On 19 June we ran a webinar on user research and user behaviour. We had three speakers – David Marshall, a UX Researcher from the University of Cambridge, Kelly Arnstein, a UX Specialist from the University of Glasgow, and Deborah Wilson, a Subject Librarian from Queens University Belfast.
(main talks 1hr + 25 minute discussion). Slides are also provided as links (below).
The talks were excellent, and followed by a lively discussion. They should prove to be useful to anyone looking at designing a website for archive catalogues, and working with students using primary sources. Overall, there was a lot of consensus about user behaviour, which is useful in terms of sharing findings – because it is likely to be relevant to all archives. The emphasis for this session was on students and academic researchers, but we did discuss some of the challenges of meeting the needs of a diverse audience.
A few summary points that came out of one or more of the talks:
People may use an archive catalogue for research and also for teaching, scoping a project, marketing and other reasons.
They want an idea of the physicality of the collection and the overall size
People want context and hierarchy, and like the idea of ‘leafing through’ material to see relationships.
There are those who want to get quickly to what they need and those who value browse and serendipity. This seems like a possible tension, and certainly a challenge, in terms of interface design. It may be that at different times the same researcher wants a quick route through and other times they want to take time and discover.
Cambridge research found that some users wanted to limit their search by date initially, but there was a strong feeling that a wide search and then filtering was generally a good option.
Finding everything of value was seen as key – many researchers were prepared to spend time to discover materials related to their research and worried about missing important materials.
The physical object remains key to many researchers
Saving searches and other forms of personalisation were seen as a good thing
Quite often researchers, especially if they are more experienced, understand that research skills are important and archive catalogues are complex; this may contrast with library databases, where they are more inclined to want to get to things quickly.
Undergraduates often don’t understand the different approach needed to engage with primary sources
Undergrads often engage with archives at the point of an assignment, where they are being marked on their use of primary sources; they initially try to find sources in the same way as they would search for anything else.
It is really valuable to educate students on the importance of context, the broad search and filter approach, understanding citations, evaluating databases, etc. They often don’t really know what primary sources are and can find them off-putting.
Researchers can make assumptions about what a repository holds, and then be surprised to find that there is material that is relevant for them.
A bad catalogue can put a researcher off, and they may choose to go further afield if the catalogue offers a better experience.
People often ignore tooltips. It is a challenge to provide help that people use.
If, as a researcher, you search for ‘Jane Drew’, the celebrated architect and town planner, on the Archives Hub, amongst other things, you might discover a single item, “Letter from Jane B Drew to John and Myfanwy Piper”, a letter in the “Papers of John and Myfanwy Piper”.
You can see that its a letter in a collection at the Tate Gallery Archive. The description of the collection is an example of a good quality traditional archival catalogue, giving a fairly detailed listing of the content this particular collection. But as a researcher you are really just interested in just this one letter. You may ask yourself a number of questions, possibly starting with (1) Is this the Jane Drew I’m interested in? and then (2) What is the relationship between Jane Drew and John and Myfanwy Piper? You may well be able to find answers by accessing the letter itself, but at this stage you may just want to place this connection in the broader context of Jane Drew’s life and work. As a researcher, understanding how these people are connected may shed light on your research interests.
In this blog I want to think about this question of relationships. The fact is that archivists rarely provide structured information about relationships; if there is information, it is usually in the biographical history, which might outline key events and people in someone’s life, referring to their parents, work colleagues, friends, etc. The nature of the relationship is sometimes explicitly given, but often it is not. Our standards don’t really say much about relationships between the entities (people, organisations, places, etc) that we describe in our catalogues.
Going back to the Papers of John and Myfanwy Piper as an example, the biographical history includes the following:
[John] Piper began writing reviews from the late 1920s making a name for himself as a critic writing for periodicals like ‘The Listener’ and the ‘Architectural Review’. From 1935-1937 he assisted Myfanwy Evans, with the production of a quarterly review of contemporary European abstract painting called ‘Axis’. In 1937 Piper was commissioned by his friend John Betjeman to write the ‘Shell Guide to Oxfordshire’. Piper went on to write and provide photographs for a number of the guides as well as edit the series. In the same year John Piper married the writer Myfanwy Evans.
This is a typical of a biographical history – useful historical information about the individual or organisation. Within this there is information we can potentially use to create explicit relationship information:
John Piper ‘worked with’ Myfanwy Evans
John Piper ‘was friends with’ John Betjeman
John Piper ‘worked for’ John Betjeman
John Piper ‘was married to’ Myfanwy Evans
There are a number of issues to consider here:
How can we unambiguously identify the people?
How do we choose the vocabulary we use to define the relationships?
Do we try to include dates?
Is it reasonable for us to interpret relationships as ‘friendships’ or ‘collaborations’ if this is not actually explicit?
We are looking at some of these issues through our AHRC project, Exploring British Design. They are all issues that archivists need to explore in a debate around relationship information, but the first issue to consider is simply whether we should be thinking more about including this kind of relationship information in our archival finding aids. Is it something that would be of real value to end users? This issue is coming more to the fore as we start to think about implementing ISAAR (CPF) and working with EAC-CPF , and also as Linked Open Data gains traction.
In a (well worth reading) recent article in the Journal of Contemporary Archival Studies, on the potential impact of EAC-CPF, K.M Wisser reports the findings of a survey about relationship information. The survey received 208 responses from archivists/archives in the US. Wisser wrote “The survey results indicate that the archival community has only just begun to consider relationships in the context of archival description and the role that explicit description of those relationships may play.”
As one respondent wrote:
“relationships are among the most important facets in a collection and deserve a high priority in description. One cannot understand the historical value of an event, person, or organization without knowing [the] relationship among and between them.”
One thing that really strikes me in Wisser’s findings is that archivists see relationships that are documented outside of the collection as almost as significant as those that are documented within the collection. Going back to our original topic of Jane Drew: who else did Jane Drew work with? Should we provide that information to our users, whether or not it is documented within the collection? Is our role to give as full an account as we can of Drew’s life and career? Is it to limit ourselves to what is within the collection?
Wisser’s survey asked respondents about the importance of relationship types. It is curious to me that archivists rated ‘collaborated with’ as a more important relationship than ‘studied with’; they rated a friendship as far more important when it was documented in the collection; and they rated ‘influenced by’ as generally not so important. I’m surprised that the respondents had such definite ideas about the relative importance of different types of relationships, especially when the majority appeared to agree with the importance of ‘objective cataloguing’.
In our Exploring British Design project, the work we did with researchers definitely confirmed to me the fairly self-evident observation that any relationship can be of major significance in research, even if it appears of minor significance within the archive, or indeed, within the literature in general. A brief collaboration may have been a crucial influence, a short friendship may have had hitherto unrealised impact, and anyway, the importance of the relationship depends upon the research you are doing. Researchers are not really aware of how challenging it is for us as information professionals to establish these kinds of relationships in ways that they can then access. But it is clear that this is the sort of connectivity they are after.
One of the challenges with documenting relationship types is that they can be hard to define. As Wisser notes:
“The concept of influence, however, proved the most problematic. Comments such as ‘influence is a squishy sort of relationship’ and ‘I think it would often be very difficult to prove that Entity A was influenced by Entity B’ indicate a notion of intangibility.”
