The economist and the wider world: the papers of Lionel Robbins (1898 – 1984) is a project which aims to provide access to the papers of Lionel Robbins at the London School of Economics and Political Science and promote them through a programme of cataloguing, digitisation and publicity. The project has been generously supported by the LSE Annual Fund. The cataloguing of the collection is now complete and the catalogue is accessible via the LSE Library archives catalogue.
Lionel Robbins was closely connected with LSE for over 60 years initially as a student, then as a professor and Chair of Economics, and also through his work for the Library Appeal and on the Court of Governors. The title of the project is ‘The economist and the wider world’ and Lionel Robbins’ papers contain all the economic-related material you might expect in the personal archive of such an important figure to the practice and theory of economics. However ‘the wider world’ of the collection title hints at the wealth of other subjects that are also covered in this collection.
‘The return from the war’, poem by Lionel Robbins, 1918, 1922, ROBBINS/2/4
Robbins’ passion for the arts is well represented throughout his correspondence with friends and family, as well as through his work as a Trustee of the National Gallery and the Royal Opera House. The collection also contains his own artistic endeavors as a young man in the form of poems and short stories. Some of these, such as the poems written on his return from the First World War, are particularly moving. There are some well-known names in the correspondents, such as Henry Moore and Kenneth Clarke, and some infamous, such as Anthony Blunt.
Extract from Bretton Woods diary, 1944, ROBBINS/6/1/2
There are detailed diaries covering the period during and following the Second World War when Lionel Robbins was part of the Economic Section of the War Cabinet sent to the U.S.A. for the post-war economic negotiations. These diaries, including one from the Bretton Woods conference, give a personal account of some defining moments in post-war economic and political history. The diaries from the Hot Spring conference of 1943 and Bretton Woods in 1944 have been digitised. Complementing his professional reports on his war-time work in the U.S.A are the letters he sent home to his wife Iris. He would write to her at least once a week, often once every few days, as well as writing to his children.
The period at LSE known as the Troubles, in the late 1960s, is well documented in the collection. This was a period of student unrest and protest at LSE following controversy over the appointment of a new Director. As a member of the Court of Governors Lionel Robbins held copies of the minutes and papers of meetings that determined how the organisation would respond to student protests. He also collected examples of the student protest publications and press reports on the situation. The LSE Library Appeal which resulted in the successful purchase and renovation of the current LSE library premises was headed by Lionel Robbins. The collection contains minutes and papers relating to this appeal alongside correspondence and examples of the successful marketing campaigns and strategies.
Speeches by Lionel Robbins on higher education, 1963 – 1977 ROBBINS/8/1/3
Throughout his life Lionel continued to write and publish books and articles on economics and the collection contains the finished products as well as drafts, proofs and correspondence with publishers. His work as Chairman of the Financial Times is also documented. Lecture notes, student references, correspondence with students and former students and economics department circulars provide a detailed account of his work teaching at LSE, which he continued on a part-time basis until 1981 – 1982.
Members of the Committee on Higher Education visiting Stanford University, 1962, ROBBINS/13/5
In 1960 Lionel Robbins was invited to head a Committee on Higher Education to review current full-time higher education provision in the UK and advise the Government on long-term development. The report became known as the Robbins Report which essentially aimed to show that higher education could benefit all and its access should be expanded to everyone. This month marks the 50th anniversary of the final submission of the Robbins Report. The official papers for the Report are held at the National Archives however the Lionel Robbins Papers contains correspondence about the Report, as well as subsequent speeches and articles written by Robbins on higher education. To celebrate the 50th anniversary of the Robbins Report LSE has organised a public event ‘Shaping Higher Education Fifty Years After Robbins: what views to the future?’ on Tuesday 22nd October.
Artillery notebook kept by Lionel Robbins, 1916, ROBBINS/2/3
The Lionel Robbins catalogue on the Archives Hub now makes available the variety of subjects covered in the Lionel Robbins papers, and opens the collection up to new researchers.
Kathryn Hannan, Project Archivist
‘The economist and the wider world: the papers of Lionel Robbins (1898 – 1984)’
We have recently been reprocessing the Archives Hub data, transforming it into RDF based Linked Data, and as part of this we have been working on names matching. For Linked Data, creating links to external data sources is key – it is what defines Linked Data and gives the opportunities, potentially, for researchers to explore topics across data sources.
This names matching work has big implications for archives. I have already talked extensively in the Hub Blog about the importance of structured data, which is more effectively machine processable. For archival descriptions, we have a huge opportunity to link to all sorts of useful data sources, and one of the key means to link our data is through personal names. To do this effectively, we need names to be structured, and this is one of the reasons why the Hub practice of structuring names by separating out surname, forename, dates, titles and descriptive information (epithets) is so useful. We do this structuring even though EAD (the recognised XML standard for archives) doesn’t actually allow for it. We took the decision that the advantages would outweigh the disadvantages of a non-standard approach (and we can export the data without this additional markup, so really there is no disadvantage).
We have been working on the matching, using the freely available Open Refine data processing tool with the VIAF reconciliation service developed by Roderick Page. Freely available tools like this are so important for projects like ours, and we’re really grateful that we were able to take advantage of this service.
The matching has generally been very successful. Out of 5,076 names, just over 2,000 were linked from the Hub entry to the VIAF entry, which is a pretty good percentage.
This post provides some perspectives on the nature of the data and the results of the matching work.
Full names and epithets
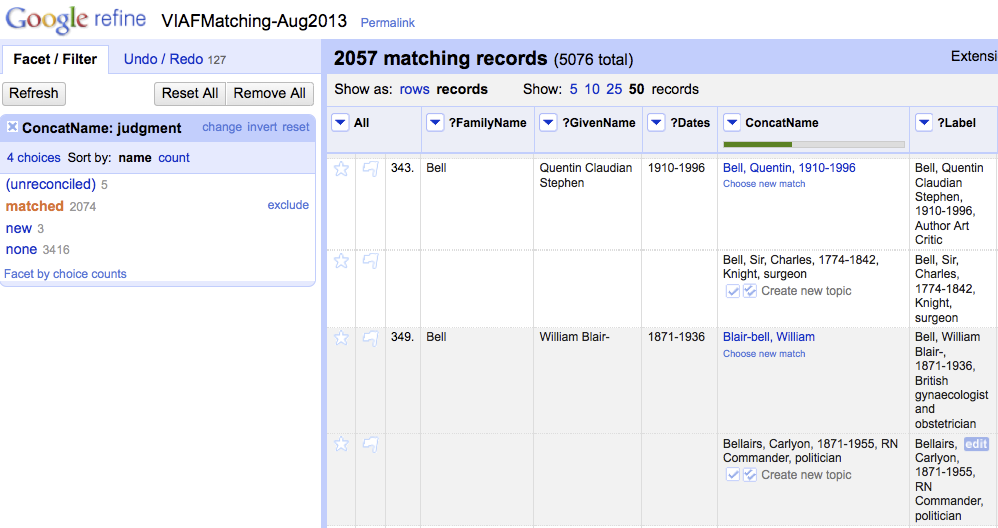
With a name like ‘Bell, Sir Charles, 1774-1842, knight surgeon’, (you can see his entry in our current Linked Data views at http://data.archiveshub.ac.uk/id/person/ncarules/bellsircharles1774-1842knightsurgeon) there is plenty of information – surname, forename, dates and an epithet to help uniquely identify the individual. However, with this name, a match was not found, despite an entry on VIAF: http://viaf.org/viaf/2619993 (which is why you may not yet see the VIAF link on our Linked Data view). Normally, this type of name would yield a match. The reason it didn’t is that the epithet came through in the data we used for matching.
