Over the first half of this year we ran a series of training sessions remotely. We agreed on a set of sessions of 1.5 hours duration, reflecting the feedback we have had from our contributors and potential contributors about what they would like.
The sessions we organised were EAD Editor sessions – basic and ‘refresher’, exporting from Calm, exporting from AdLib, providing content using spreadsheets (Excel), using the CIIM, and a session on structure and names in archive descriptions. We also ran a session on user experience and behaviour, which was the first time we have organised a session not specifically about the Archives Hub, discoverability and data.
We have received feedback from 32 attendees. 100% of attendees agreed or strongly agreed that the sessions were worthwhile. 72% agreed that the content was excellent, 28% that it was very good or good. We had similar ratings for clarity, pace and organisation. So, overall, we are happy that the training provided met people’s needs and the sessions ‘hit the spot’.
Comments (paraphrased) included: it was easy to ask questions, focused and clear, it boosted my confidence, I am clear where I can go for help if needed, good to see export in action, presented in a relaxed manner and not too long, worked well to see the Editor on screen share, the speaker held my attention for the full 90 minutes. The session on user behaviour was well received, with comments on interesting speakers, good experience of their subject, a variety of perspectives. There is a short blog post on that session, with a link to the Zoom recording.
We asked if people would like to see us cover other topics in the future. There were a variety of suggestions, all of which we will consider. One suggestion was for a session on basic structuring and approaches to cataloguing, and this has been asked for a few times, so we will aim to run a session around this in the second half of the year. We were also asked for something on the benefits of being on the Archives Hub. We did used to incorporate this into our longer EAD Editor sessions, and it is worth thinking about making sure we do convey the benefits of increased discoverability and being part of the Hub community.
If there are areas that you would like us to cover, please do get in touch. We aim to provide training that meets the needs of the community – so we need your input!
We are also looking at running more sessions that bring together speakers from our community, such as the session on user experience and behaviour. We are planning a session on ‘machine learning’ in the not too distant future.
All sessions for contributors and potential contributors will be advertised through our contributors’ list, so do make sure you are on the list in order to find out about upcoming events. Email us at contributors.hub@jisc.ac.uk.
Remember that we also have YouTube videos for practical training on using the Editor and the CIIM and on exporting.
On 19 June we ran a webinar on user research and user behaviour. We had three speakers – David Marshall, a UX Researcher from the University of Cambridge, Kelly Arnstein, a UX Specialist from the University of Glasgow, and Deborah Wilson, a Subject Librarian from Queens University Belfast.
(main talks 1hr + 25 minute discussion). Slides are also provided as links (below).
The talks were excellent, and followed by a lively discussion. They should prove to be useful to anyone looking at designing a website for archive catalogues, and working with students using primary sources. Overall, there was a lot of consensus about user behaviour, which is useful in terms of sharing findings – because it is likely to be relevant to all archives. The emphasis for this session was on students and academic researchers, but we did discuss some of the challenges of meeting the needs of a diverse audience.
A few summary points that came out of one or more of the talks:
People may use an archive catalogue for research and also for teaching, scoping a project, marketing and other reasons.
They want an idea of the physicality of the collection and the overall size
People want context and hierarchy, and like the idea of ‘leafing through’ material to see relationships.
There are those who want to get quickly to what they need and those who value browse and serendipity. This seems like a possible tension, and certainly a challenge, in terms of interface design. It may be that at different times the same researcher wants a quick route through and other times they want to take time and discover.
Cambridge research found that some users wanted to limit their search by date initially, but there was a strong feeling that a wide search and then filtering was generally a good option.
Finding everything of value was seen as key – many researchers were prepared to spend time to discover materials related to their research and worried about missing important materials.
The physical object remains key to many researchers
Saving searches and other forms of personalisation were seen as a good thing
Quite often researchers, especially if they are more experienced, understand that research skills are important and archive catalogues are complex; this may contrast with library databases, where they are more inclined to want to get to things quickly.
Undergraduates often don’t understand the different approach needed to engage with primary sources
Undergrads often engage with archives at the point of an assignment, where they are being marked on their use of primary sources; they initially try to find sources in the same way as they would search for anything else.
It is really valuable to educate students on the importance of context, the broad search and filter approach, understanding citations, evaluating databases, etc. They often don’t really know what primary sources are and can find them off-putting.
Researchers can make assumptions about what a repository holds, and then be surprised to find that there is material that is relevant for them.
A bad catalogue can put a researcher off, and they may choose to go further afield if the catalogue offers a better experience.
People often ignore tooltips. It is a challenge to provide help that people use.
To mark International Women’s Day on 8th March, here is a selection of archives featuring women who have excelled and been highly influential in many different fields.
Daphne Oram (1925-2003), composer and musician
The Daphne Oram Archive, held at Goldsmiths, University of London, comprises papers, personal research, correspondence and photographs documenting the life and work of a pioneering British composer and electronic musician.
Throughout her career she lectured on electronic music and studio techniques. In 1971 she wrote An Individual Note of Music, Sound and Electronics which investigated philosophical aspects of electronic music. Besides being a musical innovator her other significant achievements include being the first woman to direct an electronic music studio, the first woman to set up a personal studio and the first woman to design and construct an electronic musical instrument.
Delia Derbyshire (1937-2001), musician and composer
The University of Manchester holds the Papers of Delia Derbyshire, composer. After being rejected by Decca Records, who said that they did not employ women in the recording studio, in 1962 Derbyshire became a trainee studio manager at the BBC. She was soon seconded to work at the BBC’s Radiophonic Workshop, which had been set up to provide theme and incidental music and sound for BBC radio and television programmes. The following year, she produced her electronic ‘realisation’ of Ron Grainer’s theme tune for the hugely popular BBC series Doctor Who – which is still one of the most famous and instantly recognisable television themes. In the late 1990s there was renewed interest in her work and many younger musicians making electronic dance and ambient music (such as Aphex Twin and The Chemical Brothers) cited Derbyshire as an important influence.
The Anita White Foundation International Women and Sport Archive
Dr Anita White and Professor Celia Brackenridge were both associated with the University of Chichester, and they were both centrally involved in the leadership and development of the international women and sport movement since 1990. The International Women and Sport Archive is comprised primarily of papers brought together by them and other leaders in the movement, accumulated in the course of their research, study and work in the fields of the sociology of sport and sport science, and their involvement as activists and leaders in the global women and sport movement.
The International Women and Sport Movement is said to have been born out of a decade in which increasing globalisation brought together women from across the world in the practice of sport. It does not refer to any one organisation, body or country, but it is generally agreed that a landmark event and major catalyst in the movement was the first international conference on women and sport which took place on 5-8 May 1994.
Kaye Webb ( 1914-1996), editor and publisher
The Papers of Kaye Webb, covering her career as journalist, magazine editor, editor at Puffin and later literary agent, are held at the Seven Stories Archive. The collection provides a comprehensive record of Webb’s career, reflecting the wide variety of work undertaken by her, and documented through notes, correspondence, press cuttings, audio-visual material, memorabilia and ephemera. Webb was editor of Puffin Books between 1961 and 1979, and in 1967 founded the Puffin Club, which she ran until 1981. As a journalist she worked on publications including Picture Post, Lilliput and the News Chronicle.
Elizabeth Garrett Anderson (1836-1917), physician and suffragist
The Letters of Elizabeth Garrett Anderson are part of the Women’s Library Archives. An English physician and suffragist, she was was the first woman to qualify in Britain as a physician and surgeon. She was the co-founder of the first hospital staffed by women, the first dean of a British medical school, the first woman in Britain to be elected to a school board and, as mayor of Aldeburgh, the first female mayor in Britain. The letters cover Anderson’s struggle to secure an entry into the medical profession.
Barbara Castle (1910-2002), politician and campaigner
The Barbara Castle Cabinet Diaries at the University of Bradford cover 1965-1971 and 1974-1976. In the 1945 General Election Barbara Castle was elected M.P. for Blackburn, a seat that she retained for 34 years. Following the Labour victory in 1964, Prime Minister Harold Wilson put Castle in charge of the newly-created Ministry of Overseas Development. “I decided on 26 January that I ought to start keeping a regular record of what was happening”, she said. Castle maintained this political diary throughout her periods in office. In 1974 Castle was made Secretary of State for Social Services, and in this post she introduced payment of child benefit to mothers and worked on the State Earnings Related Pensions Scheme. In 1979 she became a Member of the European Parliament and in 1990 she entered the House of Lords as Baroness Castle of Blackburn.
