The Archives Hub Names Project
The Archives Hub team and Knowledge Integration, our system suppliers, are embarking upon a short four month project to start to lay the groundwork, define the challenges and test the approaches to presenting end users with a name-based means to search, and connect to a broad range of resources related to people and organisations. I will be blogging about the project as we go along.
Our key aims in the long-term are:
- To provide the end user with a way to search for people and organisations and find a range of material relevant to their research
- To enable connections to be made between resources within and external to Jisc, using names as the main focus
- To bring archive collections together in an intellectual sense and provide different contexts to collections by creating networks across our data
This first project will not create an end-user interface, but will concentrate on processing, matching names and linking resources. We want to explore how this can be administered in order to be sustainable over time. In the end, the most challenging part of working with the names we have is identification, disambiguation and matching. The aim is to explore the space and start to formulate a longer-term plan for the full implementation of names as entities within the Archives Hub.
Creation of name records from EAD description records
NB: This blog often refers to personal names for convenience, but names include personal, family and corporate entities.
 EAD descriptions include personal, family and corporate names. These ‘entities’ may be listed as archival creators and also associated with the collection as index terms. Archival creators may optionally be given biographical or administrative histories. The relationship of the collection with names in the index is not made explicit in the description (in a structural way), though it may often be gleaned from the descriptive information within the EAD record.
EAD descriptions include personal, family and corporate names. These ‘entities’ may be listed as archival creators and also associated with the collection as index terms. Archival creators may optionally be given biographical or administrative histories. The relationship of the collection with names in the index is not made explicit in the description (in a structural way), though it may often be gleaned from the descriptive information within the EAD record.
Creating name records for all names
We are proposing to begin by creating name records for all of these entries, no matter how thin the information for each entry may be.
Here is a random selection of names that are included in Archives Hub records:
Grote, Arthur
Gaskell, Arthur
Wilson, John
Thatcher, J. Wells, Barrister at Law
Barron, Margaret
Stanley, Catherine, 1792-1862
Roe, Alfred Charles
Rowlatt, Mary, b 1908
Milligan, Spike, 1918-2002
Fawcett, Margaret, d. 1987
Rolfe, Alan, 1908-2002 actor
Mayers, Frederick J (fl 1896-1937 : designer : Kidderminster, England)
Joan
Only a percentage of names have life dates. Some have born or death dates, some floruit dates.
Of course, the life dates, occupations and outputs of many people are not known, or may be very difficult to find. Also, life dates will change when a birth date is joined by a death date. Epithets may also change over time (and they are not controlled vocabulary anyway).
In addition, we have inverted and non-inverted names on the Archive Hub, names with punctuation in different places, names with and without brackets, etc. These issues create identification challenges.
Even taking names as creators and names as index terms within one single description, the match is often not exact:
Millicent Garrett Fawcett (creator name)
Fawcett, Dame Millicent. (1847-1929) nee Garrett, Feminist and Suffragist (index term)
Lingard, Joan (creator name)
Lingard, Joan Amelia, 1932- (index term)
The archival descriptions on the Archives Hub vary a great deal in terms of the structure, and different repositories have different approaches to cataloguing. Some do not add name of creator, some do not add index terms, some add them intermittently, and often the same name is added differently for different collections within the same repository. In many cases the cataloguer does not add life dates, even when they are known, or they are added to the name as creator but not in the index list, or vice versa. This sounds like a criticism, but the reality is that there are many reasons why catalogues have ended up as they are.
There has not been a strong tradition amongst archivists of adding names as unique identifiable entities, but of course, it has only been in the last few decades that we have had the potential, which is becoming increasingly sophisticated, of linking data through entity relationships, and creating so much more than stand-alone catalogue records. Many archivists still think primarily in terms of human readable descriptions. Some people feel that with the advent of Google and sophisticated text analysis, there is no need to add names in this structured way, and there is no need for index terms at all. But in reality search engines generally recommend structured data, and they are using it in sophisticated ways. Schema.org is for structured data on the web, an initiative started by Google, Microsoft, Yahoo, and Yandex. Explicit markup helps search engines understand content and it potentially helps with search engine optimisation (ensuring your content surfaces on search engines). Also, if we want to move down the Linked Data road, even if we are not thinking in terms of creating strict RDF Linked Data, we need to identify entities and provide unique identifiers for them (URLs on the web). Going back to Tim Berners-Lee’s seminal Linked Data article from 2006:
“The Semantic Web isn’t just about putting data on the web. It is about making links, so that a person or machine can explore the web of data. With linked data, when you have some of it, you can find other, related, data.”
