One of the challenges that we face with our Labs project is presentation of the Machine Learning results. We thought there would be many out of the box tools to help with this, but we have not found this to be the case.
If we use the AWS console Rekognition service interface for example, we get presented with results, but they are not provided in a way that will readily allow us and our project participants to assess them. Here is a screenshot of an image from Cardiff University – an example of out of the box use of AWS Rekognition:
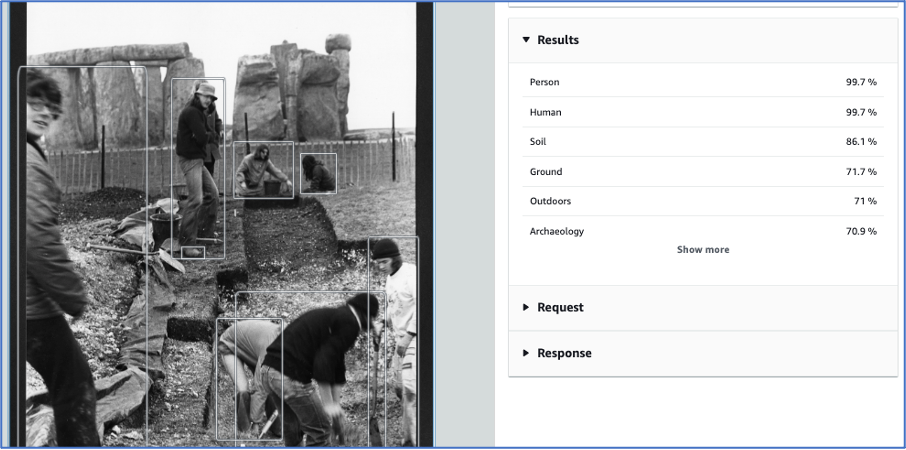
This is just one result – but we want to present the results from a large collection of images. Ideally we would run the image recognition on all of the Cardiff images, and/or on the images from one collection, assess the results within the project team and also present them back to our colleagues at Cardiff.
The ML results are actually presented in JSON:

Here you can see some of the terms identified and the confidence scores.
These particular images, from the University archive, are catalogued to item level. That means they may not benefit so much from adding tags or identifying objects. But they are unlikely to have all the terms (or ‘labels’ in ML parlance) that the Rekognition service comes up with. Sometimes the things identified are not what a cataloguer would necessarily think to add to a description. The above image is identified as ‘outdoors’, ‘ground’ and ‘soil. These terms could be useful for a researcher. Just identifying photographs with people in them could potentially be useful.
Another example below is of a printed item – a poem.

Strange formatting of the transcript aside, the JSON below shows the detected text (squirrels), confidence and area of the image where the word is located.

If this was provided to the end user, then anyone interested in squirrels in literature (surely there must be someone…) can find this digital content.
But we have to figure out how to present results and what functionality is required. It reminds me of using Open Refine to assess person name matches. The interface provides for a human eye to assess and confirm or reject the results.
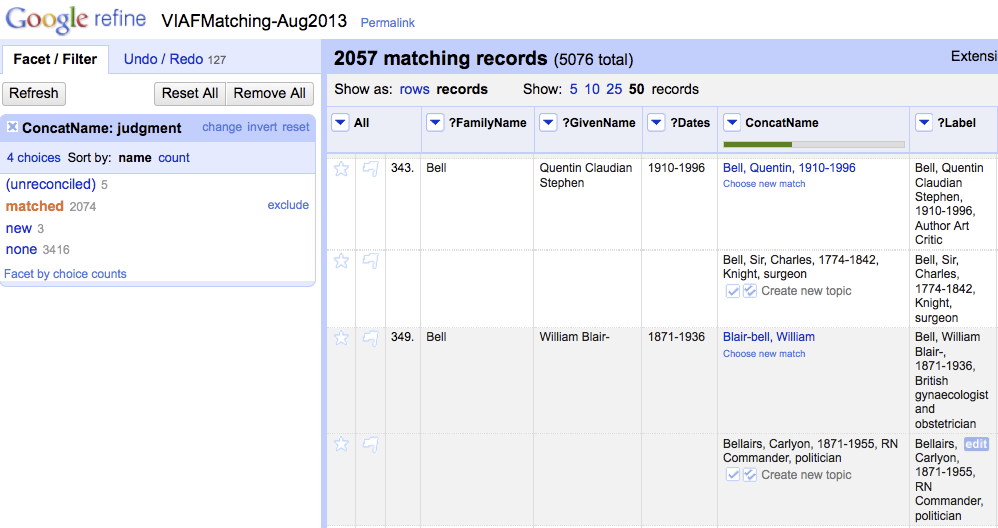
We want to be able to lead discussions with our contributors on the usefulness, accuracy, bias – lack of bias – and peculiarities of machine learning, and for that a usable interface is essential.
How we might knit this in with the Hub description is something to consider down the line. The first question is whether to use the results of ML at all. However, it is hard to imagine that it won’t play a part as it gets better at recognition and classification. Archvists often talk about how they don’t have time to catalogue. So it is arguable that machine learning, even if the results are not perfect, will be an improvement on the backlogs that we currently have.
AWS Rekognition tools
We have thought about which tools we would like to use and we are currently creating a spreadsheet of the images we have from our participants and which tools to use with each group of images.
Some tools may seem less likely, for example, image moderation. But with the focus on ethics and sensitive data, this could be useful for identifying potentially offensive or controversial images.
The Image Moderation tool recognises nudity in the above image.
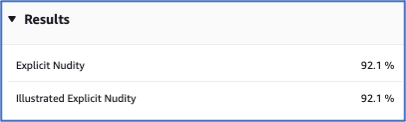
This could be carried through to the end user interface, and a user could click on ‘view content’ if they chose to do so.