Screenshot of names matching using Open Refine
This highlights an issue with the use of epithets within names. It is encouraged in the NCA Rules, and it does help to uniquely identify an individual, but it introduces an additional element in the string that makes it harder to match the data.
Where our process did not manage to get the family name, forename and dates to match with VIAF, we used the ‘label‘ information that we have in our Linked Data. This label information includes the epithet. For example: Nosek, Václav, 1892-1955, Czechoslovak politician. This doesn’t tend to find a match, because of the epithet. With examples like this we can manually check, and in this case there is a VIAF match (http://viaf.org/viaf/23683886). But manual checking is problematic where you have thousands of names.
In 95% of cases we did manage to omit the epithet. But sometimes the epithet was included because we used the label, as stated, or because the markup on the Archives Hub is not always consistent and sometimes the structured names I referred to above are not present in Hub data because the data has come from other systems. (We may have found a way to remove these stray epithets, but it would have taken a good deal more time and effort to achieve).
Bringing together information on an individual
The reference to Sir Charles Bell came from a collection of “Papers of Sir Charles Bell” (http://archiveshub.ac.uk/data/gb96-ms386). In this description his occupation is “surgeon”. In the VIAF description (http://viaf.org/viaf/2619993) he is described as “Scottish painter, draftsman, and engraver”. Ostensibly this doesn’t look like the same person, but looking down the VIAF description, you can see titles such as “The nervous system of the human body” and other works that are clearly written by a scientist. The linking of our description with the VIAF description brings together Sir Charles Bell scientist and Sir Charles Bell painter, a good illustration of how linking provides a better perspective, as the different data sources effectively become joined up.
Pulling sparse sources together
For Francis Campbell Ross Douglas VIAF only has the surname and forename (http://viaf.org/viaf/211588539/), although if you look at the source records you also find “Douglas Of Barloch” to help with identification. This is an example where the Hub record has much more information (http://archiveshub.ac.uk/data/gb097-douglasofbarloch), and therefore creating the link is particularly useful. It shows how archives can help contribute to our knowledge of individuals within the Linked Data space, as they often have little known information, gleaned from the archives themselves.
<persname>
<surname>Bell</surname>,
<forename>William Blair-</forename>
(<dates>1871-1936</dates>)
<epithet>British gynaecologist and obstetrician</epithet>
</persname>
This is an example of the application of the NCA Rules, which insist on the last entry element as the main element, so it means the element ‘Bell’ is marked up as the surname. In fact, the matching still works because, with all the elements there, the reconciliation service can still find the right person (http://viaf.org/viaf/14336292/). However, it still concerns me that within the archive sector we have a rule that separates out the surname in this way, as it makes the name non-standard compared to other data sources. It is interesting to note that the name is generally given as Blair-Bell, but the Library of Congress enters the name as Bell, W. Blair (William Blair), 1871-1936 (http://id.loc.gov/authorities/names/no92003069.html), so there is an inconsistency in how different services deal with hyphenated and compound surnames. It could be argued that once we have a match, the different formats matter less, as they are simply alternatives that can be used to identify the individual.
Hub names without structured markup
As stated, in the Hub names are marked up by surname, forename, dates, epithet, titles. However, there are still some entries that are not marked up like this, usually because they were created in proprietary software and exported. An example is Carlyon Bellairs (referenced in http://archiveshub.ac.uk/data/gb097-assoc17). The name is marked up as:
You can see the XML mark up at http://archiveshub.ac.uk/data/gb097-assoc17.xml?hub. We have been working on a script to markup the component parts of these names in the Hub, and we have been able to implement it successfully for several institutions. But it is not easy to do this with non-standard names (i.e. not in the surname, forename, dates, epithet format). We do have some instances of names such as the British Prime Minister, James Callaghan, or the author Rudyard Kipling, that are not yet marked up in this way. These individuals should be easy to match, but without the structure within the index term, it is harder for us to ensure that we can get just the name and dates from an unstructured name to match with VIAF.
It is also impossible to implement structured markup on a name where there is a compound surname entered according to NCA Rules – we simply cannot mark these names up correctly because we have no way of knowing whether part of the forename is actually part of the surname. For example, if we have the name “George, David Lloyd” we can’t write a script that can transform this into “Lloyd George, David” because most of the time a name like this will be two forenames and one surname.
The importance of life dates and the use of ‘Is Like’
If we don’t have life dates, it makes matching with certainty almost impossible. Of course, cataloguers can’t always find life dates for a person, but it is worth stressing that the need for life dates has become even more important in recent years, now we have the potential to process data in so many ways. An example is at http://archiveshub.ac.uk/data/gb532-bel – Joyce Margaret Bellamy, a Senior Research Officer at the University of Hull. As we don’t have a birth date, we did not get a match with her VIAF entry at http://viaf.org/viaf/94773174. If we have this kind of entry, without life dates, we could potentially decide to use a different status from an exact match (which usually uses the owl:sameAs property), and for example, we could use the ‘isLike‘ property from the Umbel vocabulary instead. This would be useful where we believe the two names to be referring to the same person, but this type of matching has to be done manually (although potentially we could run something where a name match without a date match was always an ‘isLike’). In the process of checking the 2,000 matches for our data we did enter a number of matches manually, and the whole process of checking took around 5 hours. Not too bad for 2,000 names, and with some time also given to thinking about the results (and making notes for this post!). But if we were to work on the entire Archives Hub data, we couldn’t undertake to do this kind of manual work unless we just had a few thousand ‘not sure’ names that we might be prepared to work through.
Matches without life dates
We do get matches to VIAF where we don’t have dates. We got a match for ‘Hilda Chamberlain’ with VIAF entry http://viaf.org/viaf/286538995/. This seems to be correct, as she is the daughter of Joseph Chamberlain, so we kept the match. But we had to check it manually. Another example is Hercules Ross – http://viaf.org/viaf/21209582/ – matched to the name in description http://archiveshub.ac.uk/data/gb254-ms17. But in this case we don’t really have enough evidence to identify the individual, even though the surname and forename match. The source of the name on VIAF is “Guild, J. Proceedings before the sheriff depute of Forfarshire … against Hercules Ross and David Scott, Esquires, 1809”, but the title deeds described in the Archives Hub cover the sixteenth to the nineteenth century!
With a name like Gustav Wilhelm Wolff (http://archiveshub.ac.uk/data/gb738-ms174), again we only have the name and not the life dates. The match given is for someone born in 1811 (http://viaf.org/viaf/8221966/), and the papers relate to Victorian Jews in Britain. This makes the match likely, but we can’t be sure without dates, so we could potentially enter an ‘is like’, to imply that they are the same person, but that we cannot be certain.
Floruit!
We had a number of individuals without known life dates where the cataloguer used a ‘floruit’, e.g. Sharman W. fl 1884 (Secretary of National Association for the Repeal of the Blasphemy Laws). This sort of entry, whilst it may be the total of the information the archivist has, is difficult to use to identify someone in order to match them. However, the majority of individuals with this kind of entry are not likely to be on VIAF simply because a floruit normally indicates someone for whom life dates cannot be found. It would be interesting to consider a tool that matches floruit dates to possible life dates (e.g. fl 1900-1910 would match to life dates of 1880-1945) but I’m not sure how much it would add much to the accuracy of a match.
