There are many ways of utilising the International Image Interoperability framework (IIIF) in order to deliver high-quality, attributed digital objects online at scale. One of the exploratory areas focused on in Images and Machine Learning – a project which is part of Archives Hub Labs – is how to display the context of the archive hierarchy using IIIF alongside the digital media.
Two of the objectives for this project are:
to explore IIIF Manifest and IIIF Collection creation from archive descriptions.
to test IIIF viewers in the context of showing the structure of archival material whilst viewing the digitised collections.
We have been experimenting with two types of resource from the IIIF Presentation API. The IIIF Manifest added into the Mirador viewer on the collection page contains just the images, in order to easily access these through the viewer. This is in contrast to a IIIF Collection, which we have been experimenting with. The IIIF Collection includes not only the images from a collection but also metadata and item structure within the IIIF resource. It is defined as a set of manifests (or ‘child’ collections) that communicate hierarchy or gather related things (for example, a set of boxes that each have folders within them, and photographs within those folders). We have been testing whether this has the potential to represent the hierarchy of an archival structure within the IIIF structure.
Creating a User Interface
Since joining the Archives Hub team, one of the areas I’ve been involved in is building a User Interface for this project that allows us to test out the different ways in which we can display the IIIF Images, Manifests and Collections using the IIIF Image API and the IIIF Presentation API. Below I will share some screenshots from my progress and talk about my process when building this User Interface.
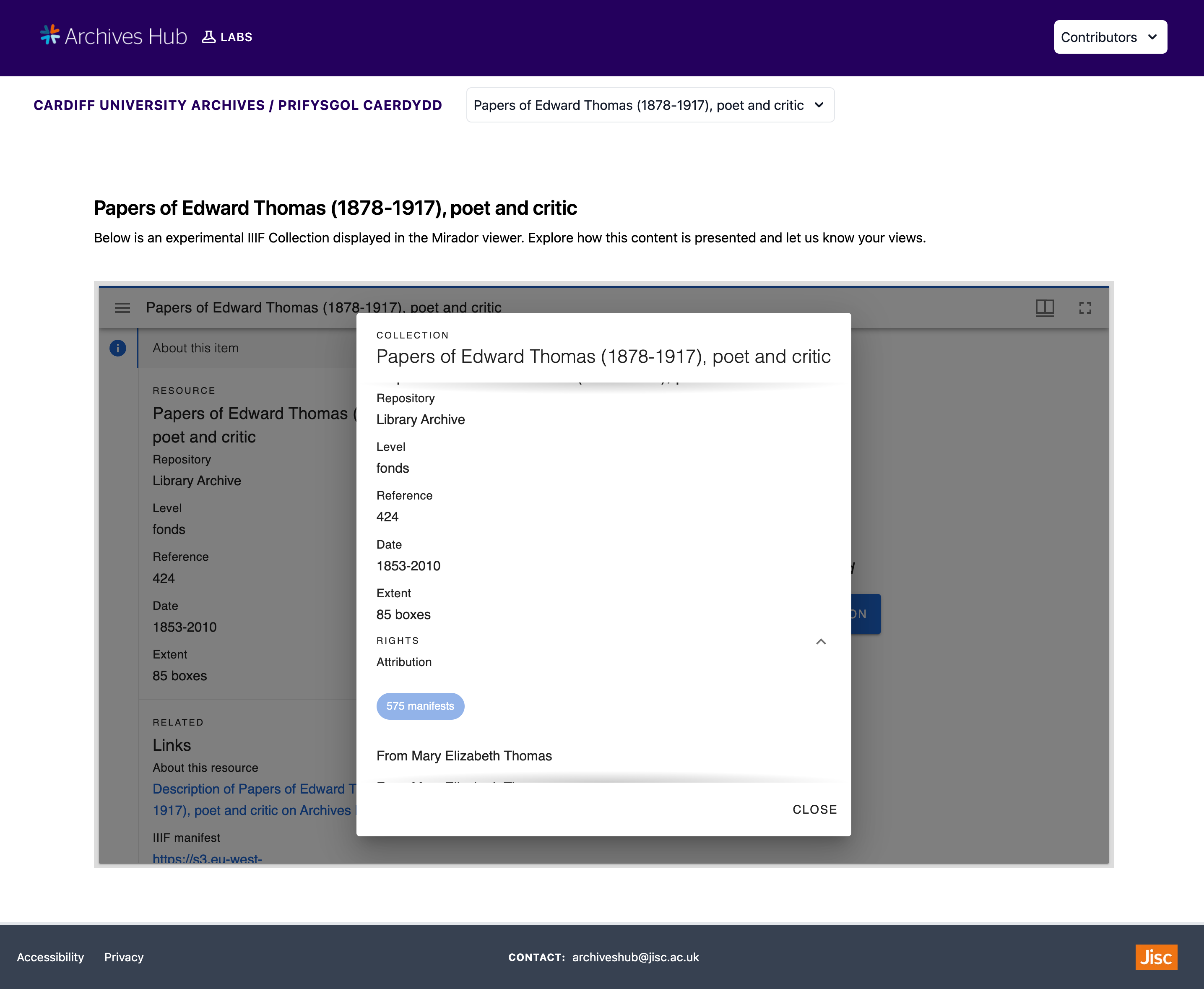
The homepage for the UI showing the list of contributors for this project.
The collections from all of our contributors that are being displayed within the UI using IIIF manifests and collections.
This web application is currently a prototype and further development will be happening in the future. The programming language I am using is Typescript. I began by creating a Next.js React application and I am also using Tailwind CSS for styling. My first task was to use the Mirador viewer to display IIIF Collections and Manifests, so I installed the mirador package into the codebase. I created dynamic pages for every contributor to display their collections.
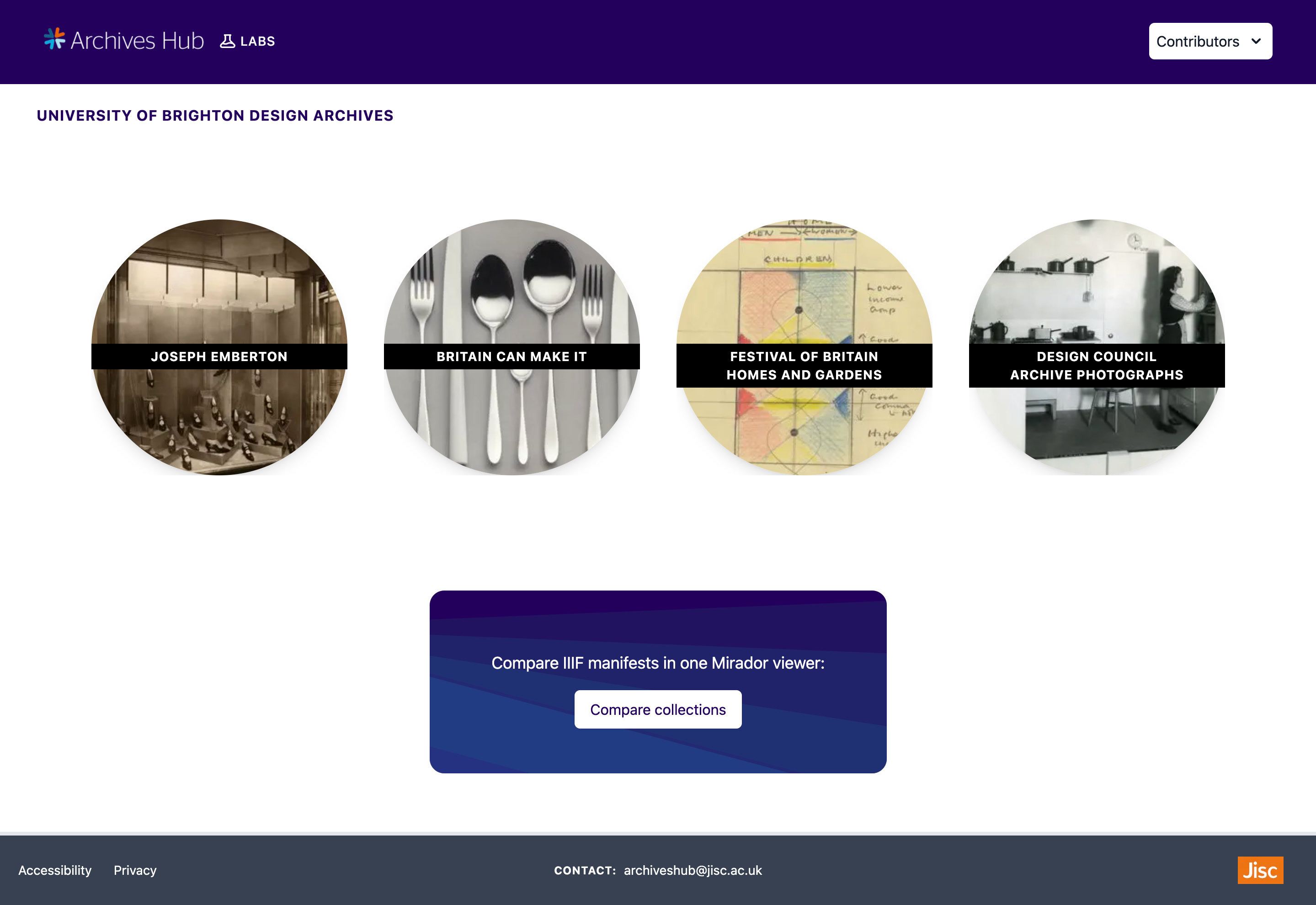
This is the contributor page for the University of Brighton Design Archives.