Alison Settle (1891-1980), fashion journalist and editor
In a career spanning from the early 1920s to the early 1970s, Alison Settle worked as a fashion journalist, and Brighton Design Archive hold the Alison Settle Archive which includes professional papers dating from the mid-1930s. She was a tireless champion of the interests of women, as well as campaigning for good quality, affordable design through her relationships with designers and manufacturers. Settle sought to improve design standards in all areas of manufacture and production, and contributed to the work of both the Council for Art & Industry and the Council of Industrial Design. She remained one of the best known fashion journalists in the country.
Elise Edith Bowerman (1889-1973), lawyer and suffragette
Diaries, photographs and correspondence of Elsie Edith Bowerman are held at the Women’s Library. Bowerman followed her mother into the suffrage movement. They were both active members of the militant Women’s Social & Political Union. They were on the maiden voyage of the Titanic – both survived. She worked for Scottish Women’s Hospitals during the First World War, and she also worked for Emmeline and Christabel Pankhurst during their campaign for ‘industrial peace’ in support of the war effort. In 1924 or 1925 she went on to set up the Women’s Guild of Empire with Flora Drummond, with the aim of promoting co-operation between employers and workers. She was admitted to the Bar in the early twenties and practised until 1938, when she joined the Women’s Voluntary Services. In 1947 Bowerman went to the United States to help set up the United Nations Commission on the Status of Women.
Tessa Boffin (1960-1993), writer, photographer and performance artist
The Tessa Boffin Archive at the University for the Creative Arts includes lesbian, gay, bisexual, transexual and other photography projects, including portrayal of AIDS, cross dressing and safe sex, as well as notes on television and radio productions of the 1980s portrayal on feminism and AIDS. Boffin was one of the leading lesbian artists in Great Britain during the AIDS Crisis, but her risqué performances were controversial, and frequently drew criticism, including from inside the LGBTQ community.
Gladys Aylward (1902-1970), missionary
Gladys May Aylward was an evangelical Christian missionary to China. She travelled to China in 1932 and in 1936 she became a Chinese citizen. In 1940, against the background of civil war between Nationalist government troops and the Communists, Japanese invasion, and the threat of bandits, she led a group of orphans on a perilous journey to Sian. Her story was told in the book The Small Woman, by Alan Burgess published in 1957, and made into the film The Inn of the Sixth Happiness starring Ingrid Bergman, in 1958. The Papers of Gladys Aylward, held at SOAS, provide a vivid portrait of Aylward, including her life in China, and the impact of World War Two.
In the last Names post I wrote about the 4-step process that covers ‘matching and meaning’. Step 2 was ‘Structuring data’, which means implementing a process to structure the elements that form part of a name string.
Many names are not structured. But if we can process the data to create better structure, we have a much better chance of matching it to other entries.
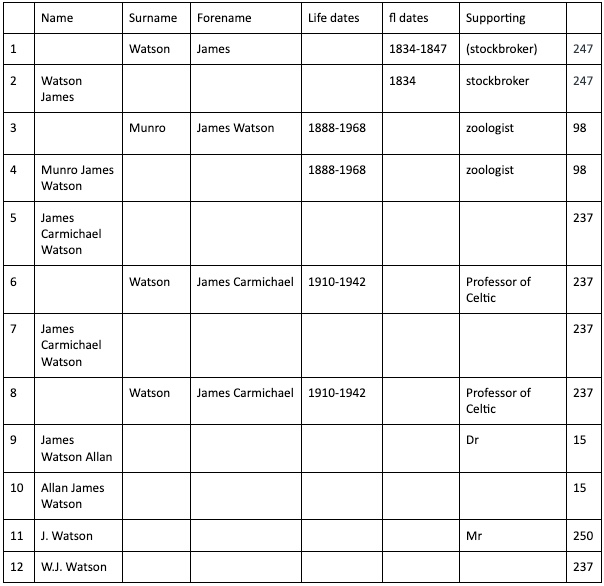
Here is a table showing some name entries around ‘J Watson’ (my examples are taken from real data, but sometimes tweaked a bit in order to cover different types of patterns – all the patterns will be found within the data).
Names based around ‘J Watson’ put into a structure table
The elements have been put into columns, and this is the idea with our structuring process. Some names are still strings – we cannot always know which part is a surname and which part a forename; and some names do not have that kind of structure anyway. We hope to identify floruit dates, and categorise them as distinct from life dates. We don’t want to match ‘1888-1938’ with ‘fl 1888-1938’ (although we might want to see this as a potential match). We will aim do something similar with birth and death dates. We want to gather all the information that is not a name or a date as ‘supporting information’.
Once we have the structure, it is far more likely we can match the name, and also control our level of confidence about matching. Here is a shorter table based on some of the entries from above:
name
surname
forename
dates
fl dates
info
Watson
James
1834-1847
stockbroker
Watson James
1834-
stockbroker
Watson
J
b 1834
Mr
James Watson
1840-1847
You can see that two of the names are simply name strings. We may not be able to identify a surname and forename in ‘James Watson’ or ‘Watson James’. With the structure that we have imposed, it is possible to write a name matching process that provides a match between the first and second entries in the above table, because we can say with some confidence that a name that includes ‘James Watson’ and that has the birth date of ‘1834’ and the additional information ‘stockbroker’ refers to the same person. We might say this is a ‘definite’ match, or a ‘probable’ match. The third entry could be a ‘possible’ match, as it includes ‘Watson’ and ‘J’ with the same birth date of 1834. If the fourth entry had ‘stockbroker’, for example, then we might consider a possible match, but as things stand, it would not be a match.
It is very important that the interface we develop indicates to end users that we are matching name strings. There is a distinction between matching name strings and simply stating that X and Y are the same person. This will help us with introducing the idea of likely, probable and possible matches.
This structuring work is absolutely at the heart of creating a name interface, and enabling researchers to look up ‘James Watson’ and then potentially go in many different directions through the connections, finding ways that archives may be related. But it is really challenging. We will not ‘get it right’. Even if we had really substantial resources and time, we could not make it perfect. Archivists, as information professionals, are keen on ‘getting it right’, which is usually a good thing; but pulling together information using names created over decades, by thousands of cataloguers, in different systems, without a clear standard to work to….it ain’t ever going to be perfect. The key question is, whether this will substantially enhance the researcher experience and allow new connections to be made. And whether it will enable us to create connections outside of the archives domain. We have to have a change of mindset to accept that it is not perfect, but it is still hugely beneficial to research.
Just to emphasise the variation in data that we have, here are some EAD names, given as they are structured. They are all fine displayed within a description, suitable for a human reader, but they create challenges in terms of name matching. When you look at these, you have to think of the structure and semantics – essentially, how can we write an algorithm that allows us to truly identify the person (or that they are not a person!):
<persname>Barron, Lilias Mary Watson (b1912 : science graduate : University of Glasgow, Scotland)</persname>
<origination label=”Creator: “><persname role=”author”>Name of Author: various </persname></origination>
The last one was actually taken directly from VIAF and imported into the Archives Hub, which is, in principle, a really good way to create a structured name. Unfortunately, the process of pulling it into the Hub using the VIAF APE did not go quite according to plan. VIAF has just the same challenges as we do – there will be structural mistakes. However, it has the VIAF ID, so funnily enough, it is easier to match than many other names.
Many of the above examples are names added as archival creator names (‘origination’). Unfortunately, there has been a tendency for cataloguers to add creator names in a very unstructured way. The old Archives Hub Editor used to encourage this, and most archival systems have a free text field for name of creator. (Now, our Editor structures the creator name and adds it as an index term – so they are both identical).
We are currently looking at the challenge of matching origination name with the index term within the same description. That may sound like an easy task, but very often they are really quite different. For example, for the name of creator you may get:
<origination>Name of Authors: various but include Reverend<persname role=”author”>Thomas Frognall Dibdin</persname>,<persname role=”author”>Richard Bentley</persname>,<persname role=”author”>Philip Bliss </persname>and<persname role=”author”>Frederick James Furnivall</persname></origination>
This is nicely structured, so that it is easy to see that they are separate names, although the lack of life dates makes unique identification more difficult. If these individual names are also added as index terms, then we want to create just one entry for e.g. ‘Thomas Frognall Dibdin’ – we don’t want two entries for the one name (taken from the ‘origination’ and the ‘controlaccess’ index area) that both represent the same archive collection.
A common pattern is something like:
<origination label=”name of creator:”>Frances Dennis</origination>
‘Frances Dennis’ as a name string is very likely to be a match with ‘Frances Mary Dennis b1847 missionary’ when it is within the same collection. If these two entries were in different descriptions, we would not match them.
Our pre-match structuring will go a long way to increasing the number of matches, and hence the intellectual bringing together of knowledge through names. Matching creator name and index term name will reduce the amount of duplication. The framework will be tweakable, so that we can constantly review and improve.
