Search logs can give us an insight into how people really search. Our current system provides ‘search logs’ that show the numbers based on the different search criteria and faceting that the Hub offers, including combined searches. We can use these to help us understand how our users search and to give us pointers to improve our interface.
The Archives Hub has a ‘default search’ on the homepage and on the main search page, so that the user can simply type a search into the box provided. This is described as a keyword search, as the user is entering their own significant search terms and the results returned include any archival description where the term(s) are used.
The researcher can also choose to narrow down their search by type. The figure below shows the main types the Archives Hub currently has. Within these types we also have boolean type options (all, exact, phrase), but we have not analysed these at this point other than for the main keyword search.
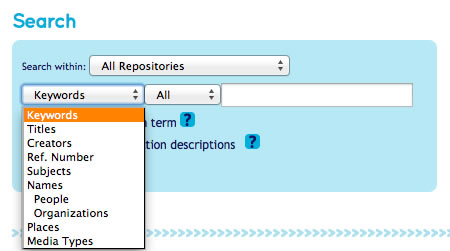
Archives Hub search box showing the types of searches available
There are caveats to this analysis.
1. Result will include spiders and spam
With our search logs, excluding bots is not straightforward, something which I refer to in a previous post: Archives Logs and Google Analytics. We are shortly to migrate to an entirely new system, so for this analysis we decided to accept that the results may be slightly skewed by these types of searches. And, of course, these crawlers often perform a genuine service, exposing archive descriptions through different search engines and other systems.
2. There are a small number of unaccounted for searches
Unidentified searches only account for 0.5% of the total, and we could investigate the origins of these searches, but we felt the time it would take was not worth it at this point in time.
3. Figures will include searches from the browse list.
These figures include searches actioned by clicking on a browse list, e.g. a list of subjects or a list of creators.
4. Creator, Subject and Repository include faceted searching
The Archives Hub currently has faceted searching for these entities, so when a user clicks to filter down by a specific subject, that counts as a subject search.
Results for One Month (October 2015)
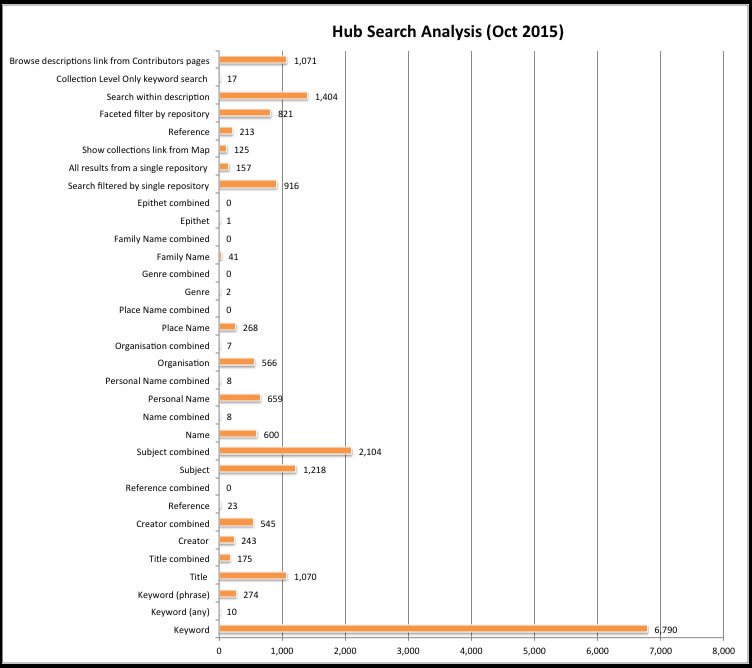
For October 2015 the total searches are 19,415. The keyword search dominates, with a smaller use of the ‘any’ and ‘phrase’ options within the keyword search. This is no surprise, but this ‘default search’ still forms only 36% of the whole, which does not necessarily support the idea that researchers always want a ‘google type’ search box.
