In 1983 the government allocated the papers of Arthur Wellesley, first Duke of Wellington, the long serving politician and the premier soldier of his generation, to the University of Southampton under national heritage legislation. The collection arrived on 17 March of that year. This brought to Southampton the University’s first major manuscript collection, leading to the creation of an Archives Department and the development of a major strand of activity within the University Library.
Official opening of the Wellington Suite Archives accommodation: Mr Naylor, University Librarian, Professor Smith, Department of History (hidden), Mr. Woolgar, Archivist, and the Duke of Wellington looking at display of papers, 14 May 1983. [MS1/Phot/39/ph3526]
Composed of around 100,000 items that cover the Duke’s career as a soldier, statesman and diplomat from 1790 to his death in 1852, the collection bears witness to great military, political and social events of the time. It is exceptional among the papers of nineteenth-century figures for its size and scope.
Plan of Seringapatam at the time of its capture by Wellington, early 19th century [MS61/WP15/6]
Wellington’s time in India, 1798-1805, when he made his fortune and his name as a military commander, is well represented by three series of letter books, the first two series arranged chronologically, with the third, covering 1802-5, arranged by correspondent. The sections for the Peninsular War (1808-14) and for the Waterloo campaign provide an unrivalled source for the history of British participation. The collection also includes Wellington’s correspondence and papers for the congresses at the end of the Napoleonic wars and the allied occupation of France, 1815-18, a period when Wellington was a major player on the European political scene.
Letter from Wellington to Lord Bathurst after the battle of Vitoria using the phrase ‘scum of the earth’, 1813 [MS61/WP1/373/6]
Wellington was involved in politics throughout his career, serving as an MP in the Irish parliament in the 1780s onwards and as Chief Secretary for Ireland, 1807-9. There is considerable material for his political career post 1818, including two times as prime minister, as well as for his role as Lord Lieutenant of Hampshire and as Commander in Chief of the Army. Amongst the extensive number of cabinet papers, drafted in the Duke’s own hand is the memorandum written by Wellington and Peel setting out the details of the Catholic emancipation act of 1829. Material from his tenure as Lord Lieutenant of Hampshire includes death threats from Captain Swing dating from the Swing riots around the southern counties of England.
Letter to Wellington, signed “Swing” threatening assassination, n.d. c. 8 November 1830 [MS61/WP1/1159/114]
As the archive is from the great age of government by correspondence, as well as coinciding with a wider revolution in communication, it contains material from a wide cross section of society. Everyone wrote to the Duke of Wellington, offering the national hero their views on a whole range of subjects, asking for patronage, promotion or assistance, wishing to dedicate their works to him, or asking him to be the godfather of their children or to be allowed to name them after him. In response to one letter, Wellington noted with his usual acerbic wit the inconvenience of calling all boys born on his birth by the name “Arthur”.
Cataloguing the Wellington Archive in the 1980s using BBC microcomputers.
The arrival of the Wellington Archive in 1983 was significant in another way in that it marked the beginning of Southampton’s long involvement in automated archive catalogues. The Wellington Papers Database could claim to be one of, if the not the earliest, online archive catalogue in the UK. Investigations into a system to support this were already underway in December 1982, prior to the arrival of the papers. In July 1983 the University decided to develop a manuscript cataloguing system using STATUS software and it was in use for cataloguing material early the following year. The cataloguing was done “offline” by the archivists on BBC microcomputers equipped with rudimentary word-processing packages – but no memory – and all text was saved onto floppy discs. It was subsequently transferred to an ICL mainframe computer for incorporation into the database by batch programme. This being the days prior to the WWW, the initial database was made available by the Joint Academic Network (JANET) and the public switched telephone network. It was initially scheduled to be made available 156 hours a week, rising to 168. In 2023 the catalogue of the Wellington Archive can be accessed in the Epexio Archive Catalogue, a new system that we launched in November 2021.
The collection also came with a major conservation challenge – some ten percent of the collection was so badly damaged it was unfit to handle and in a parlous state. Considerable progress has been made in addressing this. Important material is now available for research, including for the Peninsular War, papers for 1822 (for the Congress of Verona) and for Wellington as Prime Minister in 1829. The badly degraded and mould-damaged bundles from 1832, significant as the time of the First Reform Act, are available for the first time since 1940.
19th Wellington Lecture – Martin Carthy.
The last forty years also has seen a great deal of outreach and activity focused on the Wellington Archive. As well as research and teaching sessions, drop-in sessions, events and exhibitions, the Archives Department has arranged six international Wellington congresses. In 2015 and 2017 Karen Robson and Professor Chris Woolgar presented a MOOC they had co-created relating to Wellington and Waterloo. And since 1989 there has been the annual Wellington Lecture with speakers or presenters ranging from Elizabeth Longford to Martin Carthy.
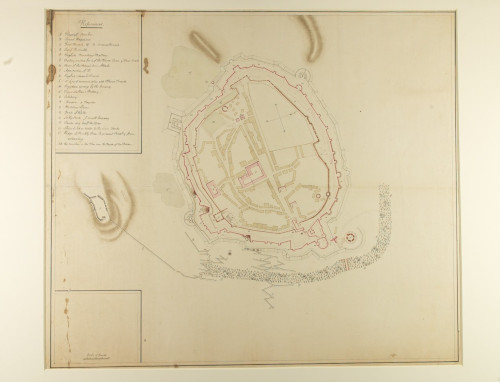
As those of you who contribute to or use the Hub will know, we went live with our new system in Dec 2016. At the heart of our new system is our new workflow. One of the key requirements that we set out with when we migrated to a new system was a more robust and sustainable workflow; the system was chosen on the basis that it could accommodate what we needed.
