Jisc aims to understand more about the student experience and student needs as part of its mission within UK higher and further education. The recent digital experience survey offers some useful findings about how students feel when it comes to digital skills and the digital experience.
37,720 students across 83 higher and further education institutions (HE and FE) are included in the data, equivalent to approximately 16% of colleges and 30% of universities in the UK.
Key findings are:
Students – regardless of setting – are positive about the quality of their institution’s digital provision, as well as digital teaching and learning on their course.
Over a third of all students want digital technologies to be used more on their course, although this does imply that the majority do not share this view.
Only 50% of FE and 69% of HE students think digital skills are important for their chosen career, and few agreed that their course prepares them for the digital workplace. This implies that there are many students who do not think digital skills are essential.
Many students bring their own devices to their institution but can’t use these to access subject-specialist software or online learning content. This indicates a lack of flexibility and interoperability.
One in five students use assistive or adaptive technologies, with 8% of HE and 6% of FE students considering these vital to their learning needs
About eight in ten students used a smartphone to support their learning, which is no surprise, and shows the importance of ensuring that sites are mobile-friendly
Around 10% of FE students rated Google search as their number one app or tool, compared with just over 1% of HE students. HE students on the other hand were twice as likely to cite Google Scholar as they were to cite Google on its own as a search tool. HE students also used a wider range of tools for online research, including online journals and journal catalogues.
A third of all students turned first to their fellow students when looking for support with digital devices or skills. A third of FE students turned first to their lecturers in comparison with only 8% of HE students. A third of HE students turned to online information in comparison with only 14% of FE students.
It appears that students feel there should be greater opportunities to work more flexibly, both in terms of device use and learning spaces, but overall the responses are generally positive in terms of the digital experience and there are high levels of overall satisfaction with institutional provision (FE: 74%, HE: 88%) and the quality of teaching and learning on students’ courses (FE: 72%, HE: 74%).
Last week I attended a very full and lively Europeana Tech conference. Here are some of the main initiatives and ideas I have taken away with me:
Think in terms of improvement, not perfection
Do the best you can with what you have; incorrect data may not be as bad as we think and maybe users expectations are changing, and they are increasingly willing to work with incomplete or imperfect data. Some of the speakers talked about successful crowd-sourcing – people are often happy to correct your metadata for you and a well thought-out crowd-sourcing project can give great results.
BL Georeferencer, showing an old map overlaying part of Manchester: http://www.bl.uk/maps/georeferencingmap.html
The British Library currently have an initiative to encourage tagging of their images on Flickr Commons and they also have a crowd-sourcing geo-referencer project.
The Cooper Hewitt Museum site takes a different and more informal approach to what we might usually expect from a cultural heritage site. The homepage goes for an honest approach:
“This is a kind of living document, meaning that development is ongoing — object research is being added, bugs are being fixed, and erroneous terms are being revised. In spite of the eccentricities of raw data, you can begin exploring the collection and discovering unexpected connections among objects and designers.”
The ‘here is some stuff’ and ‘show me more stuff’ type of approach was noticeable throughout the conference, with different speakers talking about their own websites. Seb Chan from the Cooper Hewitt Museum talked about the importance of putting information out there, even if you have very little, it is better than nothing (e.g. https://collection.cooperhewitt.org/objects/18446665).
The speaker from Google, Chris Welty, is best known for his work on ontologies in the Semantic Web and IBM’s Watson. He spoke about cognitive computing, and his message was ‘maybe it’s OK to be wrong’. Something may well still useful, even if it is not perfectly precise. We are increasingly understanding that the Web is in a state of continuous improvement, and so we should focus on improvement, not perfection. What we want is for mistakes to decrease, and for new functionality not to break old functionality. Chris talked about the importance of having a metric – something that is believable – that you can use to measure improvement. He also spoke about what is ‘true’ and the need for a ‘ground truth’ in an environment where problems often don’t have a right or wrong answer. What is the truth about an image? If you show an image to a human and ask them to talk about it they could talk for a long time. What are the right things to say about it? What should a machine see? To know this, or to know it better, Chris said, Google needs data – more and more and more data. He made it clear that the data is key and it will help us on the road to continuous improvement. He used the example of searching for pictures of flowers using Google to find ‘paintings with flowers’. If you did this search 5 years ago you probably wouldn’t get just paintings with flowers. The search has improved, and it will continue to improve. A search for ‘paintings with tulips’ now is likely to show you just tulips. However, he gave the example of ‘paintings with flowers by french artists’ – a search where you start to see errors as the results are not all by french artists. A current problem Google are dealing with is mixed language queries, such as ‘paintings des fleurs’, which opens a whole can of worms. But Chris’ message was that metadata matters: it is the metadata that makes this kind of searching possible.
The Success of Failure
Related to the point about improvement, the message is that being ‘wrong’ or ‘failing’ should be seen in a much more positive light. Chris Welty told us that two thirds of his work doesn’t make it into a live environment, and he has no problem with that. Of course, it’s hard not to think that Google can afford to fail rather more than many of us! But I did have an interesting conversation with colleagues, via Twitter, around the importance of senior management and funders understanding that we can learn a great deal from what is perceived as failure, and we shouldn’t feel compelled to hide it away.
Europeana Tech panel session, with four continents represented
Think in terms of Entities
We had a small group conversation where this came up, and a colleague said to me ‘but surely that’s obvious’. But as archivists we have always been very centered on documents rather than things – on the archive collection, and the archive collection description. The trend that I was seeing reflected at Europeana Tech continued to be towards connections, narratives, pathways, utilising new tools for working with data, for improving data quality and linking data, for adding geo-coordinates and describing new entities, for making images more interoperable and contextualising information. The principle underlying this was that we should start from the real world – the real world entities – and go from there. Various data models were explored, such as the Europeana Data Model and CIDOC CRM, and speakers explained how entities can connect, and enable a richer landscape. Data models are a tricky one because they can help to focus on key entities and relationships, but they can be very complex and rather off-putting. The EDM seems to split the crowd somewhat, and there was some criticism that it is not event-based like CIDOC CRM, but the CRM is often criticised for being very complex and difficult to understand. Anyway, setting that aside, the overall the message was that relationships are key, however we decide to model them.
