
One of the lessons we have learnt over 15 years of working on the Archives Hub is that you can dream up all of the interface ideas that you like, but in the end what you can implement successfully comes down to the data. We had many suggestions from contributors and researchers about what we could implement, but oftentimes these ideas will not work in practice because of the variations in the descriptions.
We though about implementing a search for larger, medium sized or smaller collections, but you would need consistent ‘extent’ data, and we don’t have that because archivists don’t use any kind of controlled vocabulary for extent, so it is not something we can do.
When we were running focus groups, we talked about searching by level – collection, series, sub-series, file, item, etc. For some contributors a search by a specific level would be useful, but we could only implement three levels – collection (or ‘top level’), item (which includes ‘piece’) and then everything between these, because the ‘in-between’ levels don’t lend themselves to clear categorisation. The way levels work in archival description, and the way they are interpreted by repositories, means we had to take a practical view of what was achievable.
We still aren’t completely sold on how we indicate digital content, but there are particular challenges with this. Digital content can be images that are embedded within the description, links to images, or links to any other digital content imaginable. So, you can’t just use an image icon, because that does not represent text or audio. We ended up simply using a tick to indicate that there is digital content of some sort. However, one large collection may have links to only one or two digital items, so in that case the tick may raise false expectations. But you can hardly say ‘includes digital content, but not very much, so don’t get too excited’. There is room for more thought about our whole approach to digital content on the Hub, as we get more links to digital surrogates and descriptions of born-digital collections.
Statistics
The outward indication of a more successful site is that use goes up. The use of statistics to give an indication of value is fraught with problems. Do the number of clicks represent value? Might more clicks indicate a poorer user interface design? Or might they indicate that users find the site more engaging? Does a user looking at only one description really gain less value than a user looking at ten descriptions? Clearly statistics can only ever be seen as one measure of value, and they need to be used with caution. However, the reality is that an upward graph is always welcomed! Therefore we are pleased to see that overall use of the website is up around 32% compared to this period during the previous year.
Jan 2016 (the orange line) and Jan 2017 (the blue line), which shows typical daily use above 2,000 page views.
Feedback
We are pleased to say that the site has been very well received…
“The new site is wonderful. I am so impressed with its speed and functionality, as well as its clean, modern look.” (University Archivist)
“…there are so many other features that I could pick out, such as the ability to download XML and the direct link generator for components as well as collections, and the ‘start exploring’ feature.” (University Archivist)
“Brand new Archives Hub looks great. Love how the ‘explorer themes’ connect physically separated collections” (Specialist Repository Head of Collections)
“A phenomenal achievement!” (Twitter follower)
With thanks to Rob Tice from Knowledge Integration for his input to this post.
Back in 2008 the Archives Hub embarked upon a project to become distributed; the aim was to give control of their data to the individual contributors. Every contributor could host their own data by installing and running a ‘mini Hub’. This would give them an administrative interface to manage their descriptions and a web interface for searching.
Five years later we had 6 distributed ‘spokes’ for 6 contributors. This was actually reduced from 8, which was the highest number of institutions that took up the invitation to hold their own data out of around 180 contributors at the time.
The primary reason for the lack of success was identified as a lack of technical knowledge and the skills required for setting up and maintaining the software. In addition to this, many institutions are not willing to install unknown software or maintain an unfamiliar operating system. Of course, many Hub contributors already had a management system, and so they may not have wanted to run a second system; but a significant number did not (and still don’t) have their own system. Part of the reason may institutions want an out-of-the-box solution is that they do not have consistent or effective IT support, so they need something that is intuitive to use.
The spokes institutions ended up requiring a great deal of support from the central Hub team; and at the same time they found that running their spoke took a good deal of their own time. In the end, setting up a server with an operating system and bespoke software (Cheshire in this case) is not a trivial thing, even with step-by-step instructions, because there are many variables and external factors that impact on the process. We realised that running the spokes effectively would probably require a full-time member of the Hub team in support, which was not really feasible, but even then it was doubtful whether the spokes institutions could find the IT support they required on an ongoing basis, as they needed a secure server and they needed to upgrade the software periodically.
Another big issue with the distributed model was that the central Hub team could no longer work on the Hub data in its entirety, because the spoke institutions had the master copy of their own data. We are increasingly keen to work cross-platform, using the data in different applications. This requires the data to be consistent, and therefore we wanted to have a central store of data so that we could work on standardising the descriptions.
The Hub team spend a substantial amount of time processing the data, in order to be able to work with it more effectively. For example, a very substantial (and continuing) amount of work has been done to create persistent URIs for all levels of description (i.e. series, item, etc.). This requires rigorous consistency and no duplications of references. When we started to work on this we found that we had 100’s of duplicate references due to both human error and issues with our workflow (which in some cases meant we had loaded a revised description along with the original description). Also, because we use archival references in our URIs, we were somewhat nonplussed to discover that there was an issue with duplicates arising from references such as GB 234 5AB and GB 2345 AB. We therefore had to change our URI pattern, which led to substantial additional work (we used a hyphen to create gb234-5ab and gb2345-ab).
We also carry out more minor data corrections, such as correcting character encoding (usually an issue with characters such as accented letters) and creating normalised dates (machine processable dates).
In addition to these types of corrections, we run validation checks and correct anything that is not valid according to the EAD schema, and we are planning, longer term, to set up a workflow such that we can implement some enhancement routines, such as adding a ‘personal name’ or ‘corporate name’ identifying tag to our creator names.