The conclusion could be that we should leave well alone relationships that are hard to define. On the other hand, if we are in a position, as we research a collection, to highlight potential connections, that action could be of major value to a researcher, who may otherwise never know about a link that ends up being crucial to their particular research. The relationships that are easy to define are likely to have been defined already.
One thing that strikes me about the whole notion of introducing interpretation and opinion into cataloguing (a possible argument against defining relationships) is that the horse has pretty much bolted. I’ve looked at enough ‘objective’ descriptions to be aware that the names archivists choose to add as index terms are a choice; they inevitably have to be an opinion about the names significant enough to add as index terms. And subjects are a similar case – some collections are indexed thoroughly, some not at all.
Aside from indexing, each person would create a different scope and content entry, including and excluding different information, and whether you call that subjective or not, it is certainly always selective. You could also argue that the level of detailed hierarchical cataloguing, might indicate the relative importance of the collection. On the Archives Hub there are some collections catalogued in huge detail, and it is inevitable that researchers will assume these collections are particularly important.
All of these choices have implications for discoverability.
In Wisser’s survey, a significant proportion of respondents felt that the importance of a relationship should be based upon the use of the collection. But this, again, raises the question: When thinking about relationships, is the cataloguer reflecting the scope of the collection, or are they trying to give as full a picture as they can of the person or organisation? Are we within the world of the collection; or is the collection within the world?
The reason that I believe that we should think beyond the bounds of the collection content is that I think it promises much richer rewards for our users and encourages archives to be a major player within a broader landscape of information resources. I base my thinking on the premise that the researcher is primarily interested in their research topic, which is not likely to be an archive collection per se, but rather an event, a person, an organisation, a subject, and the way things are connected. I think archivists are still tending to think in terms of a document that describes a collection, rather than how to link the collection into the cultural heritage landscape, and even more broadly beyond that. I wonder if archivists don’t always think beyond the catalogues they currently create because the researchers they have contact with (who visit the archive) are already fairly confident they want to use that repository, or a particular archive within that repository. In other words, the researcher is already in their space. When I worked in a specialist archive, I thought about researchers discovering our archive as a whole (having an online presence) and then I thought about them using our collections (individual collections each with their own description); I didn’t think about how our collections could be seen as part of a whole information landscape.
The loudest – and most convincing – argument I hear against this kind of approach is that it takes time, and archivists are short on time. But I wonder if that means we have to think fundamentally differently. Going back to Jane Drew, and think about the value of relationships for research into her life and work…
If one archive collection description highlights just a few relationships, this could take us a long way (although relationship types are a whole different thing…). If the individuals and organisations are unambiguously identified, this can help with the process of creating links out to other data sources, so that information can be linked together; then we have the chance to benefit from finding out about relationships that have been defined elsewhere. In other words, the connections one person has throughout their life can only be fully realised through the pooling of information resources, very much a joint effort. If the data is structured it can potentially be brought together.
Traditional archival cataloguing focuses on the collection, and what is documented within the collection. It tends to think in terms of a self-contained document. Pursuing relationships breaks the bounds of any one information source. That seems like a good thing, but it raises questions around approaches to cataloguing. One obvious way to tackle this is to start to think more about archival authority records. These should enable us to move beyond a collection-centric description of the collection and towards a more entity based approach, because you describe an agent (entity) independently of any one archival collection. Another option is to think in a Linked Data way, where you are concentrating on entities and relationships.
There are so many questions raised by the whole area of entities and relationships. A few of my current conclusions are:
We should primarily be led by what benefits research. Researchers are far less likely to think in terms of individual archive collections, and far more likely to think in terms of research areas (topics). The Web gives us the opportunity to think in a broader context.
Maybe it is worth considering taking some of the time used to provide a really detailed biographical history as an unstructured narrative, or the time to provide a really detailed multi-level description, and taking more time to provide (or provide the potential for) connections between our descriptions and the larger information environment. This could allow researchers to bring together much more comprehensive information, even if what we provide about individual collections is less detailed. Just adding something like a VIAF identifier to a name would be a great big leap forwards (http://viaf.org/viaf/51792789).
There is great value in being a small fish in a big pond, because most researchers are fishing for data in the big pond. As Wisser’s article says, “relationships are…seen to free collections from the isolation of individual repositories.” If we aim to be part of the big pond, we can continue to tend our smaller ponds as well!
To go back to the Piper Collection and Jane Drew….I used this as a random example, thinking of a researcher interested in one particular designer. But of course, the Tate Gallery Archive can’t be expected to define all the relationships within the description. It’s great that they have provided enough detail to find this one individual item – without that, we would not know about the connection with Jane Drew. I’m arguing for unambiguously identifying entities (people, organisations) because if we can potentially link this instance of ‘Jane Drew’ to other instances in other information sources, then it is very possible that we can find out more about this relationship; And if the relationship can’t be established through other sources, then maybe this archive provides unique evidence of a connection that could significantly benefit research.
We recently ran a second workshop as part of our Exploring British Design project. The workshops aim to understand more about approaches to research, and researchers’ understanding and use of archives.
The second workshop was run largely on the same basis as the first workshop, using the same exercises.
Looking at what our researchers said and documented about their research paths over the two workshops, some points came out quite strongly:
Google is by far the most common starting point but its shortcomings are clear and issue of trust come up frequently.
There is often a strong visual emphasis to research, including searching for images and the use of Pinterest; there seems to be a split between those who gravitate towards a more text-based approach and those who think visually (many of our participants were graphic designers though!).
It is common to utilise the references listed in Wikipedia articles.
The library as a source is seen as part of a diverse landscape – it is one place to go to, albeit an important one. It is not the first port of call for the majority.
Aggregators are not specifically referred to very often. But they may be seen as a place to go if other searches don’t yield useful results.
Talking to people is very important, be it lecturers, experts, colleagues or friends
Online research is more immediate, and usually takes less effort, but there are issues of trust and it may not yield specific enough results, or uncover the more obscure sources.
There is a tendency to start from the general and work towards the more specific. With the research paths of most of the researchers, the library/archive was somewhere in the middle of this process.
Personal habits and past experience play a very large part, but there is a real interest in finding new routes through research, so habit is not a sticking point, but simply the dominant influence unless it is challenged.
For the second workshop, the first exercise asked participants to document their likely research paths around a topic.
Research paths of two researchers for the topic of Simpsons of Piccadilly
We had four pairs of researchers looking at different topics, and we left them to discuss their research paths for about 45 minutes. The discussions following the exercise picked up on a number of areas:
Online vs Offline
We kicked off by asking the researchers about online versus ‘offline’ research paths. One participant commented that she saw online as a route through to traditional research – maybe to locate a library or archive – ‘online is telling me where to look’ but in itself it is too general and not specific enough; whereas the person she was paired with tended to do more research online. He saw online as giving the benefit of immediacy – at any time of day or night he could access content. The issue of trust came up in the discussion around this issue, and one participant summed up nicely: “If you do online research there is less effort but there is less trust; if you research offline there is more effort but there is more trust.”
Following on from the discussion about how people go about using online services, there was a comment that things found online are often the more obvious, the more used and cited resources. Visiting a library or archive may give more opportunity to uncover little known sources that help with original research. This seemed to be endorsed by most participants, one commenting that Pinterest tends to reflect what is trendy and popular. However, there was also a view that something like Pinterest can lead researchers to new sources, as they are benefiting from the efforts, and sometimes the quite obsessive enthusiasms, of a wide range of people.