Cataloguing will never capture everyone’s research interests
An obvious point, but I thought it was quite well conveyed in the conference. Do we catalogue with the assumption that people know what they need? What about researchers interested in how ‘sad’ is expressed throughout history, or fashions for facial hair, or a million other topics that simply don’t fit in with the sorts of keywords and subject terms we normally use. We’ll never be able to meet these needs, but putting out as much data as we can, and making it open, allows others to explore, tag and annotate and create infinite groups of resources. It can be amazing and moving, what people create: Every3Minutes.
There’s so much out there to explore….
There are so many great looking tools and initiatives worth looking at, so many places to go and experiment with open data, so many APIs enabling so much potential. I ended up with a very long list of interesting looking sites to check out. But I couldn’t help feeling that so few of us have the time or resource to actually take advantage of this busy world of technology. We heard about Europeana Labs, which has around 100 ‘hardcore’ users and 2,200 registered keys (required for API use). It is described as “a playground for remixing and using your cultural and scientific heritage. A place for inspiration, innovation and sharing.” I wondered if we would ever have the time to go and have a play. But then maybe we should shift focus away from not being able to do these things ourselves, and simply allow others to use the data, and to adopt the tools and techniques that are available – people can create all sorts of things. One example amongst many we heard about at the conference is a cultural collage: zenlan.com/collage. It comes back to what is now quite an old adage, ‘the best innovation may not be done by you’. APIs enable others to innovate, and what interests people can be a real surprise. Bill Thompson from the BBC referred to a huge interest in old listings from Radio Times, which are now available online.
The International Image Interoperability Framework
I list the IIIF this because it jumped out at me as a framework that seems to be very popular – several speakers referred to it, and it very positive terms. I hadn’t heard of it before, but it seemed to be seen as a practical means to ensure that images are interoperable, and can be moved around different systems.
Think Little
One of my favourite thoughts from the conference, from the ever-inspirational Tim Sherratt, was that big ideas should enable little ideas. The little ideas are often what really makes the world go round. You don’t have to always think big. In fact, many sites have suffered from the tendency to try to do everything. Just because you can add tons of features to your applications, it doesn’t mean you should
The Importance of Orientation
How would you present your collections if you didn’t have a search box? This is the question I asked myself after listening to George Oates, from Good Form and Spectacle. She is a User Interface expert, and has worked on Flickr and for the Internet Archive amongst other things. I thought her argument about the need to help orientate users was interesting, as so often we are told that the ‘Google search box’ is the key thing, and what users expect. She talked about some of her experiments with front end interfaces that allow users to look at things differently, such as the V&A Spelunker. She spoke in terms of landmarks and paths that users could follow. I wonder if this is easier said than done with archives without over-curating what you have or excluding material that is less well catalogued, or does not have a nice image to work with. But I certainly think it is an idea worth exploring.
“The V&A Spelunker is a rough thing built by Good, Form & Spectacle to give a different view into the collection of the Victoria & Albert Museum”
We have recently been reprocessing the Archives Hub data, transforming it into RDF based Linked Data, and as part of this we have been working on names matching. For Linked Data, creating links to external data sources is key – it is what defines Linked Data and gives the opportunities, potentially, for researchers to explore topics across data sources.
This names matching work has big implications for archives. I have already talked extensively in the Hub Blog about the importance of structured data, which is more effectively machine processable. For archival descriptions, we have a huge opportunity to link to all sorts of useful data sources, and one of the key means to link our data is through personal names. To do this effectively, we need names to be structured, and this is one of the reasons why the Hub practice of structuring names by separating out surname, forename, dates, titles and descriptive information (epithets) is so useful. We do this structuring even though EAD (the recognised XML standard for archives) doesn’t actually allow for it. We took the decision that the advantages would outweigh the disadvantages of a non-standard approach (and we can export the data without this additional markup, so really there is no disadvantage).
We have been working on the matching, using the freely available Open Refine data processing tool with the VIAF reconciliation service developed by Roderick Page. Freely available tools like this are so important for projects like ours, and we’re really grateful that we were able to take advantage of this service.
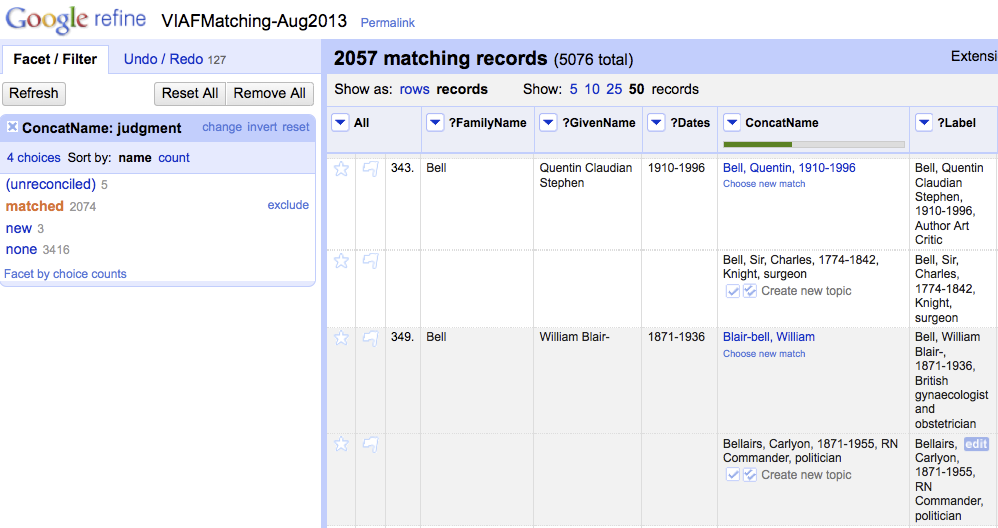
The matching has generally been very successful. Out of 5,076 names, just over 2,000 were linked from the Hub entry to the VIAF entry, which is a pretty good percentage.
This post provides some perspectives on the nature of the data and the results of the matching work.
Full names and epithets
With a name like ‘Bell, Sir Charles, 1774-1842, knight surgeon’, (you can see his entry in our current Linked Data views at http://data.archiveshub.ac.uk/id/person/ncarules/bellsircharles1774-1842knightsurgeon) there is plenty of information – surname, forename, dates and an epithet to help uniquely identify the individual. However, with this name, a match was not found, despite an entry on VIAF: http://viaf.org/viaf/2619993 (which is why you may not yet see the VIAF link on our Linked Data view). Normally, this type of name would yield a match. The reason it didn’t is that the epithet came through in the data we used for matching.