Alternative names
The reconciliation service often works where VIAF provides names that are not ‘the same’ as our name. So, for example, the Hub data may have the name ‘Orton, John Kingsley, 1933-1967’. This was linked to Joe Orton (http://viaf.org/viaf/22163951), and within the VIAF data you can see that Joe Orton is also known as John Kingsley Orton.
Fame does not always give identity
Sometimes very famous people prove problematic, and an example is someone like Queen Victoria, because the name doesn’t include a surname and people tend to enter it in various ways. There were a few examples of this type of thing in our data, although most royal names matched with no problem. It always helps if it is easier to structure a name, but kings, queens, popes, etc. are non-standard.
Some Hub names are quite fulsome, such as “Edward Albert Christian George Andrew Patrick David, 1894-1972, Duke of Windsor, formerly Edward VIII, King of Great Britain and Ireland”. This should link to VIAF http://viaf.org/viaf/47553571 (Windsor, Edward, Duke of, 1894-1972), but the match was not given due to the lack of similarity.
Accented characters may cause problems
We didn’t get a match on Jeremy Bentham, despite having the full structured name, but this may be because the VIAF match has an accent: http://viaf.org/viaf/59078842/. We could possibly have stripped out accents in our data, but in this case the accent was in the VIAF data. I only found one example where this was a problem, but clearly many names do contain accented characters.
Matches sometimes surprise…
A particularly nice match came up for “Mary-Teresa Craigie Pearl 1867-1906 novelist, dramatist and journalist as John Oliver Hobbes nee Richards”. A complex string, but the algorithm matched the basic elements that we provided (Cragie Pearl, Mary-Teresa, 1867-1906) to the name ‘John Oliver Hobbes’ on VIAF.
Mismatches
Leonard Wright, a Leiutenant (http://archiveshub.ac.uk/data/gb99-kclmawrightlw) matched to Clara Colby (http://viaf.org/viaf/63445035/), also known as Mrs Leonard Wright Colby. Here is an example of an incorrect match due to the same name, but in VIAF the person is a ‘Mrs’ (due to the old fashioned practice of using the husband’s name). The reason for the match seems to be that the name on the Hub includes a floruit (Leonard Wright, fl 1916) which matches the death date of Mrs Leonard Wright (Leonard Wright, Mrs, d 1916).
On the Hub we have an example of an archive that includes “a letter from Charlotte Bronte to Elizabeth Firth”, and the name is simply given as Elizabeth Firth in the index. The match to VIAF was for Mrs J.F.B Firth (http://viaf.org/viaf/71217693/). In this case the match is wrong, as we can see from the Hub description that Elizabeth Firth is actually “Mrs. James Clarke Franks”, and the dates within the additional information don’t seem to match.
There were very few examples of this type of mismatch, but it shows why well structured data, with life dates, helps to minimize any incorrect matches.
Incorrect Suggestions
In the names that did not find definite matches (i.e outside of the 2,000 matches), there were a few examples of suggested names that did not bear much resemblance to the text provided. One example of this was for “Bell, Vanessa, 1879-1961”. The suggestions for ‘sameAs’ names to link to this individual were Stephen, Julia Prinsep British model, 1846-1895; Woolf, Virginia, 1882-1941; Stephen, Leslie, 1832-1904. In fact, VIAF does have Vanessa Bell (http://viaf.org/viaf/7399364), and the link appears to be that the names are related within VIAF (i.e. VIAF establishes that there is an association between these people). However, these were only suggestions, they were not given as matches.
Conclusions
If there was no match given, but we can see that the name and dates have gone to VIAF, then we would assume there simply is no match and VIAF does not have anyone with our surname, forename and dates. But if we can see an epithet has also been included in the data we have provided, then there may well be a match because the epithet can be problematic for finding a match. Our intention would be to continue to improve our filtering to try to remove all epithets, but if the names are not properly structured this can be difficult.
When actually checking data like this, one thing that really comes to the fore is the risk of a ‘sameAs’ where the individual is not the same, and this is a particular risk where you are dealing with a notorious character – maybe a criminal. A number of war criminals are referred to in the Hub data, and it would be very unwise to link these to the wrong person – this is why it is best to only provide matches where the life dates match, but it is not impossible to have the same name with the same life dates of course.
In conclusion I would say that wherever our names have life dates, and these can be successfully carried over to the matching process, the likelihood of a correct match is 99%, but there is always a risk of a mismatch. Clearly the main problem would lie with two people sharing a name and life dates, and the chances of this happening will increase if we only have birth or death date.
The season of summer often brings hopes and plans for holidays and this month we’re looking at the wider theme of travel.
The hundreds of collections relating to travel featured in the Archives Hub shed light on multiple aspects of travel, from royalty to the working classes, and encompassing touring, business, exploration and research, the work of missionaries and nomadic cultures.
“The world is a book and those who do not travel read only one page” – St. Augustine.
Travel diaries
There are a number of travel diaries recording impressions of, and experiences in, the UK, Europe and beyond from a bygone era. ‘Grand tours’, leisurely and often luxurious, were the domain of the more privileged classes, where sometimes business and pleasure were combined. In more recent times, the pursuit of knowledge, education and ideas has motivated similar educational journeys.
Watercolour paintings and photographs of Canada by an unidentified artist, 1884.
The paintings and photographs are held within a large album, providing a record of a journey by unidentified travellers to Canada from Liverpool in 1884. http://archiveshub.ac.uk/data/gb159-ms57
Nassau William Senior Papers, 1830-1864.
Copies of journals kept by Nassau William Senior recording his visits to France, Germany, Austria, Italy, Ireland, Greece, Algeria and Egypt between 1850 and 1862. http://archiveshub.ac.uk/data/gb222-bmssnws
Papers of Sir Leonard David Gammans and Lady Ann Muriel Gammans, ne Paul, 1916-1971.
Diaries, notebooks, etc. of Leonard David Gammans, 1916-1956; diaries. etc. of Ann Muriel Gammans, 1918-1970; tourist brochures and other printed material concerning South Africa, [1965-1971]. http://archiveshub.ac.uk/data/gb161-mss.brit.emp.s.506
J.R.T. Pollard Papers, 1930-1999.
The collection consists of diaries and papers of J.R.T. Pollard. The diaries include details of the author’s extensive travel, particularly in Europe and observations regarding his years of army service in Africa (1941-1945). http://archiveshub.ac.uk/data/gb222-bmssjpol
Manuscript Itinerary of Henry III of England.
Not quite a diary, but of special note, is the late 19th Century Manuscript itinerary showing the geographical whereabouts of Henry III, where known, for all dates from 1216 to 1272. http://archiveshub.ac.uk/data/gb133-engms123
Business and work-related travel
Collections:
Records of the United Commercial Travellers’ Association (Nottingham Branch), 1908-1975.
The collection comprises accounts from 1932-1967, Committee minutes from 1908-1967 and registers from 1920-1975. http://archiveshub.ac.uk/data/gb159-ct
Household book of James Sharp, Archbishop of St Andrews, 1663-1666.
Household account book of James Sharp, archbishop of St Andrews, kept by his secretary George Martin of Claremont, including details of journeys to Edinburgh and London. http://archiveshub.ac.uk/data/gb227-msbx5395.s4m2
Johan Hjort collection, 1912.