There was agreement that online research can lead to ‘information dumping’, where you build up a formidable collection of resources, but are unlikely to get round to sorting them all out and using them.
Library Resources
The issue of effort came up later in the discussion when referring to a particular university library (probably typical of many university libraries), and the amount of effort involved in using its databases. There was a comment about how you need to ‘work yourself up to an afternoon in the library’ and there seemed to be a general agreement that the ‘search across all resources’ often produced quite meaningless results. When compared to Google, the issue seems to be that relevance ranking is not effective, so the top results often don’t match your requirements. There was also some discussion around the way that library resource discovery services often involve too many steps, and there is effort in understanding how the catalogue works. One participant, whose research centres on the Web and the online user experience, felt that printed sources were of little use to him, as they were out of date very quickly.
Curating your sources
One researcher talked about using Pinterest to organise findings visually. This was followed up by another researcher talking about how with online research you can organise and collect things yourself. It facilitates ‘curating’ your own collection of resources. It can also be easier to remember resources if they are visual. Comparing Pinterest to the Library – with the former you click to add the image to your board; with the Library you pay a visit, you find the book, you take it to the scanner, you pay to take a scan…although it is increasingly possible to take pictures of books using your own device. But the general feeling was that the Web was far quicker and more immediate.
Attitudes towards research
One participant felt that there might be a split between those more like him who see research as ‘a means to an end’ and those who enjoy the process itself. So maybe some are looking for the shortest route to the end goal, and others see research as more exploratory activity and expect it to take time and effort. This may partly be a result of the nature and scope of the research. Short time scales preclude in-depth research.
Talking about serendipitous approaches, someone commented that browsing the library shelves can be constructive, as you can find books around your subject that you weren’t aware existed. This is replicated to some extent in something like Amazon, which suggests books you might be interested in. There was also some feeling that exploring too many avenues can take the researcher off topic and take up a great deal of time.
Trust and Citation
The issue of trust is important. A first-hand experience, whether of a place you are researching, or using physical archive sources, is the most trustworthy, because you are seeing with your own eyes, experiencing first hand or looking at primary sources first hand; a library provides the next level of trust, as a book is an interpretation, and you may feel it requires corroboration; the online world is the least trustworthy. You will have the least trust if you are looking at a website where you don’t know about who or what is behind it. There was agreement that trust can come through crowd sourced information, but also some discussion around how to cite this (for example, using the Harvard system to reference web pages and crowd sourced resources). This led on to a short discussion around the credibility of what is cited within research. Maybe attitudes to Wikipedia are slowly changing, but at present there is generally still a feeling that a researcher cannot cite it as a source. There are traditions within disciplines around how to cite and what are the ‘right’ things to cite.
[Further posts on Exploring British Design will follow, with reflections on our workshops and updates on the project generally]
As part of our Exploring British Design project we are organising workshops for researchers, aiming to understand more about their approaches to research, and their understanding and use of archives. Our intention is to create an interface that reflects user requirements and, potentially, explores ideas that we gather from our workshops.
Of course, we can only hope to engage with a very small selection of researchers in this way, but our first workshop at Brighton Design Archive showed us just how valuable this kind of face-to-face communication can be.
We gathered together a small group of 7 postgraduate design students. We divided them into 4 groups of 2 researchers and a lone researcher, and we asked them to undertake 2 exercises. This post is about the first exercise and follow up discussion. For this exercise, we presented each group with an event, person or building:
The Festival of Britain, 1951
Black Eyes and Lemonade Exhibition, Whitechapel Art Gallery, 1951
Natasha Kroll (1912-2004)
Simposons of Piccadilly, London
We gave each group a large piece of paper, and simply asked them to discuss and chart their research paths around the subject they had been given. Each group was joined by a facilitator, who was not there to lead in any way, but just to clarify where necessary, listen to the students and make notes.
Case Study
Researchers charting their research paths for the Festival of Britain
I worked with two design students, Richard and Caroline, both postgraduate students researching aspects of design at The University of Brighton. They were looking at the subject of the Festival of Britain (FoB). It fascinated me that even when they were talking about how to represent their research paths, one instinctively went to list their methods, the other to draw theirs, in a more graphic kind of mind map. It was an immediate indication of how people think differently. They ended up using the listing method (see left).
Potential research paths for the Festival of Britain
The above represents the research paths of Richard and Caroline. It became clear early on that they would take somewhat different paths, although they went on to agree about many of the principles of research. Caroline immediately said that she would go to the University library first of all and then probably the central library in Brighton. It is her habit to start with the library, mainly because she likes to think locally before casting the net wider, she prefers the physicality of the resources to the virtual environment of the Web. She likes the opportunity to browse, and to consider the critical theory that is written around the subject as a starting point. Caroline prefers to go to a library or archive and take pictures of resources, so that she can then work through them at her leisure. She talked about the importance of being able to take pictures, in order to be able to study sources at her leisure, and how high charges for the use of digital cameras can inhibit research.
Richard started with an online search. He thought about the sort of websites that he would gravitate towards – sites that were directly about the topic, such as an exhibition website. He referred to Wikipedia early on, but saw it as a potential starting place to find links to useful websites, through the external links that it includes, rather than using the content of Wikipedia articles.
Richard took a very visual approach. He focused in on the FoB logo (we used this as a representation of the Festival) and thought about researching that. He also talked about whether the FoB might have been an exhibition that showcased design, and liked the idea of an object-based approach, researching things such as furniture or domestic objects that might have been part of the exhibition. It was clear that his approach was based upon his own interests and background as a film maker. He focused on what interested and excited him; the more visual aspects including the concrete things that could be seen, rather than thinking in a text-based way.
Caroline had previous experience of working in an archive, and her approach reflected this, as well as a more text-based way of thinking. She talked about a preference for being in control of her research, so using familiar routes was preferable. She would email the Design Archives at Brighton, but that was not top of the list because it was more of an unknown quantity than the library that she was used to. Maybe because she has worked in an archive, she referred to using film archives for her research; whereas Richard, although a film maker, did not think of this so readily. Past experience was clearly important here.
Both researchers saw the library as a place for serendipitous research. They agreed that this browsing approach was more effective in a library than online. They were clearly attracted to the idea of searching the library shelves, and discovering sources that they had not known about. I asked why they felt that this was more effective than an online exploration of resources. It seemed to be partly to do with the dependency of the physical environment and also because they felt that the choice of search term online has a substantial effect on what is, and isn’t, found.
Both researchers were also very focused on issues of trust; both very much of opinion that they would assess their sources in terms of provenance and authorship.
In addition, they liked the idea of being able to search by user-generated tags and to have the ability to add tags to content.
General Discussion
In the general discussion some of the point made in the case study were reinforced. In summary:
Participants found the exercise easy to do. It was not hard to think about how they would research the topics they were given. They found it interesting to reflect on their research paths and to share this with others.
For one other participant the library was the first port of call, but the majority started online.
Some took a more historical approach, others a much more narrative and story-based approach. There were different emphases, which seemed to be borne out of personality, experiences and preferences. For example, some thought more about the ordering of the evidence, others thought more about what was visually stimulating.
It was therefore clear that different researchers took different approaches based on what they were drawn to, which usually reflected their interests and strengths.
There was a strong feeling about trust being vital when assessing sources. Knowing the provenance of an article or piece of writing was essential.