This post is about the EAD (Encoded Archival Data) descriptions, and how they progress through our processing workflow. It is the data that is at the heart of the Archives Hub world. We also work with EAG (Encoded Archival Guide) for repository descriptions, and EAC-CPF (Encoded Archival Context, Corporate bodies, Persons and Families) for name entities. Our system actually works with JSON internally, but EAD remains our means of taking in data and providing data out via our API.
On the Archives Hub now we have two main means of data ingest, via our own EAD Editor, which can be thought of as ‘internal’, and via exports from archive systems, which can be thought of as ‘external’.
Data Ingest via the EAD Editor
1. The nature of the EAD
The Editor creates EAD according to the Archives Hub requirements. These have been carefully worked out over time, and we have a page detailing them at http://archiveshub.jisc.ac.uk/eadforthehub
Part of a Hub webpage about EAD requirements
When we started work on the new system, we were aware that having a clear and well-documented set of requirements was key. I would recommend having this before starting to implement a new system! But, as is often the case with software development, we didn’t have the luxury of doing that – we had to work it out as we went along, which was sometimes problematic, because you really need to know exactly what your data requirements are in order to set your system up. For example, simply knowing which fields are mandatory and which are not (ostensibly simple, but in reality this took us a good deal of thought, analysis and discussion).
EAD Editor
2. The scope of the EAD
EAD has plenty of tags and attributes! And they can be used in many ways. We can’t accommodate all of this in our Editor. Not only would it take time and effort, but it would result in a complicated interface, that would not be easy to use.
EAD Tag Library
So, when we created the new Editor, we included the tags and attributes for data that contributors have commonly provided to the Hub, with a few more additions that we discussed and felt were worthwhile for various reasons. We are currently looking again at what we could potentially add to the Editor, and prioritising developments. For example, the <materialspec> EAD tag is not accommodated at the moment. But if we find that our contributors use it, then there is a good argument for including it, as details specific to types of materials, such as map scales, can be useful to the end user.
We don’t believe that the Archives Hub necessarily needs to reflect the entire local catalogue of a contributor. It is perfectly reasonable to have a level of detail locally that is not brought across into an aggregator. Having said that, we do have contributors who use the Archives Hub as their sole online catalogue, so we do want to meet their needs for descriptive data. Field headings are an example of content we don’t utilise. These are contained within <head> tags in EAD. The Editor doesn’t provide for adding these. (A contributor who creates data elsewhere may include <head> tags, but they just won’t be used on the Hub, see Uploading to the Editor).
We will continue to review the scope in terms of what the Editor displays and allows contributors to enter and revise; it will always be a work in progress.
3. Uploading to the Editor
In terms of data, the ability to upload to the Editor creates challenges for us. We wanted to preserve this functionality, as we had it on the old Editor, but as EAD is so permissive, the descriptions can vary enormously, and we simply can’t cope with every possible permutation. We undertake the main data analysis and processing within our main system, and trying to effectively replicate this in the Editor in order to upload descriptions would be duplicating effort and create significant overheads. One of our approaches to this issue is that we will preserve the data that is uploaded, but it may not display in the Editor. If you think of the model as ‘data in’ > ‘data editing’ > ‘data out’, then the idea is that the ‘data in’ and ‘data out’ provides all the EAD, but the ‘data editing’ may not necessary allow for editing of all the data. A good example of this situation occurs with the <head> tag, which is used for section headings. We don’t use these on the Hub, but we can ensure they remain in the EAD and they are there in the output from the Editor, so they are retained, but not displayed in the Editor. They can then be accessed by other means, such as through an XML Editor, and displayed in other interfaces.
We have disabled upload of exports from the Calm system to the Editor at present, as we found that the data variations, which often caused the EAD to be invalid, were too much for our Editor to cope with. It has to analyse the data that comes in and decide which fields to populate with which data. Some are straightforward – ‘title’ goes into <unittitle> for example, but some are not…for example, Calm has references and alternative references, and we don’t have this in our system, so they cause problems for the Editor.