The collection comprises of correspondence by Hjort to polar explorer William Speirs Bruce (leader of the Scottish National Antarctic Expedition, 1902-1904). http://archiveshub.ac.uk/data/gb15-johanhjort
Michael William Leonard Tutton: Natural History Diary, 1930-1932.
Natural history diary kept while Tutton was a King’s Scholar at Eton, which was awarded the Natural History Prize, 1930-1931. The diary contains notes on occurrences of insects, especially butterflies and moths, and occasionally birds and mammals. http://archiveshub.ac.uk/data/gb12-ms.add.8769
Henry Seebohm: Ornithological Notebook.
Unfinished notes of visits to Glossop, Worksop, Ashopton and other places in Derbyshire; to the Farne Islands and Coquet Islands, Northumberland; to Flamborough Head, Yorkshire; and to Asia Minor (Constantinople and Smyrna) in 1872. The notebook also includes some watercolour sketches. http://archiveshub.ac.uk/data/gb12-ms.add.8794
The Gypsy Collections, c.1860-1998.
The collection consists of two separately-catalogued but interlinked parts, the Gypsy Lore Society Archive (GLS) and the Scott Macfie Gypsy Collection (SMGC). https://archiveshub.jisc.ac.uk/data/gb141-gls%26gb141smgc
Letters of Jeanie Robertson, 1954-1956.
The Scottish traditional folk singer Jeanie Robertson is regarded as a seminal figure in the music culture of Scotland’s travelling people. The collection includes letters from Robertson to the poet Hamish Henderson (1919-2002). http://archiveshub.ac.uk/data/gb237-coll-725
Miscellaneous and related information
The Records of the Traveller’s Aid Society, 1885-1939.
The Travellers’ Aid Society was initiated in 1885 by the Young Women’s Christian Association to aid female passengers arriving at ports and railway stations, where they were met by accredited station workers who reported to the Travellers Aid Society Committee. http://archiveshub.ac.uk/data/gb106-4/tas
What are the chief weapons we need to use to improve the user experience?
At ELAG 2013 I gave a presentation with a colleague from The University of Amsterdam, Lukas Koster. We wanted to do something entertaining, but with a worthwhile message that we both feel strongly about. We believe that more needs to be done to integrate resources and provide them to researchers in a way that suits end-user needs. We gave a presentation where we urged our colleagues to ‘mind the gap’ between the perspective of the information professional – their jargon and their complicated systems, which often fail to link resources adequately – and the researcher, who wants an integrated approach, language that is not a barrier to use and expects the power of the Web to be used within a library context, just as they might when looking for music online.
A researcher tries to make sense of the library systems
Our presentation included two sketches: one in a music shop, where a punter (the ‘seeker’) expects the shop owner (the ‘pusher’) to know who else bought this music and what they thought of if; and one in a library, where the seeker wants an overview of everything available, and they want to look at research data and other resources without struggling with different catalogue systems and terminology.
In our presentation we referred to the ‘seeker’ wanting a discipline-focussed approach (not format based), and access regardless of location. I highlighted one of the problems with searching by showing examples of search terms used on the Archives Hub where the researchers were confused by the results. The terms researchers use don’t always fit into our approach, using controlled vocabularies. We talked about the importance of connections between information. Our profession is making headway here, but there is a long way to go before researchers can really pull things together across different systems.
I spoke about the danger of making assumptions about our users and showed some examples of the Archives Hub survey results. Researchers don’t always come to our websites knowing what they are or what they want; they don’t necessarily have the same understanding of ‘archives’ as we do. Lukas expanded more on our musical theme. We can learn from some of the initiatives in this area – such as the ability people have to explore the musical world in so many different ways though things like MusicBrainz. Lukas also showed examples of researcher interfaces, looking to pull things together for the end user. Isn’t the idea of giving the researcher the ability to manage all of their research in this way something libraries should be spearheading?
A librarian contemplates the end of the index card…
We concluded that the vision of integrated, interconnected data is not easy. As information professionals we may have to move out of our comfort zones. But we don’t have any choice unless we want to be sidelined. This means that we need to change our mindsets (we talked about a ‘librarian lobe’!) and we need to actually think about whether it is us that needs to learn information literacy because we need to learn to think more like the end user!
The librarian has a frustrating time with a researcher who only wants one chapter!
A HEFCE study from 2010 states that “96% of students use the internet as a source of information” (1). This makes me wonder about the 4% that don’t; it’s not an insignificant number. The same study found that “69% of students use the internet daily as part of their studies”, so 31% don’t use it on a daily basis (which I take to mean ‘very frequently’).
There have been many reports on the subject of technology and its impact on learning, teaching and education. This HEFCE/NUS study is useful because it concentrates on surveying students rather than teachers or information professionals. One of the key findings is that it is important to think about the “effective use of technology” and “not just technology for technology’s sake”. Many students still find conventional methods of teaching superior (a finding that has come up in other studies), and students prefer a choice in how they learn. However, the potential for use of ICT is clear, and the need to engage with it is clear, so it is worrying that students believe that a significant number of staff “lack even the most rudimentary IT skills”. It is hardy surprising that the experiences of students vary considerably when they are partly dependent upon the skills and understanding of their teachers, and whether teachers use technology appropriately and effectively.
At the recent ELAG conference I gave a joint presentation with Lukas Koster, a colleague from the University of Amsterdam, in which we talked about (and acted out via two short sketches) the gap between researchers’ needs and what information professionals provide. Thinking simply about something as seemingly obvious as the understanding and use of
Random selection of interface terminology from archives sites.
the term ‘archives’ is a good case in point. Should we ensure that students understand the different definitions of archives? The distinction between archives that are collections with a common provenance and archives that are artificial collections? The different characters of archives that are datasets, generally used by social scientists? The “abuse” of the term archives for pretty much anything that is stored in any kind of longer-term way? Should users understand archival arrangement and how to drill down into collections? Should they understand ‘fonds’, ‘manuscripts’, ‘levels’, ‘parent collection’? Or is it that we should think more about how to translate these things into everyday language and simple design, and how to work things like archival hierarchy into easy-to-use interfaces? I think we should take the opportunities that technology provides to find ways to present information in such a way that we facilitate the user experience. But if students are reporting a lack of basic ICT skills amongst teachers, you have to wonder whether this is a problem within the archive and library sector as well. Do information professionals have appropriate ICT skills fit for ensuring that we can tailor our services to meet the needs of the technically savvy user?
Should we be teaching information literacy to students? One of the problems with this idea is that they tend to think they are already pretty literate in terms of use of the internet. In the HEFCE report, a survey of 213 FE students found that 88% felt they were effective online researchers and the majority said they were self-taught. They would not be likely to attend training on how to use the internet. And there is a question over whether they need to be taught how to use it in the ‘right’ way, or whether information professionals should, in fact, work with the reality of how it is being used (even if it is deemed to be ‘wrong’ in some way). Students are clear that they do want training “around how to effectively research and reference reliable online resources”, and maybe this is what we should be concentrating on (although it might be worth considering what ‘effective use of the internet’ and ‘effective research using the internet’ actually mean). Maybe this distinction highlights the problem with how to measure effective use of the internet, and how to define online or discovery skills.
A British Library survey from 2010 found that “only a small proportion [of students] …are using technology such as virtual-research environments, social bookmarking, data and text mining, wikis, blogs and RSS-feed alerts in their work.” This is despite the fact that many respondents in the survey said they found such tools valuable. This study also showed that students turn to their peers or supervisors rather than library staff for help.