The image moderation tool may classify images art images as sensitive when they are very unlikely to cause offence. The tools may not be able to distinguish offensive nudity from classical art nudity. With training it is likely to improve, but when you think about it, it is not always an easy line for a human to draw.
Face comparison could potentially be useful where you want to identify individuals and instances of them within a large collection of photographs for example, so we might try that out.
However, we have decided that we won’t be using ‘celebrity recognition’, or ‘PPE detection’ for this particular project!
Text and Images
We are particularly interested in text and in text within images. It might be a way to connect images, and we might be able to pull the text out to be used for searching.
Suffice to say that text will be very variable. We ran Transkribus Lite on some materials.

We compared this to use of AWS Text Rekognition.

These examples illustrate the problem with handwritten documents. Potentially the model could be trained to work better for handwriting, but this may require a very large amount of input data given the variability of writing styles.

Transkribus has transcribed this short typescript text from the same archive well. One word ‘house’ has been transcribed as ‘housd’ and ‘idea’ caused a formatting issue, but overall a good result.

The above example is Transkribus Lite on a poster from the University of Brighton Design Archives. In archives, many digital items are images with text – particularly collections of posters or flyers. Transkribus has not done well with this (though this is just using the Lite version out of the box).
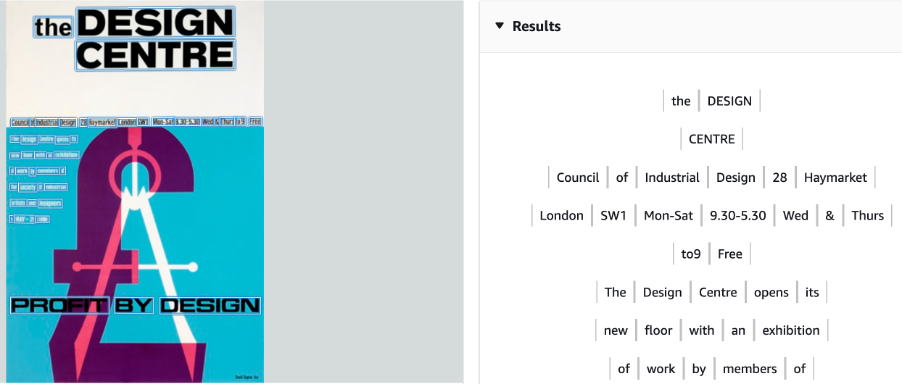
We also tried this with the AWS Rekognition Text tool, and it worked well.
Another example of images with text is maps and plans.


Above are two examples of places identified from the plan output in JSON. If we can take these outputs and add them to our search interface, an end user could search for ‘clerkenwell’ or ‘northampton square’ and find this plan.
Questions we currently have:
- How do we present the results back to the project team?
- How do we present the results to the participants?
- Do we ask participants specific questions in order to get structured feedback?
- Will we get text that is useful enough to go to the next step?
- Which images provide good text and which don’t?
- How might they results be used on the Archives Hub to help with discovery?
As we progress the work, we will start to think about organising a workshop for participants to get their feedback on the ML outputs.
Thanks to Adrian Stevenson, one of the Hub Labs team, who took me through the technical processes outlined in this post.