Firstly, an apology to those who commented. I was on a temporary machine for a while and didn’t get the notifications to approve the comments. I really appreciate feedback! And we need to think about this whole topic as an archive community.
Secondly, I wanted to pick up on some comments:
“If cataloguing archivists have access to a central pot of name authorities we are more likely to spot and re-use existing authority entries. So if one archivist identified Elizabeth Roberts 1790-1865 (artist) with a little potted biography which placed her in Penge, then a later archivist finding material from Lizzie Roberts in Penge in 1850s is much more likely to put 2 and 2 together manually”
In fact, one of the potential developments from the work we are doing is an interface specifically for cataloguers. The whole issue of ‘match’, ‘probable’ and ‘possible’ is tricky to present to end users, but relatively easy to present to cataloguers to help with creating names that will successfully be connected. So, we are bearing that in mind as a future development.
“When I looked at the list of names used in this article I thought ‘someone just doesn’t know what to include to properly describe a name”
Yes…I think that sometimes, when I am thinking about how to reconcile the massive variations and how to work with the lack of structure. But then I remember what it was like (when I was a proper archivist) to catalogue within time constraints. And I also remember that I am someone who spends half my life thinking about data! In addition, the point is that with archives it is perfectly valid to enter a name such as ‘Julia (fl 1976)’ because that is what you get from the item you are cataloguing, and nothing more. Maybe you could undertake research to find out who that it, but that would extend the time it takes to catalogue by days, if not weeks and months. For a researcher, this might jog something in the mind and lead to a connection being made. Something is better than nothing. For me, the entries that are rather more frustrating are names such as ‘various’ or ‘Author: various’, or ‘James MacAllister and various’ because these just aren’t names. However, many of these entries were probably created in a time when semantically structured data was not so important.
“The other way of dealing with this is to leave the final decision up to the end-user.”
Yes, this is a fair point. In our current thinking, the idea is that we have levels of confidence that we present to the user, and that allows them to make the decision. But we still need to think carefully about how to do this in a way that most clearly conveys meaning. The most difficult thing is to convey that even though you have linked several collection descriptions to one name, other name strings may also be a match. But at the end of the day, there is always the issue that decisions you make around the navigation and options provided to end users means they are likely to exclude some relevant results. A subject search will exclude any archives not indexed with that subject. Do you therefore dispense with a subject search? (More in this in future posts, as machine learning may present us with new tools to create subject entries).
Since my last post we actually hit the point of ‘blimey, this is just too difficult’. We really weren’t sure we were going to make this work, given the tremendous variations and, in particular, the lack of structure.
However, we have hacked our way through the undergrowth to create a path that I think will fulfil many of our aims. There is so much I could say, if I got into the detail of this, but I will spare you too much discussion around EAD and JSON structure!
A good part of the last few weeks from my point of view has been clarifying the thinking around what is required when processing names. I came up with the idea of the ‘4 pillars of names’.
Matching
This refers to comparing and grouping names.
Matching does not require us to know if it is a person or an organisation or to know anything about meaning at all. It is simply a process to group names. So, ‘D J MacDonald’ could be a company or a person. The question is, does that match ‘David John MacDonald’ or ‘D J MacDonald, manufacturers, Carlisle’?
Matching is therefore also about levels of confidence. It is about saying ‘D J MacDonald b.1932’ is the same as ‘D MacDonald b.1932’….or not.
Matching may also mean matching a creator name and an index term within a record. For more on this, see below.
2. Meaning
Name meaning is about whether it is a personal, corporate or family name. Many creator names are just ‘creator’. There is no tagging to distinguish the type. Index terms have to have a type, but matching them up to creator name is not always easy. See more on that below.
3. Search behaviour
What happens when the user clicks on the name? Previous posts have presented our ideas for this. Whilst we are not yet ready to develop an end user interface, the options that are available to us for display are necessarily constrained by how we process the data. So we do need to think about this now.
4. Display
How we display a name record, or a name page. Again, not something we are focussing on now, other than to think about the sorts of features that we want to include.
* * *
Our discussions have been characterised by ‘one step forwards two steps backwards’, which can feel a little dispiriting. But we believe we have now sorted out the approach we need to take. I have spent a lot of time working collaboratively with Rob Tice from Knowledge Integration, unpicking the (many and varied) challenges in the data and as a result we’ve agreed an approach that we believe will produce the data that we want.
So, this again consists of 4 parts – a 4-step process that covers matching and meaning.
Matching within a collection description
We need to try to match the creator name to the index term, if we have both. This is the first step in the workflow. To do this, the processing needs to identify names within one collection (each name needs to be attached to a collection via a reference).
Taking the description of the Caledonian Railway Company as an example (https://archiveshub.jisc.ac.uk/data/gb248-ugd008/7andugd8/38). The name appears as:
We want to create one entry for these names that we take forwards into the de-duplication process. In this case, the names are all marked up as corporate names. But in many cases the creator is not marked up in this way. We need a process to match these entities to say that they are the same. This is about applying matching at the level of one collection, rather than across collections. When you apply it to one collection, you can decide to make more assumptions. For example,
Creator: Dorothy Johnson Index term: Johnson, Dorothy, 1909-1966, Researcher into theatre history
This creator is not marked up as a personal name. If we worked with these entries in our general de-duplication, so that they were not associated with one particular collection, we could not say they are the same person. Indeed, we could not identify ‘Dorothy Johnson’ as a person, only as a creator. The relationship of these two entries would get lost. But within one collection description, we can make the assumption that they represent the same thing.
If we make this the first step we can remove many of the creator-as-string names from the processing – they will already be matched to a structured index term.
2. Structuring data
This is a process of following rules to structure data. Many names are not structured. PIDs (persistent identifiers) can by-pass this need for consistency, but at present the archive community barely uses recognised identifiers. I have posted previously on name authorities and structure. So, anyway, to introduce a bit of EAD, you might have:
<persname><emph altrender=”surname”>Nightingale</emph><emph altrender=”forename”>Florence</emph><emph altrender=”dates”>1820-1910</emph><emph altrender=”epithet”>Reformer of Hospital Nursing</emph></persname>
If we can process the first entry to give the kind of structure you see in the second entry that enables us to carry out de-duplication, and we have a much better chance of matching it to other entries. This is decidedly non-trivial, and we won’t be able to do this for all names.
3. De-Duplication
This is the process outlined in the blog post on de-duplication at scale . Once the other processes are in place, we are in a position to run the de-duplication process, and start to try out different levels of confidence with matching.
A working example: George Bernard Shaw
collection match:
George Bernard Shaw (gb97-photographs) matches: Shaw, George Bernard, 1856-1950, author and playwright (gb97-photographs)
structure rules:
apply rule: if it includes YYYY-YYYY and the preceding words include a comma then the first entry is a surname and the second entry is a forename apply rule: YYYY-YYYY is a date apply rule: words after YYYY-YYYY are additional information
Creates: Surname: Shaw Forename: George Bernard Dates: 1856-1950 Additional information: author and playwright
de-duplication:
The structured entry matches a name from another description:
So, we are now in the process of implementing this workflow. The current phase of this project will not allow us to complete this work, but it will lay the foundations. Of course, we’ll find other challenges and issues. We still don’t know how successful we will be. There will definitely be names we can’t match and we can’t identify as personal or corporate. But then it is down to how we present the information to the end user.
I called this post ‘A 4 year old in red wellington boots’ because in her comment on the previous blog post Teresa used that as a metaphor for how we can think about data. We need to explore, to play with data, to search and discover, to not mind getting dirty. It is easy to get stressed about not getting everything right; but we need to jump into the puddles and just see what happens!
On the Archives Hub we have plenty of name entries without dates. Here is an example of the name string ‘Elizabeth Roberts’ (picked entirely randomly) from several different contributors:
Richard and Elizabeth Roberts Roberts, Elizabeth fl. 1931 Elizabeth Grace Roberts Roberts, Elizabeth Grace Elizabeth Roberts Roberts, Elizabeth ROBERTS, Elizabeth Grace ROBERTS, Mrs Elizabeth Grace
The challenge we have is how to work this names like this. Let me modify this list into an imaginary but nonetheless realistic list of names that we might have on the Hub, just to provide a useful example (apologies to any Elizabeth Roberts’ out there):
Elizabeth Roberts 1790-1865 Elizabeth Roberts, 1901-1962 Elizabeth Roberts b 1932 Elizabeth Roberts fl. 1958 Elizabeth Roberts, artist Elizabeth Roberts Elizabeth Roberts Elizabeth Roberts
How should we treat these names in the Archives Hub display? If we can make decisions about that, it may influence how we process the names.