Part of the problem may be that the vast majority of users use the internet for leisure purposes as well as work or study, so the boundaries can become blurred, and they may feel that they are adept users without distinguishing between different types of use. They feel that they are ‘fine with the technology’, although I wonder if that could be because they spend hours playing World of Warcraft, or use Facebook or Twitter every day, or regularly download music and watch YouTube. Does that mean they will use technology in an effective way as part of their studies? The trouble is that if someone believes that they are adept at searching, they may not go that extra mile to reflect on what they are doing and how effective it really is. Do we need to adjust our ways of thinking to make our resources more user-friendly to people coming from this kind of ‘I know what I’m doing’ mindset, or do we have to disabuse them of this idea and re-train them (or exhort them to read help pages for example…which seems like a fruitless mission)? Certainly students have shown some concern over “surface learning” (skim reading, learning only the minimum, and not getting a broader understanding of issues), so there is some recognition of an issue here, and the tendency to take a superficial approach might be reinforced if we shy away from providing more sophisticated tools and interfaces.
The British Library report on the Information Behaviour of the Researcher of the Future reinforces the idea that there is a gulf between students’ assumptions regarding their ICT skills versus the reality, which reveals a real lack of understanding. It also found a significant lack of training in discovery and use of tools for postgraduate students. Studies like this can help us think about how to design our websites, and provide tools and services to help researchers using archives. We have the challenges of how to make archives more accessible and easy to discover as well as thinking about how to help students use and interpret them effectively: “The college students of the open source, open content era will distinguish themselves from their peers and competitors, not by the information they know, but by how well they convert that knowledge to wisdom, slowly and deeply internalized.” (Sheila Stearns, “Literacy in the University of 2025: Still A Great Thing‟, from The Future of Higher Education , ed. by Gary Olson & John W Presley, (Boulder: Paradigm Publishers, 2009) pp. 98-99).
What are the Solutions?
We should make user testing more integral to the development of our interfaces. It requires resource, but for the Archives Hub we found that even carrying out 10 one-hour interviews with students and academics helped us to understand where we were making assumptions and how we could make small modifications that would improve our site. And our annual online survey continues to provide really useful feedback which we use to adjust our interface design, navigation and terminology. We can understand more about our users, and sometimes our assumptions about them are challenged.
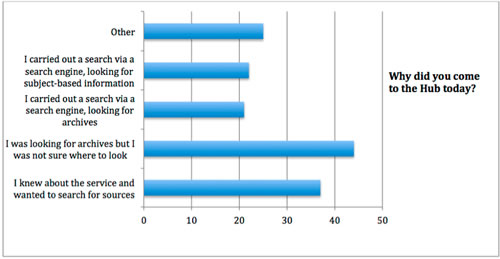
Archives Hub survey 2013: Why did you come to the Hub today?
User groups for commercial software providers can petition to ensure that out-of-the-box solutions also meet users’ needs and take account of the latest research and understanding of users’ experiences, expectations and preferences in terms of what we provide for them. This may be a harder call, because vendors are not necessarily flexible and agile; they may not be willing to make radical changes unless they see a strong business case (i.e. income may be the strongest factor).
We can build a picture of our users via our statistics. We can look at how users came into the site, the landing pages, where they went from there, which pages are most/least popular, how long they spent on individual pages, etc. This can offer real insights into user behaviour. I think a few training sessions on using Google Analytics on archive sites could come in handy!
We can carry out testing to find out how well sites rank on search engines, and assess the sort of experience users get when they come into a specialist site from a general search engine. What is the text a Google search shows when it finds one of your collections? What do people get to when they click on that link? Is it clear where they are and what they can do when they get to your site?
* * *
This is the only generation where the teachers and information professionals have grown up in a pre-digital world, and the students (unless they are mature students) are digital natives. Of course, we can’t just sit back and wait a generation for the teachers and information professionals to become more digitally minded! But it is interesting to wonder whether in 25 years time there will be much more consensus in approaches to and uses of ICT, or whether the same issues will be around.
Nigel Shadbolt has described the Web as “one of the most disruptive innovations we have ever witnessed” and at present we really seem to be struggling to find out how best to use it (and not use it), how and when to train people to use it and how and when to integrate it into teaching, learning and research in an effective way.
It seems to me that there are so many narratives and assessments at present – studies and reports that seem to run the gamut of positive to negative. Is technology isolating or socialising? Are social networks making learning more superficial or enabling richer discussion and analysis? Is open access democratising or income-reducing? Is the high cost of technology encouraging elitism in education? Does the fact that information is so easily accessible mean that researchers are less bothered about working to find new sources of information? With all these types of debates there is probably no clear answer, but let us hope we are moving forward in understanding and in our appreciation of what the Web can do to both enhance and transform learning, teaching and research.
The 2013 Eduserv Symposium, was held in the impressive (and very much ‘keep in with the old’) surroundings of One Great George Street in Westminster, the home of the Institute of Civil Engineers.
‘In with the New’ covered new skills sets, new modes of engagement and new ways of working. With such a wide topic area, the conference took quite a broad-brush approach. Andy Powell of Eduserv introduced the day and talked about dealing with change, change that may be imposed upon us from the outside, as well as being driven internally.
David Cotterill from the Government Digital Service gave the opening keynote, which is what I want to focus on here. He said his talk was about ‘my exciting life as a civil servant’….the audience weren’t convinced about this at the outset, but maybe for those interested in open data, there was some shift of opinion by the end!
He talked about the old consensus, which was built around long-term contracts for IT in government; contracts that were consistently awarded to a limited number of suppliers and not to smaller and more innovative suppliers. IT was not defined as a core function, so out-sourcing was considered appropriate. But in the 21st century things have changed. There is recognition that IT covers very diverse areas. For Government (and for many other organisations), it covers digital public services, mission IT systems (i.e. more niche or specialised systems for government departments), desktop, infrastructure, connectivity, etc. (the more general IT), and, within government, there are also ‘shared services’ (such as for financial systems). David talked about the need to structure mission IT systems and digital public services so that they can run on different desktops or infrastructures and not be tied down (as often used to be the case).
David went on to argue that the Government really has taken up the open agenda, and showed some quotes: “The latest step is the publications of this report on open standards. And once again the government has got it right.” (Wall Street Journal). He argued that in order to have flexibility to progress, to upgrade, to move forwards, you need open and standards based systems. You also need to look at specific needs in specific areas and not think of IT as some kind of monolithic thing.
It was surprising to hear him say that “this is a great time to be a supplier”, but he said that many of the current deals within government come to an end over the next few years, so there is opportunity for new suppliers and creating a more diverse set-up.
What is 21st century government about? David said it’s about things like www.gov.uk/, built using a platform approach (rather than a CMS) which allows the Government Digital Service (GDS) to build products onto it that meet user needs; products that enable the government to engage with citizens. David gave a sense of how this approach is working across UK government, with multi-disciplinary teams including developers, designers, product and service managers, policy, communications, etc.
His core message was to start with the user need. Of course, this is something that we can all agree with, although whether it always happens in reality is debatable, even if it is the intention. We need to shape things in terms of user requirements right from the start, and not bring it in once all the policy, requirements and development work is done. We should think about capturing requirements and developing alpha and then beta versions before going live. This may mean that what is initially developed is chucked out after the alpha stage, because it doesn’t meet needs, and then there is a need to start again. I think one of the problems with this approach is that funders do not necessarily facilitate it. How easy would it be to get funding for a project where the iterative process may go on for quite some time, and there is a risk of starting again several times in order to get it right? A further difficulty with this from a funding point of view is that it is much harder to specify what you are going to end up with, because you necessarily need to keep an open mind; you’ll end up (hopefully) with what users want, but it might be different to what was envisaged and you’ll only know after the testing and refining process.