The participants agreed that putting time and effort into gathering evidence is part of the enjoyment of research. One mentioned the idea that ‘a bit of pain’ makes the end result all the more rewarding! They were taken aback at the idea that that discovery services feel pressured to constantly simplify in order to ensure that we meet researchers’ needs. They understood that research is a skill and a process that takes time and effort (although, of course, this may not be how the majority of undergraduates or more inexperienced researchers feel). Certainly they agreed that information must not be withheld, it must be accessible. We (service providers) need to provide signposts, to allow researchers to take their own paths. There was discussion about ‘sleuthing’ as part of the research process, and trying unorthodox routes, as chance discoveries may be made. But there was consensus that researchers do not need or wish to be nannnied!
All researchers did use Google at some point….usually using it to start their search. Funnily enough, some participants had quite long discussions about what they would do, before they realised they would actually have gone to Google first of all. It is so common now, that most people don’t think about it. It seemed to operate very much as a as a starting point, from where the researchers would go to sites, assess their worth and ensure that the information was trustworthy.
[There will be follow up posts to this, providing more information about our researcher workshops, summarising the second activity, which was more focused on archive sources, and continuing to document our Exploring British Design project.]
In the ArchivesGrid analysis, the <unitdate> field use is around 72% within the high-level (usually collection level) description. The Archives Hub does significantly better here, with an almost universal inclusion of dates at this level of description. Therefore, a date search is not likely to exclude any potentially relevant descriptions. This is important, as researchers are likely to want to restrict their searches by date. Our new system also allows sorting retrieved results by date. The only issue we have is where the dates are non-standard and cause the ordering to break down in some way. But we do have both displayed dates and normalised dates, to enable better machine processing of the data.
Collection Title
“for sorting and browsing…utility depends on the content of the element.”
Titles are always provided, but they are very varied. Setting aside lower-level descriptions, which are particularly problematic, titles may be more or less informative. We may introduce sorting by title, but the utility of this will be limited. It is unlikely that titles will ever be controlled to the extent that they have a level of consistency, but it would be fascinating to analyse titles within the context of the ways people search on the Web, and see if we can gauge the value of different approaches to creating titles. In other words, what is the best type of title in terms of attracting researchers’ attention, search engine optimisation, display within search engine results, etc?
Lower-level descriptions tend to have titles such as ‘Accounts’, ‘Diary’ or something more difficult to understand out of context such as ‘Pigs and boars’ or ‘The Moon Dragon’. It is clearly vital to maintain the relationship of these lower-level descriptions to their parent level entries, otherwise they often become largely meaningless. But this should be perfectly possible when working on the Web.
It is important to ensure that a researcher finding a lower-level description through a general search engine gets a meaningful result.
A search result within Google
The above result is from a search for ‘garrick theatre archives joanna lumley’ – the sort of search a researcher might carry out. Whilst the link is directly to a lower -level entry for a play at the Garrick Theatre, the heading is for the archive collection. This entry is still not ideal, as the lower-level heading should be present as well. But it gives a reasonable sense of what the researcher will get if they click on this link. It includes the <unitid> from the parent entry and the URL for the lower-level, with the first part of the <scopecontent> for the entry. It also includes the Archives Hub tag line, which could be considered superfluous to a search for Garrick Theatre archives! However, it does help to embed the idea of a service in the mind of the researcher – something they can use for their research.
Extent
“It would be useful to be able to sort by size of collection, however, this would require some level of confidence that the <extent> tag is both widely used and that the content of the tag would lends itself to sorting.”
This was an idea we had when working on our Linked Data output. We wanted to think about visualizations that would help researchers get a sense of the collections that are out there, where they are, how relevant they are, and so on. In theory the ‘extent’ could help with a weighting system, where we could think about a map-based visualization showing concentrations of archives about a person or subject. We could also potentially order results by size – from the largest archive to the smallest archive that matches a researchers’ search term. However, archivists do not have any kind of controlled vocabulary for ‘extent’. So, within the Archives Hub this field can contain anything from numbers of boxes and folders to length in linear metres, dimensions in cubic metres and items in terms of numbers of photographs, pamphlets and other formats. ISAD(G) doesn’t really help with this; the examples they give simply serve to show how varied the description of extent can be.
Genre
“Other examples of desired functionality include providing a means in the interface to limit a search to include only items that are in a certain genre (for example, photographs)”.
This is something that could potentially be useful to researchers, but archivists don’t tend to provide the necessary data. We would need descriptions to include the genre, using controlled vocabulary. If we had this we could potentially enable researchers to select types of materials they are interested in, or simply include a flag to show, e.g. where a collection includes photographs.
The problem with introducing a genre search is that you run the risk of excluding key descriptions, because the search will only include results where the description includes that data in the appropriate location. If the word ‘photograph’ is in the general description only then a specific genre search won’t find it. This means a large collection of photographs may be excluded from a search for photographs.
Subject
In the Bron/Proffitt/Washburn article <controlaccess> is present around 72% of the time. I was surprised that they did not choose to analyse tags within <controlaccess> as I think these ‘access points’ can play a very important role in archival descrpition. They use the presence of <controlaccess> as an indication of the presence of subjects, and make the point that “given differences in library and archival practices, we would expect control of form and genre terms to be relatively high, and control of names and subjects to be relatively low.”
On the Archives Hub, use of subjects is relatively high (as well as personal and corporate names) and use of form and genre is very low. However, it is true to say that we have strongly encouraged adding subject terms, and archivists don’t generally see this as integral to cataloguing (although some certainly do!), so we like to think that we are partly responsible for such a high use of subject terms.
Subject terms are needed because they (1) help to pull out significant subjects, often from collections that are very diverse, (2) enable identification of words such as ‘church’ and ‘carpenter’ (ie. they are subjects, not surnames), (3) allow researchers to continue searching across the Archives Hub by subject (subjects are all linked to the browse list) and therefore pull collections together by theme (4) enable advanced searching (which is substantially used on the Hub).
Names (personal and corporate)
In Bron/Proffitt/Washburn the <origination> tag is present 87% of the time. The analysis did not include the use of <persname> and <corpname> within <origination> to identify the type of originator. In the Archives Hub the originator is a required field, and is present 99%+ of the time. However, we made what I think is a mistake in not providing for the addition of personal or corporate name identification within <origination> via our EAD Editor (for creating descriptions) or by simply recommending it as best practice. This means that most of our originators cannot be distinguished as people or corporate bodies. In addition, we have a number where several names are within one <origination> tag and where terms such as ‘and others’, ‘unknown’ or ‘various’ are used. This type of practice is disadvantageous to machine processing. We are looking to rectify it now, but addressing something like this in retrospect is never easy to do. The ideal is that all names within origination are separately entered and identified as people or organisations.
We do also have names within <controlaccess>, and this brings the same advantages as for <subjects>, ensuring the names are properly structured, can be used for searching and for bringing together archives relating to any one individual or organisation.
Repository
“Use of this element falls into the promising complete category (99.46%: see Table 7). However, a variety of practice is in play, with the name of the repository being embellished with <subarea> and <address> tags nested within <repository>.”
On the Archives Hub repository is mandatory, but as yet we do not have a checking system whereby a description is rejected if it does not contain this field. We are working towards something like this, using scripts to check for key information to help ensure validity and consistency at least to a minimum standard. On one occasion we did take in a substantial number of descriptions from a repository that omitted the name of repository, which is not very useful for an aggregation service! However, one thing about <repository> is that it is easy to add because it is always the same entry. Or at least it should be….we did recently discovery that a number of repositories had entered their name in various ways over the years and this is something we needed to correct.