These data corrections/enhancements have been applied to data held centrally. We have tried to work with the distributed data, but it is very hard to maintain version control, as the data is constantly being revised, and we have ended up with some instances where identifying the ‘master’ copy of the data has become problematic.
We are currently working towards a more automated system of data corrections/enhancement, and this makes it important that we hold all of the data centrally, so that we ensure that the workflow is clear and we do not end up with duplicate slightly different versions of descriptions. (NB: there are ways to work more effectively with distributed data, but we do not have the resources to set up this kind of environment at present – it may be something for the longer term).
We concluded that the distributed model was not sustainable, but we still wanted to provide a front-end for contributors. We therefore came up with the idea of the ‘micro sites’.
What are Hub Micro Sites?
The micro sites are a template based local interface for individual Hub contributors. They use a feed of the contributor’s data from the central Archives Hub, so the data is only held in one place but accessible through both interfaces: the Hub and the micro site. The end-user performs a search on a micro site, the search request goes to the central Hub, and the results are returned and displayed in the micro site interface.
Brighton Design Archives micro site homepage
The principles underlying the micro sites are that they need to be:
As part of our aim of ensuring a sustainable and low-cost solution we knew we had to adopt a one-size-fits-all model. The aim is to be able to set up a new micro site with minimal effort, as the basic look and feel stays the same. Only the branding, top and bottom banners, basic text and colours change. This gives enough flexibility for a micro site to reflect an institution’s identity, through its logo and colours, but it means that we avoid customisation, which can be very time-consuming to maintain.
The micro sites use an open approach, so it would be possible for institutions to customise themselves, by manipulating the stylesheets. However, this is not something that the Archives Hub can support, and therefore the institution would need to have the expertise necessary to maintain this themselves.
The Consultation Process
We started by talking to the Spokes institutions and getting their feedback about the strengths and weaknesses of the spokes and what might replace them. We then sent out a survey to Hub contributors to ascertain whether there would be a demand for the micro sites.
Institutions preferred the micro sites to be hosted by the Archives Hub. This reflects the lack of technical support within UK archives. This solution is also likely to be more efficient for us, as providing support at a distance is often more complicated than maintaining services in-house.
The responders generally did not have images displayed on the Hub, but intended to in the future, so this needed to be taken into account. We also asked about experiences with understanding and using APIs. The response showed that people had no experience of APIs and did not really understand what they were, but were keen to find out more.
We asked for requirements and preferences, which we have taken into account as much as possible, but we explained that we would have to take a uniform approach, so it was likely that there would need to be compromises.
After a period of development, we met with the early adopters of the micro sites (see below) to update them on our progress and get additional requirements from them. We considered these requirements in terms of how practical they would be to implement in the time scale that we were working towards, and we then prioritised the requirements that we would aim to implement before going live.
The additional requirements included:
Search in multi-level description: the ability to search within a description to find just the components that include the search term
Reference search: useful for contributors for administrative purposes
Citation: title and reference, to encourage researchers to cite the archive correctly
Highlight: highlighting of the search term(s)
Links to ‘search again’ and to ‘go back’ to the collection result
The addition of Google Analytics code in the pages, to enable impact analysis
The Development Process
We wanted the micro sites to be a ‘stand alone’ implementation, not tied to the Archives Hub. We could have utilised the Hub, effectively creating duplicate instances of the interface, but this would have created dependencies. We felt that it was important for the micro sites to be sustainable independent of our current Hub platform.
In fact, the Micro sites have been developed using Java, whereas the Hub uses Python, a completely different programming language. This happened mainly because we had a Java programmer on the team. It may seem a little odd to do this, as opposed to simply filtering the Hub data with Python, but we think that it has had unforeseen benefits. Namely, that the programmers who have worked on the micro sites have been able to come at the task afresh, and work on new ways to solve the many challenges that we faced. As a result of this we have implemented some solutions with the micro sites that are not implemented on the Hub. Equally, there were certainly functions within the Hub that we could not replicate with the micro sites – mainly those that were specifically set up for the aggregated nature of the Hub (e.g browsing across the Hub content).
It was a steep learning curve for a developer, as the development required a good understanding of hierarchical archival descriptions, and also an appreciation of the challenges that come from a diverse data set. As with pretty much all Hub projects, it is the diverse nature of the data set that is the main hurdle. Developers need patterns; they need something to work with, something consistent. There isn’t too much of that with aggregated archives catalogues!
The developer utilised what he could from the Hub, but it is the nature of programming that reverse engineering of someone else’s code can be a great deal harder than re-coding, so in many cases the coding was done from scratch. For example, the table of contents is a particularly tricky thing to recreate, but the code used for the current Hub proved to be too complex to work with, as it has been built up over a decade and is designed to work within the Hub environment. The table of contents requires the hierarchy to be set out, collapsible folder structures, links to specific parts of the description with further navigation from there to allow the researcher to navigate up and down, so it is a complex thing to create and it took some time to achieve.
