Introduction
As those of you who contribute to or use the Hub will know, we went live with our new system in Dec 2016. At the heart of our new system is our new workflow. One of the key requirements that we set out with when we migrated to a new system was a more robust and sustainable workflow; the system was chosen on the basis that it could accommodate what we needed.
This post is about the EAD (Encoded Archival Data) descriptions, and how they progress through our processing workflow. It is the data that is at the heart of the Archives Hub world. We also work with EAG (Encoded Archival Guide) for repository descriptions, and EAC-CPF (Encoded Archival Context, Corporate bodies, Persons and Families) for name entities. Our system actually works with JSON internally, but EAD remains our means of taking in data and providing data out via our API.
On the Archives Hub now we have two main means of data ingest, via our own EAD Editor, which can be thought of as ‘internal’, and via exports from archive systems, which can be thought of as ‘external’.
Data Ingest via the EAD Editor
1. The nature of the EAD
The Editor creates EAD according to the Archives Hub requirements. These have been carefully worked out over time, and we have a page detailing them at http://archiveshub.jisc.ac.uk/eadforthehub

When we started work on the new system, we were aware that having a clear and well-documented set of requirements was key. I would recommend having this before starting to implement a new system! But, as is often the case with software development, we didn’t have the luxury of doing that – we had to work it out as we went along, which was sometimes problematic, because you really need to know exactly what your data requirements are in order to set your system up. For example, simply knowing which fields are mandatory and which are not (ostensibly simple, but in reality this took us a good deal of thought, analysis and discussion).
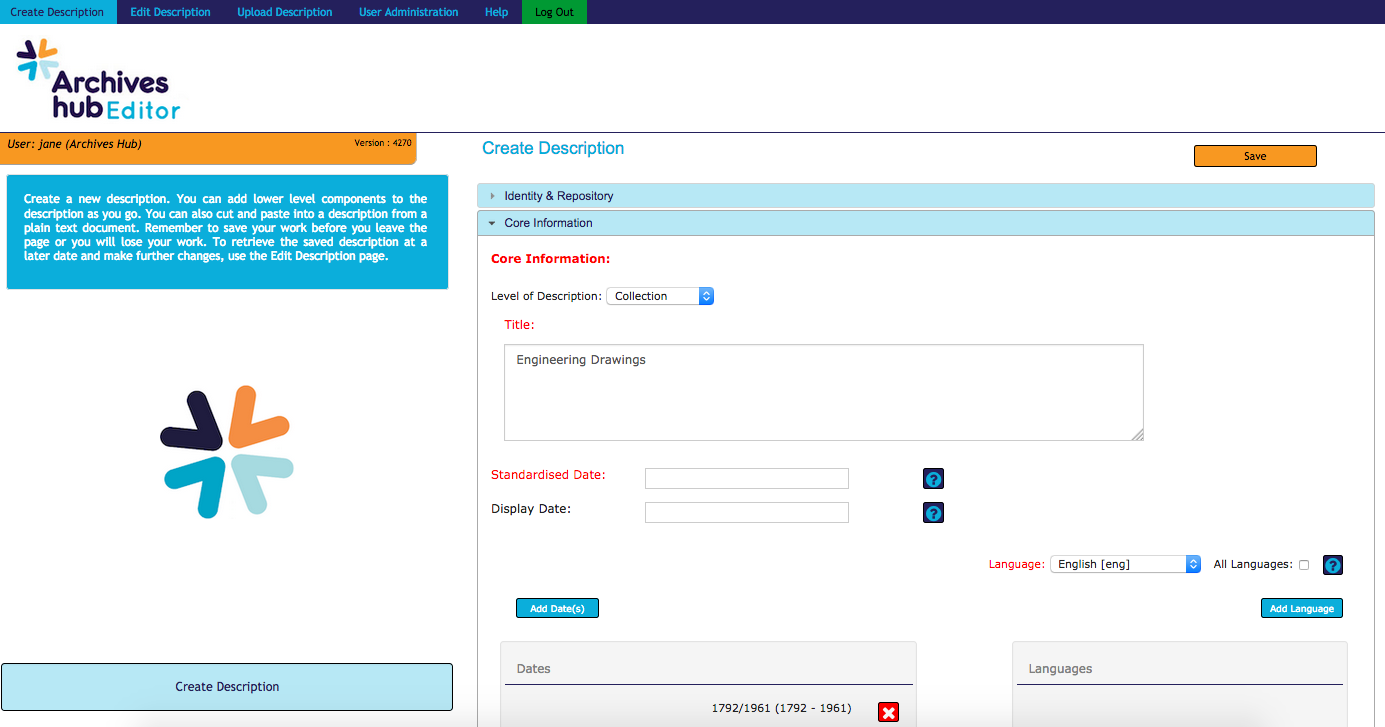
2. The scope of the EAD
EAD has plenty of tags and attributes! And they can be used in many ways. We can’t accommodate all of this in our Editor. Not only would it take time and effort, but it would result in a complicated interface, that would not be easy to use.