Screenshot of names matching using Open Refine
This highlights an issue with the use of epithets within names. It is encouraged in the NCA Rules, and it does help to uniquely identify an individual, but it introduces an additional element in the string that makes it harder to match the data.
Where our process did not manage to get the family name, forename and dates to match with VIAF, we used the ‘label‘ information that we have in our Linked Data. This label information includes the epithet. For example: Nosek, Václav, 1892-1955, Czechoslovak politician. This doesn’t tend to find a match, because of the epithet. With examples like this we can manually check, and in this case there is a VIAF match (http://viaf.org/viaf/23683886). But manual checking is problematic where you have thousands of names.
In 95% of cases we did manage to omit the epithet. But sometimes the epithet was included because we used the label, as stated, or because the markup on the Archives Hub is not always consistent and sometimes the structured names I referred to above are not present in Hub data because the data has come from other systems. (We may have found a way to remove these stray epithets, but it would have taken a good deal more time and effort to achieve).
Bringing together information on an individual
The reference to Sir Charles Bell came from a collection of “Papers of Sir Charles Bell” (http://archiveshub.ac.uk/data/gb96-ms386). In this description his occupation is “surgeon”. In the VIAF description (http://viaf.org/viaf/2619993) he is described as “Scottish painter, draftsman, and engraver”. Ostensibly this doesn’t look like the same person, but looking down the VIAF description, you can see titles such as “The nervous system of the human body” and other works that are clearly written by a scientist. The linking of our description with the VIAF description brings together Sir Charles Bell scientist and Sir Charles Bell painter, a good illustration of how linking provides a better perspective, as the different data sources effectively become joined up.
Pulling sparse sources together
For Francis Campbell Ross Douglas VIAF only has the surname and forename (http://viaf.org/viaf/211588539/), although if you look at the source records you also find “Douglas Of Barloch” to help with identification. This is an example where the Hub record has much more information (http://archiveshub.ac.uk/data/gb097-douglasofbarloch), and therefore creating the link is particularly useful. It shows how archives can help contribute to our knowledge of individuals within the Linked Data space, as they often have little known information, gleaned from the archives themselves.
<persname>
<surname>Bell</surname>,
<forename>William Blair-</forename>
(<dates>1871-1936</dates>)
<epithet>British gynaecologist and obstetrician</epithet>
</persname>
This is an example of the application of the NCA Rules, which insist on the last entry element as the main element, so it means the element ‘Bell’ is marked up as the surname. In fact, the matching still works because, with all the elements there, the reconciliation service can still find the right person (http://viaf.org/viaf/14336292/). However, it still concerns me that within the archive sector we have a rule that separates out the surname in this way, as it makes the name non-standard compared to other data sources. It is interesting to note that the name is generally given as Blair-Bell, but the Library of Congress enters the name as Bell, W. Blair (William Blair), 1871-1936 (http://id.loc.gov/authorities/names/no92003069.html), so there is an inconsistency in how different services deal with hyphenated and compound surnames. It could be argued that once we have a match, the different formats matter less, as they are simply alternatives that can be used to identify the individual.
Hub names without structured markup
As stated, in the Hub names are marked up by surname, forename, dates, epithet, titles. However, there are still some entries that are not marked up like this, usually because they were created in proprietary software and exported. An example is Carlyon Bellairs (referenced in http://archiveshub.ac.uk/data/gb097-assoc17). The name is marked up as:
You can see the XML mark up at http://archiveshub.ac.uk/data/gb097-assoc17.xml?hub. We have been working on a script to markup the component parts of these names in the Hub, and we have been able to implement it successfully for several institutions. But it is not easy to do this with non-standard names (i.e. not in the surname, forename, dates, epithet format). We do have some instances of names such as the British Prime Minister, James Callaghan, or the author Rudyard Kipling, that are not yet marked up in this way. These individuals should be easy to match, but without the structure within the index term, it is harder for us to ensure that we can get just the name and dates from an unstructured name to match with VIAF.
It is also impossible to implement structured markup on a name where there is a compound surname entered according to NCA Rules – we simply cannot mark these names up correctly because we have no way of knowing whether part of the forename is actually part of the surname. For example, if we have the name “George, David Lloyd” we can’t write a script that can transform this into “Lloyd George, David” because most of the time a name like this will be two forenames and one surname.
The importance of life dates and the use of ‘Is Like’
If we don’t have life dates, it makes matching with certainty almost impossible. Of course, cataloguers can’t always find life dates for a person, but it is worth stressing that the need for life dates has become even more important in recent years, now we have the potential to process data in so many ways. An example is at http://archiveshub.ac.uk/data/gb532-bel – Joyce Margaret Bellamy, a Senior Research Officer at the University of Hull. As we don’t have a birth date, we did not get a match with her VIAF entry at http://viaf.org/viaf/94773174. If we have this kind of entry, without life dates, we could potentially decide to use a different status from an exact match (which usually uses the owl:sameAs property), and for example, we could use the ‘isLike‘ property from the Umbel vocabulary instead. This would be useful where we believe the two names to be referring to the same person, but this type of matching has to be done manually (although potentially we could run something where a name match without a date match was always an ‘isLike’). In the process of checking the 2,000 matches for our data we did enter a number of matches manually, and the whole process of checking took around 5 hours. Not too bad for 2,000 names, and with some time also given to thinking about the results (and making notes for this post!). But if we were to work on the entire Archives Hub data, we couldn’t undertake to do this kind of manual work unless we just had a few thousand ‘not sure’ names that we might be prepared to work through.
Matches without life dates
We do get matches to VIAF where we don’t have dates. We got a match for ‘Hilda Chamberlain’ with VIAF entry http://viaf.org/viaf/286538995/. This seems to be correct, as she is the daughter of Joseph Chamberlain, so we kept the match. But we had to check it manually. Another example is Hercules Ross – http://viaf.org/viaf/21209582/ – matched to the name in description http://archiveshub.ac.uk/data/gb254-ms17. But in this case we don’t really have enough evidence to identify the individual, even though the surname and forename match. The source of the name on VIAF is “Guild, J. Proceedings before the sheriff depute of Forfarshire … against Hercules Ross and David Scott, Esquires, 1809”, but the title deeds described in the Archives Hub cover the sixteenth to the nineteenth century!