Scope and content, biographical history and abstract
It is notable that in the US <abstract> is widely used, whereas we don’t use it at all. It is intended as a very brief summary, whereas <scopecontent> can be of any length.
“For search, its worth noting that the semantics of these elements are different, and may result in unexpected and false “relevance””
One of the advantages of including <controlaccess> terms is to mitigate against this kind of false relevance, as a search for ‘mason’ as a person and ‘mason’ as a subject is possible through restricted field searching.
The Bron/Proffitt /Washburn analysis shows <bioghist> used 70% of the time. This is lower than the Archives Hub, where it is rare for this field not to be included. Archivists seem to have a natural inclination to provide a reasonably detailed biographical history, especially for a large collection focussed on one individual or organisation.
Digital Archival Objects
It is a shame that the analysis did not include instances of <dao>, but it is likely to be fairly low (in line with previous analysis by Wisser and Dean, which puts it lower than 10%). The Archives Hub currently includes around 1,200 instances of images or links to digital content. But what would be interesting is to see how this is growing over time and whether the trajectory indicates that in 5 years or so we will be able to provide researchers with routes into much of the Archives Hub content. However, it is worth bearing in mind that many archives are not digitised and are not likely to be digitised, so it is important for us not to raise expectations that links to digital content will become a matter of course.
The Future of Discovery
“In order to make EAD-encoded finding aids more well suited for use in discovery systems, the population of key elements will need to be moved closer to high or (ideally) complete.”
This is undoubtedly true, but I wonder whether the priority over and above completeness is consistency and controlled vocabulary where appropriate. There is an argument in favour of a shorter description, that may exclude certain information about a collection, but is well structured and easier to machine process. (Of course, completeness and consistency is the ideal!).
The article highlights geo-location as something that is emerging within discovery services. The Archives Hub is planning on promoting this as an option once we move to the revised EAD schema (which will allow for this to be included), but it is a question of whether archivists choose to include geographical co-ordinates in their catalogues. We may need to find ways to make this as easy as possible and to show the potential benefits of doing so.
In terms of the future, we need a different perspective on what EAD can and should be:
“In the early days of EAD the focus was largely on moving finding aids from typescript to SGML and XML. Even with much attention given over to the development of institutional and consortial best practice guidelines and requirements, much work was done by brute force and often with little attention given to (or funds allocated for) making the data fit to the purpose of discovery.”
However, I would argue that one of the problems is that archivists sometimes still think in terms of typescript finding aids; of a printed finding aid that is available within the search room, and then made available online….as if they are essentially the same thing and we can use the same approach with both. I think more needs to be done to promote, explain and discuss ‘next generation finding aids’. By working with Linked Data, I have gained a very different perspective on what is possible, challenging the traditional approach to hierarchical finding aids.
Maybe we need some ‘next generation discovery’ workshops and discussions – but in order to really broaden our horizons we will need to take heed of what is going on outside of our own domain. We can no longer consider archival practice in isolation from discovery in the most general sense because the complexity and scale of online discovery requires us to learn from others with expertise and understanding of digital technologies.
The recent Digital Humanities @ University of Manchester conference presented research and pondered issues surrounding digital humanities. I attended the morning of the conference, interested to understand more about the discipline and how archivists might interact with digital humanists, and consider ways of opening up their materials that might facilitate this new kind of approach.
Visualisation within digital humanities was presented in a keynote by Dr Massimo Riva, from Brown University. He talked about the importance of methodologies based on computation, whether the sources are analogue or digital, and how these techniques are becoming increasingly essential for humanities. He asked whether a picture is worth one million words, and presented some thought-provoking quotes relating to visualisation, such as a quote by John Berger: “The relation between what we see and what we know is never settled.” (John Berger, Ways of Seeing, 1972).
Riva talked about how visual projection is increasingly tied up with who we are and what we do. But is digital humanities translational or transformative? Are these tools useful for the pursuit of traditional scholarly goals, or do they herald a new paradigm? Does digital humanities imply that scholars are making things as they research, not just generating texts? Riva asked how we can combine close reading of individual artifacts and ‘distant reading’ of patterns across millions of artifacts. He posited that visualisation helps with issues of scale; making sense of huge amounts of data. It also helps cross boundaries of language and communication.
Riva talked about the fascinating Cave Writing at Brown University, a new kind of cognitive experience. It is a four-wall, immersive virtual reality device, a room of words. This led into his thoughts about data as a type of artifact and the nature of the archive.
“On the cusp of the twenty–first century…we speak of an ex–static archive, of an archive not assembled behind stone walls but suspended in a liquid element behind a luminous screen; the archive becomes a virtual repository of knowledge without visible limits, an archive in which the material now becomes immaterial.” This change “has altered in still unimaginable ways our relationship to the archive”. (Voss & Werner, 1999)
The Garibaldi panorama is a 276 feet long, a panorama that tells the story of Garibaldi, the Italian general and politician. It is fragile and cannot be directly consulted by scholars. So, the whole panorama was photographed in 91 digital images in 2007. The digital experience is clearly different to the physical experience. But the resulting digital panorama can be interacted with it many various ways and it is widely available via the website along with various tools to help researchers interpret the panorama. It is interesting to think about how much this is in itself a curated experience, and how much it is an experience that the user curates themselves. Maybe it is both. If it is curated, then it is not really the archivists who are curators, but those who have created the experience those with the ability to create such technical digital environments. It is also possible for students to create their own resources, and then for those resources to become part of the experience, such as an interactive timeline based on the panorama. So, students can enhance the metadata as a form of digital scholarship.
Riva showed an example of a collaborative environment where students can take parts of the panorama that interests them and explore it, finding links and connections and studying parts of the panorama along with relevant texts. It is fascinating as an archivist to see examples like this where the original archive remains the basis of the scholarly endeavour. The artifact is at a distance to the actual experience, but the researcher can analyse it to a very detailed level. It raises the whole debate around the importance of studying the original archive. As tools and environments become more and more sophisticated, it is possible to argue that the added value of a digital experience is very substantial, and for many researchers, preferable to handling the original.
Riva talked about the learning curve with the software. Scholars struggled to understand the full potential of it and what they could do and needed to invest time in this. But an important positive was that students could feedback to the programmers, in order to help them improve the environment.
We had short presentations on a diverse range of projects, all of which showed how digital humanities is helping to reveal history to us in many ways. Dr Guyda Armstrong made the point that library catalogues are more than they might seem – they are a part of cultural history. This is reflected in a bid for funding for a Digging into Data project, metaSCOPE, looking at bibliographical metadata as datamassive cultural history. The questions the project hopes to answer are many: how are different cultures expressed in the data? How do library collections data reflect the epistemic values, national and disciplinary cultures and artifacts of production and dissemination expressed in their creation? This project could help with mapping the history of publishing in space and time, as well as showing the history of one book over time.
We saw many examples of how visual work and digital humanities approaches can bring history to life and help with new understanding of many areas of research. I was interested to hear how the mapping of the Caribbean during the 18th century opened up the coastline to the slave traders, but the interior, which was not mapped in any detail, remained in many ways a free area, where the slave traders did not have control. The mapping had a direct influence on many people’s lives in very fundamental ways.