The feed of data has to provide the necessary information for the creation of the hierarchy, and our feed comes through SRU (Search/Retrieve via URL), which is a standard search protocol for Internet search queries using Contextual Query Language (CQL). This was already available through the Hub API, and the micro sites application makes uses of SRU in order to perform most of the standard searches that are available on the Hub. Essentially, each of the micro sites are provided by a single web application that acts as a layer on the Archives Hub. To access the individual micro sites, the contributor provides a shortened version of the institution’s name as a sub-string to the micro sites web address. This then filters the data accordingly for that institution, and sets up the site with the appropriate branding. The latter is achieved through CSS stylesheets, individually tailored for the given institution by a stand-alone Java application and a standard CSS template.
Page Display
One of the changes that the developer suggested for the micro sites concerns the intellectual division of the descriptions. On the current Hub, a description may carry over many pages, but each page does not represent anything specific about the hierarchy, it is just a case of the description continuing from one page to the next. With the micro sites we have introduced the idea that each ‘child’ description of the top level is represented on one page. This can more easily be shown through a screenshot:
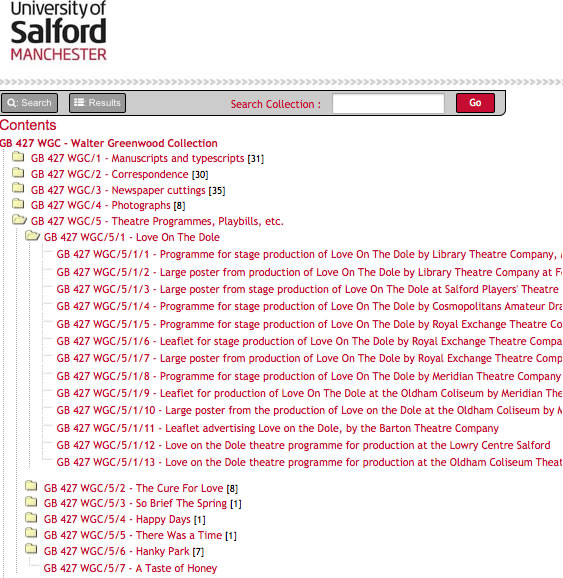
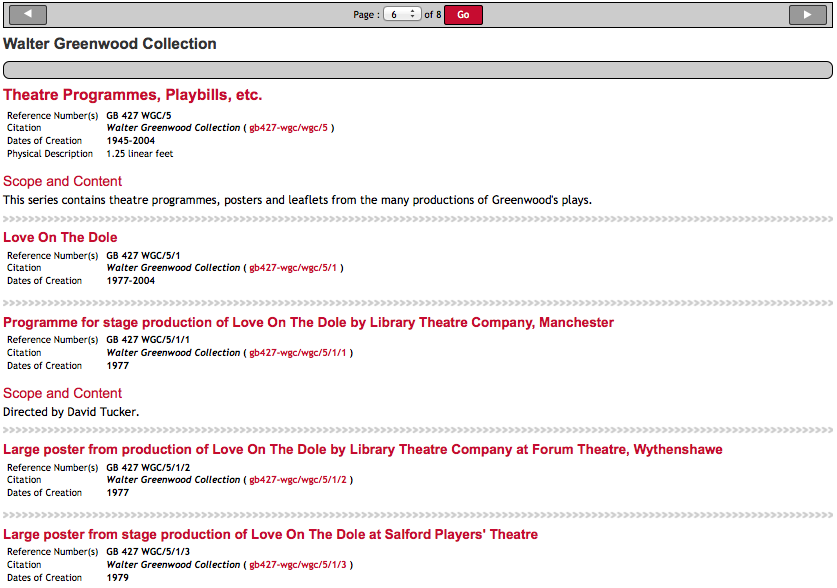
Table of Contents of the Walter Greenwood Collection showing the tree structure
In the screenshot above, the series ‘Theatre Programmes, Playbills, etc’ is a first-level child description (a series description) of the archive collection ‘The Walter Greenwood Collection’. Within this series there are a number of sub-series, the first of which is ‘Love on the Dole’, the last of which is ‘A Taste of Honey’. The researcher will therefore get a page that contains everything within this one series – all sub-series and items – if there are any described in the series.
Page for ‘Theatre Programmes, Playbills, etc’ within the Walter Greenwood Collection
The sense of hierarchy and belonging is further re-enforced by repeating the main collection title at the top of every right hand pane. The only potential downside to this approach is that it leads to variable length ‘child’ description pages, but we felt it was a reasonable trade-off because it enables the researcher to get a sense of the structure of the collection. Usually it means that they can see everything within one series on one page, as this is the most typical first child level of an archival description. In EAD representation, this is everything contained within the <c01> tag or top level <c> tag.
Next Steps
We are currently testing the micro sites with early adopters: Glasgow University Archive Services, Salford University Archives, Brighton Design Archives and the University of Manchester John Rylands Library.
We aim to go live during September 2014 (although it has been hard to fix a live date, as with a new and innovative service such as the micro sites unforeseen problems tend to emerge with alarming regularity). We will see what sort of feedback we get, and it is likely that we will find a few things need addressing as a result of putting the micro sites out into the big wide world. We intend to arrange a meeting for the early adopters to come together again and feed back to us, so that we can consider whether we need a ‘phase 2’ to iron out any problems and make any enhancements. We may at that stage invite other interested institutions, to explain the process and look at setting up further sites. But certainly our aim is to roll out the micro sites to other Archives Hub institutions.
The recent Digital Humanities @ University of Manchester conference presented research and pondered issues surrounding digital humanities. I attended the morning of the conference, interested to understand more about the discipline and how archivists might interact with digital humanists, and consider ways of opening up their materials that might facilitate this new kind of approach.