These names can be separated into two types (1) name strings that identify a person (2) name strings that don’t identify a person. This is a fundamental difference. It effectively creates two different things. One is an identifier for a person; one is simply a string that we can say is a name, but nothing more.
If we put two descriptions together because they are both a match to Elizabeth Roberts, 1790-1865, then we are stating that we think this is the same person, so the researcher can easily see collections and other information about them.
If we put two descriptions together that are both related to Elizabeth Roberts we are not doing the same thing. We are simply matching two strings.
Which of these names is an identifier? That depends upon levels of confidence, and that is why being able to set and modify levels of confidence is crucial.
Elizabeth Roberts 1790-1865 – this is enough to identify a person. In theory, there could be two people with the same life dates, but the chances are very low. So, we would bring together two entries and represented them on one name page.
Elizabeth Roberts b 1932– Is a birth or death date enough? It allows for some measure of certainty with identity, and we would probably deem this to be enough to identify a person and match to another Elizabeth Roberts born in 1932, but it is not certain. If this Elizabeth Roberts was the creator, and she has several mentions of ‘art’, ‘artist’ and ‘painting’ in her biography, it is more likely that she is the same as Elizabeth Roberts, artist and might be useful to create a link, but would it be enough for a match?
Elizabeth Roberts fl 1931 – whilst a floruit date helps place the person in a time period, it is not enough to confidently identify a person.
Elizabeth Roberts, artist – occupation or other epithet enough is not usually enough to identify someone. If there is a biographical history, there is more information about the person, but this is not enough to be sure.
If we had an entry such as Elizabeth Roberts, Baroness Wood of Foxley (completely imaginary and just for the purposes of example), then the epithet is more helpful. We might decide that this identifies a person enough for a match with any other instances of Elizabeth Roberts with baroness wood and foxley in the name string.
If we had MacAlister, Sir Donald, 1st Baronet, physician and medical administrator then ‘1st baronet’ alongside the name should give enough confidence for a match with another entry for 1st Baronet.
Display behaviour
So, how might we reflect this in the display? It can be useful to think about the display and researcher requirements and expectations and work back from there to how we actually process the data.
Firstly we might group two entries if they have the same date.
But this does not offer much benefit to the end user. They still see eight entries for this name string. So, we might bring together the entries that match exactly on the name string.
But there are still two entries that are essentially just name strings – the fl. and the ‘artist’ entry are essentially the same as those without any additional information in that they are name strings and they do not identify a person, so it makes sense to group all of these entries.
We now have a short set of entries. We can’t merge any more of them.
However, this does leave us with a problem. The end user is likely to assume that these all represent different people. That ‘Elizabeth Roberts’ is a different person from ‘Elizabeth Roberts 1901-1962’. The tricky thing is that she might be….and she might not be. It is likely that a user wanting Elizabeth Roberts with dates 1790-1865 would see the above list and click on the matching entry, not realising that the last three entries could also refer to the same person. We don’t want to exclude these from the researcher’s thinking without hinting that they may represent the same person.
We might give the list a heading that hints at the reality, such as ‘We have found the following matches:’. Maybe ‘matches’ would have a tool tip to say that the entries without dates could match the entries with dates. It is quite hard to even find a way to say this succinctly and clearly.
The identifiable names would link to name pages. We might provide information on the name pages to again emphasise that other Elizabeth Roberts entries could be of interest. We haven’t yet decided what would be best in terms of behaviour for the non-identifiable names – they might simply link to a description search – it does not make much sense to have a full name page for an unidentified person where all you have is one link to one archive description. We can’t provide links to any other resources for a non-identifiable name; unless we simply provide e.g. a Wikipedia lookup on the name. But again, we face the issue of misleading the end user; implying a ‘same as’ link when we do not have enough grounds to do that.
Names as creators
We may decide to treat creator names differently. Archival creator does have a significant meaning – it emphasises that this is a collections about that person or organisation (though even the nature of the about-ness is difficult to convey). But many users do not necessarily appreciate what an archival creator is, and many descriptions don’t provide biographical histories, so could this end up creating confusion? Also, in the end a creator name is far more likely to include life dates, so then they would have a full name page anyway. What would be the benefit of treating a creator name with no life dates and no biographical history differently from an index term and giving it a name page? You would just be linking to one archive, albeit ‘their’ archive.
What about if a name string record, say the Elizabeth Roberts fl 1931, has been ingested as an EAC record, i.e. a name record that was created by one of our contributors? It is likely that name records will include a full date of birth, or at least a birth or death date, but this is not certain. Whilst we are not currently set up to take in EAC-CPF name records, we do plan to do this in the future. If the name is provided through an EAC record and they are a creator, they may have a detailed biography, and may have other useful information, such as a chronology, so a name page would be worthwhile.
This short analysis shows some of the problems with providing a name-based interface. We will undoubtedly encounter more thorny issues. The challenge, as is so often the case, is just as much about how to convey meaning to end users when they are not necessarily familiar with archival perspectives, as it is about how to process the data.
And we haven’t even got to thinking about Eliza Roberts or Lizzy Roberts…..
Having written several blogs setting out ideas and thoughts about challenges with names, this post sets out some of our plans going forwards in order to create name records for a national aggregator; something that can work at scale and in a sustainable way. The technical work is largely being undertaken by Knowledge Integration, our system suppliers, though working closely with the Archives Hub team.
Consider one repository – one Hub contributor. They have multiple archives described on the Archives Hub, and maybe hundreds or thousands of agents (people and organisations) included in those descriptions. All of this information will be put into a ‘management index‘. This will be done for all contributors. So, the management index will include all the content, from all levels, including all the names. A huge bucket of data to start us off.
A names authority source such as VIAF or any other names data that we would like to work with will not be treated any differently to Archives Hub data at this stage. In essence matching names is matching names, whatever the data source. So, matching Archives Hub names internally is the same as matching Archives Hub names to VIAF, or to Library Hub, for example. However, this ‘names authority’ data will not go into our big bucket of Archives Hub data, because, unless we create a match with a name on the Hub, the authority data is not relevant to us. Putting the whole of VIAF into our bucket of data would create something truly huge. It is only if we think that this external data source has a name that matches a person or organisation on the Hub that it becomes important. So data from external sources are stored in separate reference indexes (buckets) for the purposes of matching.
Tokenisation
Knowledge Integration are employing a method known as tokenization, which allows us to group the data from the indexes into levels (It is quite technical and I’m not qualified to go into it in detail, so I only refer briefly to the basic principles here. Wikipedia has quite a good description of tokenization). With this process, we can establish levels that we believe will suit our purposes in terms of confidence. Level 1 might be for what we think is a guaranteed match, such as where an identifier matches. So, for example, Wikidata might have the VIAF identifier included, so that the VIAF and Wikidata name can be matched. In some cases, the Archives Hub data includes VIAF IDs, so then the Hub data can be matched to VIAF. We also hope to work with and create matches to Library Hub data, as they also have VIAF ID’s.
If all versions of a name have the same ID then they can be matched.
Level 2 might be a more configurable threshold based around the name. We might say that a match on name and date of birth, for example, is very likely an indication of a ‘same as’ relationship. We might say that ‘James T Kirk’ is the same person as ‘James Kirk’ if we have the same date of birth. This is where trial and error is inevitable, in order to test out degrees of confidence. Level 3 might bring in supporting information, such as biographical history or information about occupation or associated places. It is not useful by itself, but in conjunction with the name, it can add a degree of certainty.
Biographical information may be used to help match names
We are also thinking about a Level 4 for approaches that are Archives Hub specific. For example, if the same name is provided by the same repository, could we say it is more likely to be the same person?
This tokenisation process is all about creating a configurable process for deduplication. Tokens are created only for the purposes of matching. Once we have our levels decided, we can create a deduplication index and run the matching algorithm to see what we get.
Approaches to indexing
For deduplication indexing, the first thing to do is to convert to lower case and remove all of the non-alpha characters. (NB: For non-latin scripts, there are challenges that we may not be able to tackle in this phase of the project).
The tokens within the record will be indexed in multiple ways within the deduplication index to facilitate matching. This includes indexing all words in order that they appear, and also individual word matches.
Then, particularly when considering using text such as biographies to help identify matches, we can use bigrams and trigrams. These essentially divide text into two and three words chunks. A search can then identify how many groups of two and three words have matched. Generally, this is a useful method of ascertaining whether documents are about the same thing. It may help us with identifying name matches based upon supporting information. This is very much an exploratory approach, and we don’t know if it will help substantially with this project, but certainly it will be worth trying out this approach, and also considering using it for future data analysis projects.