Another point that really stood out to me was the danger of numbers averaging out the human experience – a challenge with digital humanities approach, as, at the same time, numbers can give great insights into history. Maybe this is a very good reason why those who create tools and those who use them benefit from a shared understanding.
“All archaeological excavation is destruction”, so what actually lives on is the record you create, says Dr Stuart Campbell. Traditional monographs synthesize all the data. They represent what is created through the process of excavation. It is a very conventional approach. But things are changing and digital archiving creates new ways of working in the virtual world of archaeological data. Dr Campbell made the point that interpretation is often privileged over the data itself in traditional methods, but new approaches open up the data, allowing more narratives to be created. The process of data creation becomes apparent, and the approach scales up to allow querying that breaks out beyond the boundaries of archaeological sites. For example, he talked about looking at pattens on ancient pottery and plotting where the pottery comes from. New sophisticated tools allow different dimensions to be brought into the research. Links can now be created that bring various social dimensions to archeological discoveries, but the understanding of what these connections really represent is less well understood or theorised.
Seemingly a contrast to many of the projects, a project to recreate the Gaskell house in Manchester is more about the physical experience. People will be able to take books down from the shelves, sit down and read them. But actually there is a digital approach here too, as the intention is to add value to the experience by enabling visitors to leaf through digital copies of Gaskell’s works and find out more about the process of writing and publishing by showing different versions of the same stories, handwritten, with annotations, and published. It is enhancing the physical experience with a tactile experience through digital means.
To end the morning we had a cautionary tale about the vulnerability of Websites. A very impressive site, allowing users to browse in detail through an Arabic manuscript, is to be taken down, presumably because of changes in personnel or priorities at the hosting institution.The sustainability of the digital approach is in itself a huge topic, whether it be the data or the dissemination approaches.
What are the chief weapons we need to use to improve the user experience?
At ELAG 2013 I gave a presentation with a colleague from The University of Amsterdam, Lukas Koster. We wanted to do something entertaining, but with a worthwhile message that we both feel strongly about. We believe that more needs to be done to integrate resources and provide them to researchers in a way that suits end-user needs. We gave a presentation where we urged our colleagues to ‘mind the gap’ between the perspective of the information professional – their jargon and their complicated systems, which often fail to link resources adequately – and the researcher, who wants an integrated approach, language that is not a barrier to use and expects the power of the Web to be used within a library context, just as they might when looking for music online.
A researcher tries to make sense of the library systems
Our presentation included two sketches: one in a music shop, where a punter (the ‘seeker’) expects the shop owner (the ‘pusher’) to know who else bought this music and what they thought of if; and one in a library, where the seeker wants an overview of everything available, and they want to look at research data and other resources without struggling with different catalogue systems and terminology.
In our presentation we referred to the ‘seeker’ wanting a discipline-focussed approach (not format based), and access regardless of location. I highlighted one of the problems with searching by showing examples of search terms used on the Archives Hub where the researchers were confused by the results. The terms researchers use don’t always fit into our approach, using controlled vocabularies. We talked about the importance of connections between information. Our profession is making headway here, but there is a long way to go before researchers can really pull things together across different systems.
I spoke about the danger of making assumptions about our users and showed some examples of the Archives Hub survey results. Researchers don’t always come to our websites knowing what they are or what they want; they don’t necessarily have the same understanding of ‘archives’ as we do. Lukas expanded more on our musical theme. We can learn from some of the initiatives in this area – such as the ability people have to explore the musical world in so many different ways though things like MusicBrainz. Lukas also showed examples of researcher interfaces, looking to pull things together for the end user. Isn’t the idea of giving the researcher the ability to manage all of their research in this way something libraries should be spearheading?
A librarian contemplates the end of the index card…
We concluded that the vision of integrated, interconnected data is not easy. As information professionals we may have to move out of our comfort zones. But we don’t have any choice unless we want to be sidelined. This means that we need to change our mindsets (we talked about a ‘librarian lobe’!) and we need to actually think about whether it is us that needs to learn information literacy because we need to learn to think more like the end user!
The librarian has a frustrating time with a researcher who only wants one chapter!
A HEFCE study from 2010 states that “96% of students use the internet as a source of information” (1). This makes me wonder about the 4% that don’t; it’s not an insignificant number. The same study found that “69% of students use the internet daily as part of their studies”, so 31% don’t use it on a daily basis (which I take to mean ‘very frequently’).
There have been many reports on the subject of technology and its impact on learning, teaching and education. This HEFCE/NUS study is useful because it concentrates on surveying students rather than teachers or information professionals. One of the key findings is that it is important to think about the “effective use of technology” and “not just technology for technology’s sake”. Many students still find conventional methods of teaching superior (a finding that has come up in other studies), and students prefer a choice in how they learn. However, the potential for use of ICT is clear, and the need to engage with it is clear, so it is worrying that students believe that a significant number of staff “lack even the most rudimentary IT skills”. It is hardy surprising that the experiences of students vary considerably when they are partly dependent upon the skills and understanding of their teachers, and whether teachers use technology appropriately and effectively.
At the recent ELAG conference I gave a joint presentation with Lukas Koster, a colleague from the University of Amsterdam, in which we talked about (and acted out via two short sketches) the gap between researchers’ needs and what information professionals provide. Thinking simply about something as seemingly obvious as the understanding and use of
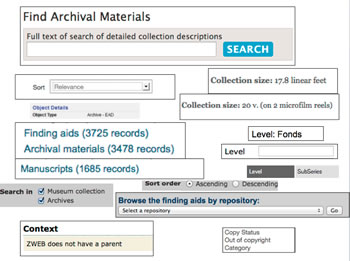
Random selection of interface terminology from archives sites.
the term ‘archives’ is a good case in point. Should we ensure that students understand the different definitions of archives? The distinction between archives that are collections with a common provenance and archives that are artificial collections? The different characters of archives that are datasets, generally used by social scientists? The “abuse” of the term archives for pretty much anything that is stored in any kind of longer-term way? Should users understand archival arrangement and how to drill down into collections? Should they understand ‘fonds’, ‘manuscripts’, ‘levels’, ‘parent collection’? Or is it that we should think more about how to translate these things into everyday language and simple design, and how to work things like archival hierarchy into easy-to-use interfaces? I think we should take the opportunities that technology provides to find ways to present information in such a way that we facilitate the user experience. But if students are reporting a lack of basic ICT skills amongst teachers, you have to wonder whether this is a problem within the archive and library sector as well. Do information professionals have appropriate ICT skills fit for ensuring that we can tailor our services to meet the needs of the technically savvy user?
Should we be teaching information literacy to students? One of the problems with this idea is that they tend to think they are already pretty literate in terms of use of the internet. In the HEFCE report, a survey of 213 FE students found that 88% felt they were effective online researchers and the majority said they were self-taught. They would not be likely to attend training on how to use the internet. And there is a question over whether they need to be taught how to use it in the ‘right’ way, or whether information professionals should, in fact, work with the reality of how it is being used (even if it is deemed to be ‘wrong’ in some way). Students are clear that they do want training “around how to effectively research and reference reliable online resources”, and maybe this is what we should be concentrating on (although it might be worth considering what ‘effective use of the internet’ and ‘effective research using the internet’ actually mean). Maybe this distinction highlights the problem with how to measure effective use of the internet, and how to define online or discovery skills.