So, including names explicitly provides huge potential (as well as subjects, places and other entities) and it has become more important, not less important. Indeed, I would go so far as to say that structured data is more important than standards compliant data, especially as, in my experience, standards are often not strictly adhered to, and also, they need constant updating in order to be relevant and useful.
The idea with our project is that we start with name records for every entity – a pot of data we can work with. We may create Encoded Archival Context (Corporate Bodies, Persons and Families), otherwise known as EAC-CPF…but that is not important at this stage. EAC is important for data ingest and output, and we intend to use it for that purpose, so it will come into the picture at some point.
The power of the anonymous
There are benefits in creating name records for people who are essentially anonymous or not easily identifiable. Firstly, these records have unknown potential; they may become key to making a particular connection at some point, bearing in mind that the Archives Hub continually takes new records in. Secondly, we can use these records to help with identification, and the matching work that we undertake may help to put more flesh on the bones of a basic name record. If we have ‘Grote, Arthur’ and then we come across ‘Grote, Arthur, 1840-1912’, we can potentially use this information and create a match. Of course, the whole business of inference is a tricky thing – you need more than a matching surname and forename to create a ‘same as’ relationship (I won’t get into that now). But the point is that a seemingly ‘orphan’ name may turn out to have utility. It may, indeed, provide the key to unlocking our understanding of particular events – the relationships and connections between people and other entities are what enable us to understand more about our history.
Components of a name record
So, all names will have name records, some with just a name, some with life dates of different sorts, some with biographical or administrative histories. The exception to this may be names that are not identifiable as people or organisations. It is potentially possible to discover the type of entity from the context, but that is a whole separate piece of work. Hundreds of names on the Archives Hub are simply labelled as ‘creator’ or ‘name’. This is down to historical circumstance – partly the Archives Hub made errors in the past (our old cataloguing tool which entered creators as simply EAD ‘origination’), partly other systems we ingest data from. At the moment, for example, we are taking in descriptions from Axiell’s AdLib system, but the system does not mark up creator names as people or organisations (unless the cataloguer explicitly adds this), so we cannot get that information. This is probably a reflection of a time when semantically structured data was simply less important. If a human reads ‘Elizabeth Gaskell’ in a catalogue entry they are likely to understand what that string means; if undertaking large-scale automated processing, it is just a string of characters, unless it includes semantic information.
From the name records that we create, we intend to develop and run algorithms to match names. In many cases, we should be able to draw several names together, with a ‘same-as’ relationship. Some may be more doubtful, others more certain. I will talk about that as we get into the work.
At the moment, we have some ideas about how we will work with these individual records in terms of the workflow and the end user experience, but we have not made any final decisions, and we think that what is most important at this stage is the creation and experimentation with algorithms to see what we can get.
Master name records
We intend to create master records for people and organisations. The principle is to see these master records not as something within the archives domain, but as stand-alone records about a person or organisation that enable a range of resources to be drawn together.
So, we might have several name records for one person:
Example of master record, with various related information included:
Webb, Martha Beatrice, 1858-1943, social reformer and historian
Examples of additional name records that should link to the master record:
Webb, Beatrice, 1858-1943 (good match)
Webb, Martha Beatrice, 1858-1943, economist and reformer (good match)
Webb, Martha Beatrice, nee Potter, 1858-1943 (good match)
Webb, M.B. b. 1858 (possible match)
but…
Potter, Martha Beatrice, b 1858
…might well not be a match, in which case it would stand separately, and the archive connected to it would not benefit from the links being made.
We have discussed the pros and cons of creating master records for all names. It makes sense to bring together all of the Beatrice Webb names into one master record – there is plenty that can be said about that individual; but does it make sense to have a master record for single orphaned names with no life dates and nothing (as yet) more to say about that individual? That is a question we have yet to answer.
