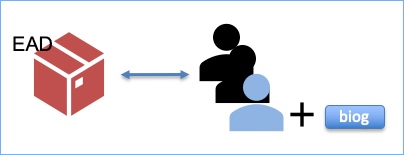
It has been great to get comments and feedback around names, and I wanted to expand upon something that a few people have commented on….the ideal of one ‘authority record’ for one person or organisation.
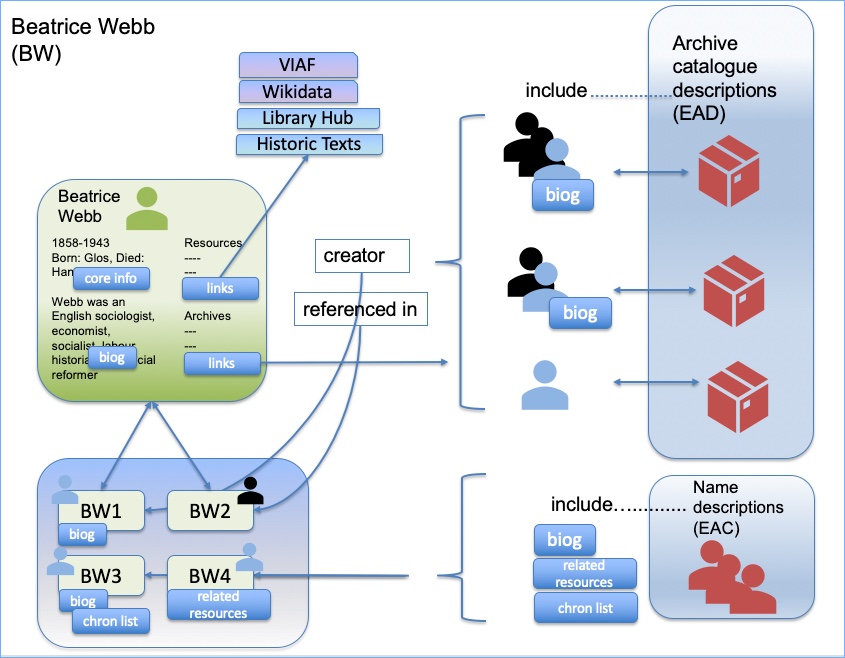
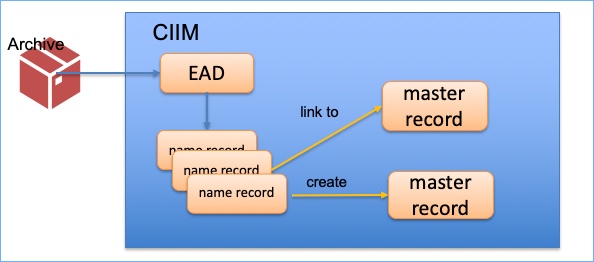
The above diagram is a proposal for the relationships we might have – note that is it a working model, and may well change over time. You can see the catalogues (the descriptions of archives) include people, some with biographical histories, and these people are either creators of archive collections or referenced in them. Each of these people then gets a name record (bottom left box), so we might have e.g. three name records for the same name (and the same name may potentially the same person…or may not). We will work with the store of records that we have with the aim of creating matches, and ending up with a generic or main name record (green box, top left).
The ‘main record’ or ‘master record’ or whatever we might call it, for each individual person or organisation, is not an ‘archival record’. It is not intended simply to be a reflection of what is in our own data. It is intended to be a page dedicated to that person or organisation. Our current feeling is that this should not be seen as domain specific; in fact, we want to get away from the idea that data is domain specific. It is about an entity (a person or organisation), and what we know of that entity.
Keeping in mind the green box, and looking at the person page for Robin Day from Exploring British Design, a previous AHRC project we ran with Brighton Design Archive, you get a sense of the type of thing we mean.

This page presents as a general information page about a designer. It is not branded as a page about archives. It takes information in from different sources. Is it an ‘authority’ record? I’m really not sure; I wouldn’t call it that. The point is really that it enables researchers to put Robin Day into the context of other people, organisations places and events, or at least it demonstrates how that can be done. It creates a network, and it intends to show the value of including archives in a network, rather than standing apart, in their ‘own world’.