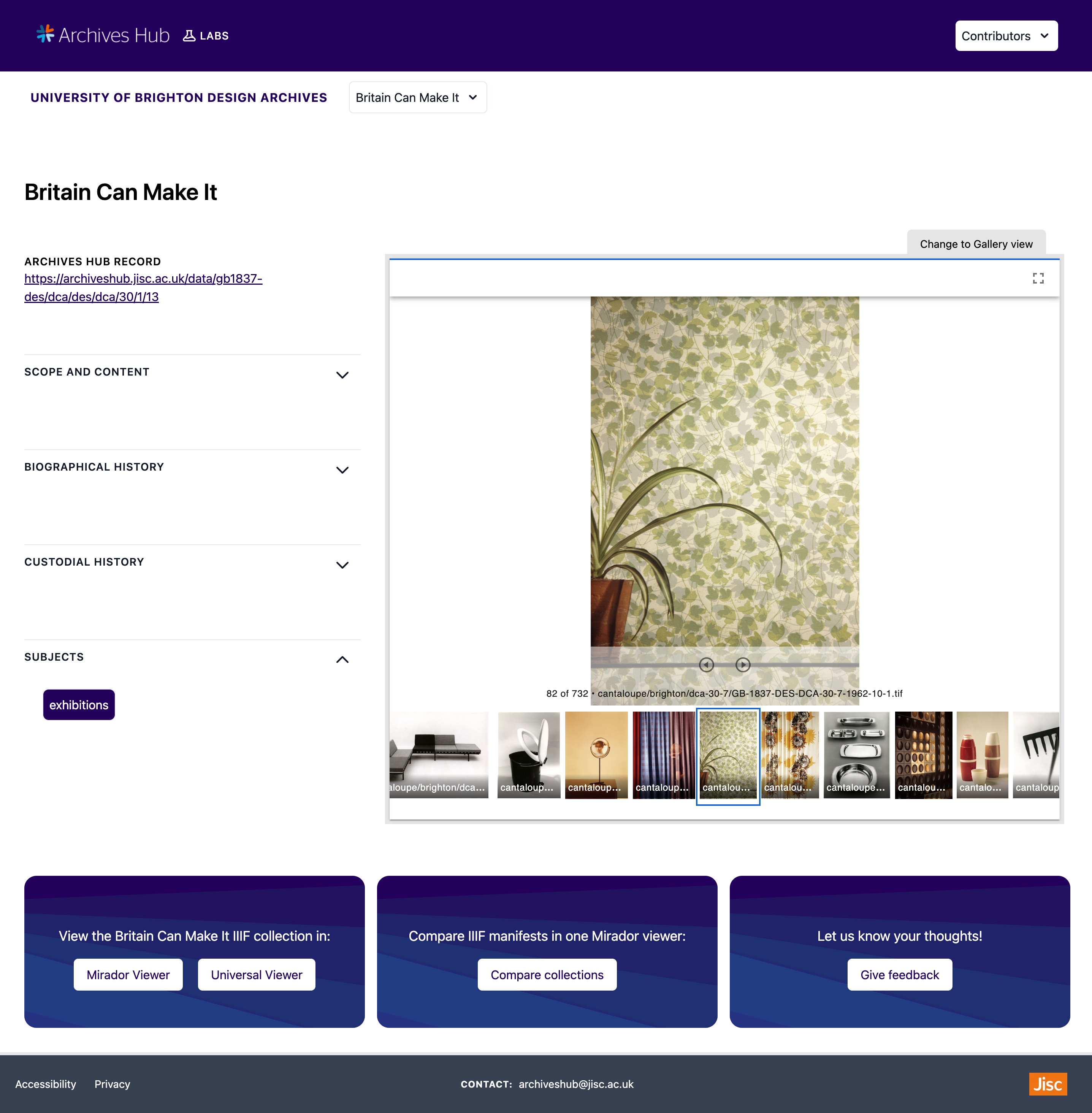
I also created dynamic collection pages for each collection. Included on the left-hand side of a collection page is the archives hub record link and the metadata about the collection taken from the archival EAD data – these sections displaying the metadata can be extended or hidden. The right-hand side of a collection page features aMirador viewer. A simple IIIF Manifest has been added for all of the images in each collection. This Manifest is used to help quickly navigate through and browse the images in the collection.
This is the collection page for the University of Brighton Design Archives ‘Britain Can Make It’ collection.
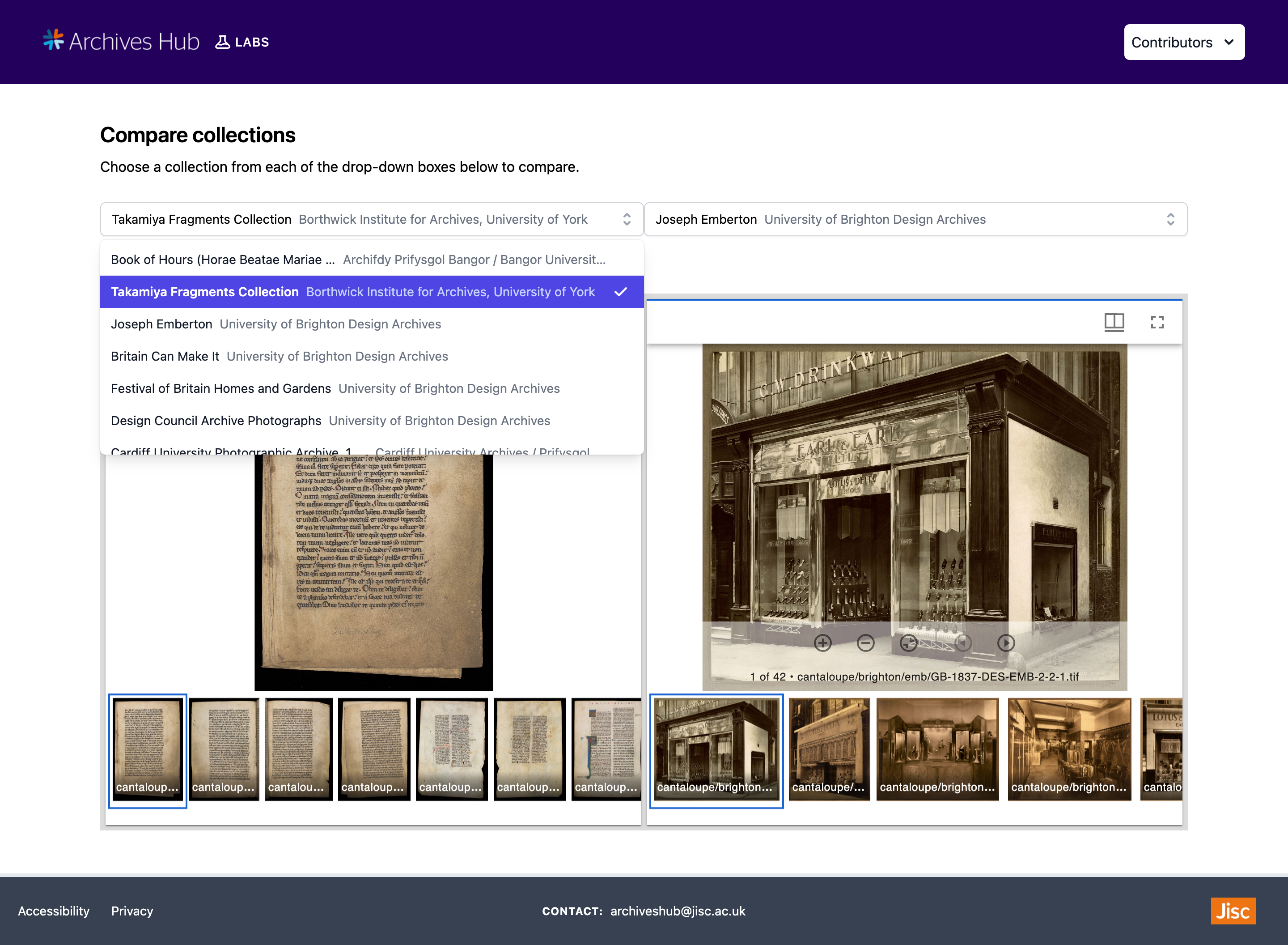
Mirador has the ability to display multiple windows within one workspace. This is really useful for comparison of images side-by-side. Therefore, I have also created a ‘Compare Collections’ page where two Manifests of collection images can be compared side-by-side. I have configured two windows to display within one Mirador viewer. Then, two collections can be chosen for comparison using the dropdown select boxes seen in the image below.
The ‘Compare Collections’ page.
Next steps
There are three key next steps for developing the User Interface –
We have experimented with the Mirador viewer, and now we will be looking at how the Universal Viewer handles IIIF Collections.
From the workshop feedback and from our exploration with the display of images, we will be looking at how we can offer an alternative experience of these archival images – distinct from their cataloguing hierarchy – such as thematic digital exhibitions and linking to other IIIF Collections and Manifests that already exist.
As part of the Machine Learning aspect of this project, we will be utilising the additional option to add annotations within the IIIF resources, so that the ML outputs from each image can be added as annotations and displayed in a viewer.
Labs IIIF Workshop
We recently held a workshop with the Archives Hub Labs project participants in order to get feedback on viewing the archive hierarchy through these IIIF Collections, displayed in a Mirador viewer. In preparation for this workshop, Ben created a sample of IIIF Collections using the images kindly provided by the project participants and the archival data related to these images that is on the Archives Hub. These were then loaded into the Mirador viewer so our workshop participants could see how the collection hierarchy is displayed within the viewer. The outcomes of this workshop will be explored in the next Archives Hub Labs blog post.
Thank you to Cardiff University, Bangor University, Brighton Design Archives at the University of Brighton, the University of Hull, the Borthwick Institute for Archives at the University of York, Lambeth Palace (Church of England) and Lloyds Bank for providing their digital collections and for participating in Archives Hub Labs.
As part of the Archives Hub Labs ‘Images and Machine Learning’ project we are currently exploring the challenges around implementing IIIF image services for archival collections, and also for Archives Hub more specifically as an aggregator of archival descriptions. This work is motivated by our desire to encourage the inclusion of more digital content on Archives Hub, and to improve our users’ experience of that content, in terms of both display and associated functionality.
Before we start to report on our progress with IIIF, we thought it would be useful to capture some of our current ideas and objectives with regards to the presentation of digital content on Archives Hub. This will help us to assess at later stages of the project how well IIIF supports those objectives, since it can be easy to get caught up in the excitement of experimenting with new technologies and lose sight of one’s starting point. It will also help our audience to understand how we’re aiming to develop the Hub, and how the Labs project supports those aims.