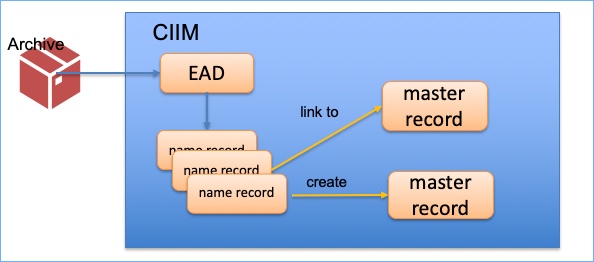
The principle is to have name records that enables us to create links to the Archives Hub entries and also to other Jisc services and resources beyond that – resources outside of the archives domain. Many of these resources may also help us with our own identification and matching processes. It is important to benefit from the work that has already been done in this area.
We are looking at various name resources and assessing where our priorities will be. This is a fairly short project, and we won’t have time to look at more than a handful of options. But we are currently thinking in terms of VIAF, ORCID and Wikidata. More on that to follow.
Personally, I’ve been thinking about working with names for several years. We have been asked about it quite a bit. But the challenge is so big and nebulous in many ways. It has not been feasible to embark upon this kind of work in the past, as our system has not supported the kind of systematic processing that is required. We are also able to benefit from the expertise K-Int can bring to data processing. It is one thing doing this as a stand-alone project; it is quite another to think about a live service, long term sustainability, version control and revisions, ingest from different systems, etc. And also, to break it down into logical phases of work. It is exciting, but it is going to involve a great deal of hard work and hard thinking.
Hi there
Writing this in a personal capacity – I am not super-techy, but the blog has set off thoughts regarding categorization of names from Black Lives Matter discussions… eg Admiral Lord Nelson, Cecil Rhodes to name but 2. Is this a time to open a discussion on name conventions? Not sure if/how this might be incorporated into the project. It might be interesting to think around how to include lesser known people? I know there are discussions happening on cataloging more generally.
Thanks!
This is definitely an area that we, as an aggregator, should think about. Obviously there is a question as to whether this sits more appropriately with individual archives, but on the other hand we could potentially implement global changes or approaches, rather than each individual archive working on this. I think that if we can get our processes set up in order to administer name records, then we have the opportunity to think about the actual content, and to undertake more analysis. So, first of all we need to figure out not only name matching but also how you do that on an ongoing basis, and not just for a stand-alone project. What you are talking about requires long-term thinking, not just trying to tackle it once. It is so important to think about how to embed these things. But so much harder than taking a shorter term project-based approach! For instance, once we have names, unique identifiers, and a workflow, we could look at more name analysis and, indeed, consider biographical histories and their biases….what to do about that is another matter. But this kind of linked data approach allows for bringing in external resources, and that way we can work with sources that help contextualise people in a more multi-dimensional way.
Hi Jane, quite important what you do! I am working on similar issues given the interest in personal history grows unstoppably among our users. One question: The richest personal name data are in databases outside the archives catalogues (census, tax records, PoW lists, etc.), does your project address this? I am now working on identifying World War II persons with names from different sources, and although there are many close similarities, the uncertainty is so high (high number of common names, relatives with the same name, etc.) that probability indexes between instances seem to me more viable than creating master records. Not to mention that librarians museologists, hate us for the inclusion of thin records of non-prominent individuals in building controlled vocabularies.
Hi Zoltan, this current project won’t address too many external sources. It is a case of taking steps towards that kind of approach. This project is about embedding a process into our system – otherwise this kind of work so often ends up not being sustainable. Yes, the problem of ‘thin records’ – as you say, that is a potential issue with archives. And yet, we have the potential to unearth new knowledge because we have hidden histories within our archives – including the roles played by little known people. The idea of a master record is precisely because the ‘same as’ connection is hard to achieve with certainty. This is a record ‘on top of’, or in a way separate from, the other individual records – so, not bringing them all together (and running the risk of errors), but providing a generic person entry from which we can then link to these individual entries, because we believe they are potentially the same entity. That’s the plan at the moment anyway! To be honest, we are being flexible, so that we can work with what we find.
Colleagues explored some of the issues around linking records in the Traces Through Time project at The National Archives. A final paper at “Traces through time: A probabilistic approach to connected archival data” https://ieeexplore.ieee.org/document/7840983
Some record series in Discovery include data from this project, suggesting potentially related records. It didn’t go as far as a creating a name record to tie these together however.
Thanks David, I was aware of the Traces Through Time project, but now is a good time to revisit it and read the paper.