Character trigrams break down individual words into groups of three characters and may be useful for the actual names. This should be useful for a more fuzzy matching approach, and it help to deal with typos. It can also help with things like plurals, which is relevant for working with the supporting information.
We are also going to explore hypocorisms. This means trying out matches for names such as Jim, Jimmy and James or Ned, Ed, Ted and Edward. A hypocorism is often defined as a pet name or term of endearment, but for us it is more about forename variations. Obviously Jim Jones is not necessarily the same person as James Jones, but there is a possibility of it, so it is useful to make that kind of match on name synonyms. It is often defined as a pet name or term of endearment.
Hypocorisms refers to pet names or terms of endearment
From this indexing approach we can try things out and see what works. There is little doubt that it will require an iterative and flexible approach. We can’t afford to set up a whole process that proves ineffective so that we have to start again. We need an approach that is basically sound and allows for infinite adjustments. This is particularly vital because this is about creating a framework that will be successful on an on-going basis, for a national-scale service. That is an entirely different challenge to creating a successful outcome for a finite project where you are not expecting to implement the process on an on-going basis. Apart from anything else, a project with a defined timescale and outcome gives you more leeway to have a bit of human intervention and tweak things manually to get a good result.
Group records
Using the tokenisers and matching methods we can try processing the data for matches. When records are matched with a degree of certainty, a group record is created in the deduplication index. It is allocated a group id and contains the ids of all of the linked records. This is used as the basis for the ‘master record’ creation.
Primary or master records
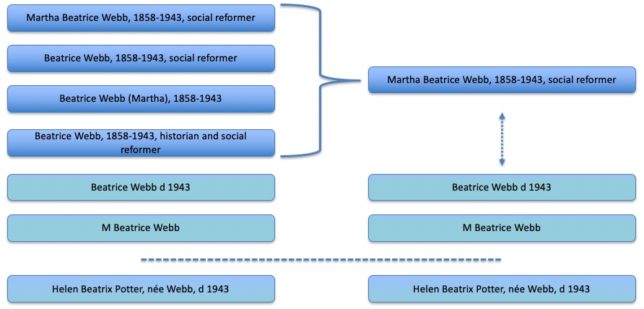
I have previously blogged some thoughts about the ‘master record’ idea. Our current proposal is that every Archives Hub name is a primary record, unless it is matched. So, if we start out with six variations of Martha Beatrice Webb, 1858-1943, then at that point they are all primary records and they would all display. If we match four of them, to a confidence threshold that we are happy with, then we have three primary records. One of the primary records covers four archives. We may be able to still link the other two instances of this name to the aggregated record, but we can assign a lower confidence threshold to this.
Deduplication for ‘Beatrice Webb’
In the above example (which is made up, but reflects some of the variations for this particular name) four of the instances of the name have been matched, and so that creates a new primary record, with child records. Two of the instances have not been matched. We might link them in some way, hence the dotted line, or they might end up as entirely separate primary records. The instance of Beatrix Potter, nee Webb, has not been matched (these two individuals are often confused, especially as they have the same death date). If we set levels of confidence wrongly, this name could easily be matched to ‘Beatrice Webb’.
The reasoning behind this approach is that we aggregate where we can, but we have a model that works comfortably with the impossibility of matching all names. Ideally we provide end users with one name record for one person – a record that links to archive collections and other related resources. But we have to balance this against levels of confidence, and we have to be careful about creating false matches. Where we do create a match, the records that were previously primary records become ‘child records’ and they no longer display in the end user interface. This means we reduce the likelihood of the end user searching for ‘william churchill’ and getting 25 results. We aim for one result, linking to all relevant archives, but we may end up with two or three results for names that have many variations, which is still a vast improvement.
If we have several primary records for the same person (due to name variations) then it may be that new data we receive will help us create a match. This cannot be a static process; it has to be an effective ongoing workflow.
It is easy to focus on names that represent fairly well known people. But one of the challenges for archives is to work with little known people – names that represent someone who is referenced in a catalogue – maybe they are indexed because they are a correspondent for example – they appear in one of a series of letters – but there is no more information about them other than their name. They may be referenced in other sources, but we have little to go on in order to discover that, and often they won’t be represented – it may be that this is the only written source that includes them.
In a names service, we can add a name – let’s say ‘Louisa Jane Justamond’ – a name from https://archiveshub.jisc.ac.uk/data/gb12-ms.add.8556 (‘The Garland continued’, a collection of poems addressed to her). We only have that one instance of that name. It is not in VIAF, it is not in Wikidata. There is an instance listed in ‘A genealogical and heraldic dictionary of the landed gentry of Great Britain’ (a precursor to Burke’s peerage). But unless we decide to use that an external source, write a name matching algorithm and decide, on levels of confidence, that it is indeed a match, that is not going to help us. We are left with a name attached to one archive collection and nothing else.
We can create a name record for Justamond, but if we display it on the Archives Hub it will simply show her name and a link back to the related description. It will be extremely minimal.
However, what we don’t know is whether new collections will be added to the Archives Hub, or new information added to Wikidata or another source that we use, such that this person becomes more identifiable. We simply don’t know what the value of a name might be. In the future, having a record of this person could prove to be immensely useful in making a connection.
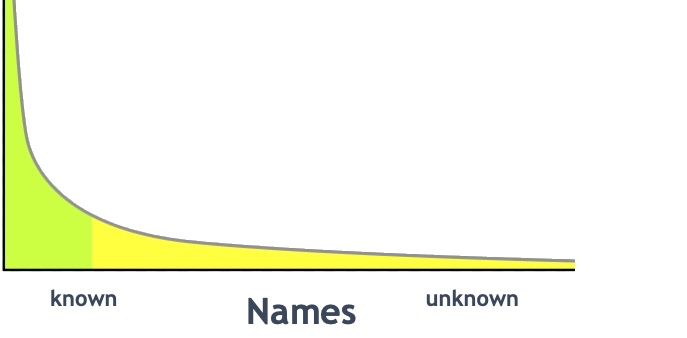
Archives have what you might call a long tail of names. It is something that characterises our holdings. It is something that sets us apart from libraries and museums, at least to a degree. Most names represented in library holdings (or names they represent in their catalogues and other finding aids) represent identifiable people.
The long tail of names
In archives, we have collections that represent ordinary people, not published, not celebrated, not notorious, with no documented place in history. We also have collections that include people where it is hard to know whether an individual is more widely known, because the archive collection does not entirely identify them.
Either way, it leaves us with a question about how to deal with a name that has nothing else attached to it other than ‘this name is in this letter’.
Building an index of all names means that we have a store of data that can be used for further exploration. It could sit behind the scenes, but it can be used to try out tools, data manipulation and matching. In other words, the data is a separate thing from what you decide to display.
Having a name (maybe not knowing exactly who the name represents) and knowing that the name is in three different archives has value. We can say ‘in the absence of any other information, we assume these names represent the same person’, or we can simply present the information and not make any conclusions (although that begs the question of how you present it without encouraging assumptions). It is then up to researchers to explore further. We might find new data sources that help to clarify names. We might get new descriptions that help to do this.
Many archival descriptions include subjects and, to a lesser extent, places. If you have Stephen Merryweather in one, with an index term of botany, and S. Merryweather in another, with the same index term, then you could say it is more likely to be a match. There is a question of how you might then present that information. The use of algorithms raises the issue of how to convey levels of confidence. It feels as if we need to have a more sophisticated – and recognised – means of presenting levels of confidence.
This whole issue of confidence levels is more of a focus for archives, because of the anonymity I’ve talked about.