Crucial part of modern research and engagement with collections, especially after the pandemic
Another route into archives for researchers
Contributes to making archives more accessible
Will enable us to create new experiences and entry points within Archives Hub
To support contributing archives which can’t host or display content themselves
The poet Edward Thomas, ‘Wearing hat, c.1904’
The Current Situation
At the moment our contributors can include digital content in their descriptions on Archives Hub. They add links to their descriptions prior to publication, and they can do this at any level, e.g. ‘item’ level for images of individually catalogued objects, or maybe ‘fonds’ or ‘collection’ level for a selection of sample images. If the links are to image files, these are displayed on the Hub as part of the description. If the links are to video or audio files, or documents, we just display a link.
There are a few disadvantages to this set up: it can be a labour-intensive process adding individual links to descriptions; links often go dead because content is moved, leading to disappointment for researchers; and it means contributing archives need to be able to host content themselves, which isn’t always possible.
Where images are included in descriptions, these are embedded in the page as part of the description itself. If there are multiple images they are arranged to best fit the size of the screen, which means their order isn’t preserved.
If a user clicks on an image it is opened in a pop out viewer, which has a zoom button, and arrows for browsing if there is more than one image.
The embedded image and the viewer are both quite small, so there is also a button to view the image in fullscreen.
The viewer and the fullscreen option both obscure all or part of the decription itself, and there is no descriptive information included around the image other than a caption, if one has been provided.
As you can see the current interface is functional, but not ideal. Listed below are some of the key things we would like to look at and improve going forwards. The list is not intended to be exhaustive, but even so it’s pretty long, and we’re aware that we might not be able to fix everything, and certainly not in one go.
Documenting our aims though is an important part of steering our innovations work, even if those aims end up evolving as part of the exploration process.
Display and Viewing Experience
❐ The viewer needs updating so that users can play audio and video files in situ on the Hub, just as they can view images at the moment. It would be great if they could also read documents (PDF, Word etc).
❐ Large or high-resolution image files should load more quickly into the viewer.
❐ The viewer should also include tools for interacting with content, e.g. for images: zoom, rotate, greyscale, adjust brightness/contrast etc; for audio-visual files: play, pause, rewind, modify speed etc.
❐ When opened, any content viewer should expand to a more usable size than the current one.
❐ Should the viewer also support the display of descriptive information around the content, so that if the archive description itself is obscured, the user still has context for what they’re looking at? Any viewer should definitely clearly display rights and licensing information alongside content.
‘Now for a jolly ride at Bridlington’
Search and Navigation
❐ The Archives Hub search interface should offer users the option to filter by the type of digital content included in their search results (e.g. image, video, PDF etc).
❐ The search interface should also highlight the presence of digital content in search results more prominently, and maybe even include a preview?
❐ When viewing the top level of a multi-level description, users should be able to identify easily which levels include digital content.
❐ Users should also be able to jump to the digital content within a multi-level description quickly – possibly being able to browse through the digital content separately from the description itself?
❐ Users should be able to begin with digital content as a route into the material on Archives Hub, rather than only being able to search the text descriptions as their starting point.
Contributor Experience
Britain Can Make It: ‘Things for children’ (1946)
❐ Perhaps Archives Hub should offer some form of hosting service, to support archives, improve availability of digital content on the Hub, and allow for the development of workflows around managing content?
❐ Ideally, we would also develop a user-friendly method for linking content to descriptions, to make publishing and updating digital content easy and time-efficient.
❐ Any workflows or interfaces for managing digital content should be straightforward and accessible for non-technical staff.
❐ The service could give contributors access to innovative but sustainable tools, which drive engagement by highlighting their collections.
❐ If possible, any resources created should be re-usable within an archive’s own sites or resources – making the most of both the material and the time invested.
Future Possibilities
❐ We could look at offering options for contributors to curate content in creative and inventive ways which aren’t tied to cataloguing alone, and which offer alternative ways of experiencing archival material for users.
❐ It would be exciting for users to be able to ‘collect’, customise or interact with content in more direct ways. Some examples might include:
Creating their own collections of content
Creating annotations or notes
Publicly tagging or commenting on content
❐ Develop the experience for users with things like: automated tagging of images for better search; providing searchable OCR scanned text for text within images; using the tagging or classification of content to provide links to information and resources elsewhere.
In the ArchivesGrid analysis, the <unitdate> field use is around 72% within the high-level (usually collection level) description. The Archives Hub does significantly better here, with an almost universal inclusion of dates at this level of description. Therefore, a date search is not likely to exclude any potentially relevant descriptions. This is important, as researchers are likely to want to restrict their searches by date. Our new system also allows sorting retrieved results by date. The only issue we have is where the dates are non-standard and cause the ordering to break down in some way. But we do have both displayed dates and normalised dates, to enable better machine processing of the data.
Collection Title
“for sorting and browsing…utility depends on the content of the element.”
Titles are always provided, but they are very varied. Setting aside lower-level descriptions, which are particularly problematic, titles may be more or less informative. We may introduce sorting by title, but the utility of this will be limited. It is unlikely that titles will ever be controlled to the extent that they have a level of consistency, but it would be fascinating to analyse titles within the context of the ways people search on the Web, and see if we can gauge the value of different approaches to creating titles. In other words, what is the best type of title in terms of attracting researchers’ attention, search engine optimisation, display within search engine results, etc?
Lower-level descriptions tend to have titles such as ‘Accounts’, ‘Diary’ or something more difficult to understand out of context such as ‘Pigs and boars’ or ‘The Moon Dragon’. It is clearly vital to maintain the relationship of these lower-level descriptions to their parent level entries, otherwise they often become largely meaningless. But this should be perfectly possible when working on the Web.
It is important to ensure that a researcher finding a lower-level description through a general search engine gets a meaningful result.
A search result within Google
The above result is from a search for ‘garrick theatre archives joanna lumley’ – the sort of search a researcher might carry out. Whilst the link is directly to a lower -level entry for a play at the Garrick Theatre, the heading is for the archive collection. This entry is still not ideal, as the lower-level heading should be present as well. But it gives a reasonable sense of what the researcher will get if they click on this link. It includes the <unitid> from the parent entry and the URL for the lower-level, with the first part of the <scopecontent> for the entry. It also includes the Archives Hub tag line, which could be considered superfluous to a search for Garrick Theatre archives! However, it does help to embed the idea of a service in the mind of the researcher – something they can use for their research.
Extent
“It would be useful to be able to sort by size of collection, however, this would require some level of confidence that the <extent> tag is both widely used and that the content of the tag would lends itself to sorting.”
This was an idea we had when working on our Linked Data output. We wanted to think about visualizations that would help researchers get a sense of the collections that are out there, where they are, how relevant they are, and so on. In theory the ‘extent’ could help with a weighting system, where we could think about a map-based visualization showing concentrations of archives about a person or subject. We could also potentially order results by size – from the largest archive to the smallest archive that matches a researchers’ search term. However, archivists do not have any kind of controlled vocabulary for ‘extent’. So, within the Archives Hub this field can contain anything from numbers of boxes and folders to length in linear metres, dimensions in cubic metres and items in terms of numbers of photographs, pamphlets and other formats. ISAD(G) doesn’t really help with this; the examples they give simply serve to show how varied the description of extent can be.
Genre
“Other examples of desired functionality include providing a means in the interface to limit a search to include only items that are in a certain genre (for example, photographs)”.
This is something that could potentially be useful to researchers, but archivists don’t tend to provide the necessary data. We would need descriptions to include the genre, using controlled vocabulary. If we had this we could potentially enable researchers to select types of materials they are interested in, or simply include a flag to show, e.g. where a collection includes photographs.
The problem with introducing a genre search is that you run the risk of excluding key descriptions, because the search will only include results where the description includes that data in the appropriate location. If the word ‘photograph’ is in the general description only then a specific genre search won’t find it. This means a large collection of photographs may be excluded from a search for photographs.
Subject
In the Bron/Proffitt/Washburn article <controlaccess> is present around 72% of the time. I was surprised that they did not choose to analyse tags within <controlaccess> as I think these ‘access points’ can play a very important role in archival descrpition. They use the presence of <controlaccess> as an indication of the presence of subjects, and make the point that “given differences in library and archival practices, we would expect control of form and genre terms to be relatively high, and control of names and subjects to be relatively low.”
On the Archives Hub, use of subjects is relatively high (as well as personal and corporate names) and use of form and genre is very low. However, it is true to say that we have strongly encouraged adding subject terms, and archivists don’t generally see this as integral to cataloguing (although some certainly do!), so we like to think that we are partly responsible for such a high use of subject terms.
Subject terms are needed because they (1) help to pull out significant subjects, often from collections that are very diverse, (2) enable identification of words such as ‘church’ and ‘carpenter’ (ie. they are subjects, not surnames), (3) allow researchers to continue searching across the Archives Hub by subject (subjects are all linked to the browse list) and therefore pull collections together by theme (4) enable advanced searching (which is substantially used on the Hub).
Names (personal and corporate)
In Bron/Proffitt/Washburn the <origination> tag is present 87% of the time. The analysis did not include the use of <persname> and <corpname> within <origination> to identify the type of originator. In the Archives Hub the originator is a required field, and is present 99%+ of the time. However, we made what I think is a mistake in not providing for the addition of personal or corporate name identification within <origination> via our EAD Editor (for creating descriptions) or by simply recommending it as best practice. This means that most of our originators cannot be distinguished as people or corporate bodies. In addition, we have a number where several names are within one <origination> tag and where terms such as ‘and others’, ‘unknown’ or ‘various’ are used. This type of practice is disadvantageous to machine processing. We are looking to rectify it now, but addressing something like this in retrospect is never easy to do. The ideal is that all names within origination are separately entered and identified as people or organisations.
We do also have names within <controlaccess>, and this brings the same advantages as for <subjects>, ensuring the names are properly structured, can be used for searching and for bringing together archives relating to any one individual or organisation.
Repository
“Use of this element falls into the promising complete category (99.46%: see Table 7). However, a variety of practice is in play, with the name of the repository being embellished with <subarea> and <address> tags nested within <repository>.”
On the Archives Hub repository is mandatory, but as yet we do not have a checking system whereby a description is rejected if it does not contain this field. We are working towards something like this, using scripts to check for key information to help ensure validity and consistency at least to a minimum standard. On one occasion we did take in a substantial number of descriptions from a repository that omitted the name of repository, which is not very useful for an aggregation service! However, one thing about <repository> is that it is easy to add because it is always the same entry. Or at least it should be….we did recently discovery that a number of repositories had entered their name in various ways over the years and this is something we needed to correct.