Visualisation within digital humanities was presented in a keynote by Dr Massimo Riva, from Brown University. He talked about the importance of methodologies based on computation, whether the sources are analogue or digital, and how these techniques are becoming increasingly essential for humanities. He asked whether a picture is worth one million words, and presented some thought-provoking quotes relating to visualisation, such as a quote by John Berger: “The relation between what we see and what we know is never settled.” (John Berger, Ways of Seeing, 1972).
Riva talked about how visual projection is increasingly tied up with who we are and what we do. But is digital humanities translational or transformative? Are these tools useful for the pursuit of traditional scholarly goals, or do they herald a new paradigm? Does digital humanities imply that scholars are making things as they research, not just generating texts? Riva asked how we can combine close reading of individual artifacts and ‘distant reading’ of patterns across millions of artifacts. He posited that visualisation helps with issues of scale; making sense of huge amounts of data. It also helps cross boundaries of language and communication.
Riva talked about the fascinating Cave Writing at Brown University, a new kind of cognitive experience. It is a four-wall, immersive virtual reality device, a room of words. This led into his thoughts about data as a type of artifact and the nature of the archive.
“On the cusp of the twenty–first century…we speak of an ex–static archive, of an archive not assembled behind stone walls but suspended in a liquid element behind a luminous screen; the archive becomes a virtual repository of knowledge without visible limits, an archive in which the material now becomes immaterial.” This change “has altered in still unimaginable ways our relationship to the archive”. (Voss & Werner, 1999)
The Garibaldi panorama is a 276 feet long, a panorama that tells the story of Garibaldi, the Italian general and politician. It is fragile and cannot be directly consulted by scholars. So, the whole panorama was photographed in 91 digital images in 2007. The digital experience is clearly different to the physical experience. But the resulting digital panorama can be interacted with it many various ways and it is widely available via the website along with various tools to help researchers interpret the panorama. It is interesting to think about how much this is in itself a curated experience, and how much it is an experience that the user curates themselves. Maybe it is both. If it is curated, then it is not really the archivists who are curators, but those who have created the experience those with the ability to create such technical digital environments. It is also possible for students to create their own resources, and then for those resources to become part of the experience, such as an interactive timeline based on the panorama. So, students can enhance the metadata as a form of digital scholarship.
Riva showed an example of a collaborative environment where students can take parts of the panorama that interests them and explore it, finding links and connections and studying parts of the panorama along with relevant texts. It is fascinating as an archivist to see examples like this where the original archive remains the basis of the scholarly endeavour. The artifact is at a distance to the actual experience, but the researcher can analyse it to a very detailed level. It raises the whole debate around the importance of studying the original archive. As tools and environments become more and more sophisticated, it is possible to argue that the added value of a digital experience is very substantial, and for many researchers, preferable to handling the original.
Riva talked about the learning curve with the software. Scholars struggled to understand the full potential of it and what they could do and needed to invest time in this. But an important positive was that students could feedback to the programmers, in order to help them improve the environment.
We had short presentations on a diverse range of projects, all of which showed how digital humanities is helping to reveal history to us in many ways. Dr Guyda Armstrong made the point that library catalogues are more than they might seem – they are a part of cultural history. This is reflected in a bid for funding for a Digging into Data project, metaSCOPE, looking at bibliographical metadata as datamassive cultural history. The questions the project hopes to answer are many: how are different cultures expressed in the data? How do library collections data reflect the epistemic values, national and disciplinary cultures and artifacts of production and dissemination expressed in their creation? This project could help with mapping the history of publishing in space and time, as well as showing the history of one book over time.
We saw many examples of how visual work and digital humanities approaches can bring history to life and help with new understanding of many areas of research. I was interested to hear how the mapping of the Caribbean during the 18th century opened up the coastline to the slave traders, but the interior, which was not mapped in any detail, remained in many ways a free area, where the slave traders did not have control. The mapping had a direct influence on many people’s lives in very fundamental ways.
Another point that really stood out to me was the danger of numbers averaging out the human experience – a challenge with digital humanities approach, as, at the same time, numbers can give great insights into history. Maybe this is a very good reason why those who create tools and those who use them benefit from a shared understanding.
“All archaeological excavation is destruction”, so what actually lives on is the record you create, says Dr Stuart Campbell. Traditional monographs synthesize all the data. They represent what is created through the process of excavation. It is a very conventional approach. But things are changing and digital archiving creates new ways of working in the virtual world of archaeological data. Dr Campbell made the point that interpretation is often privileged over the data itself in traditional methods, but new approaches open up the data, allowing more narratives to be created. The process of data creation becomes apparent, and the approach scales up to allow querying that breaks out beyond the boundaries of archaeological sites. For example, he talked about looking at pattens on ancient pottery and plotting where the pottery comes from. New sophisticated tools allow different dimensions to be brought into the research. Links can now be created that bring various social dimensions to archeological discoveries, but the understanding of what these connections really represent is less well understood or theorised.
Seemingly a contrast to many of the projects, a project to recreate the Gaskell house in Manchester is more about the physical experience. People will be able to take books down from the shelves, sit down and read them. But actually there is a digital approach here too, as the intention is to add value to the experience by enabling visitors to leaf through digital copies of Gaskell’s works and find out more about the process of writing and publishing by showing different versions of the same stories, handwritten, with annotations, and published. It is enhancing the physical experience with a tactile experience through digital means.
