I attended the ‘CogX Global Leadership Summit and Festival of AI’ last week, my first ‘in-person’ event in quite a while. The CogX Festival “gathers the brightest minds in business, government and technology to celebrate innovation, discuss global topics and share the latest trends shaping the defining decade ahead”. Although the event wasn’t orientated towards archives or cultural heritage specifically, we are doing work behind the scenes on AI and machine learning with the Archives Hub that we’ll say more about in due course. Most of what’s described below is relevant to all sectors as AI is a very generalised technology in its application.

My attention was drawn to the event by my niece Laura Stevenson who works at Faculty and was presenting on ‘How the NHS is using AI to predict demand for services‘. Laura has led on Faculty’s AI driven ‘Early Warning System’ that forecasts covid patient admissions and bed usage for the NHS. The system can use data from one trust to help forecast care for a trust in another area, and can help with best and worst scenario planning with 95% confidence. It also incorporates expert knowledge into the modelling to forecast upticks more accurately than doubling rates can. Laura noted that embedding such a system into operational workflows is a considerable extra challenge to developing the technology.
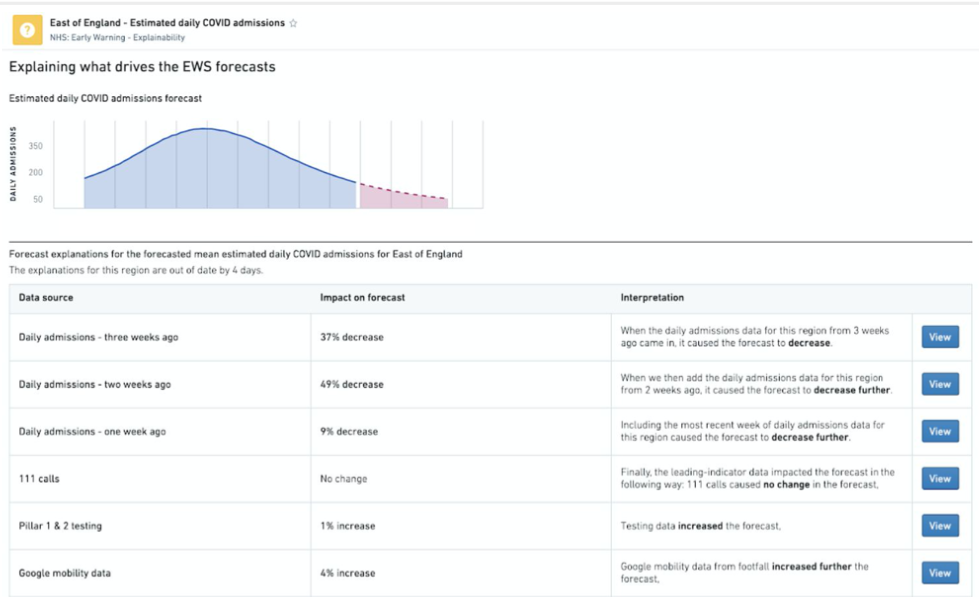
The system includes an explainability feature showing various inputs and the degree to which they affect forecasting. To help users trust the tool, the interface has a model performance tab so users can see information on how accurate the tool has been with previous forecasts. The tool is continuing to help NHS operational managers make planning decisions with confidence and is expected to have lasting impact on NHS decision making.

‘Responsible leadership: The risks and the rewards of advancing the state of the art in AI’ – Lila Ibrahim
Lila works at Deep Mind who are looking to use AI to unlock whole new areas of science. Lila highlighted the role of the AI Council who are providing guidance to UK Government in regard to UK AI research. She talked about Alphafold that has been addressing the 50 year old challenge of protein folding. This is a critical issue as being able to predict protein folding unlocks many possibilities including disease control and using enzymes to break down industrial waste. DeepMind have already created an AI system that can help predict how a protein folding occurs and have a peer reviewed article coming out soon. They are trying to get closer to the great challenge of general intelligence.