Scope and content, biographical history and abstract
It is notable that in the US <abstract> is widely used, whereas we don’t use it at all. It is intended as a very brief summary, whereas <scopecontent> can be of any length.
“For search, its worth noting that the semantics of these elements are different, and may result in unexpected and false “relevance””
One of the advantages of including <controlaccess> terms is to mitigate against this kind of false relevance, as a search for ‘mason’ as a person and ‘mason’ as a subject is possible through restricted field searching.
The Bron/Proffitt /Washburn analysis shows <bioghist> used 70% of the time. This is lower than the Archives Hub, where it is rare for this field not to be included. Archivists seem to have a natural inclination to provide a reasonably detailed biographical history, especially for a large collection focussed on one individual or organisation.
Digital Archival Objects
It is a shame that the analysis did not include instances of <dao>, but it is likely to be fairly low (in line with previous analysis by Wisser and Dean, which puts it lower than 10%). The Archives Hub currently includes around 1,200 instances of images or links to digital content. But what would be interesting is to see how this is growing over time and whether the trajectory indicates that in 5 years or so we will be able to provide researchers with routes into much of the Archives Hub content. However, it is worth bearing in mind that many archives are not digitised and are not likely to be digitised, so it is important for us not to raise expectations that links to digital content will become a matter of course.
The Future of Discovery
“In order to make EAD-encoded finding aids more well suited for use in discovery systems, the population of key elements will need to be moved closer to high or (ideally) complete.”
This is undoubtedly true, but I wonder whether the priority over and above completeness is consistency and controlled vocabulary where appropriate. There is an argument in favour of a shorter description, that may exclude certain information about a collection, but is well structured and easier to machine process. (Of course, completeness and consistency is the ideal!).
The article highlights geo-location as something that is emerging within discovery services. The Archives Hub is planning on promoting this as an option once we move to the revised EAD schema (which will allow for this to be included), but it is a question of whether archivists choose to include geographical co-ordinates in their catalogues. We may need to find ways to make this as easy as possible and to show the potential benefits of doing so.
In terms of the future, we need a different perspective on what EAD can and should be:
“In the early days of EAD the focus was largely on moving finding aids from typescript to SGML and XML. Even with much attention given over to the development of institutional and consortial best practice guidelines and requirements, much work was done by brute force and often with little attention given to (or funds allocated for) making the data fit to the purpose of discovery.”
However, I would argue that one of the problems is that archivists sometimes still think in terms of typescript finding aids; of a printed finding aid that is available within the search room, and then made available online….as if they are essentially the same thing and we can use the same approach with both. I think more needs to be done to promote, explain and discuss ‘next generation finding aids’. By working with Linked Data, I have gained a very different perspective on what is possible, challenging the traditional approach to hierarchical finding aids.
Maybe we need some ‘next generation discovery’ workshops and discussions – but in order to really broaden our horizons we will need to take heed of what is going on outside of our own domain. We can no longer consider archival practice in isolation from discovery in the most general sense because the complexity and scale of online discovery requires us to learn from others with expertise and understanding of digital technologies.
A HEFCE study from 2010 states that “96% of students use the internet as a source of information” (1). This makes me wonder about the 4% that don’t; it’s not an insignificant number. The same study found that “69% of students use the internet daily as part of their studies”, so 31% don’t use it on a daily basis (which I take to mean ‘very frequently’).
There have been many reports on the subject of technology and its impact on learning, teaching and education. This HEFCE/NUS study is useful because it concentrates on surveying students rather than teachers or information professionals. One of the key findings is that it is important to think about the “effective use of technology” and “not just technology for technology’s sake”. Many students still find conventional methods of teaching superior (a finding that has come up in other studies), and students prefer a choice in how they learn. However, the potential for use of ICT is clear, and the need to engage with it is clear, so it is worrying that students believe that a significant number of staff “lack even the most rudimentary IT skills”. It is hardy surprising that the experiences of students vary considerably when they are partly dependent upon the skills and understanding of their teachers, and whether teachers use technology appropriately and effectively.
At the recent ELAG conference I gave a joint presentation with Lukas Koster, a colleague from the University of Amsterdam, in which we talked about (and acted out via two short sketches) the gap between researchers’ needs and what information professionals provide. Thinking simply about something as seemingly obvious as the understanding and use of
Random selection of interface terminology from archives sites.
the term ‘archives’ is a good case in point. Should we ensure that students understand the different definitions of archives? The distinction between archives that are collections with a common provenance and archives that are artificial collections? The different characters of archives that are datasets, generally used by social scientists? The “abuse” of the term archives for pretty much anything that is stored in any kind of longer-term way? Should users understand archival arrangement and how to drill down into collections? Should they understand ‘fonds’, ‘manuscripts’, ‘levels’, ‘parent collection’? Or is it that we should think more about how to translate these things into everyday language and simple design, and how to work things like archival hierarchy into easy-to-use interfaces? I think we should take the opportunities that technology provides to find ways to present information in such a way that we facilitate the user experience. But if students are reporting a lack of basic ICT skills amongst teachers, you have to wonder whether this is a problem within the archive and library sector as well. Do information professionals have appropriate ICT skills fit for ensuring that we can tailor our services to meet the needs of the technically savvy user?
Should we be teaching information literacy to students? One of the problems with this idea is that they tend to think they are already pretty literate in terms of use of the internet. In the HEFCE report, a survey of 213 FE students found that 88% felt they were effective online researchers and the majority said they were self-taught. They would not be likely to attend training on how to use the internet. And there is a question over whether they need to be taught how to use it in the ‘right’ way, or whether information professionals should, in fact, work with the reality of how it is being used (even if it is deemed to be ‘wrong’ in some way). Students are clear that they do want training “around how to effectively research and reference reliable online resources”, and maybe this is what we should be concentrating on (although it might be worth considering what ‘effective use of the internet’ and ‘effective research using the internet’ actually mean). Maybe this distinction highlights the problem with how to measure effective use of the internet, and how to define online or discovery skills.
A British Library survey from 2010 found that “only a small proportion [of students] …are using technology such as virtual-research environments, social bookmarking, data and text mining, wikis, blogs and RSS-feed alerts in their work.” This is despite the fact that many respondents in the survey said they found such tools valuable. This study also showed that students turn to their peers or supervisors rather than library staff for help.
Part of the problem may be that the vast majority of users use the internet for leisure purposes as well as work or study, so the boundaries can become blurred, and they may feel that they are adept users without distinguishing between different types of use. They feel that they are ‘fine with the technology’, although I wonder if that could be because they spend hours playing World of Warcraft, or use Facebook or Twitter every day, or regularly download music and watch YouTube. Does that mean they will use technology in an effective way as part of their studies? The trouble is that if someone believes that they are adept at searching, they may not go that extra mile to reflect on what they are doing and how effective it really is. Do we need to adjust our ways of thinking to make our resources more user-friendly to people coming from this kind of ‘I know what I’m doing’ mindset, or do we have to disabuse them of this idea and re-train them (or exhort them to read help pages for example…which seems like a fruitless mission)? Certainly students have shown some concern over “surface learning” (skim reading, learning only the minimum, and not getting a broader understanding of issues), so there is some recognition of an issue here, and the tendency to take a superficial approach might be reinforced if we shy away from providing more sophisticated tools and interfaces.
The British Library report on the Information Behaviour of the Researcher of the Future reinforces the idea that there is a gulf between students’ assumptions regarding their ICT skills versus the reality, which reveals a real lack of understanding. It also found a significant lack of training in discovery and use of tools for postgraduate students. Studies like this can help us think about how to design our websites, and provide tools and services to help researchers using archives. We have the challenges of how to make archives more accessible and easy to discover as well as thinking about how to help students use and interpret them effectively: “The college students of the open source, open content era will distinguish themselves from their peers and competitors, not by the information they know, but by how well they convert that knowledge to wisdom, slowly and deeply internalized.” (Sheila Stearns, “Literacy in the University of 2025: Still A Great Thing‟, from The Future of Higher Education , ed. by Gary Olson & John W Presley, (Boulder: Paradigm Publishers, 2009) pp. 98-99).
What are the Solutions?
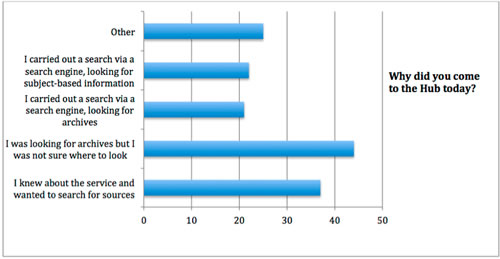
We should make user testing more integral to the development of our interfaces. It requires resource, but for the Archives Hub we found that even carrying out 10 one-hour interviews with students and academics helped us to understand where we were making assumptions and how we could make small modifications that would improve our site. And our annual online survey continues to provide really useful feedback which we use to adjust our interface design, navigation and terminology. We can understand more about our users, and sometimes our assumptions about them are challenged.
Archives Hub survey 2013: Why did you come to the Hub today?
User groups for commercial software providers can petition to ensure that out-of-the-box solutions also meet users’ needs and take account of the latest research and understanding of users’ experiences, expectations and preferences in terms of what we provide for them. This may be a harder call, because vendors are not necessarily flexible and agile; they may not be willing to make radical changes unless they see a strong business case (i.e. income may be the strongest factor).
We can build a picture of our users via our statistics. We can look at how users came into the site, the landing pages, where they went from there, which pages are most/least popular, how long they spent on individual pages, etc. This can offer real insights into user behaviour. I think a few training sessions on using Google Analytics on archive sites could come in handy!
We can carry out testing to find out how well sites rank on search engines, and assess the sort of experience users get when they come into a specialist site from a general search engine. What is the text a Google search shows when it finds one of your collections? What do people get to when they click on that link? Is it clear where they are and what they can do when they get to your site?