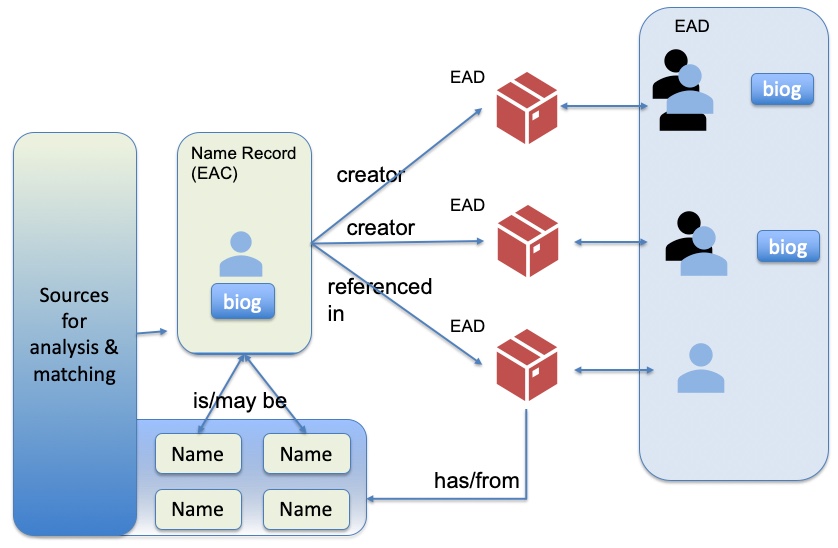
Relationships of data involved in creating name records
The ‘Name’ records shown above are the names within archival descriptions (EAD records on the Hub). These names can be pulled out from ‘origination’ (creator) and from ‘persname’ (usually in the controlaccess index section, but potentially elsewhere in the description). These names may represent ‘unknown’ people, the EAD may not even indicate whether they are personal or corporate or family names. They may not include dates, they may just be ‘Mary Fleming’ or ‘Mary Fleming fl 1717’. They may also be ‘unknown’, ‘[unknown]’, or even ‘unknown unknown’ (keeping the surname, forename structure!). They may be ‘Name of author (various)’ or ‘Various health authority bodies’ or ‘Possibly Miss M. Lindsay’. All these are examples from our data. They illustrate the conflict between human readable data – where ‘unknown’ is useful – and machine processable data – where semantics are important, and a name is ideally just a name.
If we create ‘Name’ entries for all of these then we have a store of data to work with, something I’ve mentioned before in my Names Project blogs. We can then find out how many ‘Mary Fleming’ entries there are, or how many ‘M Fleming’ entries. How we then choose to display that information to end users is a separate question. But with the advances in machine learning, it is becoming an increasingly pertinent question.
We have an opportunity with archival metadata, with the way that archives represent ‘ordinary life’. But it is a challenge Catalogues are still not really set up to identify entities (in a way that works for machine processing). We create what we refer to as ‘name authorities’ but we do not usually consider the importance of matching names outside of individual organisations. The Archives Hub has an opportunity to work on behalf of UK archives to try to draw out people and, in a sense, identify them, or at least, enable them to be more contextualised. But it will require a good deal of experimentation and expertise in working with disparate data. However, if we create a pool of names and provide an API, that would enable others to work with the data, and try different approaches. This is a big challenge, and it needs a concerted and collaborative approach.
As archivists, we deal with ethical issues a good deal. But the ability to link disparate and diverse data sources opens up new challenges in this area, and I wanted to explore this a bit.
If you do a general search for ethics and data, top of the list comes health. An interesting example of data join-up is the move to link health data to census data, which could potentially highlight where health needs are not being met:
“Health services are required to demonstrate that they are meeting the needs of ethnic minority populations. This is difficult, because routine data on health rarely include reliable data on ethnicity. But data on ethnicity are included in census returns, and if health and census data for the same individuals can be linked, the problem might be solved.” (Ethnicity and the ethics of data linkage)
However, individuals who stated their ethnicity in census returns were not told that this might subsequently be linked with their health data. Should explicit informed consent be given? Given the potential benefits, is this a reasonable ask? It is certainly getting into hazardous terrain to ignore the principle of informed consent. In their book ‘Rethinking Informed Consent in Bioethics‘, Manson and O’Neill argue that informed consent cannot be fully specific or fully explicit. They argue for a distinctive approach where rights can be waived or set aside in controlled and specific ways.
This leads to a wider question, is fully explicit and specific informed consent actually achievable within the joined-up online world? A world where data travels across connections, is blended, re-mixed, re-purposed. A world where APIs allow data to be accessed and utilised for all sorts of purposes, and ‘open data’ has become a rallying cry. Is there a need to engage the public more fully in order to gain public confidence in what open data really means, and in order to debate what ‘informed consent’ is, and where it is really required?
I am working on a project to create name records, and I am looking at bringing data sources together. Of course, this is hardly new. Wikipedia is the most well-known hub for biographical data. Anyone can add anything to a Wikipedia page (within some limits, and with some policing and editing by Wikipedia, but in essence it is an open database). Wikidata, which underlies Wikipedia, is about bringing sources together in an automated way. Projects within cultural heritage are also working on linked data approaches to create rich sources of information on people. SNAC has taken archival data from many different archive repositories and brought it together. A page for one person, such as Martin Luther-King provides a whole host of associations and links. These sources are not all individually checked and verified, because this kind of work has to be done algorithmically. However, there is a great deal of provenance information, so that all sources used are clear.
The Face of White Australia
There are some amazing projects working to reveal hidden histories. Tim Sherratt has done some brilliant work with Australian records. Projects such as Invisible Australians, which aims to reveal hidden lives, using biographical information found in the records. He has helped to create some wonderful sites that reveal histories that have been marginalised. Tim talks about ‘hacking heritage’ and says: ‘By manipulating the contexts of cultural heritage collections we can start to see their limits and biases. By hacking heritage we can move beyond search interfaces and image galleries to develop an understanding of what’s missing.’ (Hacking heritage, blog post) He emphasises that access to indigenous cultural collections should be subject to community consultation and control. But what does community consultation and control really mean?
I have always been keen to work with the names in archival descriptions – archival creators and all the other people who are associated with a collection. They are listed in the catalogue (leastways the names that we can work with are listed – many names obviously aren’t included, but that’s another story), so they are already publicly declared. It is not a case of whether the name should be made public at all, or, at least, that decision has been made already by the cataloguer. But our plan is to take the names and bring them to the fore – to give them their own existence within our service. We are taking them out of the context of a single archive collection and putting them into a broader one. In so doing, we want to give the archive collections themselves more social context, we want to give more effective access to distributed historical records, and we also want to enable researchers to travel through connections to create their own narratives.
This may help to reveal things about our history and highlight the roles that people have played. It may bring people to the fore people who have been marginalised. Of course, it does not address the problem of biases and subjective approaches to accessions and cataloguing. But a joined-up approach may help us to see those biases and gaps; to understand more about the silent spaces.
Creating persistent identifiers and linking data reveals knowledge. It is temping to see that in simple terms as a good thing. But what about privacy and ethics? Even if someone is no longer living, there are still privacy issues, and many people represented in archives are alive.
Do individuals want to be persistently identified? What about if they change their identity? Do they want a pseudonym associated with their real name? They might have very good reasons for keeping their identity private. Persistent identification encourages openness and transparency, which can have real benefits, but it is not always benign. It is like any information – it can be used for good and bad purposes, and who is to say what is good and what is not? Obviously we have GDPR and the Data Protection Act, and these have a good deal to say about obligations, the value of historical research and the right to be forgotten. This is something we’ll need to take into account. But linked data principles are not so much about working with personal data as working with data that may not seem personal, but that can help to reveal things when linked with other sources of data.
GDPR supports the principle of transparency and the importance of people’s awareness and control over what happens to their personal data. Even if we are not creating and storing personal data, it seems important to engage with data protection and what this means. The challenge of how to think about data when it is part of an ever shifting and growing global data environment seems to me to be a huge one.
Certainly the horse has bolted to some degree with regards to joining up data. The Web lowered barriers considerably, and now we increasingly have structured data, so it is somewhat like one gigantic database. Finding things out about individuals is entirely feasible with or without something like a Names service created by the Archives Hub. We are not creating any new content, but creating this interface means we are consciously bringing data together, and obviously we want to be responsible, and respect people’s right to privacy. Clearly it is entirely impractical to try to get permission from all those living people who might be included. So, in the end, we are taking a degree of risk with privacy. Of course, we will un-publish on request, and engage with any feedback and concerns. But at present we are taking the view that the advantages and benefits outweigh the risks.
“Imagine being a sibling in a family that continually removes you from photos; tries its best to erase you…As you go through [the scrapbook] you see events where you know you were there, but you are still missing.” Lae’l Hughes-Watkins (University of Maryland) gave an impassioned and inspiring talk at DCDC 2019 about her experiences. She argued that archivists need to interrogate the reality that has been presented, and accept that our ideas of neutrality are misplaced. She wants a history that actively represents her – her history and culture, and experiences as a black woman in the USA. She related moving stories of people with amazing stories (and amazing archives) who distrust cultural institutions because they don’t feel included or represented.
This may seem a long way away from our small project to create name records, but in reality our project could be seen as one very small part of a move towards what Lae’l is talking about. Bringing descriptions together from across the UK together maybe helps us to play a small role in this – aiming to move towards documenting the full breadth of human experience. The archives that we cover may retain the biases and gaps for some time to come (probably for ever, given that documentary evidence tends to represent the powerful and the elite much more strongly), but by aggregating and creating connections with other sources, we help to paint a bigger picture. By creating name records we help to contextualise people, making it much easier to bring other lives and events into the picture. It is a move towards recognising the limitation of what is actually in the archive, and reaching out to take advantage of what is on the Web. In doing this through explicitly identifying people we do leave ourselves more open to the dangers of not respecting privacy or anonymity. When we plug fully into the Web, we become a part of its infinite possibilities, which is always going to be a revealing, exciting, uncontrollable and risky business. By allowing others to use this data in different ways, we open it up to diverse perspectives and uses.
