There are many ways of utilising the International Image Interoperability framework (IIIF) in order to deliver high-quality, attributed digital objects online at scale. One of the exploratory areas focused on in Images and Machine Learning – a project which is part of Archives Hub Labs – is how to display the context of the archive hierarchy using IIIF alongside the digital media.
Two of the objectives for this project are:
- to explore IIIF Manifest and IIIF Collection creation from archive descriptions.
- to test IIIF viewers in the context of showing the structure of archival material whilst viewing the digitised collections.
We have been experimenting with two types of resource from the IIIF Presentation API. The IIIF Manifest added into the Mirador viewer on the collection page contains just the images, in order to easily access these through the viewer. This is in contrast to a IIIF Collection, which we have been experimenting with. The IIIF Collection includes not only the images from a collection but also metadata and item structure within the IIIF resource. It is defined as a set of manifests (or ‘child’ collections) that communicate hierarchy or gather related things (for example, a set of boxes that each have folders within them, and photographs within those folders). We have been testing whether this has the potential to represent the hierarchy of an archival structure within the IIIF structure.
Creating a User Interface
Since joining the Archives Hub team, one of the areas I’ve been involved in is building a User Interface for this project that allows us to test out the different ways in which we can display the IIIF Images, Manifests and Collections using the IIIF Image API and the IIIF Presentation API. Below I will share some screenshots from my progress and talk about my process when building this User Interface.


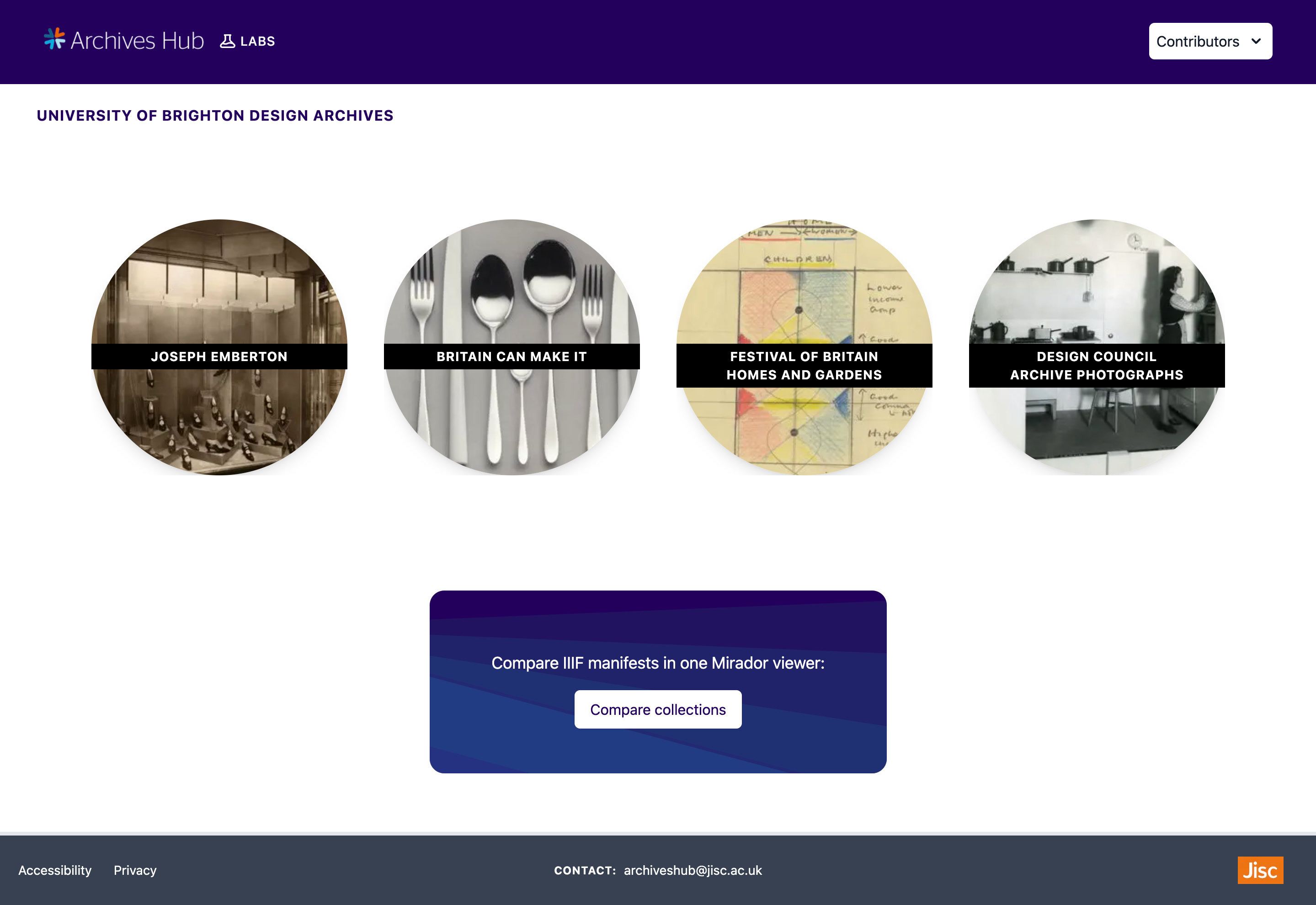
This web application is currently a prototype and further development will be happening in the future. The programming language I am using is Typescript. I began by creating a Next.js