* * *
This is the only generation where the teachers and information professionals have grown up in a pre-digital world, and the students (unless they are mature students) are digital natives. Of course, we can’t just sit back and wait a generation for the teachers and information professionals to become more digitally minded! But it is interesting to wonder whether in 25 years time there will be much more consensus in approaches to and uses of ICT, or whether the same issues will be around.
Nigel Shadbolt has described the Web as “one of the most disruptive innovations we have ever witnessed” and at present we really seem to be struggling to find out how best to use it (and not use it), how and when to train people to use it and how and when to integrate it into teaching, learning and research in an effective way.
It seems to me that there are so many narratives and assessments at present – studies and reports that seem to run the gamut of positive to negative. Is technology isolating or socialising? Are social networks making learning more superficial or enabling richer discussion and analysis? Is open access democratising or income-reducing? Is the high cost of technology encouraging elitism in education? Does the fact that information is so easily accessible mean that researchers are less bothered about working to find new sources of information? With all these types of debates there is probably no clear answer, but let us hope we are moving forward in understanding and in our appreciation of what the Web can do to both enhance and transform learning, teaching and research.
I was lucky enough to attend the 2012 EmTACL conference in Trondheim, and this blog is based around the excellent keynote presentation by Herbert van de Sompel, which really made me think about temporal issues with the Web and how this can limit our understanding of the scholarly record.
Herbert believes that the current infrastructure for scholarly communication is not up to the job. We now have many non-traditional assets, which do not always have fixity and often have a wide range of dependencies; assets such as datasets, blogs, software, videos, slides which may form part of a scholarly resource. Everything is much more dynamic than it used to be. ‘Research objects’ often include assets that are interdependent with each other, so they need to be available all together for the object to be complete. But this is complicated by the fact that many of them are ‘in motion’ and updated over time.
This idea of dynamic resources that are in flux, constantly being updated, is very relevant for archivists, partly because we need to understand how archives are not static and fixed in time, and partly because we need to be aware of the challenges of archiving ever more complex and interconnected resources. It is useful to understand the research environment and the way technology influences outputs and influences what is possible for future research.
There are examples of innovative services that are responding to the opportunities of dynamic resources. One that Herbert mentioned was PLOS, which publishes open scholarly articles. It puts publications into Wikipedia as well as keeping the ‘static’ copy, so that the articles have a kind of second life where they continue to evolve as well as being kept as they were at the time of submission. For example, ‘Circular Permutation in Proteins‘.
The idea of executable papers is starting to become established – papers that are not just to read but to interact with. These contain access to the primary data with capabilities to re-execute algorithms and even capabilities to allow researchers to upload and use their own data. It produces a complex interdependency and produces a challenge for archiving because if something is not fixed in time, what does that mean for retaining access to it over time?
This all raises the issue of what the scholarly record actually is. Where does it start? Where does it end? We are no longer talking about a bunch of static files but a dynamic interconnected resource. In fact, there is an increasing sense that the article itself is not necessarily the key output, but rather it is the advertising for the actual scholarship.
Herbert concluded from this that it becomes very important to be able to view different points in time in the evolution of scholarly record, and this should be done in a way that works with the Web. The Web is the platform, the infrastructure for the scholarly record. Scholarly communication then becomes native to the Web. At the heart of this is the need to use HTTP URIs.
However, where are we at the moment? The current archival infrastructure for scholarly outputs deals with things with fixity and boundaries. It cannot deal with things in flux and with inter-dependencies. The Web exists in ‘now’ time; it does not have a built in notion of time. It assumes that you want the current version of something – you cannot use a URI to get to a prior version.
Slide from Herbert van de Sompel’s presentation showing the publication context on the Web
We don’t really object to this limitation, something evidenced by the fact that we generally accept links that take us to 404 pages, as if it is just an inevitable inconvenience. Maybe many people just don’t think that there is any real interest in or requirement for ‘obsolete’ resources, and what is current is what is important on the Web.
Of course, there is the Internet Archive and other similar initiatives in Web archiving, but they are not integrated into the Web. You have to go somewhere completely different in order to search for older copies of resources.
If the research paper remains the same, but resources that are an integral part of it change over time, then we need to change archiving to reflect this. We need to think about how to reference assets over time and how to recreate older versions. Otherwise, we access the current version, but we are not getting the context that was there at the time of creation; we are getting something different.
Can we recreate a version of a scholarly record? Can we go back to certain point it time so we can see linked assets from a paper as they were at the time of publication? At the moment we are likely to get many 404s when we try to access links associated with a publication. Herbert showed one survey on the decay of URLs in Medline, which is about 10% per year, especially with links to thinks like related databases.
One solution to this is to be able to follow a URI in time – to be able to click on URI and say ‘I want to see this as was 2 years ago’. Herbert went on to talk about something he has created called Memento. Memento aims to better integrate the current and past Web. It allows you to select a day or time in the browser and effectively take the URI back in time. Currently, the team are looking at enabling people to browse past pages of Wikipedia. Memento has a fairly good success rate with going back to retrieve old versions, although it will not work for all resources. I tried it with the Archives Hub and found it easy to take the website back to how it looked right in the very early days.
Using Memento to take the Archives Hub back in time.
One issue is that the archived copies are not always created near the time of publication. But for those that are, they are created simply as part of the normal activity of the Web, by services like the Internet Archive or the British Library, so there is no extra work involved.
Herbert outlined some of the issues with using DOIs (digital object identifiers), which provide identifiers for resources that use a resolver to ensure that the identifier can remain the same over time. This is useful if, for example, a publisher is bought out – the identifier is still the same as the resolver redirects to the right location However, a DOI resolver exists in the perpetual now. It is not possible to travel back in time using HTTP URIs. This is maybe one illustration of the way some of the processes that we have implemented over the Web do not really fulfil our current needs, as things change and resources become more complex and dynamic.
With Memento, the same HTTP URI can function as the reference to temporally evolving resources. The importance of this type of functionality is becoming more recognised. There is a new experimental URI scheme, DURI , or Dated URI. The ideas is that a URI, such as http://www.ntnu.no, can be dated: 1997-06-17:http://www.ntnu.no (this is an example and is not actionable now). Herbert did raise another possibly of developing Websites that can deal with the TEL (telephone) protocol. The idea would be that the browser asks you whether the Website can use the TEL protocol, and if it can, you get this option offered to you. You can then use this and reference a resource and use Memento to go back in time.
Herbert concluded that the idea of ‘archiving’ should not be just a one-off event, but needs to happen continually. In fact, it could happen whenever there is an interaction. Also, when new materials are taken into a repository, you could scan for links and put them into an archive, so the links don’t die. If you archive the links at the time of publication or when materials submitted to a repository, then you protect against losing the context of the resource.
Herbert introduced us to SiteStory, which offers transactional archiving of a a web server. Usually a web archive sends out a robot, gathers and dumps the data. With SiteStory the web server takes an active part. Every time a user requests a page it is also pushed back into the archive, so you get a fine grained history of the resource. Something like this could be done by publishers/service providers, with the idea that they hold onto the hits, the impact, the audience. It certainly does seem to be a growing area of interest.
This is something that I’ve thought about quite a bit, as I work as the manager of an online service for Archives and I do training and teaching for archivists and archive students around creating online descriptions. I would like to direct this blog post to archive students or those considering becoming archivists. I think this applies equally to records managers, although sometimes they have a more defined role in terms of audience, so the perspective may be somewhat different.
It’s fine if you have ‘a love of history’, if you ‘feel a thrill when handling old documents’. That’s a good start. I’ve heard this kind of thing frequently as a motivation for becoming an archivist. But this is not enough. It is more important to have the desire to make those archives available to others; to provide a service for researchers. To become an archivist is to become a service provider, not an historian. It may not sound as romantic, but as far as I am concerned it is what we are, and we should be proud of the service we provide, which is extremely valuable to society. Understanding how researchers might use the archives is, of course, very important, so that you can help to support them in their work. Love of the materials, and love of the subject (especially in a specialist repository) should certainly help you with this core role. Indeed, you will build an understanding of your collections, and become more expert in them over time, which is one of the wonderful things about being an archivist.
Your core role is to make archives available to the community – for many of us, the community is potentially anyone, for some of us it may be more restricted in scope. So, you have an interest in the materials, you need to make them available. To do this you need to understand the vital importance of cataloguing. It is this that gives people a way in to the archives. Cataloguing is a real skill, not something to be dismissed as simply creating a list of what you have. It is something to really work on and think about. I have seen enough inconsistent catalogues over the last ten years to tell you that being rigorous, systematic and standards-based in cataloguing is incredibly important, and technology is our friend in this aim. Furthermore, the whole notion of ‘cataloguing’ is changing, a change led by the opportunities of the modern digital age and the perspectives and requirements of those who use technology in their every day life and work. We need to be aware of this, willing (even excited!) to embrace what this means for our profession and ready to adapt.
This brings me to the subject I am particularly interested in: the use of technology. Cataloguing *is* using technology, and dissemination *is* using technology. That is, it should be and it needs to be if you want to make an impact; if you want to effectively disseminate your descriptions and increase your audience. It is simply no good to see this profession as in any way apart from technology. I would say that technology is more central to being an archivist than to many professions, because we *deal in information*. It may be that you can find a position where you can keep technology at arm’s length, but these types of positions will become few and far between. How can you be someone who works professionally with information, and not be prepared to embrace the information environment? The Web, email, social networks, databases: these are what we need to use to do our jobs. We generally have limited resources, and technology can both help us make the most of the resources we have and, conversely, we may need to make informed choices about the technology we use and what sort of impact it will have. Should you use Flickr to disseminate content? What are the pros and cons? Is ‘augmented reality’ a reality for us? Should you be looking at Linked Data? What is is and why might it be important? What about Big Data? It may sound like the latest buzz phrase but it’s big business, and can potentially save time and money. Is your system fit for purpose? Does it create effective online catalogues? How interoperable is it? How adaptable?
Before I give the impression that you need to become some sort of technical whizz-kid, I should make clear that I am not talking about being an out-and-out techie – a software developer or programmer. I am talking about an understanding of technology and how to use it effectively. I am also talking about the ability to talk to technical colleagues in order to achieve this. Furthermore, I am talking about a willingness to embrace what technology offers and not be scared to try things out. It’s not always easy. Technology is fast-moving and sometimes bewildering. But it has to be seen as our ally, as something that can help us to bring archives to the public and to promote a greater understanding of what we do. We use it to catalogue, and I have written previously about how our choice of system has a great impact on our catalogues, and how important it is to be aware of this.