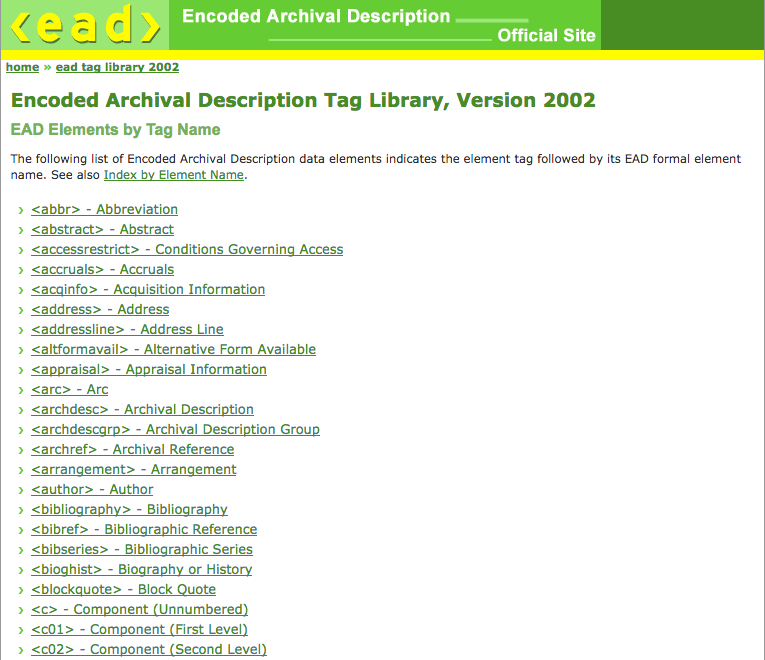
4. Output from the Editor
When a description is submitted to the Archives Hub from the Editor, it is uploaded to our system (CIIM, pronounced ‘sim’), which is provided by Knowledge Integration, and modified for our own data processing requirements.
CIIM Browse screen
The CIIM framework allows us to implement data checking and customised transformations, which can be specific to individual repositories. For the data from the Editor, we know that we only need a fairly basic default processing, because we are in control of the EAD that is created. However, we will have to consider working with EAD that is uploaded to the Editor, but has not been created in the Editor – this may lead to a requirement for additional data checking and transformations. But the vast majority of the time descriptions are created in the Editor, so we know they are good, valid, Hub EAD, and they should go through our processing with no problems.
Data Ingest from External Data Providers
1. The nature of the EAD
EAD from systems such as Calm, Archivist’s Toolkit and AtoM is going to vary far more than EAD produced from the Editor. Some of the archival management systems have EAD exports. To have an export is one thing; it is not the same as producing EAD that the Hub can ingest. There are a number of factors here. The way people catalogue varies enormously, so, aside from the system itself, the content can be unpredictable – we have to deal with how people enter references; how they enter dates; whether they provide normalised dates for searching; whether entries in fields such as language are properly divided up, or whether one entry box is used for ‘English, French, Latin’, or ‘English and a small amount of Latin’; whether references are always unique; whether levels are used to group information, rather than to represent a group of materials; what people choose to put into ‘origination’ and if they use both ‘origination’ and ‘creator’; whether fields are customised, etc. etc.
The system itself will influence on the EAD output. A system will have a template, or transformation process, that maps the internal content to EAD. We have only worked in any detail with the Calm template so far. Axiell, the provider of Calm, made some changes for us, for example, only six languages were exporting when we first started testing the export, so they expanded this list, and then we made additional changes, such as allowing for multiple creators, subjects and dates to export, and ensuring languages in Welsh would export. This does mean that any potential Calm exporter needs to use this new template, but Axiell are going to add it to their next upgrade of Calm.
We are currently working to modify the AdLib template, before we start testing out the EAD export. Our experience with Calm has shown us that we have to test the export with a wide variety of descriptions, and modify it accordingly, and we eventually get to a reasonably stable point, where the majority of descriptions export OK.
We’ve also done some work with AtoM, and we are hoping to be able to harvest descriptions directly from the system.
2. The scope of the EAD
As stated above, finding aids can be wide ranging, and EAD was designed to reflect this, but as a result it is not always easy to work with. We have worked with some individual Calm users to extend the scope of what we take in from them, where they have used fields that were not being exported. For instance, information about condition and reproduction was not exporting in one case, due to the particular fields used in Calm, which were not mapping to EAD in the template. We’ve also had instances of index terms not exporting, and sometimes this had been due to the particular way an institution has set up their system. It is perfectly possible for an institution to modify the template themselves so that it suits their own particular catalogues, but this is something we are cautious about, as having large numbers of customised exports is going to be harder to manage, and may lead to more unpredictable EAD.
3. Uploading to the Editor
In the old Hub world, we expected exports to be uploaded to the Editor. A number of our contributors preferred to do this, particularly for adding index terms. However, this lead to problems for us because we ended up with such varied EAD, which mitigated against our aim of interoperable content. If you catalogue in a system, export from that system, upload to another system, edit in that system, then submit to an aggregator (and you do this sometimes, but other times you don’t), you are likely to run into problems with version control. Over the past few years we have done a considerable amount of work to clarify ‘master’ copies of descriptions. We have had situations where contributors have ended up with different versions to ours, and not necessarily been aware of it. Sometimes the level of detail would be greater in the Hub version, sometimes in the local version. It led to a deal of work sorting this out, and on some occasions data simply had to be lost in the interests of ending up with one master version, which is not a happy situation.
We are therefore cautious about uploading to the Editor, and we are recommending to contributors that they either provide their data directly (through exports) or they use the Editor. We are not ruling out a hybrid approach if there is a good reason for it, but we need to be clear about when we are doing this, what the workflow is, and where the master copy resides.
4. Output from Exported Descriptions
When we pass the exports through our processing, we carry out automated transformations based on analysis of the data. The EAD that we end up with – the processed version – is appropriate for the Hub. It is suitable for our interface, for aggregated searching, and for providing to others through our APIs. The original version is kept, so that we have a complete audit trail, and we can provide it back to the contributor. The processed EAD is provided to the Archives Portal Europe. If we did not carry out the processing, APE could not ingest many of the descriptions, or else they would ingest, but not display to the optimum standard.