It makes we think about archival software systems, for example. Surely you should put the user needs at the heart of the development of your system? Ideally you would start out by gathering user requirements for a system, maybe looking at other research done in this area. You’d end up with a specification, listing priorities for your system. Most archives can’t then build it themselves, so they would go out and look at what meets these needs. But would it be possible to test a system out with users, to see if it really does fulfill their needs, and if it doesn’t go back and try something else? The problem here is that if you are buying a system, its hard to apply an iterative approach. However, it may be possible to move to a more user-centered approach. You should have clear evidence that the system does meet key user needs, and, in the absence of an ability to chop and change, you should ensure that the system does not tie you down and that it provides the flexibility to build and modify, so that changing priorities can be met.
It’s good to see Government leading the way. David showed previews of some services that are being developed, working towards a more transparent approach to things like transactional services and he highlighted a government manual about building services that people want to use. There is now a ‘Standards Hub‘, to promote open standards and also to encourage wider participation in solving data challenges. It is amazing to see Government code on GitHub. Somehow that really brought home to me home how different things are now to 10-15 years ago. David, as well as other speakers at the conference, believes that open standards encourage a more efficient approach, so it becomes a cost-saving venture as well as encouraging public engagement and transparency.
This post picks out some highlights from a report from Ithaka S+R, “Supporting the Changing Research Practices of Historians” by Roger C Schonfeld and Jennifer Rutner (December 2012). It concentrates on findings that are of particular relevance for archivists and for discovery. The report is recommended reading. It is a US study, but clearly there are strong similarities with other countries.
The report finds that underlying research methods are still broadly as they were but practices have changed considerably: “Based on interviews with dozens of historians, librarians, archivists, and other support services providers, this project has found that the underlying research methods of many historians remain fairly recognizable even with the introduction of new tools and technologies, but the day to day research practices of all historians have changed fundamentally.”
It goes on to summarise the improvements that archives might make to meet changing needs, none of which are unexpected: “For archives, we recommend ongoing improvements to access through improved finding aids, digitization, and discovery tool integration, as well as expanded opportunities for archivists to help historians interpret collections, to build connections among users, and to instruct PhD students in the use of archives.”
It is very encouraging to see the positive comments about researchers’ interactions with archivists: “Having a meeting with the archivist and librarian is really fantastic, because they help you understand what is in the archive, and what you might be able to use.” It is clear from the study that archivists have a vital role to play as key collaborators and colleagues of historians, and their value is clear: “Archivists are often able to hone and direct an inquiry, bringing to light items and collections that the researcher may have been unaware of.”
The study does highlight the changing nature of interactions with archival material, as a result of the use of digital cameras in particular, which enables the analytical work to take place elsewhere. It is generally felt to be a convenient and time-saving option, enabling long-term interaction with resources outside of the reading room. This development is actually described as “the single most significant shift in research practices among historians.” It raises questions about whether the role of the archivist changes when the analytical work is displaced from the archive, as archivists may have less opportunity for intellectual engagement with researchers. The study does highlight a possible issue with digital copies, namely the separation of metadata from content, where the researcher has hundreds of images and needs to organise them constructively, and it also found that scholars are struggling to work with digitised non-textual content effectively.
The ability to find time for research trips was a primary challenge for many researchers. “Interviewees repeatedly emphasized that the amount of time they are able to spend in the archives shapes the nature of the interaction with the sources significantly.” Because most struggle to find time for research trips, digitised sources are hugely beneficial.
The study found that digitised finding aids help researchers to “travel more strategically”. It suggests that high-quality finding aids may become more important as researchers move more towards photographic visits to archives, rather than serendipitous visits. This connection is something I have not thought about before, and I would be very interested to hear what archivists think about this idea.
Of major relevance for a service like the Archives Hub is the conclusion about finding aids:
“The use of online finding aids greatly facilitates, and sometimes displaces, these visits. If a “good” finding aid is readily available online, this might make a scouting visit unnecessary, depending on the importance of the archive to the research project. In some cases, researchers were able to rule out a visit to an archive based on the online finding aids, and re-purpose funds and effort to tracking down other sources for the project.”
This study is a clear endorsement for our belief (which, I should say, is also backed up by our own researcher surveys) that finding aids play a role not only in identifying and prioritising sources, but also in providing enough information in themselves to make a visit unnecessary. As well as this, they may have a kind of positive negative effect: the researcher knows that materials can be ruled out. The study strongly emphasised the need for “searchable databases” and “centralized searching” and participants talked about the problem with locating each collection independently, especially across the diverse types of archive repository: “The process of identifying archives – in some cases small, local archives or international archives – can present an amazing challenge to researchers.” Clearly comprehensive cross-searching search tools are a huge boon to researchers.
In terms of discovery, Google is clearly a major tool and there was a feeling that it was the most comprehensive discovery tool, as well as being convenient and easy to use. It is often used at the start of a searching process.: “Generally, historians discover finding aids through Google searches and archive websites.” There is a clear demand for more descriptions online: “The general consensus among interviewees was that more online finding aids would greatly benefit their research, and that archives should continue to make efforts to make these accessible online. Continued and expanded efforts to develop finding aids more efficiently and to make them available digitally would seem to support the needs of historians for improved access.”
In terms of PhD students (and maybe others who are inexperienced researchers), the study found issues with the use of archives and other sources:
“Interviews with PhD candidates indicated that there is often little support for them in learning about new research methods or practices, either in their department or elsewhere at their institution, of which they are aware. While the subject matter treated by historians continues to diversify dramatically, new methodologies develop, and research practices change rapidly, it is clearly critically important that students have a grounding in the methods and practices of the field.” The Archives Hub has recently produced a brief Guide to Using Archives for the Inexperienced, and discussions on the archives email list showed just how much this is an important topic for archivists and how there was a general consensus that PhD students need more training on research methodologies.
Summing up, the report makes six recommendations specifically for Archives:
1. More online finding aids
2. More digitisation
3. Discovery tools that promote cross-searching, crossing institutional boundaries and encompassing small and local record offices
4. Adequate resources for ensuring the expertise of the archivist continues to be available, enabling archivists to be active interpreters of the collections
5. Adapting to and facilitating the use of digital cameras and scanners in reading rooms
6. Training PhD students in the use of archives
There is a great deal more of interest and relevance in the report around searching, Google Scholar, the use of the academic library, organising and managing research, citation management and digital research methods. It is very well worth reading.
In the 1870s a young man from a small town in New York decided to organise the world’s knowledge. Well, at least the world’s knowledge in book form. The now ubiquitous Dewey Decimal system divides knowledge decimally, as Dewey loved the decimal system. So, there are ten top-level classes with ten first-level sub-divisions (and so on). It’s a curious arrangement. Eight of the nine major divisions for religion are given over to Christianity. Dewey relegates Buddhism right down the ranks of its hierarchy, as a ‘religion of Indian origin’. It gives an entire category over to ‘Paranormal Phenomena’, and 999 is, rather satisfyingly, ‘extraterrestrial worlds’ (under 990, ‘General history of other areas’). When computing came along, there was no room for it left in the 600’s – Technology and Applied Sciences – so it went under the 000’s, which was originally for ‘generalities’.