Our role in using technology is really *all about people*. I often think of myself as the middleman, between the technology (the developers) and the audience. My role is to understand technology well enough to work with it, and work with experts, to harness it in order to constantly evolve and use it to best advantage, but also to constantly communicate with archivists and with researchers. To have an understanding of requirements and make sure that we are relevant to end-users. Its a role, therefore, that is about working with people. For most archivists, this role will be within a record office or repository, but either way, working with people is the other side of the coin to working with technology. They are both central to the world of archives.
If you wonder how you can possibly think about everything that technology has to offer: well, you can’t. But that’s why it is even more vital now than it has ever been to think of yourself as being in a collaborative profession. You need to take advantage of the experience and knowledge of colleagues, both within the archives profession and further afield. It’s no good sitting in a bubble at your repository. We need to talk to each other and benefit from sharing our understanding. We need to be outgoing. If you are an introvert, if you are a little shy and quiet, that’s not a problem; but you may have to make a little more effort to engage and to reach out and be an active part of your profession.
They say ‘never work with children and animals’ in show business because both are unpredictable; but in our profession we should be aware that working with people and technology is our bread and butter. Understanding how to catalogue archives to make them available online, to use social networks to communicate our messages, to think about systems that will best meet the needs of archives management, to assess new technologies and tools that may help us in our work. These are vital to the role of a modern professional archivist.
This blog is about ‘Big Data’. I think it’s worth understanding what’s happening within this space, and my aim is to give a (reasonably) short introduction to the concept and possible relevance for archives.
I attended the the Eduserv Symposium 2012 on Big Data , and this post is partly inspired by what I heard there, in particular the opening talk by Rob Anderson, Chief Technology Officer EMEA. Thanks also to Adrian Stevenson and Lukas Koster for their input during our discussions of this topic (over a beer!).
What is Big Data? In the book Planning for Big Data (Edd Dumbill, O’Reilly) it is described as:
“data that exceeds the processing capacity of conventional database systems. The data is too big, moves too fast, or doesn’t fit the strictures of your database architectures. To gain value from this data you must choose an alternative way to process it.”
Big data is often associated with the massive and growing scale of data, and at the Eduserv Symposium many speakers emphasised just how big this increase in data is (which got somewhat repetitive). Many of them spoke about projects that involve huge, huge amounts of data, in particular medical and scientific data. For me tera- and peta- and whatever else -bytes don’t actually mean much. Suffice to say that this scale of data is way way beyond the sort of scale of data that I normally think about in terms of archives and archive descriptions.
We currently have more data than we can analyse, and 90% of the digital universe is unstructured, a fact that drives the move towards the big data approach. You may think big data is new; you may not have come across it before, but it has certainly arrived. Social media, electronic payments, retail analytics, video analysis of customers, medical imaging, utilities data, etc, etc., all are in the Big Data space, and the big players are there too – Google, Amazon, Walmart, Tesco, Facebook, etc., etc., – they all stand to gain a great deal from increasingly effective data analysis.
Very large scale unstructured data needs a different approach to structured data. With structured data there is a reasonable degree of routine. Data searches of a relational database, for example, are based around the principle of searching specific fields, the scope is already set out. But unstructured data is different, and requires a certain amount of experimentation with analysis.
The speakers throughout the Eduserv symposium emphasised many of the benefits that can come with the analysis of unstructured data. For example, Rob Anderson argued that we can raise the quality of patient care through analysis of various data sources – we can take into account treatments, social and economic factors, international perspective
, individual patient history. Another example he gave was the financial collapse: could we have averted this at least to some extent through being able to identify ‘at risk’ customers more effectively? It certainly seems convincing that analysing and understanding data more thoroughly could help us to improve public services and achieve big savings. In other words, data science principles could really bring public benefits and value for money.
The characteristics of big data
But the definition of big data as unstructured data is only part of the story. It is often characterised by three things, volume (scale), velocity (speed) and variety (heterogenous data).
It is reasonably easy to grasp the idea of volume – processing huge quantities of data. For this scale of data the traditional approaches, based on structured data, are often inadequate.
Velocity may relate to how quickly the data comes into the data centre and the speed of response. Real-time analysis is becoming increasingly effective, used by players like Google. It enables them to instantly identify and track trends – they are able to extract value from the data they are gathering. Similarly Facebook and Twitter are storing every message and monitoring every market trend. Amazon react instantly to purchase information – this can immediately affect price and they can adjust the supply chain. Tesco, for example, know when more of something is selling intensively and can divert supplies to meet demand. Big data approaches are undoubtedly providing great efficiencies for companies, although it raises the whole question of what these companies know about us and whether we are aware of how much data we are giving away.
The variety of data refers to diversity, maybe data from a variety of sources. It may be un-curated, have no schema, be inconsistent and changing. With these problems it can be hard to extract value. The question is, what is the potential value that can be extracted and how can that value be used to good effect? It may be that big data leads to the opti
mised organisation, but it takes time and skill to build what is required and it is important to have a clear idea of what you are wanting to achieve – what your value proposition is. Right now decisions are often made based on pretty poor information, and so they are often pretty poor decisions. Good data is often hard to get, so decisions may be based on little or no data at all. Many companies fail to detect shifts in consumer demand, but at the same time the Internet has made customers more segmented, so the picture is more complex. Companies need to adjust to this and respond to differing requirements. They need to take a more scientific approach because sophisticated analytics makes for better decisions and in the end better products.
Andy Powell introduces the Eduserv Symposium: Big Data, big deal?
At the Eduserv Symposium there were a number of speakers who provided some inspirational examples of what is possible with big data solutions. Dr Guy Coates from the Wellcome Trust Sanger Institute talked about the human genome. The ability to compare, correlate with other records and work towards finding genetic causes for diseases opens up exciting new opportunities. It is possible to work towards more personalised medicine, avoiding the time spent trying to work out which drugs work for individuals. Dr Coates talked about the rise of more agile systems, able to cope with this way of working, more modular design and an evolving incremental approach rather than the typical 3-year cycle of complete replacement of hardware.
Professor Anthony Brookes from the University of Leicester introduced the concept of ‘knowledge engineering’, thinking about this in the context of health. He stated that in many cases it may be that the rate of data generation is increasing, but it is often the same sort of data, so it may be that scale is not such an issue in all cases. This is an important point. It is easy to equate big data with scale, but it is not all about scale. The rise of Big Data is just as concerned with things like new tools that are making analysis of data more effective.
Prof Brookes described knowledge engineering as a discipline that involves integrating knowledge into computer systems in order to solve complex problems (see the i4health website for more information). He effectively conveyed how we have so much medical knowledge, but the knowledge is simply not used properly. Research and healthcare are separate – the data does not flow properly between them. We need to bring together bio-informatics and academics with medical informatics and companies, but at the moment there is a very definite gap, and this is a really really big problem. We need to build a bridge between the two, and for this you need an engineer – a knowledge engineer – someone with expertise to work through the issues involved in bridging the gap and getting the data flow right. The knowledge engineer needs to understand the knowledge potential, understand standards, understand who owns the data, understand the ethics, think about what is required to share data, such as having researcher IDs, open data discovery, remote pooled analysis of data, categories of risk for data. This type of role is essential in order to effect an integration of data with knowledge.
As well as hearing about the knowledge engineer we heard about the rise of the ‘data scientist‘, or, rather more facetiously, the “business analyst who lives in Califorina” (Adam Cooper’s blog). This concept of a data scientist was revisited throughout the Eduserv symposium. At one point it was referred to as “someone who likes telling stories around data”, an idea that immediately piqued my interest. It did seem to be a broad concept, encompassing both data analysis and data curation, although in reality these roles are really quite distinct, and there was acknowledgement that they need to be more clearly defined.
Big data has helped to create an atmosphere where expectations people have of the public sector are no longer met; expectations created by what is often provided in the private sector, for example, a more rapid response to enquiry. We expect the commercial sector to know about us and understand what we want and maybe we think public services should do the same? But organisational change is a big challenge in the public sector. Data analysis can actually be seen as opposed to the ‘human agenda’ as it moves away from the principle of human relationships. But data can drive public service innovation, and help to allocate resources efficiently, in a way that responds to need.
Big Data raises the question of the benefits of open, transparent and shared information. This message seems to come to the fore again and again, not just with Big Data, but with the whole open data agenda and Linked Data area. For example, advance warning for earthquakes requires real-time analytics – it is hard to extract this information from the diverse systems that are out there. But a Twitter-based Earthquake Detector provides substantial benefits. Simply by following #quake tweets it is possible to get a surprisingly accurate picture very quickly; apparently more #quake tweets has been shown to be an accurate indication of a bigger quake. Twitter users reacted extremely quickly to the quake and tsunami in Japan. In the US, the Government launched a cash for old cars initiative (Cash for Clunkers), to encourage people to move to greener vehicles. The Government were not sure whether the initiative was proving to be successful, but Google knew that it was, because they had the information about what people were searching for and they could see people searching for this initiative to find information about what the Government were offering. Google can instantly find out where in the world people are searching for information – for example, information about flu trends, because they can analyse which search terms are relevant, something called ‘nowcasting‘.
In the commercial sector big data is having a big impact, but it is less certain what its impact is within higher education and sectors such as cultural heritage. The question many people seem to be asking is ‘how will this be relevant to us?’
Big data may have implications for archivists in terms of what to keep and what to delete. We often log everything because we don’t know what questions we will want the answer to. But if we decide we can’t keep everything then what do we delete? We know that people only tend to criticise if you get it wrong. In the US the new National Science Foundation data retention requirements now mean you have to keep all data for 3 years after the research award conclusion, and you must produce a data management plan. But with more and more sophisticated means of processing data, should we be looking to keep data that we might otherwise dispose of? We might have considered it expensive to manage and hard to extract value from, but this is now changing. Should we always keep everything when we can? Many companies are simply storing more and more data ‘just in case’; partly because they don’t want to risk being accused of throwing it away if it turns out to be important. Our ideas of what we can extract from data are changing, and this may have implications for its value.