To end the morning we had a cautionary tale about the vulnerability of Websites. A very impressive site, allowing users to browse in detail through an Arabic manuscript, is to be taken down, presumably because of changes in personnel or priorities at the hosting institution.The sustainability of the digital approach is in itself a huge topic, whether it be the data or the dissemination approaches.
I was lucky enough to attend the 2012 EmTACL conference in Trondheim, and this blog is based around the excellent keynote presentation by Herbert van de Sompel, which really made me think about temporal issues with the Web and how this can limit our understanding of the scholarly record.
Herbert believes that the current infrastructure for scholarly communication is not up to the job. We now have many non-traditional assets, which do not always have fixity and often have a wide range of dependencies; assets such as datasets, blogs, software, videos, slides which may form part of a scholarly resource. Everything is much more dynamic than it used to be. ‘Research objects’ often include assets that are interdependent with each other, so they need to be available all together for the object to be complete. But this is complicated by the fact that many of them are ‘in motion’ and updated over time.
This idea of dynamic resources that are in flux, constantly being updated, is very relevant for archivists, partly because we need to understand how archives are not static and fixed in time, and partly because we need to be aware of the challenges of archiving ever more complex and interconnected resources. It is useful to understand the research environment and the way technology influences outputs and influences what is possible for future research.
There are examples of innovative services that are responding to the opportunities of dynamic resources. One that Herbert mentioned was PLOS, which publishes open scholarly articles. It puts publications into Wikipedia as well as keeping the ‘static’ copy, so that the articles have a kind of second life where they continue to evolve as well as being kept as they were at the time of submission. For example, ‘Circular Permutation in Proteins‘.
The idea of executable papers is starting to become established – papers that are not just to read but to interact with. These contain access to the primary data with capabilities to re-execute algorithms and even capabilities to allow researchers to upload and use their own data. It produces a complex interdependency and produces a challenge for archiving because if something is not fixed in time, what does that mean for retaining access to it over time?
This all raises the issue of what the scholarly record actually is. Where does it start? Where does it end? We are no longer talking about a bunch of static files but a dynamic interconnected resource. In fact, there is an increasing sense that the article itself is not necessarily the key output, but rather it is the advertising for the actual scholarship.
Herbert concluded from this that it becomes very important to be able to view different points in time in the evolution of scholarly record, and this should be done in a way that works with the Web. The Web is the platform, the infrastructure for the scholarly record. Scholarly communication then becomes native to the Web. At the heart of this is the need to use HTTP URIs.
However, where are we at the moment? The current archival infrastructure for scholarly outputs deals with things with fixity and boundaries. It cannot deal with things in flux and with inter-dependencies. The Web exists in ‘now’ time; it does not have a built in notion of time. It assumes that you want the current version of something – you cannot use a URI to get to a prior version.
Slide from Herbert van de Sompel’s presentation showing the publication context on the Web
We don’t really object to this limitation, something evidenced by the fact that we generally accept links that take us to 404 pages, as if it is just an inevitable inconvenience. Maybe many people just don’t think that there is any real interest in or requirement for ‘obsolete’ resources, and what is current is what is important on the Web.
Of course, there is the Internet Archive and other similar initiatives in Web archiving, but they are not integrated into the Web. You have to go somewhere completely different in order to search for older copies of resources.
If the research paper remains the same, but resources that are an integral part of it change over time, then we need to change archiving to reflect this. We need to think about how to reference assets over time and how to recreate older versions. Otherwise, we access the current version, but we are not getting the context that was there at the time of creation; we are getting something different.
Can we recreate a version of a scholarly record? Can we go back to certain point it time so we can see linked assets from a paper as they were at the time of publication? At the moment we are likely to get many 404s when we try to access links associated with a publication. Herbert showed one survey on the decay of URLs in Medline, which is about 10% per year, especially with links to thinks like related databases.
One solution to this is to be able to follow a URI in time – to be able to click on URI and say ‘I want to see this as was 2 years ago’. Herbert went on to talk about something he has created called Memento. Memento aims to better integrate the current and past Web. It allows you to select a day or time in the browser and effectively take the URI back in time. Currently, the team are looking at enabling people to browse past pages of Wikipedia. Memento has a fairly good success rate with going back to retrieve old versions, although it will not work for all resources. I tried it with the Archives Hub and found it easy to take the website back to how it looked right in the very early days.
Using Memento to take the Archives Hub back in time.
One issue is that the archived copies are not always created near the time of publication. But for those that are, they are created simply as part of the normal activity of the Web, by services like the Internet Archive or the British Library, so there is no extra work involved.
Herbert outlined some of the issues with using DOIs (digital object identifiers), which provide identifiers for resources that use a resolver to ensure that the identifier can remain the same over time. This is useful if, for example, a publisher is bought out – the identifier is still the same as the resolver redirects to the right location However, a DOI resolver exists in the perpetual now. It is not possible to travel back in time using HTTP URIs. This is maybe one illustration of the way some of the processes that we have implemented over the Web do not really fulfil our current needs, as things change and resources become more complex and dynamic.