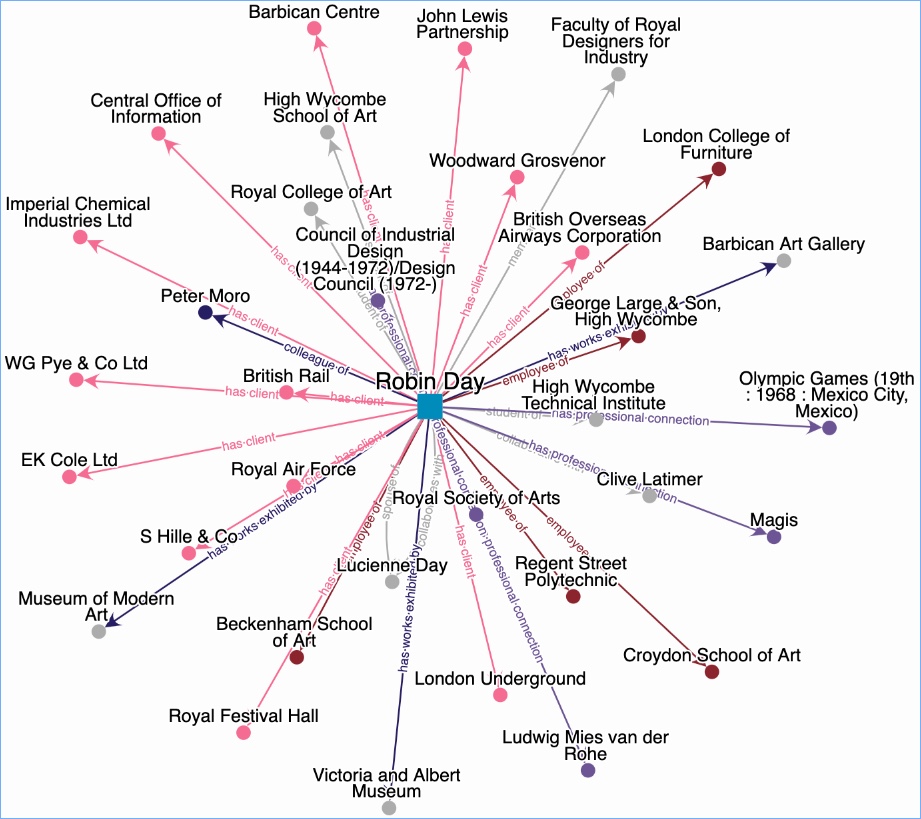
The network can easily be visualised. There are tools out there to do this. The challenge is to create the data to feed into these visualisers. Again, this visualisation is not about archival name authority records, it is not domain specific.
In the Robin Day page, we have a section for related archives and museum resources.
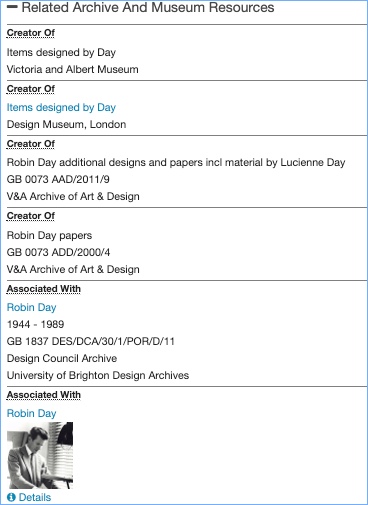
This lists archives Robin Day is the ‘creator of’ or archives he is ‘associated with’. It links to the Archives Hub, but also to other sources. One of the options for end users is to go and find out more about the archival sources, but it is not prioritised above other options.
So, this is essentially the idea – a page for a person, a page for an organisation. An information resources that focuses on creating a network of connections. We think this is a good approach, but creating something along these lines that is automated, sustainable and effective within an ongoing national service is much harder.
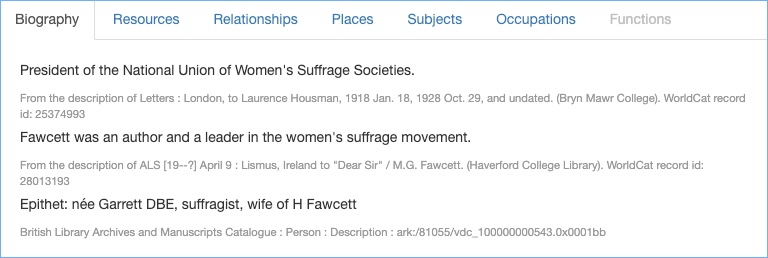
Why not just use this one record, link to the archive catalogues, and dispense with the individual name records that we have created? There are three reasons to consider providing access to the individual name records: biographical history, uncertainty around matching and ingesting name authority records.
I have already written about biographical and administrative history in a separate post.
In this phase of the Names Project the individual records for Beatrice Webb (as a name example), will be created either from the creator name or index terms that we have in the Archives Hub catalogues.
The main problem is the wide variation in name entries.
Webb, Beatrice
Webb, Beatrice, née Potter
Webb (Martha) Beatrice, 1858-1943
Webb, Martha Beatrice, 1858-1943
Webb;[Martha] Beatrice [nee Potter] 1858-1943
These are all entries in the Archives Hub. We can match them all up, but can we say they are all the same? Names without dates should not be matched with certainty, but quite often they will be the same person. (Beatrix Potter also often ends up being linked with Beatrice Webb, née Potter).