A British Library survey from 2010 found that “only a small proportion [of students] …are using technology such as virtual-research environments, social bookmarking, data and text mining, wikis, blogs and RSS-feed alerts in their work.” This is despite the fact that many respondents in the survey said they found such tools valuable. This study also showed that students turn to their peers or supervisors rather than library staff for help.
Part of the problem may be that the vast majority of users use the internet for leisure purposes as well as work or study, so the boundaries can become blurred, and they may feel that they are adept users without distinguishing between different types of use. They feel that they are ‘fine with the technology’, although I wonder if that could be because they spend hours playing World of Warcraft, or use Facebook or Twitter every day, or regularly download music and watch YouTube. Does that mean they will use technology in an effective way as part of their studies? The trouble is that if someone believes that they are adept at searching, they may not go that extra mile to reflect on what they are doing and how effective it really is. Do we need to adjust our ways of thinking to make our resources more user-friendly to people coming from this kind of ‘I know what I’m doing’ mindset, or do we have to disabuse them of this idea and re-train them (or exhort them to read help pages for example…which seems like a fruitless mission)? Certainly students have shown some concern over “surface learning” (skim reading, learning only the minimum, and not getting a broader understanding of issues), so there is some recognition of an issue here, and the tendency to take a superficial approach might be reinforced if we shy away from providing more sophisticated tools and interfaces.
The British Library report on the Information Behaviour of the Researcher of the Future reinforces the idea that there is a gulf between students’ assumptions regarding their ICT skills versus the reality, which reveals a real lack of understanding. It also found a significant lack of training in discovery and use of tools for postgraduate students. Studies like this can help us think about how to design our websites, and provide tools and services to help researchers using archives. We have the challenges of how to make archives more accessible and easy to discover as well as thinking about how to help students use and interpret them effectively: “The college students of the open source, open content era will distinguish themselves from their peers and competitors, not by the information they know, but by how well they convert that knowledge to wisdom, slowly and deeply internalized.” (Sheila Stearns, “Literacy in the University of 2025: Still A Great Thing‟, from The Future of Higher Education , ed. by Gary Olson & John W Presley, (Boulder: Paradigm Publishers, 2009) pp. 98-99).
What are the Solutions?
We should make user testing more integral to the development of our interfaces. It requires resource, but for the Archives Hub we found that even carrying out 10 one-hour interviews with students and academics helped us to understand where we were making assumptions and how we could make small modifications that would improve our site. And our annual online survey continues to provide really useful feedback which we use to adjust our interface design, navigation and terminology. We can understand more about our users, and sometimes our assumptions about them are challenged.
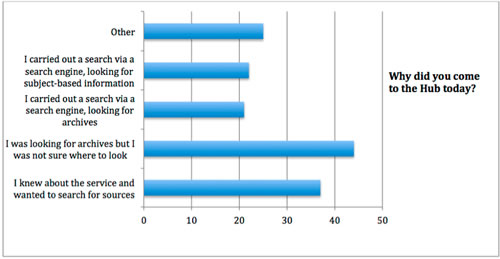
Archives Hub survey 2013: Why did you come to the Hub today?
User groups for commercial software providers can petition to ensure that out-of-the-box solutions also meet users’ needs and take account of the latest research and understanding of users’ experiences, expectations and preferences in terms of what we provide for them. This may be a harder call, because vendors are not necessarily flexible and agile; they may not be willing to make radical changes unless they see a strong business case (i.e. income may be the strongest factor).
We can build a picture of our users via our statistics. We can look at how users came into the site, the landing pages, where they went from there, which pages are most/least popular, how long they spent on individual pages, etc. This can offer real insights into user behaviour. I think a few training sessions on using Google Analytics on archive sites could come in handy!
We can carry out testing to find out how well sites rank on search engines, and assess the sort of experience users get when they come into a specialist site from a general search engine. What is the text a Google search shows when it finds one of your collections? What do people get to when they click on that link? Is it clear where they are and what they can do when they get to your site?
* * *
This is the only generation where the teachers and information professionals have grown up in a pre-digital world, and the students (unless they are mature students) are digital natives. Of course, we can’t just sit back and wait a generation for the teachers and information professionals to become more digitally minded! But it is interesting to wonder whether in 25 years time there will be much more consensus in approaches to and uses of ICT, or whether the same issues will be around.
Nigel Shadbolt has described the Web as “one of the most disruptive innovations we have ever witnessed” and at present we really seem to be struggling to find out how best to use it (and not use it), how and when to train people to use it and how and when to integrate it into teaching, learning and research in an effective way.
It seems to me that there are so many narratives and assessments at present – studies and reports that seem to run the gamut of positive to negative. Is technology isolating or socialising? Are social networks making learning more superficial or enabling richer discussion and analysis? Is open access democratising or income-reducing? Is the high cost of technology encouraging elitism in education? Does the fact that information is so easily accessible mean that researchers are less bothered about working to find new sources of information? With all these types of debates there is probably no clear answer, but let us hope we are moving forward in understanding and in our appreciation of what the Web can do to both enhance and transform learning, teaching and research.
This post picks out some highlights from a report from Ithaka S+R, “Supporting the Changing Research Practices of Historians” by Roger C Schonfeld and Jennifer Rutner (December 2012). It concentrates on findings that are of particular relevance for archivists and for discovery. The report is recommended reading. It is a US study, but clearly there are strong similarities with other countries.
The report finds that underlying research methods are still broadly as they were but practices have changed considerably: “Based on interviews with dozens of historians, librarians, archivists, and other support services providers, this project has found that the underlying research methods of many historians remain fairly recognizable even with the introduction of new tools and technologies, but the day to day research practices of all historians have changed fundamentally.”
It goes on to summarise the improvements that archives might make to meet changing needs, none of which are unexpected: “For archives, we recommend ongoing improvements to access through improved finding aids, digitization, and discovery tool integration, as well as expanded opportunities for archivists to help historians interpret collections, to build connections among users, and to instruct PhD students in the use of archives.”
It is very encouraging to see the positive comments about researchers’ interactions with archivists: “Having a meeting with the archivist and librarian is really fantastic, because they help you understand what is in the archive, and what you might be able to use.” It is clear from the study that archivists have a vital role to play as key collaborators and colleagues of historians, and their value is clear: “Archivists are often able to hone and direct an inquiry, bringing to light items and collections that the researcher may have been unaware of.”
The study does highlight the changing nature of interactions with archival material, as a result of the use of digital cameras in particular, which enables the analytical work to take place elsewhere. It is generally felt to be a convenient and time-saving option, enabling long-term interaction with resources outside of the reading room. This development is actually described as “the single most significant shift in research practices among historians.” It raises questions about whether the role of the archivist changes when the analytical work is displaced from the archive, as archivists may have less opportunity for intellectual engagement with researchers. The study does highlight a possible issue with digital copies, namely the separation of metadata from content, where the researcher has hundreds of images and needs to organise them constructively, and it also found that scholars are struggling to work with digitised non-textual content effectively.
The ability to find time for research trips was a primary challenge for many researchers. “Interviewees repeatedly emphasized that the amount of time they are able to spend in the archives shapes the nature of the interaction with the sources significantly.” Because most struggle to find time for research trips, digitised sources are hugely beneficial.
The study found that digitised finding aids help researchers to “travel more strategically”. It suggests that high-quality finding aids may become more important as researchers move more towards photographic visits to archives, rather than serendipitous visits. This connection is something I have not thought about before, and I would be very interested to hear what archivists think about this idea.