Does the archive community need to engage with big data? At the Eduserv Symposium one of the speakers referred to NARA making available documents for analysis. The analysis of data is something that should interest us:
“A common use of big data processing is to take unstructured data and extract ordered meaning, for consumption either by humans or as a structured input to an application.” (Planning for Big Data, Edd Dumbill).
For example, you might be looking to determine exactly what a name refers to: is this city London, England or London, Texas? Tasks such as crowd-sourcing, cleaning data, answering imprecise questions, these are relevant in the big data space and therefore potentially relevant within archives.
As already stated, it is about more than scale, and it can be very relevant to the end-user experience: “Big data is often about fast results, rather than simply crunching a large amount of information.” (Dumbill) For example, the ability to suggest on-the-fly which books someone might enjoy requires a system to provide an answer in the time it takes a page to load. It is possible to think about ways that this type of data processing could enhance the user experience within the archives space; helping the user to find what might be of relevance to their research. Again, expectations may start to demand that we provide this type of experience, as many other information sites already provide it.
The Eduserv Symposium concluded that there is a skills gap in both the public and commercial sector when it comes to big data. We need a new generation of “big data scientists” to meet a need. We also need to combine algorithms, machines and people holistically to meet the big data problem. There may be an issue around mindset, particularly in terms of worries about the use of data – something that arises in the whole open data agenda. In addition, one of the big problems we have at the moment is that we are often building on infrastructures that are not really suited to this type of unstructured data. It takes time, and knowledge of what is required, to move towards a new infrastructure, and the advance of big data may be held back by the organisational change required and skills needed to do this work.
Speaking at the recent World Wide Web (WWW2012) conference in Lyon, Neelie Kroes, Vice President of the European Commission, emphasised the benefits of an open Web: “With a truly open, universal platform, we can deliver choice and competition; innovation and opportunity; freedom and democratic accountability”.
But what does ‘open’ really mean? Do we really have a clear idea about what it is, how we achieve it, and what the benefits might be? And do we have a sense of what is happening in this landscape and the implications for our own domain?
There is a tendency to think that the social web equates to some degree with the open web, but this is not the case. Social sites like Facebook often create walled gardens, and you could argue that whilst they are connecting people, they are working against the principle of free and linked information. Just because the aim is to enable people to be social and connected, that doesn’t mean that it is done in a way that ensures the data is open.
Another confusion may arise around open and its relationship to privacy. Again, things can be open, but privacy can be respected. It’s about clear and transparent choices – whether you want your data to be open or whether you want to include some restrictions. We are not always aware of what we are giving away:
“the Net enables individuals in many cases to compromise privacy more thoroughly than the government and commercial institutions traditionally targeted for scrutiny and regulation. The standard approaches that have been developed to analyze and limit institutional actors do not not work well for this new breed of problem, which goes far beyond the compromise of sensitive information.” (Jonathan Zittrain, The Future of the Internet).
There is an irony that we often readily give away personal data – so we can be (unknowingly?) very open with our own information – but often we give it away to companies that are not, in their turn, open with the data that is provided. As Tim Berners-Lee has stated, “”One of the issues of social networking silos is that they have the data and I don’t”. It is possible to paint quite a worrying trend towards control being in the hands of the few:
Google has often been seen as a good guy in this context, but recently a number of actions have indicated a move away from open web principles. We have started to be aware of the way Google collects and uses our data, and there have been some dubious practices around ways that data has been gathered (eg. personal data collected from UK Wifi networks). Google appear to be very eager to get us all using Google+, and we are starting to see ‘social’ search results that appear to be pushing people towards using Google+. I think we should be concerned by the announcement from Google that they are now starting to combine your Google search history with other data they collect through use of their products in order, they say, to deliver improved search results. Do we want Google to do this? Are we happy with our search history being used to push products. Is a ‘personalised’ service worth having if it means companies are collecting and holding all of the data we provide when we browse the web for their own commercial purposes?
It does seem that many of these companies will defend ‘open’ if it is in their interests, but find ways to bypass it when it is not. But maybe if we continue to apply pressure in support of an open approach, by implementing it ourselves and favouring tools and services that implement it, we can tip the balance increasingly towards a genuine open approach that is balanced by safeguards for guaranteeing privacy.
It is worth thinking about some of these issues when we think about our own archival data and whether we are going to take an open approach. It is not just our own individual circumstances, within one repository, that we should think about, but the whole context of what we want the Web to be, because our choices help determine the direction that the Internet goes in.
We do not know how our archival data will be used and we never have. Even when the data was on paper, we couldn’t control use. Fundamentally, we need to see this as a good thing, not a threat, but we need to be aware of the risks. The paradigm has shifted because the data is much much easier to mess with now that it is digital, and, of course, we have digital archives, and we are concerned to protect the integrity of these sources. Providing an API interface seems like a much more explicit invitation to play with the data than simply putting it on the Web. Furthermore, the mindset of the digital generation is entirely different. Cutting and pasting, mashing and inter-linking are all taken for granted and sometimes the idea of the provenance of data sources seems to go out of the window.
This issue of ‘unpredictable use’ is interesting. When the Apple II was launched, Steve Jobs did not know how it would be used – as Zittrain states, it ‘invited people to tinker with it’, and whilst Apple might have had ideas about use, there ideas were not a constraint to reality. Contrast this with the iPhone: it comes out of the box programmed. Quoting Zittrain again: ‘Whereas the world would innovate for the Apple II, only Apple would innovate for the iPhone.’ Zittrain sees this trend towards fixed appliances as pointing to a rather bleak future of ‘sterile appliances tethered to a network of control.’
Maybe the challenge is partly around our understanding of the data we are ‘giving away’, why we are giving it away, and if it’s worth giving away because of what we get in return. Think about the data gathered as we browse the Web – cookies have always had a major role in building up a profile of our Web behaviour – where we go and what we do. Cookies are generally interested in behaviour rather than identity. But still, from 26 May this year, every website operating in the UK will be required to inform its users that they are being tracked with cookies, and to ask users for their consent. This means justifying why cookies are required – it may be for very laudable reasons – logging users’ preferences to help improve their experience, and generally getting a better understanding of how people use the site in order to improve it. It may be in order to target advertising – and you may feel that its hardly a problem if this is adversely affected, but maybe it will be smaller, potentially very useful sites that will suffer if their advertising revenue is affected. Is it a good think that sites will have to justify use of cookies? Is it in our interests? Is this really where the main fight is around protecting your identity? At the same time, the Government is proposing to bring in powers to monitor the websites people are looking at, something which has very profound implications for our privacy.
On the side of the good guys, there are plenty of people out there espousing the importance of an altruistic approach. In The Digital Public Domain: Foundations for an Open Culture the authors argue that the Public Domain — that is, the informational works owned by all of us, be that literature, music, the output of scientific research, educational material or public sector information — is fundamental to a healthy society. Many other publications echo this belief and you can see plenty of evidence of the movement towards open publication. Technology can increasingly help us realise the advantages of an open approach. For example, text mining is something that can potentially bring substantial economic and cultural benefits. It is often associated with biomedical sciences, but it could have great potential across the humanities. A recent JISC report on the Value and Benefits of Text Mining concluded that the current licensing arrangements are a key barrier to unlocking the potential value of text mining to society and enabling researchers to gain maximum benefit from the data. Text mining analyses text using computational methods, and provides the end user with what is most relevant to them. But copyright law works against this principle:
“Current copyright law, however, imposes serious restrictions on text mining, because it involves a range of computerised analytical processes that are not all readily permitted within UK intellectual property law. In order to be ‘mined’, text must be accessed, copied, analysed, annotated and related to existing information and understanding. Even if the user has access rights to the material, making annotated copies can currently be illegal without the permission of the copyright holder.” (JISC report: Value and Benefits of Text Mining)
It is important to think beyond types of data and formats, and engage with the debate about the sort of advances for researchers that we can gain by opening up all types of data; whilst the data may differ, many of the arguments about the benefits of open data apply across the board, in terms of encouraging innovation and the advancement of knowledge.
The battle between open and transparent and the walled garden scenario is played out in many ways. One area is the growth of native apps for mobile devices. It is easy to simply see mobile apps as providing new functionality, and opportunities for innovation, with so many people creating apps for every activity you can think of. But what are the implications of a scenario where you have to enter a ‘silo’ environment in order to do anything, from finding your way to a location to converting measurements from one unit to another, to reading the local news reports? Tim Berners-Lee sees this as one of the main threats to the principle of the Web as a platform with the potential to connect data.
Should we be promoting the open Web? Surely as information professionals we should. This does not mean that there is an imperative to make everything open – we are all aware of the Data Protection Act and there are a whole range of very valid reasons to withhold information. But it is increasingly apparent that we need to be explicit in applying permissions – whether it be explicitly fully open licences, attribution licences or closure periods. Many of the archives described on the Archives Hub have ‘open for consultation’ under Access Conditions. But what does this really mean? What can people really do with the content? Is the content actually ‘open for reuse in any way the end-user deems useful to them’? And specifically, what can they do with digital content, available on the World Wide Web?
We need to be aware of the open data agenda and the threats and opportunities presented to us. We have the same kind of tensions within our own world in terms of what we need to protect, both for preservation reasons and for reasons of IPR and commercial advantage, but we want to make archives as open and available as possible and we need to understand what this means in the context of the digital, online world. The question is, whether we want to encourage innovation, what Zittrain calls a ‘generative’ approach. This means enabling programmers to take hold of what you can provide and working with it, as well as encouraging reuse by end users. But it also means taking a risk with security, because making things open inevitably makes them more open to abuse.