We did not analyse these additional filters (‘any/phrase/exact’) for all of the searches, but looking at them for ‘keyword’ gives a general sense that they are useful, but not highly used.
A clear second is search by subject, with 17% of the total. The subject search was most commonly combined with other searches, such as a keyword and further subject search. Interestingly, subject is the only search where a combined subject + other search(es) is higher than a single subject search. If we look at the results over a year, the combined subject search is by far the highest number for the whole year, in fact it is over 50% of the total searches. This strongly suggests that bots are commonly responsible for combined subject searches.
These searches are often very long and complex, as can be seen from the search logs:
[2015-09-17 07:36:38] INFO: 94.212.216.52:: [+0.000 s] search:: [+0.044 s] Searching CQL query: (dc.subject exact “books of hours” and/cql.relevant/cql.proxinfo (dc.subject exact “protestantism” and/cql.relevant/cql.proxinfo (dc.subject exact “bible o.t. psalms” and/cql.relevant/cql.proxinfo (dc.subject exact “authors, classical” and/cql.relevant/cql.proxinfo (dc.subject exact “bible o.t. psalms” and/cql.relevant/cql.proxinfo (dc.subject exact “law” and/cql.relevant/cql.proxinfo (dc.subject exact “poetry” and/cql.relevant/cql.proxinfo (dc.subject exact “bible o.t. psalms” and/cql.relevant/cql.proxinfo (dc.subject exact “sermons” and/cql.relevant/cql.proxinfo bath.personalname exact “rawlinson richard 1690-1755 antiquary and nonjuror”))))))))):: [+0.050 s] 1 Hits:: Total time: 0.217 secs
It is most likely that the bots are not nefarious; they may be search engine bots, or they may be indexing for the purposes of information services of some kind, such as bibliographic services, but they do make attempts to assess the value of the various searches on the Hub very difficult.
Of the remaining search categories available from the main search page, it is no surprise that ‘title’ is used a fair bit, at 6.5%, and then after that creator, name, and organisation and personal name. These are all fairly even. For October 2015 they are around 3% of the total each, and it seems to be similar for other months.
The repository filter is popular. Researchers can select a single repository to find all of their descriptions (157), select a single repository and also search terms (916), and also search for all the descriptions from a single repository from our map of contributors (125). This is a total of 1,198, which is 6.1% of the total. If we also add the faceted filter by repository, after a search has been carried out, the total is 2,019, and the percentage is 10.4%. Looking at the whole year, the various options to select repository become an even bigger percentage of the total, in particular the faceted filter by repository. This suggests that improvements to the ability to select repositories, for example, by allowing researchers to select more than one repository, or maybe type of repository, would be useful.
Google Map on the Hub showing the link to search by contributor
We have a search within multi-level descriptions, introduced a few years ago, and that clearly does get a reasonable amount of use, with 1,404 uses in this particular month, or 7.2% of the total. This is particularly striking as this is only available within multi-level descriptions. It is no surprise that this is valuable for lengthy descriptions that may span many pages.
The searches that get minimal use are identifier, genre, family name and epithet. This is hardly surprising, and illustrates nicely some of the issues around how to measure the value of something like this.
Identifier enables users to search by the archival reference. This may not seem all that useful, but it tends to be popular with archivists, who use the Hub as an administrative tool. However, the current Archives Hub reference search is poor, and the results are often confusing. It seems likely that our contributors would use this search more if the results were more appropriate. We believe it can fulfill this administrative function well if we adjust the search to give better quality results; it is never likely to be a highly popular search option for researchers as it requires knowledge of the reference numbers of particular descriptions.
Epithet is tucked away in the browse list, so a ‘search’ will only happen if someone browses by epithet and then clicks on a search result. Would it be more highly used if we had a ‘search by occupation or activity’? There seems little doubt of this. It is certainly worth considering making this a more prominent search option, or at least getting more user feedback about whether they would use a search like this. However, its efficacy may be compromised by the extremely permissive nature of epithet for archival descriptions – the information is not at all rigorous or consistent.