Future Developments
Our automated workflow is working well. We have taken complete, or near complete, exports from Calm users such as the Universities of Nottingham, Hull and (shortly) Warwick, and a number of Welsh local authority archives. This is a very effective way to ensure that we have up-to-date and comprehensive data.
We have well over one hundred active users of the EAD Editor and we also have a number of potential contributors who have signed up to it, keen to be part of the Archives Hub.
We intend to keep working on exports, and also hope to return to some work we started a few years ago on taking in Excel data. This is likely to require contributors to use our own Excel template, as it is impractical to work with locally produced templates. The problem is that working with one repository’s spreadsheet, translating it into EAD, could take weeks of work, and it would not replicate to other repositories, who will have different spreadsheets. Whilst Excel is reasonably simple, and most offices have it, it is also worth bearing in mind that creating data in Excel has considerable shortcomings. It is not designed for hierarchical archival data, which has requirements in terms of both structure and narrative, and is constantly being revised. TNA’s Discovery are also working with Excel, so we may be able to collaborate with them in progressing this area of work.
Our new architecture is working well, and it is gratifying to see that what we envisaged when we started working with Knowledge Integration and started setting out our vision for our workflow is now a reality. Nothing stands still in archives, in standards, in technology or in user requirements, so we cannot stand still either, but we have a set-up that enables us to be flexible, and modify our processing to meet any new challenges.
This is the first post outlining what the Archives Hub team have been up to over the past 18 months in creating a new system. We have worked with Knowledge Integration (K-Int) to create a new back end, using their CIIM software and Elastic Search, and we’ve worked with Gooii and Sero to create a new interface. We are also building a new EAD Editor for cataloguing. Underlying all this we have a new data workflow and we will be implementing this through a new administrative interface. This post summarises some of the building blocks – our overall approach, objectives and processes.
What did we want to achieve?
The Archives Hub started off as a pilot project and has been running continuously as a service aggregating UK archival descriptions since 1999 (officially launched in 2001). That’s a long time to build up experience, to try things out, to have successes and failures, and to learn from mistakes.
The new Hub aimed to learn lessons from the past and to build positively upon our experiences.
Our key goals were:
sustainability
extensibility
reusability
Within these there is an awful I could unpack. But to keep it brief…
It was essential to come up with a system that could be maintained with the resources we had. In fact, we aimed to create a system that could be maintained to a basic level (essentially the data processing) with less effort than before. This included enabling contributors to administer their own data through access to a new interface, rather than having to go through the Hub team. Our more automated approach to basic processing would give us more resource to concentrate on added value, and this is essential in order to keep the service going, because a service has to develop to remain relevant and meet changing needs.
The system had to be ‘future proof’ to the extent that we could make it so. One way to achieve this is to have a system that can be altered and extended over time; to make sure it is reasonably modular so that elements can be changed and replaced.
Key for us was that we wanted to end up with a store of data that could potentially be used in other interfaces and services. This is a substantial leap from thinking in terms of just servicing your own interface. But it is essential in the global digital age, and when thinking about value and impact, to think beyond your own environment and think in terms of opportunities for increasing the profile and use of archives and of connecting data. There can be a tension between this kind of objective of openness and the need to clearly demonstrate the impact of the service, as you are pushing data beyond the bounds of your own scope and control, but it is essential for archives to be ‘out there’ in the digital environment, and we cannot shy away from the challenges that this raises.
In pursuing these goals, we needed to bring our contributors along with us. Our aims were going to have implications for them, so it was important to explain what we were doing and why.
Data Model for Sustainability
It is essential to create the right foundation. At the heart of what we do is the data (essentially meaning the archive descriptions, although future posts will introduce other types of data, namely repository descriptions and ‘name authorities’). Data comes in, is processed, is stored and accessed, and it flows out to other systems. It is the data that provides the value, and we know from experience that the data itself provides the biggest challenges.
The Archives Hub system that we originally created, working with the University of Liverpool and Cheshire software, allowed us to develop a successful aggregator, and we are proud of the many things we achieved. Aggregation was new, and, indeed, data standards were relatively new, and the aim was essentially to bring in data and provide access to it via our Archives Hub website. The system was not designed with a focus on a consistent workflow and sustainability was something of an unknown quantity, although the use of Encoded Archival Description (EAD) for our archive collection descriptions gave us a good basis in structured data. But in recent years the Hub started to become out of step with the digital environment.
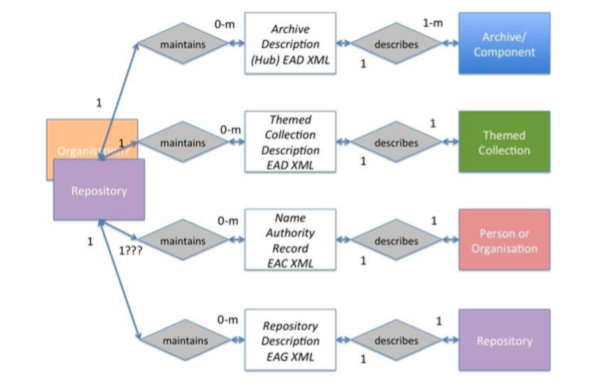
For the new Hub we wanted to think about a more flexible model. We wanted the potential to add new ‘entities’. These may be described as any real world thing, so they might include archive descriptions, people, organisations, places, subjects, languages, repositories and events. If you create a model that allows for representing different entities, you can start to think about different perspectives, different ways to access the data and to connect the data up. It gives the potential for many different contexts and narratives.