It has been great to get comments and feedback around names, and I wanted to expand upon something that a few people have commented on….the ideal of one ‘authority record’ for one person or organisation.
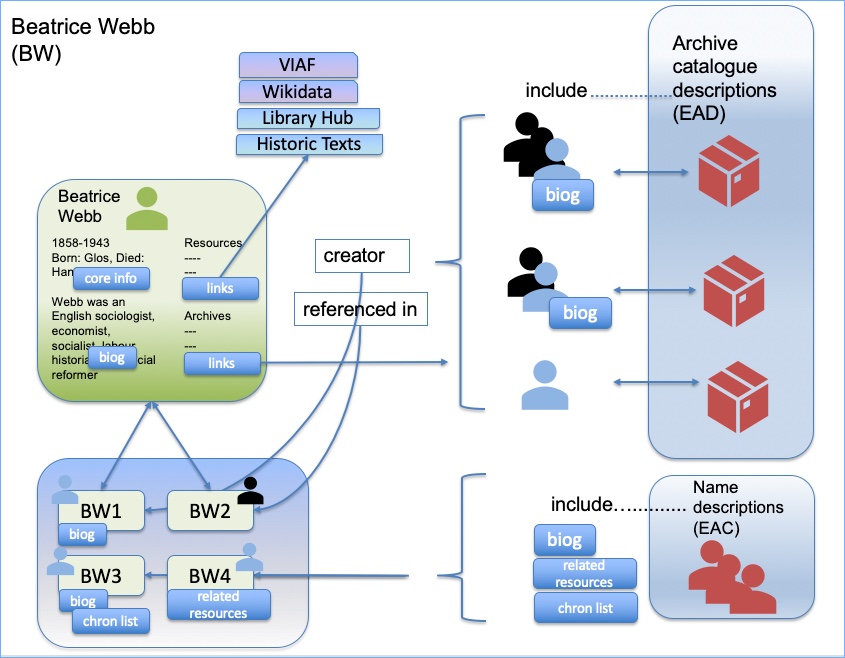
Model showing potential relationships between catalogues and name records
The above diagram is a proposal for the relationships we might have – note that is it a working model, and may well change over time. You can see the catalogues (the descriptions of archives) include people, some with biographical histories, and these people are either creators of archive collections or referenced in them. Each of these people then gets a name record (bottom left box), so we might have e.g. three name records for the same name (and the same name may potentially the same person…or may not). We will work with the store of records that we have with the aim of creating matches, and ending up with a generic or main name record (green box, top left).
The ‘main record’ or ‘master record’ or whatever we might call it, for each individual person or organisation, is not an ‘archival record’. It is not intended simply to be a reflection of what is in our own data. It is intended to be a page dedicated to that person or organisation. Our current feeling is that this should not be seen as domain specific; in fact, we want to get away from the idea that data is domain specific. It is about an entity (a person or organisation), and what we know of that entity.
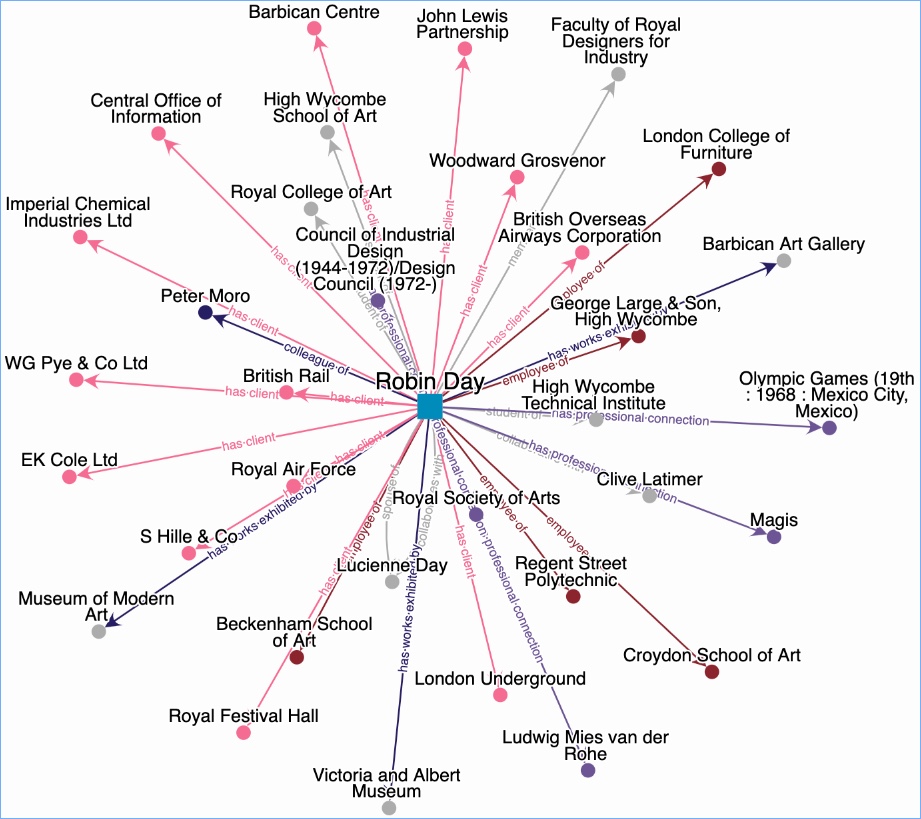
Keeping in mind the green box, and looking at the person page for Robin Day from Exploring British Design, a previous AHRC project we ran with Brighton Design Archive, you get a sense of the type of thing we mean.
Exploring British Design: Robin Day
This page presents as a general information page about a designer. It is not branded as a page about archives. It takes information in from different sources. Is it an ‘authority’ record? I’m really not sure; I wouldn’t call it that. The point is really that it enables researchers to put Robin Day into the context of other people, organisations places and events, or at least it demonstrates how that can be done. It creates a network, and it intends to show the value of including archives in a network, rather than standing apart, in their ‘own world’.
Visualised relationships
The network can easily be visualised. There are tools out there to do this. The challenge is to create the data to feed into these visualisers. Again, this visualisation is not about archival name authority records, it is not domain specific.
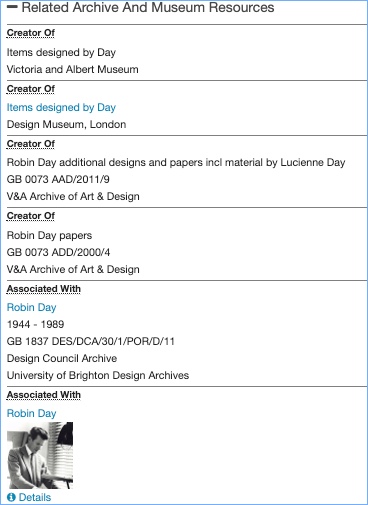
In the Robin Day page, we have a section for related archives and museum resources.
Related archive and museum resources
This lists archives Robin Day is the ‘creator of’ or archives he is ‘associated with’. It links to the Archives Hub, but also to other sources. One of the options for end users is to go and find out more about the archival sources, but it is not prioritised above other options.
So, this is essentially the idea – a page for a person, a page for an organisation. An information resources that focuses on creating a network of connections. We think this is a good approach, but creating something along these lines that is automated, sustainable and effective within an ongoing national service is much harder.
Why not just use this one record, link to the archive catalogues, and dispense with the individual name records that we have created? There are three reasons to consider providing access to the individual name records: biographical history, uncertainty around matching and ingesting name authority records.
In this phase of the Names Project the individual records for Beatrice Webb (as a name example), will be created either from the creator name or index terms that we have in the Archives Hub catalogues.
The main problem is the wide variation in name entries.
These are all entries in the Archives Hub. We can match them all up, but can we say they are all the same? Names without dates should not be matched with certainty, but quite often they will be the same person. (Beatrix Potter also often ends up being linked with Beatrice Webb, née Potter).
The decision we need to make is whether to provide links to these individual name records that we will have, or only use them as a source of data. It seems valuable to enable end users to see these names as a group, but it is another thing to risk integrating information from them all into one name record. There is no perfect answer to this, but it does seem important to clearly indicate the level of uncertainty. So many names that we have don’t have life dates, or have variations in structure. What we are looking to achieve is a clear provenance, giving end users the best understanding of what they are seeing.