‘Sustainable Technologies, Green IT & Cloud‘ – Yves Bernaert, Senior Managing Director, Accenture
Yves focussed on company and corporate responsibility, starting his session with some striking statistics:
- 100 companies produce 70% of global carbon emissions.
- 40% of water consumption is by companies.
- 40% of deforestation is by companies.
- There is 80 times more industrial waste than consumer waste.
- 20% of the acidification of the ocean is produced by 20 companies only.
Yves therefore believes that companies have a great responsibility, and technology can help to reduce climate impact. 2% of global electricity comes from data centres currently and is growing exponentially, soon to be 8%. A single email produces on average 4g of carbon. Yves stressed that all companies have to accept that now is the time to come up with solutions and companies must urgently get on with solving this problem. IT energy consumption needs to be seen as something to be fixed. If we use IT more efficiently, emissions can be reduced by 20-30%. The solution starts with measurement which must be built into the IT design process.
We can also design software to be far more efficient. Yves gave the example of AI model accuracy. More accuracy requires more energy. If 96% accuracy is to be improved by just 2%, the cost will be 7 times more energy usage. To train a single neural network requires the equivalent of the full lifecycle energy consumption of five cars. These are massive considerations. Interpreted program code has much higher energy use than compiled code such as C++.
A positive note is that 80% of the global IT workload is expected to move to the cloud in the next 3 years. This will reduce carbon emissions by 84%. Savings can be made with cloud efficiency measures such as scaling systems down and outwards so as not to unneccessarily provision for occasional workload spikes. Cloud migration can save 60 million tons carbon per year which is the equivalent of 20 million full lifecycle car emissions. We have to make this happen!
On where are the big wins, Yves said this is also in the IT area. Companies need to embed sustainability into their goals and strategy. We should go straight for the biggest spend. Make measurements and make changes that will have the most effect. Allow departments and people to know their carbon footprint.
* Update 28th June 2021 * – It was remiss of me not to mention that I’m working on a number of initiatives relating to green sustainable computing at Jisc. We’re looking at assessing the carbon footprint of the Archives Hub using the Cloud Carbon Footprint tool to help us make optimisations. I’m also leading on efforts within my directorate, Digital Resources, to optimise our overall cloud infrastructure using some of the measures mentioned above in conjuction with the Jisc Cloud Solutions team and our General Infrastructure team. Our Cloud CTO Andy Powell says more on this in his ‘AI, cloud and the environment‘ blog post.

‘Future of Research’ – Prof. Dame Ottoline Leyser, CEO, UK Research and Innovation (UKRI)
Ottoline believes that pushing the boundaries of how we support research needs to happen. Research is now more holistic. We draw in what we need to create value. The lone genius is a big problem for research culture and it has to go. Research is insecure and needs connectivity.
Ottoline believes AI will change everything about how research is done. It’s initially replacing mundane tasks but will some more complex tasks such as spotting correlations. Eventually AI will be used as a tool to help understanding in a fundamental way. In terms of the existential risk of AI, we need to embed research as collective endeavour and share effort to mitigate and distribute this risk. It requires culture change, joining up education and entrepreneurship.
We need to fund research in places that are not the usual places. Ottoline likes a football analogy where people are excited and engaged at all levels of the endeavour, whether in the local park or at the stadium. She suggests research at the moment is more like elitist Polo not football.
Ottoline mentioned that UKRI funding does allow for white spaces research. Anyone can apply. However, we need to create wider white spaces to allow research in areas not covered by the usual research categories. It will involve braided and micro careers, not just research careers. Funding is needed to support radical transitions. Ottonline agrees that the slow pace of publication and peer review is a big problem that undermines research. We need to broaden ways we evaluate research. Peer Review is helpful but mustn’t slow things down.

‘Ethics and Bias in AI‘ – Rob Glaser, CEO & Founder of RealNetworks
Rob suggests we are in an era with AI where there are no clear rules of the road yet. The task for AI is to make it safe to ‘drive’ with regulations. We can’t stop facial recognition any more than we can stop gravity. We need datasets for governance so we can check accuracy against these for validation. Transparency is also required so we can validate algorithms. A big AI concern is the tribalism on social media.

‘AI and Healthcare‘ – Rt. Hon. Matt Hancock
Matt Hancock believes we are at a key moment with healthcare and AI technology where it’s now of vital importance. Data saves lives! The next thing is how to take things forward in NHS. A clinical trials interoperability programme is starting that will agreed standards to get more out of data use, and the Government will be updating it’s Data strategy soon. He suggests we need to remove silos and commercial incentives (sic). On the use of GP data he suggests we all agree on the use of data, but the question is how it’s used. The NHS technical architecture needs to improve for better use and building data into the way the NHS works. GPs don’t own patient data, it is the citizen.
He said a data lake is being built across the NHS. Citizen interaction with health data is now greater than ever before and NHS data presents a great opportunity for research, and an enormous opportunity for the use of data to advance health care. He suggested we need to radically simplify the NHS information governance rules. On areas where not enough progress has been made, he mentioned the lack of separation of data layers is currently a problem. So many applications silo their data. There has also been a culture of Individual data with personal curation. The UK is going for a TRE first approach: ‘Trusted Research Environment service for England‘. Data is the preserve of the patient who will allow accredited researchers to use the data through the TRE. The clear preference of citizens is sharing data if they trust the sharing mechanism. Every person goes through a consent process for all data sharing. Acceptance requires motivating people with the lifesaving element of research. If there’s trust, the public will be on side. Researchers in this domain with have to abide by new rules to allow us to build on this data. He mentioned that Ben Goldacre will look at the line where open commons ends and NHS data ownership begins in the forthcoming Goldacre Review.