We didn’t have the time and resource to bring in all the entities that we might have wanted to include; but a model that is based upon entities and relationships leaves the door open to further development. We needed a system that was compatible with this way of thinking. In fact, we went live without the ‘People and Organisations’ entity that we have been working on, but we can implement it when we are ready because the system allows for this.
Entities within the Archives Hub system
The company that we employed to build the system had to be able to meet the needs of this type of model. That made it likely that we would need a supplier who already had this type of system. We found that with Knowledge Integration, who understood our modelling and what we were trying to achieve, and who had undertaken similar work aggregating descriptions of museum content.
Data Standards
The Hub works with Encoded Archival Description, so descriptions have to be valid EAD, and they have to conform to ISAD(G) (which EAD does). Originally the Hub employed a data editor, so that all descriptions were manually checked. This has the advantage of supporting contributors in a very 1-2-1 way, and working on the content of descriptions as well as the standardisation (e.g. thinking about what it means to have a useful title as well as thinking about the markup and format) and it was probably essential when we set out. But this approach had two significant shortcomings – content was changed without liaising with the contributor, which creates version control issues, and manual checking inevitably led to a lack of consistency and non-repeatable processes. It was resource intensive and not rigorous enough.
In order to move away from this and towards machine based processing we embarked upon a long process, over several months, of discussing ‘Hub data requirements’. It sometimes led to brain-frying discussions, and required us to make difficult decisions about what we would make mandatory. We talked in depth about pretty much every element of a description; we talked about levels of importance – mandatory, recommended, desirable; we asked contributors their opinions; we looked at our data from so many different angles. It was one of the more difficult elements of the work. Two brief examples of this (I could list many more!):
Name of Creator
Name of creator is an ISAD(G) mandatory field. It is important for an understanding of the context of an archive. We started off by thinking it should be mandatory and most contributors agreed. But when we looked at our current data, hundreds of descriptions did not include a name of creator. We thought about whether we could make it mandatory for a ‘fonds’ (as opposed to an artificial collection), but there can be instances where the evidence points to a collection with a shared provenance, but the creator is not known. We looked at all the instances of ‘unknown’ ‘several’, ‘various’, etc within the name of creator field. They did not fulfill the requirement either – the name of a creator is not ‘unknown’. We couldn’t go back to contributors and ask them to provide a creator name for so many descriptions. We knew that it was a bad idea to make it mandatory, but then not enforce it (we had already got into problems with an inconsistent approach to our data guidelines). We had to have a clear position. For me personally it was hard to let go of creator as mandatory! It didn’t feel right. It meant that we couldn’t enforce it with new data coming in. But it was the practical decision because if you say ‘this is mandatory except for the descriptions that don’t have it’ then the whole idea of a consistent and rigorous approach starts to be problematic.
Access Conditions
This is not an ISAD(G) mandatory field – a good example of where the standard lags behind the reality. For an online service, providing information about access is essential. We know that researchers value this information. If they are considering travelling to a repository, they need to be aware that the materials they want are available. So, we made this mandatory, but that meant we had to deal with something like 500 collections that did not include this information. However, one of the advantages of this type of information is that it is feasible to provide standard ‘boiler plate’ text, and this is what we offered to our contributors. It may mean some slightly unsatisfactory ‘catch all’ conditions of access, but overall we improved and updated the access information in many descriptions, and we will ask for it as mandatory with future data ingest.
Normalizing the Data
Our rather ambitious goal was to improve the consistency of the data, by which I mean reducing variation, where appropriate, with things like date formats, name of repository, names of rules or source used for index terms, and also ensuring good practice with globally unique references.
To simplify somewhat, our old approach led us to deal with the variations in the data that we received in a somewhat ad hoc way, creating solutions to fix specific problems; solutions that were often implemented at the interface rather than within the back-end system. Over time this led to a somewhat messy level of complexity and a lack of coherence.
When you aggregate data from many sources, one of the most fundamental activities is to enable it to be brought together coherently for search and display so oftentimes you are carrying out some kind of processing to standardise in some way. This can be characterised as simple processing and complex processing:
1) If X then Y
2) If X then Y or Z depending on whether A is present, and whether B and C match or do not match and whether the contributor is E or F.
The first example is straightforward; the second can get very complicated.
If you make these decisions as you go along, then after so many years you can end up with a level of complexity that becomes rather like a mass of lengths of string that have been tangled up in the middle – you just about manage to ensure that the threads in and out are still showing (the data in at one end; the data presented through interface the researcher uses at the other) but the middle is impossible to untangle and becomes increasingly difficult to manage.
This is eventually going to create problems for three main reasons. Firstly, it becomes harder to introduce more clauses to fix various data issues without unforeseen impacts, secondly it is almost impossible to carry out repeatable processes, and thirdly (and really as a result of the other two), it becomes very difficult to provide the data as one reasonably coherent, interoperable set of data for the wider world.