Of major relevance for a service like the Archives Hub is the conclusion about finding aids:
“The use of online finding aids greatly facilitates, and sometimes displaces, these visits. If a “good” finding aid is readily available online, this might make a scouting visit unnecessary, depending on the importance of the archive to the research project. In some cases, researchers were able to rule out a visit to an archive based on the online finding aids, and re-purpose funds and effort to tracking down other sources for the project.”
This study is a clear endorsement for our belief (which, I should say, is also backed up by our own researcher surveys) that finding aids play a role not only in identifying and prioritising sources, but also in providing enough information in themselves to make a visit unnecessary. As well as this, they may have a kind of positive negative effect: the researcher knows that materials can be ruled out. The study strongly emphasised the need for “searchable databases” and “centralized searching” and participants talked about the problem with locating each collection independently, especially across the diverse types of archive repository: “The process of identifying archives – in some cases small, local archives or international archives – can present an amazing challenge to researchers.” Clearly comprehensive cross-searching search tools are a huge boon to researchers.
In terms of discovery, Google is clearly a major tool and there was a feeling that it was the most comprehensive discovery tool, as well as being convenient and easy to use. It is often used at the start of a searching process.: “Generally, historians discover finding aids through Google searches and archive websites.” There is a clear demand for more descriptions online: “The general consensus among interviewees was that more online finding aids would greatly benefit their research, and that archives should continue to make efforts to make these accessible online. Continued and expanded efforts to develop finding aids more efficiently and to make them available digitally would seem to support the needs of historians for improved access.”
In terms of PhD students (and maybe others who are inexperienced researchers), the study found issues with the use of archives and other sources:
“Interviews with PhD candidates indicated that there is often little support for them in learning about new research methods or practices, either in their department or elsewhere at their institution, of which they are aware. While the subject matter treated by historians continues to diversify dramatically, new methodologies develop, and research practices change rapidly, it is clearly critically important that students have a grounding in the methods and practices of the field.” The Archives Hub has recently produced a brief Guide to Using Archives for the Inexperienced, and discussions on the archives email list showed just how much this is an important topic for archivists and how there was a general consensus that PhD students need more training on research methodologies.
Summing up, the report makes six recommendations specifically for Archives:
1. More online finding aids
2. More digitisation
3. Discovery tools that promote cross-searching, crossing institutional boundaries and encompassing small and local record offices
4. Adequate resources for ensuring the expertise of the archivist continues to be available, enabling archivists to be active interpreters of the collections
5. Adapting to and facilitating the use of digital cameras and scanners in reading rooms
6. Training PhD students in the use of archives
There is a great deal more of interest and relevance in the report around searching, Google Scholar, the use of the academic library, organising and managing research, citation management and digital research methods. It is very well worth reading.
It would not be an exaggeration to say that the history of voluntary, civic and cultural organisations has never been more popular as an academic subject in Britain. Leading historians like Brian Harrison have called attention to the importance of voluntarism as a theme in post-war British history while there has been a wave of PhD theses dealing with topics such as the voluntary hospitals, the role of disability charities in politics, the professionalization of the voluntary sector and the formation of humanitarian networks across empire. In 2011 no less than three edited collections presenting the latest research on voluntary action history were published and several further volumes appeared in 2012 or are in press. Such new research has been strengthened and sustained by the Voluntary Action History Society and particularly its active New Researchers group. Importantly, not all these studies are by historians, pointing to the importance of archival resources for students of political science, sociology, health studies and other disciplines. There is growing recognition that we cannot write British social history or social policy without looking at the considerable contributions of charities, voluntary groups, philanthropists, campaigners and volunteers.
So how do academic researchers track down the archives of the voluntary and community organisations they want to use? Any would-be researcher of charity needs to understand that those bodies with catalogued and accessible institutional archives – whether kept in-house or deposited elsewhere – represent only a very small minority of voluntary organisations. Unsurprisingly these tend to be the larger, better funded and longer-established groups such as the British Red Cross or the Children’s Society. The voluntary sector in Britain is often likened to a pyramid: a very small number of organisations at the top with paid staff, regular income and office space resting on a much larger base of groups run entirely by volunteers, subsisting on small grants and donations. Voluntary sector archives may reflect this pattern, but there is no guarantee that even the largest charity will have made provision for preservation and conservation of its records (aside from the limited financial data required by the Charity Commission) let alone for cataloguing or access.
Researchers and students are advised to start with the National Register of Archives. Another useful database is DANGO, which identifies the locations of the papers of several thousand non-governmental organisations, and was put together by a team at Birmingham University, although the end of project funding means its entries and website are no longer being updated. Searching the Archives Hub will find records of voluntary groups where these are deposited at an institution contained on its database; Hull History Centre, SOAS, Birmingham University Library or the Women’s Library have all built up specialisms in this area. Perhaps there would be a way of encouraging charities with in-house collections to make the catalogues available via Archives Hub?
Archives Hub has helped me search for materials relating to small or short-lived student-run charities that may be contained within a students’ union archive or an individual’s private papers. Although an organisation’s institutional archive may be lost or never have existed, its history can be reconstructed through accessing annual reports, correspondence and other papers held in many different repositories – as I have managed to do for the group International Student Service. It would be helpful for future researchers if it was possible to log this information somewhere.
It remains the case that many researchers will have to seek access to records by contacting an organisation or group founder directly, with variable results. This is likely to be increasingly the case given the increase in numbers of pressure groups, charities and other voluntary bodies since the 1960s. In my experience there is a range of practice from organisations which ignore or refuse requests for access with varying degrees of politeness to those that welcome you with open arms and let you sit unsupervised with the charity’s papers, free to copy, remove, deface or pour coffee all over the institutional record. Once you’ve had success accessing the records of one organisation, it may be easier to open communications with others in a related sector. Learning how to negotiate what we might call ‘informal archives’ will be a key challenge for future researchers of voluntary action. There is a need for better advice for academics, particularly students and new researchers, on the multiple ethical considerations and practical concerns that come with using informal archives. How do you track down such records? How do you reference sources? What do you do if you’re concerned about the physical state of records or what might happen to them when the group’s founder dies? How to reconcile your obligations as a historian with the fact that a particular organisation has trusted you to look at their materials?
It is also worth remembering that records relating to charitable activities can turn up in unexpected places, for example in the archives of private companies. The records of a charitable Trust or Foundation may well contain better sources about a particular charity than the organisation itself has preserved, although again there may be problems of access. There are good signs that this is changing not least through the positive examples of two funders involved with the new Campaign for Voluntary Sector Archives: the Barrow Cadbury Trust and the Diana, Princess of Wales Memorial Fund.
This new Campaign for Voluntary Sector Archives, which was launched at the House of Lords in October 2012, seeks to raise awareness of the importance of voluntary sector archives as strategic assets for governance, corporate identity, accountability and research. It maintains that caring for archives and records is actually an important aspect of the sector’s wider public benefit responsibility. Most significantly, the Campaign brings together academic researchers, custodians, creators of records and others in the voluntary sector to share expertise and resources. Together, we should be able to begin to address some of the issues and questions I’ve outlined above. Yet there is a long way to go before all voluntary organisations are convinced not only of the value of records to the current mission, but also of the value of making these accessible to researchers from a variety of disciplines. For more information contact info@voluntarysectorarchives.org.uk