With a name like Gustav Wilhelm Wolff (http://archiveshub.ac.uk/data/gb738-ms174), again we only have the name and not the life dates. The match given is for someone born in 1811 (http://viaf.org/viaf/8221966/), and the papers relate to Victorian Jews in Britain. This makes the match likely, but we can’t be sure without dates, so we could potentially enter an ‘is like’, to imply that they are the same person, but that we cannot be certain.
Floruit!
We had a number of individuals without known life dates where the cataloguer used a ‘floruit’, e.g. Sharman W. fl 1884 (Secretary of National Association for the Repeal of the Blasphemy Laws). This sort of entry, whilst it may be the total of the information the archivist has, is difficult to use to identify someone in order to match them. However, the majority of individuals with this kind of entry are not likely to be on VIAF simply because a floruit normally indicates someone for whom life dates cannot be found. It would be interesting to consider a tool that matches floruit dates to possible life dates (e.g. fl 1900-1910 would match to life dates of 1880-1945) but I’m not sure how much it would add much to the accuracy of a match.
Alternative names
The reconciliation service often works where VIAF provides names that are not ‘the same’ as our name. So, for example, the Hub data may have the name ‘Orton, John Kingsley, 1933-1967’. This was linked to Joe Orton (http://viaf.org/viaf/22163951), and within the VIAF data you can see that Joe Orton is also known as John Kingsley Orton.
Fame does not always give identity
Sometimes very famous people prove problematic, and an example is someone like Queen Victoria, because the name doesn’t include a surname and people tend to enter it in various ways. There were a few examples of this type of thing in our data, although most royal names matched with no problem. It always helps if it is easier to structure a name, but kings, queens, popes, etc. are non-standard.
Some Hub names are quite fulsome, such as “Edward Albert Christian George Andrew Patrick David, 1894-1972, Duke of Windsor, formerly Edward VIII, King of Great Britain and Ireland”. This should link to VIAF http://viaf.org/viaf/47553571 (Windsor, Edward, Duke of, 1894-1972), but the match was not given due to the lack of similarity.
Accented characters may cause problems
We didn’t get a match on Jeremy Bentham, despite having the full structured name, but this may be because the VIAF match has an accent: http://viaf.org/viaf/59078842/. We could possibly have stripped out accents in our data, but in this case the accent was in the VIAF data. I only found one example where this was a problem, but clearly many names do contain accented characters.
Matches sometimes surprise…
A particularly nice match came up for “Mary-Teresa Craigie Pearl 1867-1906 novelist, dramatist and journalist as John Oliver Hobbes nee Richards”. A complex string, but the algorithm matched the basic elements that we provided (Cragie Pearl, Mary-Teresa, 1867-1906) to the name ‘John Oliver Hobbes’ on VIAF.
Mismatches
Leonard Wright, a Leiutenant (http://archiveshub.ac.uk/data/gb99-kclmawrightlw) matched to Clara Colby (http://viaf.org/viaf/63445035/), also known as Mrs Leonard Wright Colby. Here is an example of an incorrect match due to the same name, but in VIAF the person is a ‘Mrs’ (due to the old fashioned practice of using the husband’s name). The reason for the match seems to be that the name on the Hub includes a floruit (Leonard Wright, fl 1916) which matches the death date of Mrs Leonard Wright (Leonard Wright, Mrs, d 1916).
On the Hub we have an example of an archive that includes “a letter from Charlotte Bronte to Elizabeth Firth”, and the name is simply given as Elizabeth Firth in the index. The match to VIAF was for Mrs J.F.B Firth (http://viaf.org/viaf/71217693/). In this case the match is wrong, as we can see from the Hub description that Elizabeth Firth is actually “Mrs. James Clarke Franks”, and the dates within the additional information don’t seem to match.
There were very few examples of this type of mismatch, but it shows why well structured data, with life dates, helps to minimize any incorrect matches.
Incorrect Suggestions
In the names that did not find definite matches (i.e outside of the 2,000 matches), there were a few examples of suggested names that did not bear much resemblance to the text provided. One example of this was for “Bell, Vanessa, 1879-1961”. The suggestions for ‘sameAs’ names to link to this individual were Stephen, Julia Prinsep British model, 1846-1895; Woolf, Virginia, 1882-1941; Stephen, Leslie, 1832-1904. In fact, VIAF does have Vanessa Bell (http://viaf.org/viaf/7399364), and the link appears to be that the names are related within VIAF (i.e. VIAF establishes that there is an association between these people). However, these were only suggestions, they were not given as matches.
Conclusions
If there was no match given, but we can see that the name and dates have gone to VIAF, then we would assume there simply is no match and VIAF does not have anyone with our surname, forename and dates. But if we can see an epithet has also been included in the data we have provided, then there may well be a match because the epithet can be problematic for finding a match. Our intention would be to continue to improve our filtering to try to remove all epithets, but if the names are not properly structured this can be difficult.
When actually checking data like this, one thing that really comes to the fore is the risk of a ‘sameAs’ where the individual is not the same, and this is a particular risk where you are dealing with a notorious character – maybe a criminal. A number of war criminals are referred to in the Hub data, and it would be very unwise to link these to the wrong person – this is why it is best to only provide matches where the life dates match, but it is not impossible to have the same name with the same life dates of course.
In conclusion I would say that wherever our names have life dates, and these can be successfully carried over to the matching process, the likelihood of a correct match is 99%, but there is always a risk of a mismatch. Clearly the main problem would lie with two people sharing a name and life dates, and the chances of this happening will increase if we only have birth or death date.
A HEFCE study from 2010 states that “96% of students use the internet as a source of information” (1). This makes me wonder about the 4% that don’t; it’s not an insignificant number. The same study found that “69% of students use the internet daily as part of their studies”, so 31% don’t use it on a daily basis (which I take to mean ‘very frequently’).
There have been many reports on the subject of technology and its impact on learning, teaching and education. This HEFCE/NUS study is useful because it concentrates on surveying students rather than teachers or information professionals. One of the key findings is that it is important to think about the “effective use of technology” and “not just technology for technology’s sake”. Many students still find conventional methods of teaching superior (a finding that has come up in other studies), and students prefer a choice in how they learn. However, the potential for use of ICT is clear, and the need to engage with it is clear, so it is worrying that students believe that a significant number of staff “lack even the most rudimentary IT skills”. It is hardy surprising that the experiences of students vary considerably when they are partly dependent upon the skills and understanding of their teachers, and whether teachers use technology appropriately and effectively.