We needed to go beyond the idea of the Archives Hub interface being the objective; we needed to open up the data, to ensure that contributors could get the maximum impact from providing the data to the Archives Hub. We needed to think of the Hub not as the end destination but as a means to enable many more (as yet maybe unknown) destinations. By doing this, we would also set things up for if and when we wanted to make significant changes to our own interface.
This is a game changer. It sounds like the right thing to do, but the problem is that it meant tackling the descriptions we already had on the Hub to introduce more consistency. Thousands of descriptions with hundreds of thousands of units created over time, in different systems, with different mindsets, different ‘standards’, different migration paths. This is a massive challenge, and it wasn’t possible for us to be too idealistic; we had to think about a practical approach to transforming descriptions and creating descriptions that makes them more re-usable and interoperable. Not perfect, but better.
Migrating the Data
Once we had our Hub requirements in place, we could start to think about the data we currently have, and how to make sure it met our requirements. We knew that we were going to implement ‘pipelines’ for incoming data (see below) within the new system, but that was not exactly the same process as migrating data from old world to new, as migration is a one-off process. We worked slowly and carefully through a spreadsheet, over the best part of a year, with a line for each contributor. We used XSLT transforms (essentially scripts to transform data). For each contributor we assessed the data and had to work out what sort of processing was needed. This was immensely time-consuming and sometimes involved complex logic and careful checking, as it is very easy with global edits to change one thing and find knock-on effects elsewhere that you don’t want.
The migration process was largely done through use of these scripts, but we had a substantial amount of manual editing to do, where automation simply couldn’t deal with the issues. For example:
dates such as 1800/190, 1900-20-04, 8173/1878
non-unique references, often the result of human error
corporate names with surnames included
personal names that were really family names
missing titles, dates or languages
When working through manual edits, our aim was to liaise with the contributor, but in the end there was so much to do that we made decisions that we thought were sensible and reasonable. Being an archivist and having significant experience of cataloguing made me feel qualified to do this. With some contributors, we also knew that they were planning a re-submission of all their descriptions, so we just needed to get the current descriptions migrated temporarily, and a non-ideal edit might therefore be fine just for a short period of time. Even with this approach we ended have a very small number of descriptions that we could not migrate for the going live date because we needed more time to figure out how to get them up to the required standard.
Creating Pipelines
Our approach to data normalization for incoming descriptions was to create ‘pipelines’. More about this in another blog post, but essentially, we knew that we had to implement repeatable transformation processes. We had data from many different contributors, with many variations. We needed a set of pipelines so that we could work with data from each individual contributor appropriately.. The pipelines include things like:
fix problems with web links (where the link has not been included, or the link text has not been included)
Of course, for many contributors these processes will be the same – there would be a default approach, but we sometimes will need to vary the pipelines as appropriate for individual contributors. For example:
add access information where it is not present
use the ‘alternative reference’ (created in Calm) as the main reference
We will be implementing these pipelines in our new world, through the administration interface that K-Int have built. We’re just starting on that particular journey!
Conclusion
We were ambitious, and whilst I think we’ve managed to fulfill many of the goals that we had, we did have to modify our data standards to ‘lower the bar’ as we went along. It is far better to set data standards at the outset as changing them part way through usually has ramifications, but it is difficult to do this when you have not yet worked through all the data. In hindsight, maybe we should have interrogated the data we have much more to begin with, to really see the full extent of the variations and missing data…but maybe that would have put us off ever starting the project!
The data is key. If you are aggregating from many different sources, and you are dealing with multi-level descriptions that may be revised every month, every year, or over many years, then the data is the biggest challenge, not the technical set-up. It was essential to think about the data and the workflow first and foremost.
It was important to think about what the contributors can do – what is realistic for them. The Archives Hub contributors clearly see the benefits of contributing and are prepared to put what resources they can into it, but their resources are limited. You can’t set the bar too high, but you can nudge it up in certain ways if you give good reasons for doing so.
It is really useful to have a model that conveys the fundamentals of your data organisation. We didn’t apply the model to environment; we created the environment from the model. A model that can be extended over time helps to make sure the service remains relevant and meets new requirements.
One of our key aims at the Hub is to increase the range of archives who can contribute. Not just because we like having lots of contributors (we do!), but because we want to help open up hidden archive collections, and help archivists to make them discoverable online.
Used under a CC licence from http://www.flickr.com/photos/markkelley/157662318/
So, new for 2012 is Project Headway. Building on some work we’ve been doing over the past couple of years with Calm and Adlib to improve the EAD export, Project Headway aims to make it easier for archives to contribute to the Archives Hub. We’re especially thinking about archives with little or no online presence, who may not have archival management systems.
With this in mind, one of the things Headway is going to be looking at is producing an Excel template, to allow institutions which catalogue in Excel to convert their catalogues to EAD. This would mean that they could upload their descriptions to online catalogues (such as the Hub), as well as giving them a version of their data that’s in a robust, sustainable, platform-neutral format.
Project headway is scheduled to run until then end of June, and we’re also going to be looking at EAD exports from ICA-AtoM, the Archivist’s Toolkit, and Modes, as well as continuing our work with Calm and Adlib.
We hope to be able to expand on Headway work in the second half of the year, and look at other archival management systems, as well as export from Access databases.
If you’d like to know more about the project, want to volunteer to send us some descriptions, or have a system you’d like us to consider for phase 2, please get in touch!