Family name is not provided as a main search option, and is only available by browsing for a family name and clicking on a result, as with epithet. The main ‘name’ search option enables users to search by family name. We did find the family name search was much higher for the whole year, maybe an indication of use by family historians and of the importance of family estate records.
Genre is in the main list of search options, but we have very few descriptions that provide the form or medium of the archive. However, users are not likely to know this, and so the low use may also be down to our use of ‘Media type’, which may not be clear, and a lack of clarity about what sort of media types people can search for. There is also, of course, the option that people don’t want to search on this facet. However, looking at the annual search figures, we have 1,204 searches by media type, which is much more significant, and maybe could be built up if we had something like radio buttons for ‘photographs’, ‘manuscripts’, ‘audio’ that were more inviting to users. But, with a lack of categorisation by genre within the descriptions that we have, a search on genre will mean that users filter out a substantial amount of relevant material. A collection of photographs may not be catalogued by genre at all, and so the user would only get ‘photographs’ through a keyword search.
Place name is an interesting area. We have always believed that users would find an effective ‘search by place’ useful. Our place search is in the main search options, but most archivists do not index their descriptions by place and because of this it does not seem appropriate to promote a place name search. We would be very keen to find ways to analyse our descriptions and consider whether place names could be added as index terms, but unless this happens, place name is rather like media type – if we promote it as a means to find descriptions on the Archives Hub, then a hit list would exclude all of those descriptions that do not include place names.
This is one of the most difficult areas for a service like the Archives Hub. We want to provide search options that meet our users’ needs, but we are aware of the varied nature of the data. If a researcher is interested in ‘Bath’ then they can search for it as a keyword, but they will get all references to bath, which is not at all the same as archives that are significantly about Bath in Gloucestershire. But if they search for place name: bath, then they exclude any descriptions that are significantly about Bath, but not indexed by place. In addition, words like this, that have different meanings, can confuse the user in terms of the relevance of the results because ‘bath’ is less likely to appear in the title. It may simply be that somewhere in the description, there is a reference to a Dr Bath, for example.
This is one reason why we feel that encouraging the use of faceted search will be better for our users. A more simple initial search is likely to give plenty of results, and then the user can go from there to filter by various criteria.
It is worth mentioning ‘date’ search. We did have this at one point, but it did not give good results. This is partly due to many units of description not including normalised dates. But the feedback that we have received suggests that a date search would be popular, which is not surprising for an archives service. We are planning to provide a filter by date, as well as the ordering by date that we currently have.
Finally, I was particularly interested to see how popular our ‘search collection level only’ is.  This enables users to only see ‘top level’ results, rather than all of the series and items as well. As it is a constant challenge to present hierarchical descriptions effectively, this would seem to be one means to simplify things. However, for October 2015 we had 17 uses of this function, and for the whole year only 148. This is almost negligible. It is curious that so few users chose to use this. Is it an indication that they don’t find it useful, or that they didn’t know what it means? We plan to have this as a faceted option in the future, and it will be interesting to see if that makes it more popular or not.
This enables users to only see ‘top level’ results, rather than all of the series and items as well. As it is a constant challenge to present hierarchical descriptions effectively, this would seem to be one means to simplify things. However, for October 2015 we had 17 uses of this function, and for the whole year only 148. This is almost negligible. It is curious that so few users chose to use this. Is it an indication that they don’t find it useful, or that they didn’t know what it means? We plan to have this as a faceted option in the future, and it will be interesting to see if that makes it more popular or not.
We are considering whether we should run this exercise using some sort of filtering to check for search engines, dubious IP addresses, spammers, etc., and therefore get a more accurate result in terms of human users. We would be very interested to hear from anyone who has undertaken this kind of exercise.