At the recent ELAG conference I gave a joint presentation with Lukas Koster, a colleague from the University of Amsterdam, in which we talked about (and acted out via two short sketches) the gap between researchers’ needs and what information professionals provide. Thinking simply about something as seemingly obvious as the understanding and use of
Random selection of interface terminology from archives sites.
the term ‘archives’ is a good case in point. Should we ensure that students understand the different definitions of archives? The distinction between archives that are collections with a common provenance and archives that are artificial collections? The different characters of archives that are datasets, generally used by social scientists? The “abuse” of the term archives for pretty much anything that is stored in any kind of longer-term way? Should users understand archival arrangement and how to drill down into collections? Should they understand ‘fonds’, ‘manuscripts’, ‘levels’, ‘parent collection’? Or is it that we should think more about how to translate these things into everyday language and simple design, and how to work things like archival hierarchy into easy-to-use interfaces? I think we should take the opportunities that technology provides to find ways to present information in such a way that we facilitate the user experience. But if students are reporting a lack of basic ICT skills amongst teachers, you have to wonder whether this is a problem within the archive and library sector as well. Do information professionals have appropriate ICT skills fit for ensuring that we can tailor our services to meet the needs of the technically savvy user?
Should we be teaching information literacy to students? One of the problems with this idea is that they tend to think they are already pretty literate in terms of use of the internet. In the HEFCE report, a survey of 213 FE students found that 88% felt they were effective online researchers and the majority said they were self-taught. They would not be likely to attend training on how to use the internet. And there is a question over whether they need to be taught how to use it in the ‘right’ way, or whether information professionals should, in fact, work with the reality of how it is being used (even if it is deemed to be ‘wrong’ in some way). Students are clear that they do want training “around how to effectively research and reference reliable online resources”, and maybe this is what we should be concentrating on (although it might be worth considering what ‘effective use of the internet’ and ‘effective research using the internet’ actually mean). Maybe this distinction highlights the problem with how to measure effective use of the internet, and how to define online or discovery skills.
A British Library survey from 2010 found that “only a small proportion [of students] …are using technology such as virtual-research environments, social bookmarking, data and text mining, wikis, blogs and RSS-feed alerts in their work.” This is despite the fact that many respondents in the survey said they found such tools valuable. This study also showed that students turn to their peers or supervisors rather than library staff for help.
Part of the problem may be that the vast majority of users use the internet for leisure purposes as well as work or study, so the boundaries can become blurred, and they may feel that they are adept users without distinguishing between different types of use. They feel that they are ‘fine with the technology’, although I wonder if that could be because they spend hours playing World of Warcraft, or use Facebook or Twitter every day, or regularly download music and watch YouTube. Does that mean they will use technology in an effective way as part of their studies? The trouble is that if someone believes that they are adept at searching, they may not go that extra mile to reflect on what they are doing and how effective it really is. Do we need to adjust our ways of thinking to make our resources more user-friendly to people coming from this kind of ‘I know what I’m doing’ mindset, or do we have to disabuse them of this idea and re-train them (or exhort them to read help pages for example…which seems like a fruitless mission)? Certainly students have shown some concern over “surface learning” (skim reading, learning only the minimum, and not getting a broader understanding of issues), so there is some recognition of an issue here, and the tendency to take a superficial approach might be reinforced if we shy away from providing more sophisticated tools and interfaces.
The British Library report on the Information Behaviour of the Researcher of the Future reinforces the idea that there is a gulf between students’ assumptions regarding their ICT skills versus the reality, which reveals a real lack of understanding. It also found a significant lack of training in discovery and use of tools for postgraduate students. Studies like this can help us think about how to design our websites, and provide tools and services to help researchers using archives. We have the challenges of how to make archives more accessible and easy to discover as well as thinking about how to help students use and interpret them effectively: “The college students of the open source, open content era will distinguish themselves from their peers and competitors, not by the information they know, but by how well they convert that knowledge to wisdom, slowly and deeply internalized.” (Sheila Stearns, “Literacy in the University of 2025: Still A Great Thing‟, from The Future of Higher Education , ed. by Gary Olson & John W Presley, (Boulder: Paradigm Publishers, 2009) pp. 98-99).
What are the Solutions?
We should make user testing more integral to the development of our interfaces. It requires resource, but for the Archives Hub we found that even carrying out 10 one-hour interviews with students and academics helped us to understand where we were making assumptions and how we could make small modifications that would improve our site. And our annual online survey continues to provide really useful feedback which we use to adjust our interface design, navigation and terminology. We can understand more about our users, and sometimes our assumptions about them are challenged.
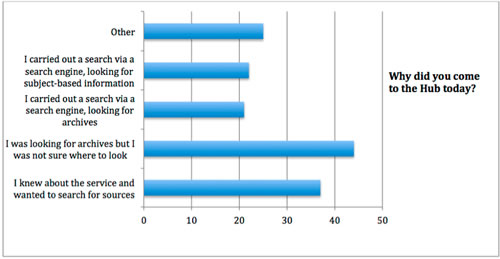
Archives Hub survey 2013: Why did you come to the Hub today?
User groups for commercial software providers can petition to ensure that out-of-the-box solutions also meet users’ needs and take account of the latest research and understanding of users’ experiences, expectations and preferences in terms of what we provide for them. This may be a harder call, because vendors are not necessarily flexible and agile; they may not be willing to make radical changes unless they see a strong business case (i.e. income may be the strongest factor).
We can build a picture of our users via our statistics. We can look at how users came into the site, the landing pages, where they went from there, which pages are most/least popular, how long they spent on individual pages, etc. This can offer real insights into user behaviour. I think a few training sessions on using Google Analytics on archive sites could come in handy!
We can carry out testing to find out how well sites rank on search engines, and assess the sort of experience users get when they come into a specialist site from a general search engine. What is the text a Google search shows when it finds one of your collections? What do people get to when they click on that link? Is it clear where they are and what they can do when they get to your site?