We’ve started off 2012 with two new developers for Mimas, both of whom will be doing some work for the Hub. Neeta Patel will be working on the UKAD website and some of the Hub interface developments and challenging global edits to help us improve the consistency and utility of the data. We also have Lee Baylis, who is working on our Linked Data project, Linking Lives. He will be helping to design the interface, and is currently beavering away on some exciting ideas for how researchers could customise their display for our biographical interface.
Punctuation for Index Terms
Something that may seem small, but is mighty complicated to execute: Currently we have a mixture of index terms with punctuation and no punctuation. This is because some descriptions came to us with, some without, and some through our EAD Editor – which adds punctuation (so these descriptions are all fine).
Just go to browse and search for ‘andrews’, for example, to see what I mean. You can see:
Andrewes, Lancelot, 1555-1626, Bishop of Winchester
and
Andrews Barbara B 1829 Nee Campbell
The second is a little confusing without punctuation. But it is not easy to find a way to include punctuation for so many different names, with titles, dates, epithets, kings, queens, floruits, circas, etc. So, we are going to attempt to write scripts that will do this for us, and we’ll see how we go!
Alternative and Former Reference
We’ve taken a while, but finally we are displaying ‘former reference’ with an appropriate field heading. It has been complicated partly because descriptions with these references often come from the CALM software, and some contributors want the former reference to be the current reference, because they don’t use the CALM automatically generated reference, whilst most want it to be the former reference, and for some it is more of an alternative reference. Finding it impossible to attend to all these needs, we are displaying any reference that is labelled as ‘former reference’ in the markup with the name of ‘Alt. Ref. Number’. This is a compromise, and at least ensures that all references are displayed.
Assessment of ICA AtoM
The Archives Hub is undertaking a review of current software, and as part of this we are looking at ICA-AtoM (Access to Memory). We will be undertaking a fairly detailed assessment of the software, from installation through to upload, search, display and other aspects such as scalability, Google exposure and APIs. We feel that AtoM offers a number of advantages, as free open source software, conforming to archival standards and with the the ability to incorporate name authority records and controlled vocabularies. We are also attracted by the lively international community that has built up around AtoM, and the ethos of sharing and working together to improve the functionality.
It will be interesting to see how it compares to our current software, Cheshire 3, which offers many advantages and sophisticated functionality, build up over 10 years to meet the needs of the Hub and archival researchers. Cheshire has served us very well, and provides stiff competition for any rivals, but it is important to assess where we are and what is best for us going forwards. Looking at other systems offers us the opportunity to think about functionality and assess exactly what we need going forwards.
Why Contribute?
We are constantly updating our pages, and adding new ones. Recently we’ve revamped the ‘Why Contribute?’ page as well as creating a new page, Becoming a Contributor. If you know of any archivists interested in the Hub, maybe you could point them to these pages as a means to provide some compelling reasons to be part of the Hub!
New Contributors
Our two latest contributors illustrate admirably the great diversity of Hub repositories. We have the Freshwater Biological Association with a collection about lakes and rivers in Cumbria and Scotland (if you ever wanted to know about bacteria counts, for example…), and also the National Meteorological Archive looking for a fair outlook by promoting their collections on the Hub.
Open Data
Some of you may have seen the announcement of the Open Data Strategy by the European Commission. This is very much in line with the increasing move towards open data: “The best way to get value from data is to give it away”. The Archives Hub fully supports this ethos, and we will release all our data as open data unless any contributor wishes to opt out.
“Will you browse around my website”, said the spider to the fly,
‘Tis the most attractive website that you ever did spy”
All of us want to provide attractive websites for our users. Of course, we’d like to think its not really the spider/fly kind of relationship! But we want to entice and draw people in and often we will see our own website as our key web presence; a place for people to come to to find out about who we are, what we have and what we do and to look at our wares, so to speak.
The recently released ‘Discovery’ vision is to provide UK researchers with “easy, flexible and ongoing access to content and services through a collaborative, aggregated and integrated resource discovery and delivery framework which is comprehensive, open and sustainable.” Does this have any implications for the institutional or small-scale website, usually designed to provide access to the archives (or descriptions of archives) held at one particular location?
Over the years that I’ve been working in archives, announcements about new websites for searching the archives of a specific institution, or the outputs of a specific project have been commonplace. A website is one of the obvious outputs from time-bound projects, where the aim is often to catalogue, digitise or exhibit certain groups of archives held in particular repositories. These websites are often great sources of in-depth information about archives. Institutional websites are particularly useful when a researcher really wants to gain a detailed understanding of what a particular repository holds.
However, such sites can present a view that is based more around the provider of the information rather than the receiver. It could be argued that a researcher is less likely to want to use the archives because they are held at a particular location, apart from for reasons of convenience, and more likely to want archives around their subject area, and it is likely that the archives which are relevant to them will be held in a whole range of archives, museums and libraries (and elsewhere). By only looking at the archives held at a particular location, even if that location is a specialist repository that represents the researcher’s key subject area, the researcher may not think about what they might be missing.
Project-based websites may group together archives in ways that benefit researchers more obviously, because they are often aggregating around a specific subject area. For example, making available the descriptions and links to digital archives around a research topic. Value may be added through rich metadata, community engagement and functionality aimed at a particular audience. Sometimes the downside here is the sustainability angle: projects necessarily have a limited life-span, and archives do not. They are ever-changing and growing and descriptions need to be updated all the time.