So, when we created the new Editor, we included the tags and attributes for data that contributors have commonly provided to the Hub, with a few more additions that we discussed and felt were worthwhile for various reasons. We are currently looking again at what we could potentially add to the Editor, and prioritising developments. For example, the <materialspec> EAD tag is not accommodated at the moment. But if we find that our contributors use it, then there is a good argument for including it, as details specific to types of materials, such as map scales, can be useful to the end user.
We don’t believe that the Archives Hub necessarily needs to reflect the entire local catalogue of a contributor. It is perfectly reasonable to have a level of detail locally that is not brought across into an aggregator. Having said that, we do have contributors who use the Archives Hub as their sole online catalogue, so we do want to meet their needs for descriptive data. Field headings are an example of content we don’t utilise. These are contained within <head> tags in EAD. The Editor doesn’t provide for adding these. (A contributor who creates data elsewhere may include <head> tags, but they just won’t be used on the Hub, see Uploading to the Editor).
We will continue to review the scope in terms of what the Editor displays and allows contributors to enter and revise; it will always be a work in progress.
3. Uploading to the Editor
In terms of data, the ability to upload to the Editor creates challenges for us. We wanted to preserve this functionality, as we had it on the old Editor, but as EAD is so permissive, the descriptions can vary enormously, and we simply can’t cope with every possible permutation. We undertake the main data analysis and processing within our main system, and trying to effectively replicate this in the Editor in order to upload descriptions would be duplicating effort and create significant overheads. One of our approaches to this issue is that we will preserve the data that is uploaded, but it may not display in the Editor. If you think of the model as ‘data in’ > ‘data editing’ > ‘data out’, then the idea is that the ‘data in’ and ‘data out’ provides all the EAD, but the ‘data editing’ may not necessary allow for editing of all the data. A good example of this situation occurs with the <head> tag, which is used for section headings. We don’t use these on the Hub, but we can ensure they remain in the EAD and they are there in the output from the Editor, so they are retained, but not displayed in the Editor. They can then be accessed by other means, such as through an XML Editor, and displayed in other interfaces.
We have disabled upload of exports from the Calm system to the Editor at present, as we found that the data variations, which often caused the EAD to be invalid, were too much for our Editor to cope with. It has to analyse the data that comes in and decide which fields to populate with which data. Some are straightforward – ‘title’ goes into <unittitle> for example, but some are not…for example, Calm has references and alternative references, and we don’t have this in our system, so they cause problems for the Editor.
4. Output from the Editor
When a description is submitted to the Archives Hub from the Editor, it is uploaded to our system (CIIM, pronounced ‘sim’), which is provided by Knowledge Integration, and modified for our own data processing requirements.