* * *
This is the only generation where the teachers and information professionals have grown up in a pre-digital world, and the students (unless they are mature students) are digital natives. Of course, we can’t just sit back and wait a generation for the teachers and information professionals to become more digitally minded! But it is interesting to wonder whether in 25 years time there will be much more consensus in approaches to and uses of ICT, or whether the same issues will be around.
Nigel Shadbolt has described the Web as “one of the most disruptive innovations we have ever witnessed” and at present we really seem to be struggling to find out how best to use it (and not use it), how and when to train people to use it and how and when to integrate it into teaching, learning and research in an effective way.
It seems to me that there are so many narratives and assessments at present – studies and reports that seem to run the gamut of positive to negative. Is technology isolating or socialising? Are social networks making learning more superficial or enabling richer discussion and analysis? Is open access democratising or income-reducing? Is the high cost of technology encouraging elitism in education? Does the fact that information is so easily accessible mean that researchers are less bothered about working to find new sources of information? With all these types of debates there is probably no clear answer, but let us hope we are moving forward in understanding and in our appreciation of what the Web can do to both enhance and transform learning, teaching and research.
I was lucky enough to attend the 2012 EmTACL conference in Trondheim, and this blog is based around the excellent keynote presentation by Herbert van de Sompel, which really made me think about temporal issues with the Web and how this can limit our understanding of the scholarly record.
Herbert believes that the current infrastructure for scholarly communication is not up to the job. We now have many non-traditional assets, which do not always have fixity and often have a wide range of dependencies; assets such as datasets, blogs, software, videos, slides which may form part of a scholarly resource. Everything is much more dynamic than it used to be. ‘Research objects’ often include assets that are interdependent with each other, so they need to be available all together for the object to be complete. But this is complicated by the fact that many of them are ‘in motion’ and updated over time.
This idea of dynamic resources that are in flux, constantly being updated, is very relevant for archivists, partly because we need to understand how archives are not static and fixed in time, and partly because we need to be aware of the challenges of archiving ever more complex and interconnected resources. It is useful to understand the research environment and the way technology influences outputs and influences what is possible for future research.
There are examples of innovative services that are responding to the opportunities of dynamic resources. One that Herbert mentioned was PLOS, which publishes open scholarly articles. It puts publications into Wikipedia as well as keeping the ‘static’ copy, so that the articles have a kind of second life where they continue to evolve as well as being kept as they were at the time of submission. For example, ‘Circular Permutation in Proteins‘.
The idea of executable papers is starting to become established – papers that are not just to read but to interact with. These contain access to the primary data with capabilities to re-execute algorithms and even capabilities to allow researchers to upload and use their own data. It produces a complex interdependency and produces a challenge for archiving because if something is not fixed in time, what does that mean for retaining access to it over time?
This all raises the issue of what the scholarly record actually is. Where does it start? Where does it end? We are no longer talking about a bunch of static files but a dynamic interconnected resource. In fact, there is an increasing sense that the article itself is not necessarily the key output, but rather it is the advertising for the actual scholarship.
Herbert concluded from this that it becomes very important to be able to view different points in time in the evolution of scholarly record, and this should be done in a way that works with the Web. The Web is the platform, the infrastructure for the scholarly record. Scholarly communication then becomes native to the Web. At the heart of this is the need to use HTTP URIs.
However, where are we at the moment? The current archival infrastructure for scholarly outputs deals with things with fixity and boundaries. It cannot deal with things in flux and with inter-dependencies. The Web exists in ‘now’ time; it does not have a built in notion of time. It assumes that you want the current version of something – you cannot use a URI to get to a prior version.
Slide from Herbert van de Sompel’s presentation showing the publication context on the Web
We don’t really object to this limitation, something evidenced by the fact that we generally accept links that take us to 404 pages, as if it is just an inevitable inconvenience. Maybe many people just don’t think that there is any real interest in or requirement for ‘obsolete’ resources, and what is current is what is important on the Web.
Of course, there is the Internet Archive and other similar initiatives in Web archiving, but they are not integrated into the Web. You have to go somewhere completely different in order to search for older copies of resources.
If the research paper remains the same, but resources that are an integral part of it change over time, then we need to change archiving to reflect this. We need to think about how to reference assets over time and how to recreate older versions. Otherwise, we access the current version, but we are not getting the context that was there at the time of creation; we are getting something different.
Can we recreate a version of a scholarly record? Can we go back to certain point it time so we can see linked assets from a paper as they were at the time of publication? At the moment we are likely to get many 404s when we try to access links associated with a publication. Herbert showed one survey on the decay of URLs in Medline, which is about 10% per year, especially with links to thinks like related databases.
One solution to this is to be able to follow a URI in time – to be able to click on URI and say ‘I want to see this as was 2 years ago’. Herbert went on to talk about something he has created called Memento. Memento aims to better integrate the current and past Web. It allows you to select a day or time in the browser and effectively take the URI back in time. Currently, the team are looking at enabling people to browse past pages of Wikipedia. Memento has a fairly good success rate with going back to retrieve old versions, although it will not work for all resources. I tried it with the Archives Hub and found it easy to take the website back to how it looked right in the very early days.
Using Memento to take the Archives Hub back in time.
One issue is that the archived copies are not always created near the time of publication. But for those that are, they are created simply as part of the normal activity of the Web, by services like the Internet Archive or the British Library, so there is no extra work involved.
Herbert outlined some of the issues with using DOIs (digital object identifiers), which provide identifiers for resources that use a resolver to ensure that the identifier can remain the same over time. This is useful if, for example, a publisher is bought out – the identifier is still the same as the resolver redirects to the right location However, a DOI resolver exists in the perpetual now. It is not possible to travel back in time using HTTP URIs. This is maybe one illustration of the way some of the processes that we have implemented over the Web do not really fulfil our current needs, as things change and resources become more complex and dynamic.
With Memento, the same HTTP URI can function as the reference to temporally evolving resources. The importance of this type of functionality is becoming more recognised. There is a new experimental URI scheme, DURI , or Dated URI. The ideas is that a URI, such as http://www.ntnu.no, can be dated: 1997-06-17:http://www.ntnu.no (this is an example and is not actionable now). Herbert did raise another possibly of developing Websites that can deal with the TEL (telephone) protocol. The idea would be that the browser asks you whether the Website can use the TEL protocol, and if it can, you get this option offered to you. You can then use this and reference a resource and use Memento to go back in time.