With Memento, the same HTTP URI can function as the reference to temporally evolving resources. The importance of this type of functionality is becoming more recognised. There is a new experimental URI scheme, DURI , or Dated URI. The ideas is that a URI, such as http://www.ntnu.no, can be dated: 1997-06-17:http://www.ntnu.no (this is an example and is not actionable now). Herbert did raise another possibly of developing Websites that can deal with the TEL (telephone) protocol. The idea would be that the browser asks you whether the Website can use the TEL protocol, and if it can, you get this option offered to you. You can then use this and reference a resource and use Memento to go back in time.
Herbert concluded that the idea of ‘archiving’ should not be just a one-off event, but needs to happen continually. In fact, it could happen whenever there is an interaction. Also, when new materials are taken into a repository, you could scan for links and put them into an archive, so the links don’t die. If you archive the links at the time of publication or when materials submitted to a repository, then you protect against losing the context of the resource.
Herbert introduced us to SiteStory, which offers transactional archiving of a a web server. Usually a web archive sends out a robot, gathers and dumps the data. With SiteStory the web server takes an active part. Every time a user requests a page it is also pushed back into the archive, so you get a fine grained history of the resource. Something like this could be done by publishers/service providers, with the idea that they hold onto the hits, the impact, the audience. It certainly does seem to be a growing area of interest.
This is something that I’ve thought about quite a bit, as I work as the manager of an online service for Archives and I do training and teaching for archivists and archive students around creating online descriptions. I would like to direct this blog post to archive students or those considering becoming archivists. I think this applies equally to records managers, although sometimes they have a more defined role in terms of audience, so the perspective may be somewhat different.
It’s fine if you have ‘a love of history’, if you ‘feel a thrill when handling old documents’. That’s a good start. I’ve heard this kind of thing frequently as a motivation for becoming an archivist. But this is not enough. It is more important to have the desire to make those archives available to others; to provide a service for researchers. To become an archivist is to become a service provider, not an historian. It may not sound as romantic, but as far as I am concerned it is what we are, and we should be proud of the service we provide, which is extremely valuable to society. Understanding how researchers might use the archives is, of course, very important, so that you can help to support them in their work. Love of the materials, and love of the subject (especially in a specialist repository) should certainly help you with this core role. Indeed, you will build an understanding of your collections, and become more expert in them over time, which is one of the wonderful things about being an archivist.
Your core role is to make archives available to the community – for many of us, the community is potentially anyone, for some of us it may be more restricted in scope. So, you have an interest in the materials, you need to make them available. To do this you need to understand the vital importance of cataloguing. It is this that gives people a way in to the archives. Cataloguing is a real skill, not something to be dismissed as simply creating a list of what you have. It is something to really work on and think about. I have seen enough inconsistent catalogues over the last ten years to tell you that being rigorous, systematic and standards-based in cataloguing is incredibly important, and technology is our friend in this aim. Furthermore, the whole notion of ‘cataloguing’ is changing, a change led by the opportunities of the modern digital age and the perspectives and requirements of those who use technology in their every day life and work. We need to be aware of this, willing (even excited!) to embrace what this means for our profession and ready to adapt.
This brings me to the subject I am particularly interested in: the use of technology. Cataloguing *is* using technology, and dissemination *is* using technology. That is, it should be and it needs to be if you want to make an impact; if you want to effectively disseminate your descriptions and increase your audience. It is simply no good to see this profession as in any way apart from technology. I would say that technology is more central to being an archivist than to many professions, because we *deal in information*. It may be that you can find a position where you can keep technology at arm’s length, but these types of positions will become few and far between. How can you be someone who works professionally with information, and not be prepared to embrace the information environment? The Web, email, social networks, databases: these are what we need to use to do our jobs. We generally have limited resources, and technology can both help us make the most of the resources we have and, conversely, we may need to make informed choices about the technology we use and what sort of impact it will have. Should you use Flickr to disseminate content? What are the pros and cons? Is ‘augmented reality’ a reality for us? Should you be looking at Linked Data? What is is and why might it be important? What about Big Data? It may sound like the latest buzz phrase but it’s big business, and can potentially save time and money. Is your system fit for purpose? Does it create effective online catalogues? How interoperable is it? How adaptable?
Before I give the impression that you need to become some sort of technical whizz-kid, I should make clear that I am not talking about being an out-and-out techie – a software developer or programmer. I am talking about an understanding of technology and how to use it effectively. I am also talking about the ability to talk to technical colleagues in order to achieve this. Furthermore, I am talking about a willingness to embrace what technology offers and not be scared to try things out. It’s not always easy. Technology is fast-moving and sometimes bewildering. But it has to be seen as our ally, as something that can help us to bring archives to the public and to promote a greater understanding of what we do. We use it to catalogue, and I have written previously about how our choice of system has a great impact on our catalogues, and how important it is to be aware of this.
Our role in using technology is really *all about people*. I often think of myself as the middleman, between the technology (the developers) and the audience. My role is to understand technology well enough to work with it, and work with experts, to harness it in order to constantly evolve and use it to best advantage, but also to constantly communicate with archivists and with researchers. To have an understanding of requirements and make sure that we are relevant to end-users. Its a role, therefore, that is about working with people. For most archivists, this role will be within a record office or repository, but either way, working with people is the other side of the coin to working with technology. They are both central to the world of archives.
If you wonder how you can possibly think about everything that technology has to offer: well, you can’t. But that’s why it is even more vital now than it has ever been to think of yourself as being in a collaborative profession. You need to take advantage of the experience and knowledge of colleagues, both within the archives profession and further afield. It’s no good sitting in a bubble at your repository. We need to talk to each other and benefit from sharing our understanding. We need to be outgoing. If you are an introvert, if you are a little shy and quiet, that’s not a problem; but you may have to make a little more effort to engage and to reach out and be an active part of your profession.