React application and I am also using Tailwind CSS for styling. My first task was to use the Mirador viewer to display IIIF Collections and Manifests, so I installed the mirador package into the codebase. I created dynamic pages for every contributor to display their collections.
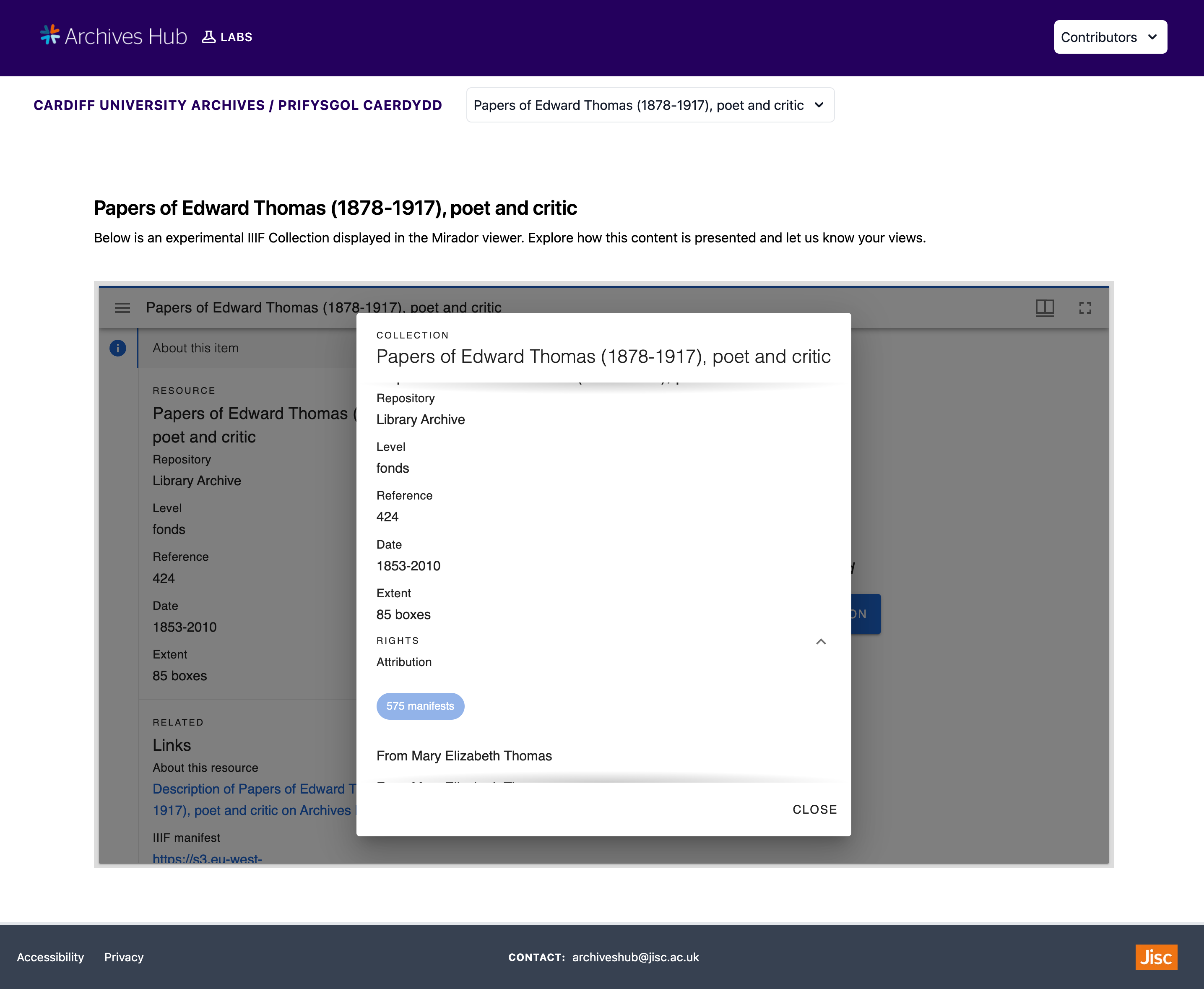
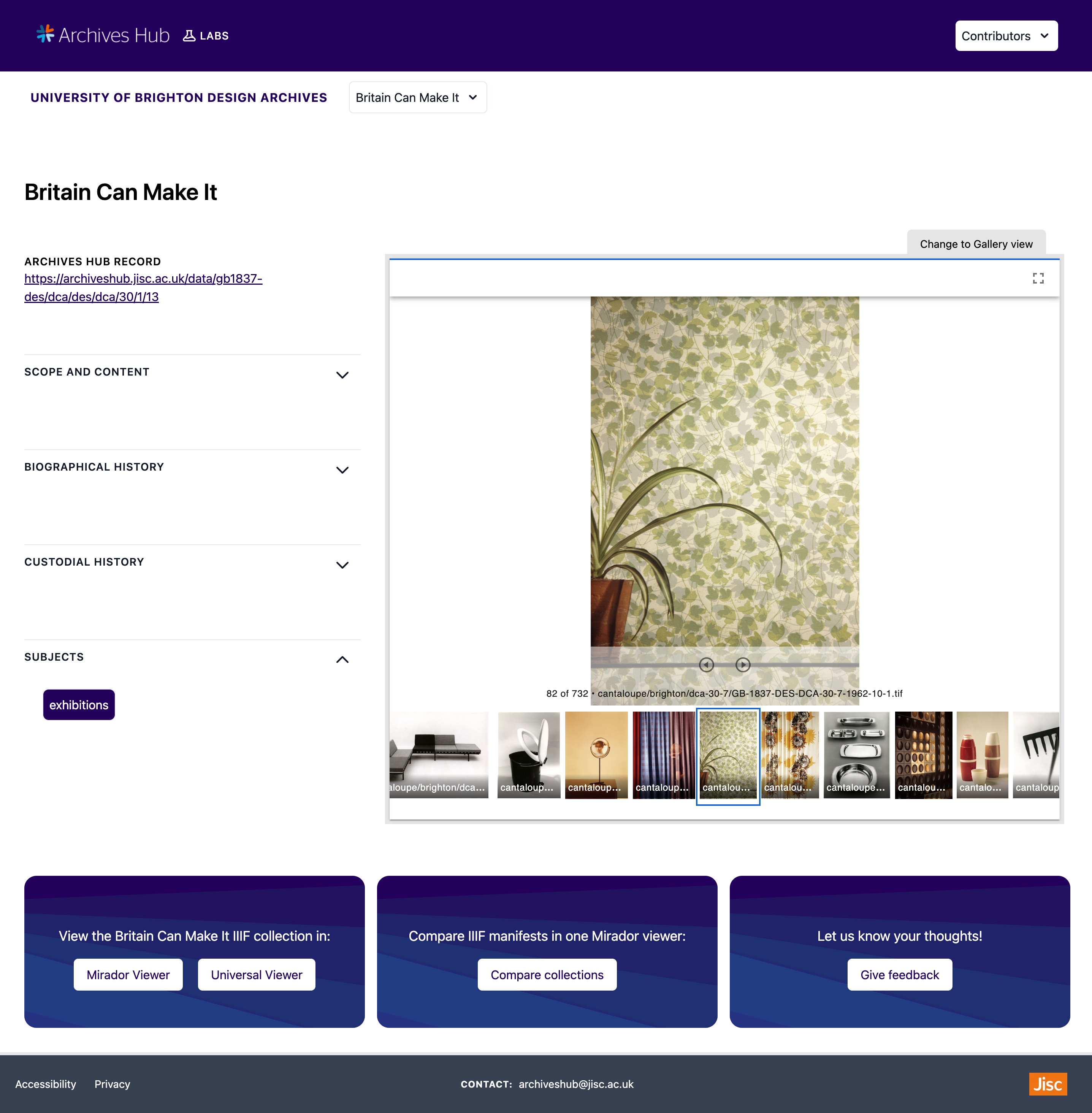
I also created dynamic collection pages for each collection. Included on the left-hand side of a collection page is the archives hub record link and the metadata about the collection taken from the archival EAD data – these sections displaying the metadata can be extended or hidden. The right-hand side of a collection page features a Mirador viewer. A simple IIIF Manifest has been added for all of the images in each collection. This Manifest is used to help quickly navigate through and browse the images in the collection.
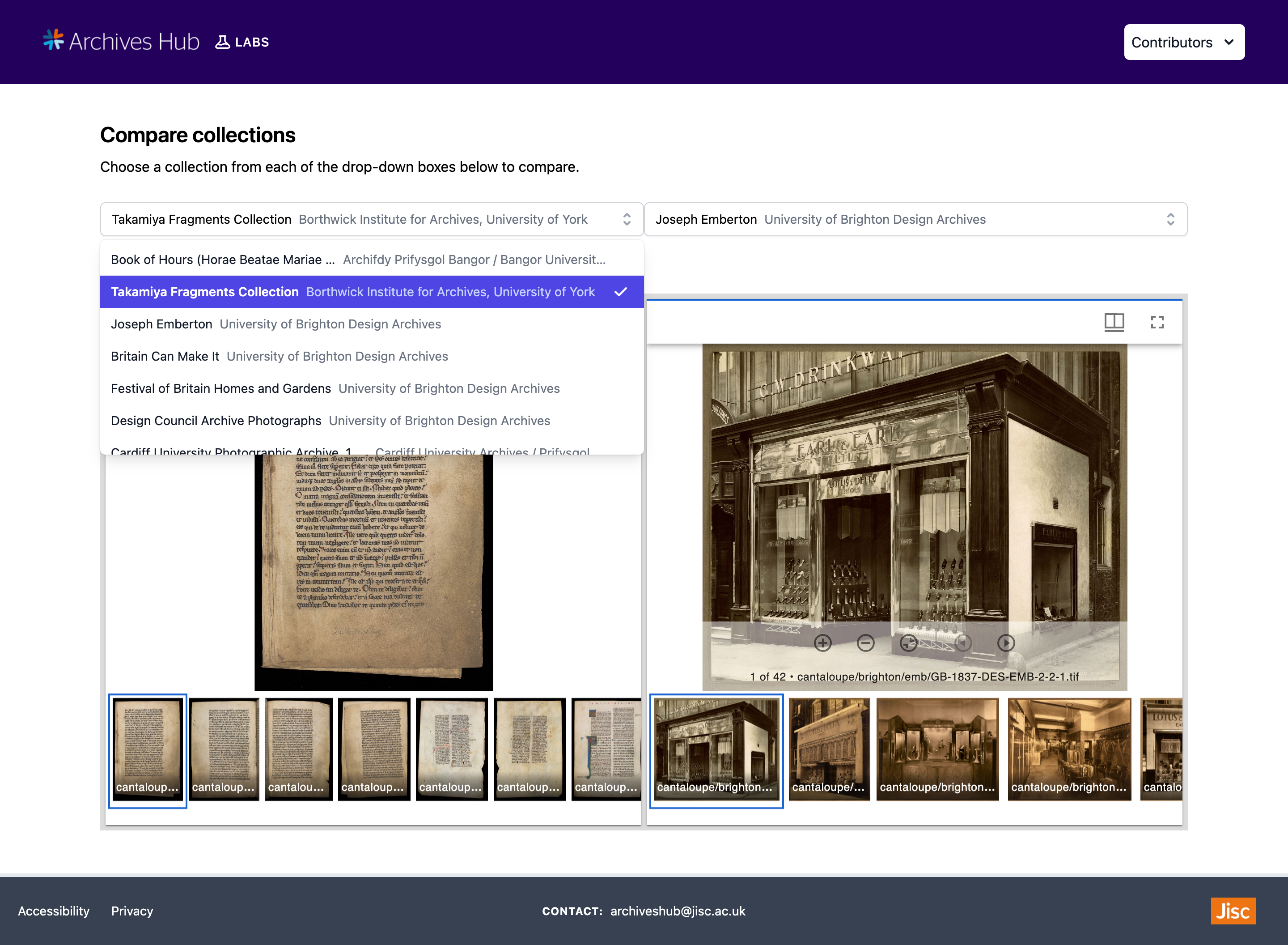