Herbert concluded that the idea of ‘archiving’ should not be just a one-off event, but needs to happen continually. In fact, it could happen whenever there is an interaction. Also, when new materials are taken into a repository, you could scan for links and put them into an archive, so the links don’t die. If you archive the links at the time of publication or when materials submitted to a repository, then you protect against losing the context of the resource.
Herbert introduced us to SiteStory, which offers transactional archiving of a a web server. Usually a web archive sends out a robot, gathers and dumps the data. With SiteStory the web server takes an active part. Every time a user requests a page it is also pushed back into the archive, so you get a fine grained history of the resource. Something like this could be done by publishers/service providers, with the idea that they hold onto the hits, the impact, the audience. It certainly does seem to be a growing area of interest.
This is something that I’ve thought about quite a bit, as I work as the manager of an online service for Archives and I do training and teaching for archivists and archive students around creating online descriptions. I would like to direct this blog post to archive students or those considering becoming archivists. I think this applies equally to records managers, although sometimes they have a more defined role in terms of audience, so the perspective may be somewhat different.
It’s fine if you have ‘a love of history’, if you ‘feel a thrill when handling old documents’. That’s a good start. I’ve heard this kind of thing frequently as a motivation for becoming an archivist. But this is not enough. It is more important to have the desire to make those archives available to others; to provide a service for researchers. To become an archivist is to become a service provider, not an historian. It may not sound as romantic, but as far as I am concerned it is what we are, and we should be proud of the service we provide, which is extremely valuable to society. Understanding how researchers might use the archives is, of course, very important, so that you can help to support them in their work. Love of the materials, and love of the subject (especially in a specialist repository) should certainly help you with this core role. Indeed, you will build an understanding of your collections, and become more expert in them over time, which is one of the wonderful things about being an archivist.
Your core role is to make archives available to the community – for many of us, the community is potentially anyone, for some of us it may be more restricted in scope. So, you have an interest in the materials, you need to make them available. To do this you need to understand the vital importance of cataloguing. It is this that gives people a way in to the archives. Cataloguing is a real skill, not something to be dismissed as simply creating a list of what you have. It is something to really work on and think about. I have seen enough inconsistent catalogues over the last ten years to tell you that being rigorous, systematic and standards-based in cataloguing is incredibly important, and technology is our friend in this aim. Furthermore, the whole notion of ‘cataloguing’ is changing, a change led by the opportunities of the modern digital age and the perspectives and requirements of those who use technology in their every day life and work. We need to be aware of this, willing (even excited!) to embrace what this means for our profession and ready to adapt.
This brings me to the subject I am particularly interested in: the use of technology. Cataloguing *is* using technology, and dissemination *is* using technology. That is, it should be and it needs to be if you want to make an impact; if you want to effectively disseminate your descriptions and increase your audience. It is simply no good to see this profession as in any way apart from technology. I would say that technology is more central to being an archivist than to many professions, because we *deal in information*. It may be that you can find a position where you can keep technology at arm’s length, but these types of positions will become few and far between. How can you be someone who works professionally with information, and not be prepared to embrace the information environment? The Web, email, social networks, databases: these are what we need to use to do our jobs. We generally have limited resources, and technology can both help us make the most of the resources we have and, conversely, we may need to make informed choices about the technology we use and what sort of impact it will have. Should you use Flickr to disseminate content? What are the pros and cons? Is ‘augmented reality’ a reality for us? Should you be looking at Linked Data? What is is and why might it be important? What about Big Data? It may sound like the latest buzz phrase but it’s big business, and can potentially save time and money. Is your system fit for purpose? Does it create effective online catalogues? How interoperable is it? How adaptable?
Before I give the impression that you need to become some sort of technical whizz-kid, I should make clear that I am not talking about being an out-and-out techie – a software developer or programmer. I am talking about an understanding of technology and how to use it effectively. I am also talking about the ability to talk to technical colleagues in order to achieve this. Furthermore, I am talking about a willingness to embrace what technology offers and not be scared to try things out. It’s not always easy. Technology is fast-moving and sometimes bewildering. But it has to be seen as our ally, as something that can help us to bring archives to the public and to promote a greater understanding of what we do. We use it to catalogue, and I have written previously about how our choice of system has a great impact on our catalogues, and how important it is to be aware of this.
Our role in using technology is really *all about people*. I often think of myself as the middleman, between the technology (the developers) and the audience. My role is to understand technology well enough to work with it, and work with experts, to harness it in order to constantly evolve and use it to best advantage, but also to constantly communicate with archivists and with researchers. To have an understanding of requirements and make sure that we are relevant to end-users. Its a role, therefore, that is about working with people. For most archivists, this role will be within a record office or repository, but either way, working with people is the other side of the coin to working with technology. They are both central to the world of archives.
If you wonder how you can possibly think about everything that technology has to offer: well, you can’t. But that’s why it is even more vital now than it has ever been to think of yourself as being in a collaborative profession. You need to take advantage of the experience and knowledge of colleagues, both within the archives profession and further afield. It’s no good sitting in a bubble at your repository. We need to talk to each other and benefit from sharing our understanding. We need to be outgoing. If you are an introvert, if you are a little shy and quiet, that’s not a problem; but you may have to make a little more effort to engage and to reach out and be an active part of your profession.
They say ‘never work with children and animals’ in show business because both are unpredictable; but in our profession we should be aware that working with people and technology is our bread and butter. Understanding how to catalogue archives to make them available online, to use social networks to communicate our messages, to think about systems that will best meet the needs of archives management, to assess new technologies and tools that may help us in our work. These are vital to the role of a modern professional archivist.
The Horizon Report is an excellent way to get a sense of emerging and developing technologies, and it is worth thinking about what they might mean for archives. In this post I concentrate on the key trends that are featured for the next 1-4 years.
Electronic Books
“[E]lectronic books are beginning to demonstrate capabilities that challenge the very definition of reading.”
Electronic books promise not just convenience, but also new ways of thinking about reading. They encourage interactive, social and collaborative approaches. Does this have any implications for archives? Most archives are paper-based and do not lend themselves so well to this kind of approach. We think of consulting archives as a lone pursuit, in a reading room under carefully controlled conditions. The report refers to “a dynamic journey that changes every time it is opened.” An appealing thought, and indeed we might feel that archives also offer this kind of journey. Increasingly we have digital and born-digital archives, but could these form part of a more collaborative and interactive way of learning? Issues of authenticity, integrity and intellectual property may mitigate against this.