The decision we need to make is whether to provide links to these individual name records that we will have, or only use them as a source of data. It seems valuable to enable end users to see these names as a group, but it is another thing to risk integrating information from them all into one name record. There is no perfect answer to this, but it does seem important to clearly indicate the level of uncertainty. So many names that we have don’t have life dates, or have variations in structure. What we are looking to achieve is a clear provenance, giving end users the best understanding of what they are seeing.
What about name records that have been created by our contributors? The name records we create ourselves from catalogue descriptions will generally be no more than the name, dates, and biographical history. But, going forwards, we will want to work with much more detailed name records.
For Exploring British Design we created rich name records with an entity-relationship structure (essentially using the EAC-CPF structure and working in RDF), to demonstrate the power of connecting entities. For this purpose, we partially hand-crafted the name records, as well as carrying out some very complex processing to create various connections.
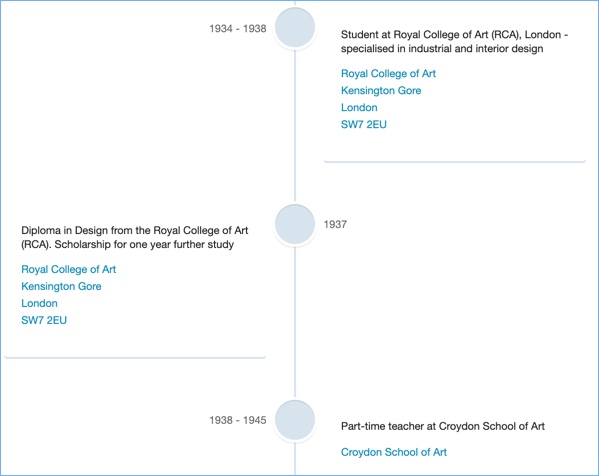
The example above shows events from the Robin Day timeline, with linked connections to related organisations. If we ingest EAC-CPF records we might get timelines like this.
Name records may also include relationships. The Borthwick Institute has good examples of name records with plenty of rich relationship information. e.g. Charles Lindley Wood, Viscount Halifax.

If we took this record into the Archives Hub it might seem to make sense for it to become the main person record for Wood. But that would involve a process of making choices, preferencing one name record over another. Possible, but tricky to do in an automated way. Another record office might also have a splendid example of a name entry for this person, with some different data. Furthermore, this record has links to the Borthwick catalogue. We would potentially have to remove these links.
It would be very challenging to create one record from several source EAC-CPF records for the same person – to blend timelines, or sort out relationships listed in different records, bearing in mind that it needs to be done in an automated way, keeping version control and dealing with revisions and new data coming in that might add to the name record. How could we compare and blend two lists of relationships? Or two chronologies? We’d probably end up having to keep them all, and then potentially have similar but different relationships and chronologies, giving a slightly confused user experience.
If we do ingest records like the one above, we will have to figure out how these more detailed records will relate to what we have already created. If, as planned, we have one generic name record for a person, it makes the job easier, as we won’t be looking to make any one EAC-CPF record into the main name record, we will simply link to it from the main record. Bear in mind, our main record is intended to be a domain-neutral entry – linking to other sources beyond archives. EAC-CPF records might do this to some extent, but they are unlikely to link to the Jisc Library Hub, and probably won’t link to Wikidata, or other external sources. They are far more likely to provide internal links to the archive catalogue they relate to.
Arguably, it might be easier to forget about creating name records ourselves (from the catalogue entries) and just work with name records that have been created by our contributors (which are likely to be well-structured and include life dates). But if we do that, the pot of names will grow slowly, as only a small proportion of repositories create name records. We can’t realistically give the end user a few thousand name records covering maybe 1-2% of our names – they might search for ‘Winston Churchill’ as a name, and find that we don’t have him! It would not remove the problem of name matching, and it would make the whole idea of reaching out beyond the archive domain, by linking into other resources using our names as the hook, rather ineffectual.
Therefore, we propose to keep the separate name records in our system We propose to create a ‘generic record’, which is what would be prominent in the Archives Hub display. We would then have the potential to link the records together, to blend them, to try some text mining and analysis techniques. It gives us options. It would not be sensible to make those decisions now. It is better to lay the groundwork that enables us to be flexible. This approach allows us to link to an individual name record where we don’t feel able to confirm a ‘same as’ relationship. It presents the option to the end user – here is a name – we think this is the same person, so we’ve provided a link.
The end user experience needs to make sense and not mislead or provide false information. Links to brief name records could seem confusing, but, as I have said, trying to bring together in one record all the information from several name records, with their biographies, relationships, aliases, events, related resources, is likely to be a nightmare. In the end, it will take a good deal more testing and working with researchers to work out what is best.