So, what is the answer? Is this too much of a silo-type approach, creating a large number of websites, each dedicated to a small selection of archives?
Broader aggregation seems like one obvious answer. It allows for descriptions of archives (or other resources) to be brought together so that researchers have the benefit of searching across collections, bringing together archives by subject, place, person or event, regardless of where they are held (although there is going to be some kind of limit here, even if it is at the national level).
You might say that the Archives Hub is likely to be in favour of aggregation! But it’s definitely not all pros and no cons. Aggregations may offer a powerful search functionality for intellectually bringing together archives based on a researcher’s interests, but in some ways there is a greater risk around what is omitted. When searching a website that represents one repository, a researcher is more likely to understand that other archives may exist that are relevant to them. Aggregations tend to promote themselves as comprehensive – if not explicitly then implicitly – which this creates expectation that cannot ever fully be met. They can also raise issues around measuring impact and around licensing. There is also the risk of a proliferation of aggregation services, further confusing the resource discovery landscape.
Is the ideal of broad inter-disciplinary cross-searching going to be impeded if we compete to create different aggregations? Yes, maybe it will be to some extent, but I think that it is an inevitability, and it is valid for different gateways to service different audiences’ needs. It is important to acknowledge that researchers in different disciplines and at different levels have their own needs, their own specific requirements, and we cannot fulfill all of these needs by only presenting data in one way.
One thing I think is critical here is for all archive repositories to think about the benefits of employing recognised and widely-used standards, so that they can effectively interoperate and so that the data remains relevant and sustainable over time. This is the key to ensuring that data is agile, and can meet different needs by being used in different systems and contexts.
I do wonder if maybe there is a point at which aggregations become unwieldy, politically complicated and technically challenging. That point seems to be when they start to search across countries. I am still unsure about whether Europeana can overcome this kind of problem, although I can see why many people are so keen on making it work. But at present, it is extremely patchy, and , for example, getting no results for texts held in Britain relating to Shakespeare is not really a good result. But then, maybe the point is that Europeana is there for those that want to use it, and it is doing ground-breaking work in its focus on European culture; the Archives Hub exists for those interested in UK Archives and a more cross-disciplinary approach; Genesis exists for those interested in womens studies; for those interested in the Co-operative movement, there is the National Co-operative Archive site; for those researching film, the British Film Institute website and archive is of enormous value.
So, is the important principle here that diversity is good because people are diverse and have diverse needs? Probably so. But at the same time, we need to remember that to get this landscape, we need to encourage data sharing and avoid duplication of effort. Once you have created descriptions of your archive collections you should be able to put them onto your own website, contribute them to a project website, and provide them to an aggregator.
Ideally, we would be looking at one single store of descriptions, because as soon as you contribute to different systems, if they also store the data, you have version control issues. The ability to remotely search different data sources would seem to be the right solution here. However, there are substantial challenges. The Archives Hub has been designed to work in a distributed way, so that institutions can host their own data. The distributed searching does present challenges, but it certainly works pretty well. The problem is that running a server, operating system and software can actually be a challenge for institutions that do not have the requisite IT skills dedicated to the archives department. Institutions that hold their own data have it in a great variety of formats. So, what we really need is the ability for the Archives Hub to seamlessly search CALM, AdLib, MODES, ICA AtoM, Access, Excel, Word, etc. and bring back meaningful results. Hmmm….
The business case for opening up data seems clear. Project like Open Bibliographic Data have helped progress the thinking in this arena and raised issues and solutions around barriers such as licensing. But it seems clear that we need to understand more about the benefits of aggregation, and the different approaches to aggregation, and we need to get more buy-in for this kind of approach. Does aggregation allow users to do things that they could not do otherwise? Does it save them time? Does it promote innovation? Does it skew the landscape? Does it create problems for institutions because of the problems with branding and measuring impact? Furthermore, how can we actually measure these kinds of potential benefits and issues?
Websites that offer access to archives (or descriptions of archives) based on where they are located and based on they body that administers them have an important role to play. But it seems to me that it is vital that these archives are also represented on a more national, and even international stage. We need to bring our collections to where the users are. We need to ensure that Google and other search engines find our descriptions. We need to put archives at the heart of research, alongside other resources.
I remember once talking about the Archives Hub to an archivist who ran a specialist repository. She said that she didn’t think it was worth contributing to the Hub because they already had their own catalogue. That is, researchers could find what they wanted via the institute’s own catalogue on their own system, available in their reading room. She didn’t seem to be aware that this could only happen if they knew that the archive was there, and that this view rested on the idea that researchers would be happy to repeat that kind of search on a number of other systems. Archives are often about a whole wealth of different subjects – we all know how often there are unexpected and exciting finds. A specialist repository for any one discipline will have archives that reach way beyond that discipline into all sorts of fascinating areas.
It seems undeniable that data is going to become more open and that we should promote flexible access through a number of discovery routes, but this throws up challenges around version control, measuring impact, brand and identity. We always have to be cognisant of funding, and widely disseminated data does not always help us with a funding case because we lose control of the statistics around use and any kind of correlation between visits to our website and bums on seats. Maybe one of the challenges is therefore around persuading top-level managers and funders to look at this whole area with a new perspective?







")