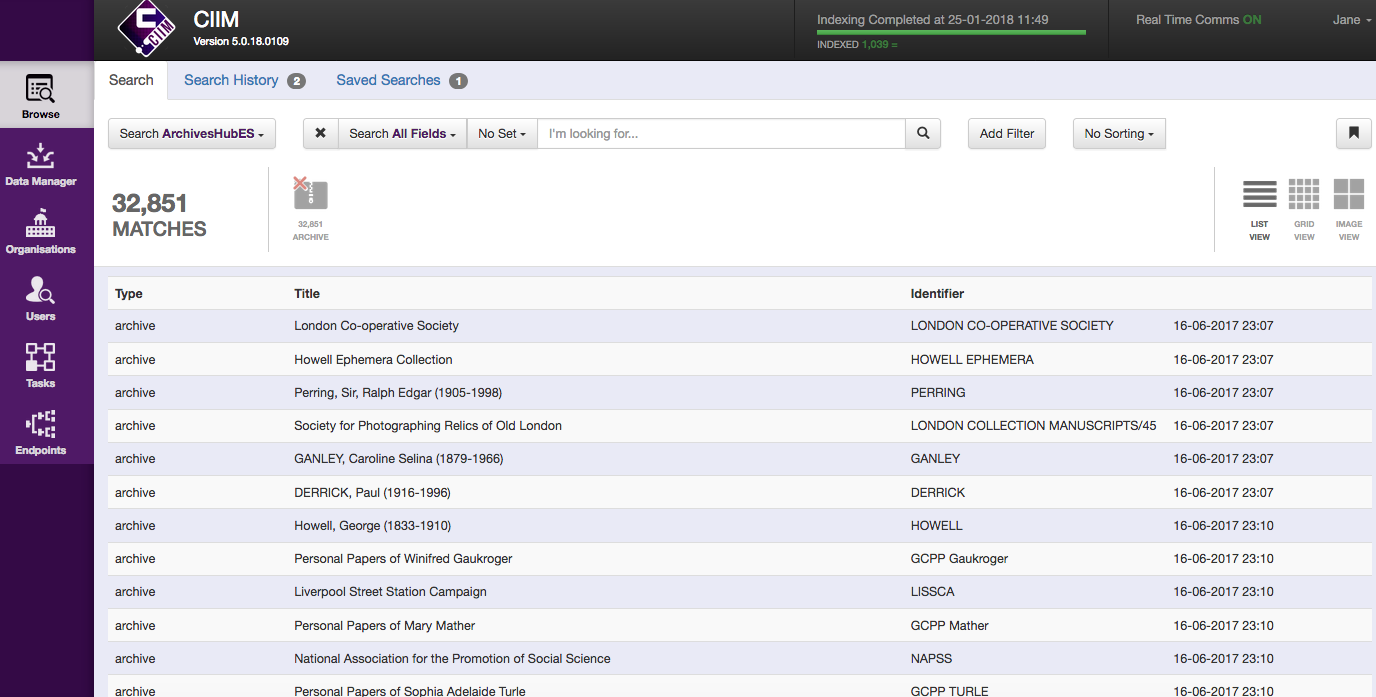
The CIIM framework allows us to implement data checking and customised transformations, which can be specific to individual repositories. For the data from the Editor, we know that we only need a fairly basic default processing, because we are in control of the EAD that is created. However, we will have to consider working with EAD that is uploaded to the Editor, but has not been created in the Editor – this may lead to a requirement for additional data checking and transformations. But the vast majority of the time descriptions are created in the Editor, so we know they are good, valid, Hub EAD, and they should go through our processing with no problems.
Data Ingest from External Data Providers
1. The nature of the EAD
EAD from systems such as Calm, Archivist’s Toolkit and AtoM is going to vary far more than EAD produced from the Editor. Some of the archival management systems have EAD exports. To have an export is one thing; it is not the same as producing EAD that the Hub can ingest. There are a number of factors here. The way people catalogue varies enormously, so, aside from the system itself, the content can be unpredictable – we have to deal with how people enter references; how they enter dates; whether they provide normalised dates for searching; whether entries in fields such as language are properly divided up, or whether one entry box is used for ‘English, French, Latin’, or ‘English and a small amount of Latin’; whether references are always unique; whether levels are used to group information, rather than to represent a group of materials; what people choose to put into ‘origination’ and if they use both ‘origination’ and ‘creator’; whether fields are customised, etc. etc.
The system itself will influence on the EAD output. A system will have a template, or transformation process, that maps the internal content to EAD. We have only worked in any detail with the Calm template so far. Axiell, the provider of Calm, made some changes for us, for example, only six languages were exporting when we first started testing the export, so they expanded this list, and then we made additional changes, such as allowing for multiple creators, subjects and dates to export, and ensuring languages in Welsh would export. This does mean that any potential Calm exporter needs to use this new template, but Axiell are going to add it to their next upgrade of Calm.