They say ‘never work with children and animals’ in show business because both are unpredictable; but in our profession we should be aware that working with people and technology is our bread and butter. Understanding how to catalogue archives to make them available online, to use social networks to communicate our messages, to think about systems that will best meet the needs of archives management, to assess new technologies and tools that may help us in our work. These are vital to the role of a modern professional archivist.
Mimas works on exciting and innovative projects all the time and we wanted Hub blog readers to find out more about the SCARLET project, where Mimas staff, academics from the University of Manchester and the archive team at John Rylands University Library are exploring how Augmented Reality can bring resources held in special collections to life by surrounding original materials with digital online content.
The Project
Special Collections using Augmented Reality to Enhance Learning and Teaching (SCARLET)
SCARLET addresses one of the principal obstacles to the use of Special Collections in teaching and learning – the fact that students must consult rare books, manuscripts and archives within the controlled conditions of library study rooms. The material is isolated from the secondary, supporting materials and the growing mass of related digital assets. This is an alien experience for students familiar with an information-rich, connected wireless world, and is a barrier to their use of Special Collections.
The SCARLET project will provide a model that other Special Collections libraries can follow, making these resources accessible for research, teaching and learning. If you are interested in creating similar ‘apps’ and using the toolkit created by the team then please get in touch.
The academic year is now in full swing and JRUL Special Collections staff are busy delivering ‘close-up’ sessions and seminars for undergraduate and postgraduate students.
A close-up session typically involves a curator and an academic selecting up to a dozen items to show to a group of students. The items are generally set out on tables and everyone gathers round for a discussion. It is a real thrill for students to see Special Collections materials up close, and in some circumstances to handle the items themselves. The material might be papyri from Greco-Roman Egypt, medieval manuscripts, early printed books, eighteenth-century diaries and letters, or modern literary archives: the range of our Special Collections is vast.
Dr Guyda Armstrong shows her students a selection of early printed editions of Dante.
From our point of view, it’s really rewarding and enlightening to work alongside enthusiastic teachers such as Guyda Armstrong, Roberta Mazza and Jerome de Groot. The ideal scenario is a close partnership between the academic and the curator. Curators know the collections well, and we can discuss with students the materiality of texts, technical aspects of books and manuscripts, the context in which texts and images were originally produced, and the afterlife of objects – the often circuitous routes by which they have ended up in the Rylands Library. Academics bring to the table their incredible subject knowledge and their pedagogical expertise. Sparks can fly, especially when students challenge what they are being told!
This week I have been involved in close-up sessions for Roberta Mazza’s ‘Egypt in the Graeco-Roman World’ third-year Classics course, and Guyda Armstrong’s ‘Beyond the Text’ course on Dante, again for third-year undergraduates. Both sessions were really enjoyable, because the students engaged deeply with the material and asked lots of questions. But the sessions also reinforced my belief that Augmented Reality will allow us to do so much more. AR will make the sessions more interactive, moving towards an enquiry-based learning model, where we set students real questions to solve, through a combination of close study of the original material, and downloading metadata, images and secondary reading, to help them interrogate and interpret the material. Already Dr Guyda Armstrong’s students have had a sneak preview of the Dante app, and I’m look forward to taking part in the first trials of the app in a real teaching session at Deansgate in a few weeks’ time.
For many years Special Collections have been seen by some as fusty and dusty. AR allows us to bring them into the age of app.
The Horizon Report is an excellent way to get a sense of emerging and developing technologies, and it is worth thinking about what they might mean for archives. In this post I concentrate on the key trends that are featured for the next 1-4 years.
Electronic Books
“[E]lectronic books are beginning to demonstrate capabilities that challenge the very definition of reading.”
Electronic books promise not just convenience, but also new ways of thinking about reading. They encourage interactive, social and collaborative approaches. Does this have any implications for archives? Most archives are paper-based and do not lend themselves so well to this kind of approach. We think of consulting archives as a lone pursuit, in a reading room under carefully controlled conditions. The report refers to “a dynamic journey that changes every time it is opened.” An appealing thought, and indeed we might feel that archives also offer this kind of journey. Increasingly we have digital and born-digital archives, but could these form part of a more collaborative and interactive way of learning? Issues of authenticity, integrity and intellectual property may mitigate against this.
Whilst we may find it hard to see how archives may not become a part of this world – we are talking about archives, after all, and not published works – there may still be implications around the ways that people start to think about reading. Will students become hooked on rich and visual interfaces and collaborative opportunities that simply do not exist with archives?
Mobiles
“According to a recent report from mobile manufacturer Ericsson, studies show that by 2015, 80% of people accessing the Internet will be doing so from mobile devices.”
Mobiles are a major part of the portable society. Archive repositories can benefit from this, ensuring that people can always browse their holdings, wherever they are. We need to be involved in mobile innovation. As the report states: “Cultural heritage organizations and museums are also turning to mobiles to educate and connect with audiences.” We should surely see mobiles as an opportunity, not a problem for us, as we increasingly seek to broaden our user-base and connect with other domains. Take a look at the ‘100 most educational iPhone Apps‘. They include a search of US historical documents with highlighting and the ability to add notes.