What about name records that have been created by our contributors? The name records we create ourselves from catalogue descriptions will generally be no more than the name, dates, and biographical history. But, going forwards, we will want to work with much more detailed name records.
For Exploring British Design we created rich name records with an entity-relationship structure (essentially using the EAC-CPF structure and working in RDF), to demonstrate the power of connecting entities. For this purpose, we partially hand-crafted the name records, as well as carrying out some very complex processing to create various connections.
Part of the timeline for Robin Day
The example above shows events from the Robin Day timeline, with linked connections to related organisations. If we ingest EAC-CPF records we might get timelines like this.
Name records may also include relationships. The Borthwick Institute has good examples of name records with plenty of rich relationship information. e.g. Charles Lindley Wood, Viscount Halifax.
An excerpt from a Borthwick entry for Charles Lindley Wood
If we took this record into the Archives Hub it might seem to make sense for it to become the main person record for Wood. But that would involve a process of making choices, preferencing one name record over another. Possible, but tricky to do in an automated way. Another record office might also have a splendid example of a name entry for this person, with some different data. Furthermore, this record has links to the Borthwick catalogue. We would potentially have to remove these links.
It would be very challenging to create one record from several source EAC-CPF records for the same person – to blend timelines, or sort out relationships listed in different records, bearing in mind that it needs to be done in an automated way, keeping version control and dealing with revisions and new data coming in that might add to the name record. How could we compare and blend two lists of relationships? Or two chronologies? We’d probably end up having to keep them all, and then potentially have similar but different relationships and chronologies, giving a slightly confused user experience.
If we do ingest records like the one above, we will have to figure out how these more detailed records will relate to what we have already created. If, as planned, we have one generic name record for a person, it makes the job easier, as we won’t be looking to make any one EAC-CPF record into the main name record, we will simply link to it from the main record. Bear in mind, our main record is intended to be a domain-neutral entry – linking to other sources beyond archives. EAC-CPF records might do this to some extent, but they are unlikely to link to the Jisc Library Hub, and probably won’t link to Wikidata, or other external sources. They are far more likely to provide internal links to the archive catalogue they relate to.
Arguably, it might be easier to forget about creating name records ourselves (from the catalogue entries) and just work with name records that have been created by our contributors (which are likely to be well-structured and include life dates). But if we do that, the pot of names will grow slowly, as only a small proportion of repositories create name records. We can’t realistically give the end user a few thousand name records covering maybe 1-2% of our names – they might search for ‘Winston Churchill’ as a name, and find that we don’t have him! It would not remove the problem of name matching, and it would make the whole idea of reaching out beyond the archive domain, by linking into other resources using our names as the hook, rather ineffectual.
Therefore, we propose to keep the separate name records in our system We propose to create a ‘generic record’, which is what would be prominent in the Archives Hub display. We would then have the potential to link the records together, to blend them, to try some text mining and analysis techniques. It gives us options. It would not be sensible to make those decisions now. It is better to lay the groundwork that enables us to be flexible. This approach allows us to link to an individual name record where we don’t feel able to confirm a ‘same as’ relationship. It presents the option to the end user – here is a name – we think this is the same person, so we’ve provided a link.
The end user experience needs to make sense and not mislead or provide false information. Links to brief name records could seem confusing, but, as I have said, trying to bring together in one record all the information from several name records, with their biographies, relationships, aliases, events, related resources, is likely to be a nightmare. In the end, it will take a good deal more testing and working with researchers to work out what is best.
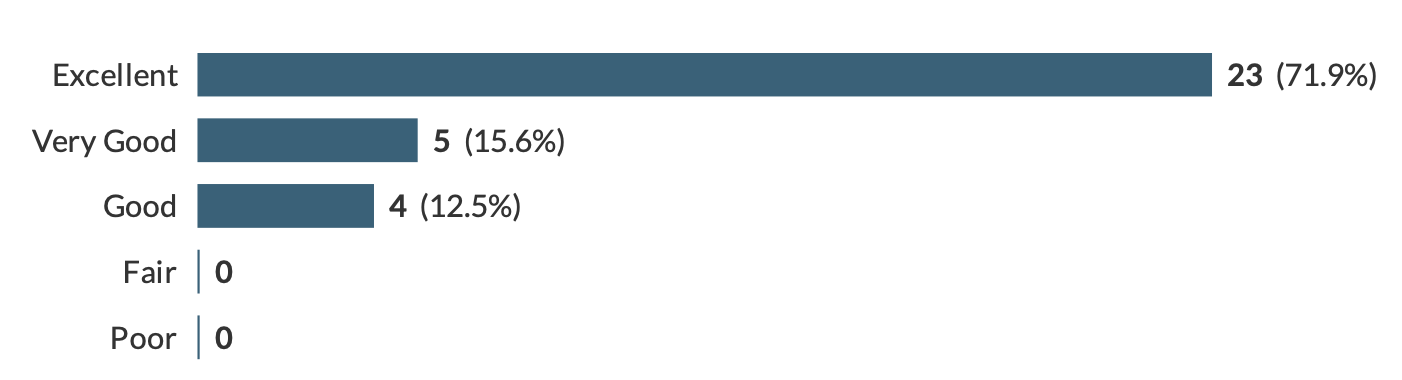 Content of the workshop
Content of the workshop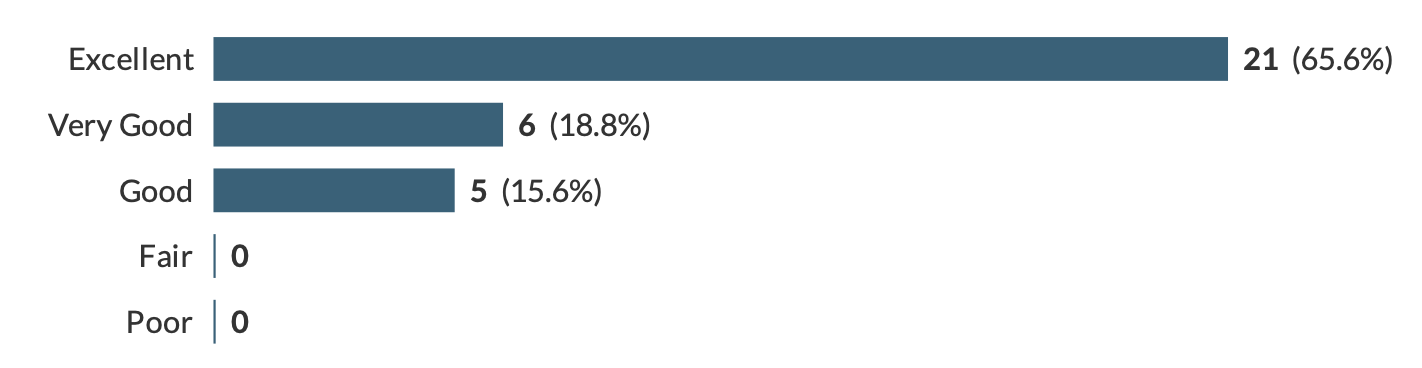 Clarity of the workshop
Clarity of the workshop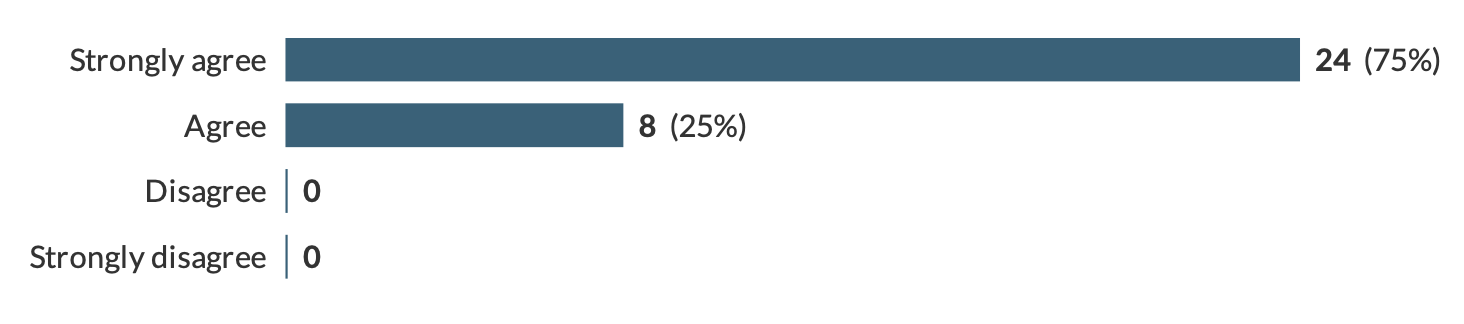 Useful & worthwhile
Useful & worthwhile