“And there’s the weakness and the greatness of Dewey’s system. The…system lets patrons stroll through the collected works of What We Know – our collective memory palace – but the price for ordering knowledge in the physical world is having to make either-or decisions…The library’s geography of knowledge can have one shape but no other.” (Everything is Miscellaneous, David Weinberger)
The world of Dewey classification doesn’t reflect the way we see the world now because the shape of knowledge is fluid and ever-changing, and even then there were many who disputed his arangement. But it seems that for now we’re stuck with the basics of the Dewey system because the implications of changing it would be massive – libraries the world over have been physically ordered based on Dewey, and long decimal numbers have been painstakingly written on the spines of millions of books.
The Dewey system came to be as a result of the need to store one book in one place – knowledge has to be ordered when it is on shelves. Archives avoid this particular trap because they are not set out on shelves for people to browse, so they do not need a set physical order. The danger of archives being stereotyped as dusty boxes on shelves in dark rooms at least provided the advantage that they did not need to be ordered for browsing; the intellectual arrangement of archives has always been via the finding aids, so the physical collections did not need to undergo the either-or of arrangement in the way that libraries did.
Dewey relies upon giving a book a subject (although there can be cross-referencing to it of course). A book is not always easy to categorise under a subject; but an archive collection may be nigh on impossible to shoe-horn into one subject heading. If it’s hard enough to decide where to put a book about something like globalisation, trade and technology, for example, then it is almost an impossible task with archives because one collection is typically about a whole range of subjects, often ostensibly unrelated. And, of course, often archives are not consciously ‘about’ a subject, in so far as the subject is not central to the reason they were created. For example, a series of correspondence held in a Manchester archive might not be created to consciously describe or explain aspects of social housing developments in Manchester, but it might provide valuable evidence nonetheless; a letter might be written by someone moving into a new housing development, giving a great insight into how people felt about the large post-war housing estates, and what sort of changes it made to their lives. But the collection wouldn’t be ‘put under housing’ because it doesn’t need to be. It would really be impossible to physically put it together with other materials about the same subject because the correspondence might cover all manner of subjects – in a sense random subjects – if the writer is essentially communicating news and stuff that affects their life.
So, what are the implications for archives cataloguing? How does ‘the geography of knowledge’ impact on archives? We haven’t got something like Dewey, we don’t have the problem of arranging physical things on shelves for people to browse. But do we still have a sense of ‘the right way’ to organise knowledge?
Well, we may not physically arrange archive collections on shelves, but we do approach dealing with each collection by the principles that we deem to be important – provenance and original order. Maybe we’re lucky that we have the principle of original order because it gives us a sensible, rational means to order a collection of sometimes very disparate materials (or you might say the idea is that the collection is already ordered for us). If we dispensed with original order, then we could come up with all sorts of other ways to order things but it is hard to see them making much sense. Weinberger’s book ‘Everything is Miscellaneous’, holds to the principle that in the digital age information wants to be free from all physical constraints, but I contend that original order provides a physical order that gives researchers an option – a way into the content should they choose to take it. I think ‘everything can be miscellaneous’ is more to the point. There are good reasons for imposing a physical order on an archive; but that shouldn’t mean that researchers are constrained as a result.
I think that what we need to be thinking about is enabling researchers to organise knowledge themselves – in a way that is relevant and useful for their own purposes. This potential for organisation is directly related to how we catalogue. Many people will search by subject, but when I look at the descriptions on the Archives Hub, I find many don’t have subject headings added to them. Subject headings offer significant advantages; they allow for the idea of different ways into a collection of information. They are like different pathways for researchers to take in order to get to the collection and connect it up with other collections.
When I search for ‘cooperative movements’ as a phrase on the Hub I get 40 hits. When I search for it as a subject I get 15 hits. If the system was working perfectly, I would deduce from this that there are 15 instances where ‘cooperative movement’ is a significant subject, and 25 more where it is relevant in some way – maybe it is referred to in passing, but the archive is not substantially concerned with this topic. However, it doesn’t really work like this because it is impossible to achieve that level of consistency in cataloguing. Different people catalogue differently. Some cataloguers put in more subjects, and some less; some maybe take more time to think about appropriate subjects, others just add a few very quickly; some don’t put any in at all, maybe believing that a free text search is enough. The end result of this is that searching becomes even more of a chance thing than it maybe needs to be. The irony for me, managing an aggregator, is that life would probably be a great deal easier if everyone catalogued in a superficial way…as long as it was consistent. As it is, you enter a subject term and you may still miss an archive of major importance. Enter a keyword (searching all the text) and you may not enter the same word(s) the cataologuer has used. There is, without doubt, an inevitable mis-match between what the cataloguer does and what the researcher needs in many cases.
It is a similar situation with the title of the material, which has become a vital way into collections now that so many people use general search engines. The title is what they see in a list of Google results. It needs to do its very best to reflect the content of the archive. “Miscellany of eighteenth century poems by various authors” is pretty good, when you have something that is quite varied it pulls it together by what it is and when it was created. “Verse miscellany” is not so good, as it gives the researcher less to go on. “Poems” is pretty vague. A researcher on the Hub can look for ‘poems’ and then narrow the search down by other means, but when on Google these titles are not so useful. We try to keep the dates of creation with the title, as the two together provide a good deal more information. But a title can so often give a sense of the miscellaneous in archives; and it can be quite difficult to get round this with some of the more varied collections, which can sometimes be somewhat esoteric. Other titles just offer a personal or organisation name, which is fine when the researcher is in the reading room – they assume the name means that this is an archive about this person/organisation. Out of content a name is just a name and could mean absolutely anything.
Of course, we have to take a pragmatic approach, and there has been plenty written about this. Cataloguing will never ever be perfect: researchers will always have to seek in order to find. But we can probably do more to make things better, and we can try to understand more about the ways that people both look for something they want to find and search for what is out there (not knowing what they want to find).
I believe that it is worth putting a small amount extra thought into the words that are chosen when cataloguing, thinking about how each end-user will want to organise their own geography of knowledge. A bit of thought about the key significant subjects is a good approach. This will help people, coming from different perspectives, and different search strategies, to discover archive collections.
We are still a long way from connecting things up in a way that researchers would like to see. The vision of Linked Data is to do just this. It offers a way to make connections across data sets. It opens up the idea of organising knowledge so that its never just one thing but a completely fluid landscape. It’s not Melvil Dewey, looking at the world and giving us his version of how it should be organised; rather it is offering the chance to organise the world in an infinite number of ways. If others out there have resources on ‘The Fabian Society’ or ‘Beatrice Webb’ or ‘ the co-operative movement’ they can state that their concepts are the same as mine, and therefore my archive can be linked to these other resources. This opens up data, enabling people to traverse data sets and bring resources together for their own ends. For creating Linked Data, structured concepts, like subject headings, are a great help, because they facilitate making these connections. Of course, there’s a bit more involved in Linked Data (including creating persistent URIs and actually matching up the same concepts), but the potential to link knowledge together in this large-scale way is immense.
Another means to encourage this fluidity is to allow end-users to add tags to content, so that we generate a mass of ways into the data. We really have to seriously consider this option for archival data, because it offers such significant advantages in terms of making things more discoverable. It is moving away from the idea that there is one way of doing things. It allows for things to be organised in an infinite variety of ways. Plenty of projects are now doing this, such as the zooniverse science projects https://www.zooniverse.org/, the Your Paintings project and the British Library georeferencing project for maps, but I’m not sure that we are really embracing it on a day-to-day level within archive catalogues.