Whilst we may find it hard to see how archives may not become a part of this world – we are talking about archives, after all, and not published works – there may still be implications around the ways that people start to think about reading. Will students become hooked on rich and visual interfaces and collaborative opportunities that simply do not exist with archives?
Mobiles
“According to a recent report from mobile manufacturer Ericsson, studies show that by 2015, 80% of people accessing the Internet will be doing so from mobile devices.”
Mobiles are a major part of the portable society. Archive repositories can benefit from this, ensuring that people can always browse their holdings, wherever they are. We need to be involved in mobile innovation. As the report states: “Cultural heritage organizations and museums are also turning to mobiles to educate and connect with audiences.” We should surely see mobiles as an opportunity, not a problem for us, as we increasingly seek to broaden our user-base and connect with other domains. Take a look at the ‘100 most educational iPhone Apps‘. They include a search of US historical documents with highlighting and the ability to add notes.
Augmented Reality
We have tended to think of augmented reality as something suitable for marketing, social engagement and amuseument. But it is starting to provide new opportunities for learning and changing expectations around access to information. This could provide opportunities for archives to engage with users in new ways, providing a more visual experience. Could it provide a means to help people understand what archives are all about? Stanford University in the US has created an island in Second Life. The unique content that the archives provide was seen as something that could draw visitors back and showcase the extensive resources available. Furthermore, they created a ‘virtual archives’, giving researchers an opportunity to explore the strong rooms, discover and use collections and collaborate in real time.
The main issue around using these kinds of tools is going to be the lack of skills and resources. But we may still have a conflict of opinions over whether virtual reality really has a place in ‘serious research’. Does it trivialize archives and research? Or does it provide one means to engage younger potential users of archives in a way that is dynamic and entertaining? I think that it is a very positive thing if used appropriately. The Horizon Report refers to several examples of its use in cultural heritage: the Getty Museum are providing ‘access’ to a 17th century collector’s cabinet of wonders; the Natural History Museum in London are using it in an interactive video about dinosaurs; the Museum of London are using it to allow people to view 3D historical images overlaid on contemporary buildings. Another example is the Powerhouse Museum in Sydney, using AR to show the environment around the Museum 100 years ago. In fact, AR does seem to lend itself particularly well to teaching people about the history around them.
Game-Based Learning
Another example of blending entertainment with learning, games are becoming increasingly popular in higher education, and the Serious Games movement is an indication of how far we have come from the notion that games are simply superficial entertainment. “[R]esearch shows that players readily connect with learning material when doing so will help them achieve personally meaningful goals.” For archives, which are often poorly understood by people, I think that gaming may be one possible means to explain what archives are, how to navigate through them and find what may be of interest, and how to use them. How about something a bit like this Smithsonian initiative, Ghosts of a Chance, but for archives?
These technologies offer new ways of learning, but they also suggest that our whole approach to learning is changing. As archivists, we need to think about how this might impact upon us and how we can use it to our advantage. Archives are all about society, identity and story. Surely, therefore, these technologies should give us opportunities to show just how much they are a part of our life experiences.
Democracy 2.0: A Case Study in Open Government from across the pond.
I have just listened to a presentation by David Ferriero – 10th Archivist of the US at the National Archives and Records Administration (www.archives.gov). He was talking about democracy, about being open and participatory. He contrasted the very early days of American independence, where there was a high level of secrecy in Government, to the current climate, where those who make decisions are not isolated from the citizens, and citizens’ voices can be heard. He referred to this as ‘Democracy 2.0.’ Barack Obama set out his open government directive right from the off, promoting the principles of more transparecy, participation and collaboration. Ferriero talked about seeking to inform, educate and maybe even entertain citizens.
The backbone of open government must be good record keeping. Records document individual rights and entitlements, record actions of government and who is responsible and accountable. They give us the history of the national experience. Only 2-3 percent of records created in conducting the public’s business are considered to be of permanent value and therefore kept in the US archives (still, obviously, a mind-bogglingly huge amount of stuff).
Ferriero emphasised the need to ensure that Federal records of historical value are in good order. But there are still too many records are at risk of damange or loss. A recent review of record keeping in Federal Agencies showed that 4 out of 5 agencies are at high or moderate risk of improper destruction of records. Cost effective IT solutions are required to address this, and NARA is looking to lead in this area. An electronic records archive (ERA) is being build in partnership with the private sector to hold all the Federal Government’s electronic records, and Ferriero sees this as the priority and the most important challenge for the National Archives. He felt that new kinds of records create new challenges, that is, records created as result of social media, and an ERA needs to be able to take care of these types of records.
Change in processes and change in culture is required to meet the new online landscape. The whole commerce of information has changed permanently and we need to be good stewards of the new dynamic. There needs to be better engagement with employees and with the public. NARA are looking to improve their online capabilities to improve the delivery of records. They are developing their catalogue into a social catalogue that allows users to contribute and using Web 2.0 tools to allow greater communication between staff. They are also going beyond their own website to reach users where they are, using YouTube, Twitter, blogs, etc. They intend to develop comprehensive social media strategy (which will be well worth reading if it does emerge).
The US Government are publishing high value datasets on data.gov and Ferriero said that they are eager to see the response to this, in terms of the innovative use of data. They are searching for ways to step of digitisation – looking at what to prioritise and how to accomplish the most with least cost. They want to provide open government leadership to Federal Agencies, for example, mediating in disputes relating to FoI. There are around 2,000 different security classification guides in the government, which makes record processing very comlex. There is a big backlog of documents waiting to be declassified, some pertaining to World War Two, the Koeran War and the Vietnam War, so they will be of great interest to researchers.
Ferriero also talked about the challenge of making the distiction between business records and personal records. He felt that the personal has to be there, within the archive, to help future researchers recreate the full picture of events.
There is still a problem with Government Agencies all doing their own thing. The Chief Information officers of all agencies have a Council (the CIO Council). The records managers have the Records Management Council. But it is a case of never the twain shall meet at the moment. Even within Agencies the two often have nothing to do with eachother….there are now plans to address this!
This was a presentation that ticked many of the boxes of concern – the importance of addressing electronic records, new media, bringing people together to create efficiencies and engaging the citizens. But then, of course, it’s easy to do that in words….