People’s experiences with the Internet are shaped by the devices they use to access it. And, similarly, their experiences of archives are shaped by the ways that we choose to enable access. In the same way that a revolution started when computers were made available that could potentially run software that was not available at the time they were built, so we should think about enabling innovation with our data that we may not envisage at present, not trying to determine user behaviour but relishing the idea of the unknown. This raises the question of whether we facilitate this by simply putting the data out as it is, even if it is somewhat unstructured, making it as open as possible, or whether we should try to clean up data, and make it more rigorous, more consistent and more structured, with the purpose of facilitating flexible use of the data, enabling people to use and present it in other ways. But maybe that is another story…
In a way, the early development of the Internet has been an unexpected journey. Innovation has been encouraged because a group of computer scientists did not want to control or to ensure maximum commercial success. It was an altruistic approach; and it may not have turned out that way. Maybe the PC was an unlikely success story in business, where a stable, supported, predictable solution might have been favoured, where companies did not need skills in-house. Both Microsoft and Apple made their computers’ operating systems open for third-party software development, so even if there was a sense of monopoly, there was still a basic ethos of anyone being able to write for the PC.
Are we still moving down that road where amateur innovation and ‘messing about’ is seen as a positive thing? Or are the problems of security, spam and viruses, along with the power of the big guys, taking us towards something that is far more fixed and controlled?
Last week I attended a meeting at the British Museum to talk with some museum folk about ways forward with Linked Data. It was a follow up to a meeting I organised on Archives and Linked Data, and it was held under the auspices of the CIDOC Documentation Standards Working Group. The group consisted of me, Richard Light (Museum consultant), Rory McIllroy (ULCC), Jeremy Ottevanger (Imperial War Museum), Jonathan Whitson Cloud (British Museum), Julia Stribblehill (British Museum), and briefly able to join us was Pete Johnston (worked on the Locah project and now on the Linking Lives Linked Data project).
It proved to be a very pleasant day, with lots of really useful discussion. We spent some time simply talking about the differences – and similarities – in our perspectives and in our data. One of our aims was to start to create more links and dialogue between our sectors, and in this regard I think that the day was undoubtedly successful.
To start with our conversation ranged around various issues that our domains deal with. For example, we talked a bit about definitions, and how important they are within a museum context. For example, if you think about a collection of coins, defining types is key, and agreeing what those types are and what they should be called could be a very significant job in itself. We were thinking about this in the context of providing authoritative identifiers for these types, so that different data sources can use the same terms. Effectively identifying entities such as names and places are vital for museums, libraries and archives, of course, and then within the archive community we could also provide authoritative identifiers for things like levels of description. Workign together to provide authoritative and persistent URIs for these kinds of things could be really useful for our communities.
We talked about the value of promoting ‘storytelling’ and the limitations that may inhibit a more event-based approach. DBPedia (Wikipedia as Linked Data) may be at the centre of the Linked Data Cloud, but it may not be so useful in this context because it cannot chart data over time. For example, it can give you the population of Berlin, but it cannot give you the changing population over time. We agreed that it is important to have an emphasis on this kind of timeline approach.
We spent a little while looking at the British Museum’s departmental database, which includes some archives, but treats them more as objects (although the series they form a part of is provided, this contextual information is not at the fore – there is not a series description as such). The proposal is to find a way to join this system up with the central archive, maybe through the use of Linked Data.
We touched upon the whole issue of what a ‘collection’ is within the museum context, which is often more about single objects, and reflected on the challenge of how to define a collection, because even something like a cup and saucer could be seen as a collection…or it is one object?…or is a full tea set a collection?
For archivists, quite detailed biographical information is often part of the description of a collection. We do this in order to place the collection within a context. These biographical histories often add significant value to our descriptions, and sometimes the information in them may be taken from the archive collection, so new information may be revealed. Museums don’t tend to provide this kind of detail, and are more likely to reference other sources for the researcher to use to find out about individuals or organisations. In fact, referencing external sources is something archives are doing more frequently, and Linked Data will encourage this kind of approach, and may save us time in duplicating effort creating new biographical entries for the same person. (There is also the move towards creating separate name authorities, but this also brings with it big challenges around sharing data and using the same authorities).
We moved on to talk about Linked Data more specifically, and thought a bit about whether the emphasis should be on discovery or the quality and utility of what you get when you are presented with the results. We generally felt that discovery was key because Linked Data is primarily about linking things together in order to make new discoveries and take new directions in research.
Wellcome Library, London
One of the main aims of the day was to discuss the idea of the use of design patterns to help the cultural heritage community create and use Linked Data. It would facilitate the process of querying different graphs and getting reasonably predictable information back, if we could do things in common where possible. Richard has written up some thoughts about design patterns from a museum perspective and there is a very useful Linked Data Patterns book by Leigh Dodds and Richard Davis. We felt this could form a template for the sort of thing that we want to do. We were well aware that this work would really benefit from a cross-domain approach involving museums, archives, libraries and galleries, and this is what we hope to achieve.
We spoke briefly about the value of something like OpenCalais and wondered whether a cultural heritage version of this kind of extraction tool would be useful. If it was more tailored for our own sectors, it may be more useful in creating authorities, so that we can refer to things in a common way, as a persistent URL would be provided for the people, subjects, concepts, that we need to describe. We considered the scenario that people may go back to writing free text and then intelligent tools will extract concepts for them.
We concluded that it would be worth setting up a Wiki to encourage the community to get involved in exploring the idea of Linked Data Patterns. We thought it would be a good idea to ask people to tell us what they want to know – we need the real life questions and then we can think about how our data can join up to answer those questions. Just a short set of typical real-life questions would enable us to look at ways to link up data that fit a need, because a key question is whether existing practices are a good fit for what researchers really want to know.
We are currently evaluating ICA-AtoM, and it is throwing up some really useful ideas and some quite difficult issues because it supports the creation of name authorities, and it also automatically creates authority records for any creator name and any names within the access points when you upload an archive description.
As far as I am concerned, the idea of name authorities is to create a biographical entry for a person or organisation, something that gives the researcher useful information about the entity, different names they use, significant events in their life, people they know, etc (all set out within the ISAAR(CPF) standard (PDF)). You can then link to the archive collections that relate to them, thus giving the archives more context. You can distinguish between archives that they ‘created’ (were responsible for writing or accumulating), and archives that they are a subject of (where they are referenced – maybe as an access point in the index terms).
The ideal vision is for one name authority record for an entity, and that authority record intellectually brings together the archives relating to the entity, which is a great advantage for researchers. However, this is not practically achievable. Just the creation and effective use of name authorities to bring archives together at any level is quite challenging. For the Hub we have a number of issues….
Often we have more than one archive collection for the same entity (let’s say person, although it could be a corporate body or family). I’ll take Martha Beatrice Webb as an example, because we have 9 collections on the Archives Hub where she is a creator. She’s also topical, as the LSE have just launched a new Digital Library with the Beatrice Webb diaries!
There is nothing wrong with any of these entries. In fact, I pick Beatrice Webb as an example because we do have some really good, detailed biographical history entries for her – exactly what we want in a collection description, so that researcher can get as much useful information as possible. We have always recommended to our contributors that they do provide a biographical history (we know from researchers that this is often useful to them; although conversely it is true to say that some researchers see it as unnecessary).
We have nine collections for Beatrice Webb, and three repositories holding these collections.
If we were to try to create one authority record for these nine collections:
1. Which biographical history would we use? Would we use them all, which means a lot of information and quite a bit of duplication? Would we pick the longest one? What criteria could we use?
2. Two of these collections are attributed to Beatrice and Sydney Webb. Ideally, we would want to link the collections to two authority records – one for Beatrice and one for Sydney, but the biographical history is for both of them, so we would probably end up with an authority record for ‘Beatrice and Sydney Webb’ as an entity.
3. The name of creator is entered differently in the descriptions – ‘Beatrice Webb’ and ‘Webb, Martha Beatrice, 1858-1943, wife of 1st Baron Passfield, social reformer and historian’. This is very typical for the Hub. Sometimes the name of creator is entered simply as forename and surname, but sometimes the same elements as are used for the index term entry are used – sometimes in the same (inverted) order and sometimes not. This makes it harder to automatically create one authority record, because you have to find ways to match the names and confirm they are the same person.
4. Maybe it would be easier to try to create one authority record per repository, so for Beatrice Webb we would have three records, but this would go against the idea of using name authorities to help intellectually bring archives together and still leaves us with some of the same challenges.
5. How would we deal with new descriptions? Could we get contributors to link to the authority records that have been created? Would we ask them to stop creating biographical histories within descriptions?
6. The name as an access point is often even more variable than the name as creator, although it does tend to have more structure. How can we tell that ‘Martha Beatrice Webb’ is the same person as ‘Beatrice Webb’ is the same person as ‘Beatrice Potter Webb’? For this we’ll have to carry out analysis of the data and pattern matching. For some names this isn’t so difficult, such as for Clough Williams-Ellis and Clough Williams Ellis. But what about ‘Edward Coles’ (author of commonplace book c. 1730-40) and ‘Edward Coles fl. 1741’? With archives, there is a good deal of ‘fl’ and ‘c’ due to the relative obscurity of many people within archive collections. If we don’t identify matches, then we will have an authority record for every variation in a name.
7. We will have issues where a biographical history is cross-referenced, as in one example here. It makes perfect sense within the current context, and indeed, it follows the principle of using one biographical history for the same person, but it requires a distinct solution when introducing authority records.
I would be really interested to know what archivists, especially Hub contributors, think about linking to authority files. I am very excited about the potential, and I believe there is so much great information tied up in biographical and administrative history fields that would help to make really useful authority records, but the challenges are pretty substantial. Some questions to consider:
(1) Would you be happy to link to a ‘definitive’ authority record? What would ‘authority’ and ‘definitive’ mean for you?
(2) Would you like to be able to edit the ‘definitive’ record – maybe you have further information to add to it? Would this type of collective authorship work?
(3) Would you rather have one authority record for each repository?
(4) Would you rather have room within an archive description to create a biographical entry that reflected that particular archive?
(5) Would you like to see co-ordination of the creation and use of name authorities? Maybe it’s something The National Archives could lead, following their work in maintaining names through the National Register of Archvies?
I’m sure you can think of other questions to ask, and maybe you have some questions to ask of us about our review? Suffice to say that we have no plans to change our software – this is currently just an assessment, but we are seriously thinking of how we can start to incorporate name authorities into the Archives Hub.
Finally, its worth mentioning that if you are interested in ways to bring biographical histories together, you might like to follow our ‘Linking Lives’ linked data project through the Linking Lives blog, as for this project we are looking at providing an interface that gives then end user something a little like a name authority record, only it will include more external links to other content.