An archive can act like a lego set. As archivists we present the set as it was originally built, and we aim to keep this because it is evidence of its use. But we want, somehow, to label the whole, and to label parts of the whole, in such a way that researchers can take bits of them and use them to build other constructs; the difference now from 50 years ago is that we are more aware that we should not try to second-guess the constructs that people want to make, but we should catalogue to allow for infinite patterns.
It is tempting to forge ahead with ambitious plans for Web interfaces that grab the attention, that look impressive and do new and whizzy things. But I largely agree with Lloyd Rutledge that we want “less emphasis on grand new interfaces” (Lloyd Rutledge, The Semantic Web – ISWC 2010, Selected Papers). I think it is important to experiment with exciting, innovative interfaces, but the priority needs to be creating interfaces that are effective for users, and that usually means a level of familiarity and supporting the idea that “users of the Web feel it acts they way they always knew it should (even though they actually couldn’t imagine it beforehand).” Maybe the key is to make new things feel familiar, so that we aren’t asking users to learn a whole new literacy, but a new literacy will gradually emerge and evolve.
For the Archives Hub, we face similar challenges to many websites that promote and provide access to archives, although our challenges are compounded by being an aggregator and not being in control of the content of the descriptions. We are seeking to gradually modify and improve our interfaces, in the hope that we help to make the users’ discovery experiences more effective, and encourage people to engage with archives.
One of our aims is to introduce options for users that allow them to navigate around in a fairly flexible manner, meeting different levels of experience and need, but without cluttering the screen or making the navigation look complicated and off-putting. Interviews with researchers have indicated how people have a tendency to ‘click and see’, learning as they go, but expecting useful results fairly quickly, so we want to work with this principle, to use hyperlinks effectively, on the understanding that the terminology used and the general layout of the page will have an effect on user expectations.
A Separation of Parts
One of the issues when presenting an archival description is how to separate out the ‘further actions’ or ‘find out more’ from the basic content. The challenge here is compounded by the fact that researchers often believe the description is the actual content, and not just metadata, or alternatively they assume that they can always access a digital resource.
We have tried to simplify the display by introducing a Utility Bar. It is intended to bring together the further options available to the end user. The idea is to make the presentation neater, show the additional options more clearly, and also keep the main description clear and self-contained.
The user can click to find out how to access the materials, to find out where the repository is located in the UK or contact the repository by email. We are planning to make the email contact link more direct, opening an email and populating it with the email address of the repository in order to cut down on the number of stages the user has to go through (currently we link to the Archon directory of Archive services). We can also modify other aspects of the Utility Bar over time, adding functionality as required, so it is a way to make the display more extensible.
We have included links to social networking sites, although in truth we have no real evidence that these are required or used. This really was a case of ‘suck it and see’ and it will be interesting to investigate whether this functionality really is of value. We certainly have a lively following on Twitter, and indications are that our Twitter presence is valued, so we do believe that social networking sites play an important part in what we do.
We have also included the ability to view different formats. This will not be of value to most researchers, but it is intended to be part of our mission to open up the data and give a sense of transparency – anyone can see the encoding behind the description and see that it is freely available. Some of our contributors may find it useful, as well as developers interested in the XML behind the scenes.
The Biggest Challenge: how to present an archive description
Until recently we presented users with an initial hit list of results, which enabled them to see the title of a description and choose between a ‘summary’ presentation and a ‘full’ presentation. However, feedback indicates that users don’t know what we mean by this. Firstly, they haven’t yet seen the description, so there is nothing on which to base the choice of link to click, and secondly, what is the definition of ‘summary’ and ‘full’ anyway? Our intention was to give the user the choice of a fairly brief, one page summary description, with the key descriptive data about the archive collection, or the full, complete description, which may run to many pages. A further consideration was that we could only provide highlighting of terms on a single page, so if we only had the full description, highlighting would not be possible.
There are a number of issues here. (a) Descriptions may be exactly the same for summary and full because sometimes they are short, only including key fields, and they do not provide multi-level content; the full description will only provide more information if the cataloguer has filled in additional fields, or created a multi-level display. (b) ‘Summary’ usually means a cut-down version of something, taking key elements, but we do not do this; we simply select what we believe to be the key fields. For example, Scope and Content may actually be very long and detailed, but it would always be part of the ‘summary’ description. (c) Fields that are excluded from the summary view may be particularly important in some cases – for example, the collection may be closed for a period of time, and this would really be key information for a researcher.
With the new Utility Bar we changed ‘summary’ and ‘full’ to become ‘brief’ and ‘detailed’. We felt that this more accurately reflects what these options represent. At present we have continued with the same principle of displaying selected fields in the ‘brief’ description, but we feel that this approach should be revised. After much discussion, we have (almost) decided that we will change our approach here. The brief description will become simply the collection-level description in its entirety; the detailed description will be the multi-level description. This gives the advantage of a certain level of consistency, but there are still potential pitfalls. Two of the key issues are (a) that ‘brief’ may actually be quite long (a collection description can still be very long) and (b) that many descriptions are not multi-level, so there would be no difference between the two descriptions. Therefore, we will look at creating a scenario where the user only gets the ‘Detailed Description’ link when the description is multi-level. If we can do this we will may change the terminology; but in the end there is no real user-friendly way to succinctly describe a collection-level as opposed to a multi-level description, simply because many people are not aware of what archival hierarchy really means.
As well as introducing the Utility Bar we changed the hit list of results to link the title of the description to the brief view. We simply show the title and the date(s) of the archive, as we feel that these are the key pieces of information that the researcher needs in order to select relevant collections to view.
Centralised Innovation
For some of the more complex changes we want to make, we need to first of all centralise the Archives Hub, so that the descriptions are all held by us. For some time we thought that this seemed like a retrograde step: to move from a federated system to a centralised system. But a federated system adds a whole layer of complexity because not only do you not have control over the data you are presenting; you do not have control over some of the data at all, to view it, and examine any issues with it, and also to potentially improve the consistency (of the markup in particular). In addition, there is a dependency between the centralised system and the local systems that form the federated model. Centralising the data will actually allow us to make it more openly available as well, and to continue to innovate more easily.
Multiple Gateways: Multiple Interfaces
We will continue to work to improve the Archives Hub interface and navigation, but we are well aware that increasingly people use alternative interfaces, or search techniques. As Lorcan Dempsey states: “options have multiplied and the breadth of interest of the local gateway is diminished: it provides access only to a part of what I am potentially interested in.” We need to be thinking more broadly: “The challenge is not now only to improve local systems, it is to make library resources discoverable in other venues and systems, in the places where their users are having their discovery experiences.” (Lorcan Dempsey’s Webblog). This is partly why we believe that we need to concentrate on presenting the descriptions themselves more effectively – users increasingly come directly to descriptions from search engines like Google, rather than coming to the Archives Hub homepage and entering a search from there. We need to think about any page within our site as a landing page, and how best to help users from there, to discovery more about what we have to offer them.
The Archives Hub team wish everyone a very Merry Christmas, and a Happy New Year!
The Archives Hub office will close on 21st December and will reopen on the 2nd January.
The Archives Hub service will be available over Christmas and New Year, but there will be no helpdesk support. Any queries sent over this period will be dealt with when we return.