Augmented Reality
We have tended to think of augmented reality as something suitable for marketing, social engagement and amuseument. But it is starting to provide new opportunities for learning and changing expectations around access to information. This could provide opportunities for archives to engage with users in new ways, providing a more visual experience. Could it provide a means to help people understand what archives are all about? Stanford University in the US has created an island in Second Life. The unique content that the archives provide was seen as something that could draw visitors back and showcase the extensive resources available. Furthermore, they created a ‘virtual archives’, giving researchers an opportunity to explore the strong rooms, discover and use collections and collaborate in real time.
The main issue around using these kinds of tools is going to be the lack of skills and resources. But we may still have a conflict of opinions over whether virtual reality really has a place in ‘serious research’. Does it trivialize archives and research? Or does it provide one means to engage younger potential users of archives in a way that is dynamic and entertaining? I think that it is a very positive thing if used appropriately. The Horizon Report refers to several examples of its use in cultural heritage: the Getty Museum are providing ‘access’ to a 17th century collector’s cabinet of wonders; the Natural History Museum in London are using it in an interactive video about dinosaurs; the Museum of London are using it to allow people to view 3D historical images overlaid on contemporary buildings. Another example is the Powerhouse Museum in Sydney, using AR to show the environment around the Museum 100 years ago. In fact, AR does seem to lend itself particularly well to teaching people about the history around them.
Game-Based Learning
Another example of blending entertainment with learning, games are becoming increasingly popular in higher education, and the Serious Games movement is an indication of how far we have come from the notion that games are simply superficial entertainment. “[R]esearch shows that players readily connect with learning material when doing so will help them achieve personally meaningful goals.” For archives, which are often poorly understood by people, I think that gaming may be one possible means to explain what archives are, how to navigate through them and find what may be of interest, and how to use them. How about something a bit like this Smithsonian initiative, Ghosts of a Chance, but for archives?
These technologies offer new ways of learning, but they also suggest that our whole approach to learning is changing. As archivists, we need to think about how this might impact upon us and how we can use it to our advantage. Archives are all about society, identity and story. Surely, therefore, these technologies should give us opportunities to show just how much they are a part of our life experiences.
Democracy 2.0: A Case Study in Open Government from across the pond.
I have just listened to a presentation by David Ferriero – 10th Archivist of the US at the National Archives and Records Administration (www.archives.gov). He was talking about democracy, about being open and participatory. He contrasted the very early days of American independence, where there was a high level of secrecy in Government, to the current climate, where those who make decisions are not isolated from the citizens, and citizens’ voices can be heard. He referred to this as ‘Democracy 2.0.’ Barack Obama set out his open government directive right from the off, promoting the principles of more transparecy, participation and collaboration. Ferriero talked about seeking to inform, educate and maybe even entertain citizens.
The backbone of open government must be good record keeping. Records document individual rights and entitlements, record actions of government and who is responsible and accountable. They give us the history of the national experience. Only 2-3 percent of records created in conducting the public’s business are considered to be of permanent value and therefore kept in the US archives (still, obviously, a mind-bogglingly huge amount of stuff).
Ferriero emphasised the need to ensure that Federal records of historical value are in good order. But there are still too many records are at risk of damange or loss. A recent review of record keeping in Federal Agencies showed that 4 out of 5 agencies are at high or moderate risk of improper destruction of records. Cost effective IT solutions are required to address this, and NARA is looking to lead in this area. An electronic records archive (ERA) is being build in partnership with the private sector to hold all the Federal Government’s electronic records, and Ferriero sees this as the priority and the most important challenge for the National Archives. He felt that new kinds of records create new challenges, that is, records created as result of social media, and an ERA needs to be able to take care of these types of records.
Change in processes and change in culture is required to meet the new online landscape. The whole commerce of information has changed permanently and we need to be good stewards of the new dynamic. There needs to be better engagement with employees and with the public. NARA are looking to improve their online capabilities to improve the delivery of records. They are developing their catalogue into a social catalogue that allows users to contribute and using Web 2.0 tools to allow greater communication between staff. They are also going beyond their own website to reach users where they are, using YouTube, Twitter, blogs, etc. They intend to develop comprehensive social media strategy (which will be well worth reading if it does emerge).
The US Government are publishing high value datasets on data.gov and Ferriero said that they are eager to see the response to this, in terms of the innovative use of data. They are searching for ways to step of digitisation – looking at what to prioritise and how to accomplish the most with least cost. They want to provide open government leadership to Federal Agencies, for example, mediating in disputes relating to FoI. There are around 2,000 different security classification guides in the government, which makes record processing very comlex. There is a big backlog of documents waiting to be declassified, some pertaining to World War Two, the Koeran War and the Vietnam War, so they will be of great interest to researchers.
Ferriero also talked about the challenge of making the distiction between business records and personal records. He felt that the personal has to be there, within the archive, to help future researchers recreate the full picture of events.
There is still a problem with Government Agencies all doing their own thing. The Chief Information officers of all agencies have a Council (the CIO Council). The records managers have the Records Management Council. But it is a case of never the twain shall meet at the moment. Even within Agencies the two often have nothing to do with eachother….there are now plans to address this!
This was a presentation that ticked many of the boxes of concern – the importance of addressing electronic records, new media, bringing people together to create efficiencies and engaging the citizens. But then, of course, it’s easy to do that in words….