Mirador has the ability to display multiple windows within one workspace. This is really useful for comparison of images side-by-side. Therefore, I have also created a ‘Compare Collections’ page where two Manifests of collection images can be compared side-by-side. I have configured two windows to display within one Mirador viewer. Then, two collections can be chosen for comparison using the dropdown select boxes seen in the image below.
Next steps
There are three key next steps for developing the User Interface –
- We have experimented with the Mirador viewer, and now we will be looking at how the Universal Viewer handles IIIF Collections.
- From the workshop feedback and from our exploration with the display of images, we will be looking at how we can offer an alternative experience of these archival images – distinct from their cataloguing hierarchy – such as thematic digital exhibitions and linking to other IIIF Collections and Manifests that already exist.
- As part of the Machine Learning aspect of this project, we will be utilising the additional option to add annotations within the IIIF resources, so that the ML outputs from each image can be added as annotations and displayed in a viewer.
Labs IIIF Workshop
We recently held a workshop with the Archives Hub Labs project participants in order to get feedback on viewing the archive hierarchy through these IIIF Collections, displayed in a Mirador viewer. In preparation for this workshop, Ben created a sample of IIIF Collections using the images kindly provided by the project participants and the archival data related to these images that is on the Archives Hub. These were then loaded into the Mirador viewer so our workshop participants could see how the collection hierarchy is displayed within the viewer. The outcomes of this workshop will be explored in the next Archives Hub Labs blog post.
Thank you to Cardiff University, Bangor University, Brighton Design Archives at the University of Brighton, the University of Hull, the Borthwick Institute for Archives at the University of York, Lambeth Palace (Church of England) and Lloyds Bank for providing their digital collections and for participating in Archives Hub Labs.