We are currently working to modify the AdLib template, before we start testing out the EAD export. Our experience with Calm has shown us that we have to test the export with a wide variety of descriptions, and modify it accordingly, and we eventually get to a reasonably stable point, where the majority of descriptions export OK.
We’ve also done some work with AtoM, and we are hoping to be able to harvest descriptions directly from the system.
2. The scope of the EAD
As stated above, finding aids can be wide ranging, and EAD was designed to reflect this, but as a result it is not always easy to work with. We have worked with some individual Calm users to extend the scope of what we take in from them, where they have used fields that were not being exported. For instance, information about condition and reproduction was not exporting in one case, due to the particular fields used in Calm, which were not mapping to EAD in the template. We’ve also had instances of index terms not exporting, and sometimes this had been due to the particular way an institution has set up their system. It is perfectly possible for an institution to modify the template themselves so that it suits their own particular catalogues, but this is something we are cautious about, as having large numbers of customised exports is going to be harder to manage, and may lead to more unpredictable EAD.
3. Uploading to the Editor
In the old Hub world, we expected exports to be uploaded to the Editor. A number of our contributors preferred to do this, particularly for adding index terms. However, this lead to problems for us because we ended up with such varied EAD, which mitigated against our aim of interoperable content. If you catalogue in a system, export from that system, upload to another system, edit in that system, then submit to an aggregator (and you do this sometimes, but other times you don’t), you are likely to run into problems with version control. Over the past few years we have done a considerable amount of work to clarify ‘master’ copies of descriptions. We have had situations where contributors have ended up with different versions to ours, and not necessarily been aware of it. Sometimes the level of detail would be greater in the Hub version, sometimes in the local version. It led to a deal of work sorting this out, and on some occasions data simply had to be lost in the interests of ending up with one master version, which is not a happy situation.
We are therefore cautious about uploading to the Editor, and we are recommending to contributors that they either provide their data directly (through exports) or they use the Editor. We are not ruling out a hybrid approach if there is a good reason for it, but we need to be clear about when we are doing this, what the workflow is, and where the master copy resides.
4. Output from Exported Descriptions
When we pass the exports through our processing, we carry out automated transformations based on analysis of the data. The EAD that we end up with – the processed version – is appropriate for the Hub. It is suitable for our interface, for aggregated searching, and for providing to others through our APIs. The original version is kept, so that we have a complete audit trail, and we can provide it back to the contributor. The processed EAD is provided to the Archives Portal Europe. If we did not carry out the processing, APE could not ingest many of the descriptions, or else they would ingest, but not display to the optimum standard.
Future Developments
Our automated workflow is working well. We have taken complete, or near complete, exports from Calm users such as the Universities of Nottingham, Hull and (shortly) Warwick, and a number of Welsh local authority archives. This is a very effective way to ensure that we have up-to-date and comprehensive data.
We have well over one hundred active users of the EAD Editor and we also have a number of potential contributors who have signed up to it, keen to be part of the Archives Hub.
We intend to keep working on exports, and also hope to return to some work we started a few years ago on taking in Excel data. This is likely to require contributors to use our own Excel template, as it is impractical to work with locally produced templates. The problem is that working with one repository’s spreadsheet, translating it into EAD, could take weeks of work, and it would not replicate to other repositories, who will have different spreadsheets. Whilst Excel is reasonably simple, and most offices have it, it is also worth bearing in mind that creating data in Excel has considerable shortcomings. It is not designed for hierarchical archival data, which has requirements in terms of both structure and narrative, and is constantly being revised. TNA’s Discovery are also working with Excel, so we may be able to collaborate with them in progressing this area of work.
Our new architecture is working well, and it is gratifying to see that what we envisaged when we started working with Knowledge Integration and started setting out our vision for our workflow is now a reality. Nothing stands still in archives, in standards, in technology or in user requirements, so we cannot stand still either, but we have a set-up that enables us to be flexible, and modify our processing to meet any new challenges.






