
The BL Labs is an initiative funded by the Mellon Foundation that invites researchers and developers to work with the BL and their digital data to address research questions. The Symposium 2014 showcased some of the work funded by the Labs, presenting innovative and exploratory projects that have been funded through this initiative. This year’s competition winners are the Victorian Meme Machine, creating a database of Victorian jokes, and a Text to Image Linking Tool (TILT) for linking areas on a page image and a clear transcription of the content.
Tim Hitchcock, Professor of Digital History from the University of Sussex, opened with a great keynote talk. He started out by stressing the role of libraries, archives and museums in preserving memory and their central place in a complex ecology of knowledge discovery, dissemination and reflection. He felt it was essential to remember this when we get too caught up in pursuing shiny new ideas. It is important to continually rethink what it is to be an information professional; whilst also respecting the basic principles that a library (archive, museum) was created to serve.
Tim Hitchcock’s talk was Big Data, Small Data and Meaning. He said that conundrums of size mean there is a danger of a concentration on Big Data and a corresponding neglect of Small Data. But can we view and explore a world encompassing both the minuscule and the massive? Hitchcock introduced the concept of the macroscope, a term coined in a science fiction novel by Piers Anthony back in 1970. He used this term in his talk to consider the idea of a macro view of data. How has the principle of the macroscope influenced the digital humanities? Hitchcock referred to Katy Borner’s work with Plug-and-Play Macroscopesa: “Macroscopes let us observe what is at once too great or too slow or too complex for the human eye and mind to notice and comprehend.” (See http://vimeo.com/33413091 for an introductory video).
Hitchcock felt that ideally macroscopes should be to observe patterns across large data and at the same time show the detail within small data. The way that he talked about Big Data within the context of both the big and the small helped me to make more sense of Big Data methods. I think that within the archive community there has been something of a collective head scratching around Big Data; what its significance is, and how it relates to what we do. In a way it helps to think of it alongside the analysis that Small Data allows researchers to undertake.
Hitchcock gave some further examples of Big Data projects. Paper Machines is a plugin for Zotero that enables topic modelling analysis. It allows the user to curate a large collection of works and explore its characteristics with some great results; but the analysis does not really address detail.
The History Manifesto, by Jo Guldi and David Armitage talks about how Big Data might be used to redefine the role of Digital Humanities. But Hitchcock criticised it for dismissing micro-history as essentially irrelevant.
Scott Weingart is also a fan of the macroscope. He is a convincing advocate for network analysis, which he talks about in his blog, The modern role of DH in a data-driven world:
“distant reading occludes as much as it reveals, resulting in significant ethical breaches in our digital world. Network analysis and the humanities offers us a way out, a way to bridge personal stories with the big picture, and to bring a much-needed ethical eye to the modern world.”
Hitchcock posited that the large scale is often seen as a route to impact in policy formation, and this is an attractive inducement to think large. In working on a big data scale, Humanities can speak to power more convincingly; it can lead to a more powerful voice and more impact.
We were introduced to Ben Schmidt’s work, Prochronisms. This uses TV anachronisms to learn about changes in language scales of analysis around the analysis of text used, and Schmidt has done some work around particular TV programmes and films, looking at the overall use of language and the specifics of word use. One example of his work is the analysis of 12 Years a Slave:

‘the language Ridley introduces himself is full of dramatically modern words like “outcomes,” “cooperative,” and “internationally:” but that where he sticks to Northup’s own words, the film is giving us a good depiction of how things actually sounded. This is visible in the way that the orange ball is centered much higher than the blue one: higher translates to “more common than then now.”‘
Schmidt gives very entertaining examples of anachronisms, for example, the use of ‘parenting a child’ in the TV drama series Downton Abbey, which only shows up in literature 5 times during the 1920’s and in a rather different context to our modern use; his close reading of context also throws up surprises, such as his analysis of the use of the word ‘stuff’ in Downton Abbey (as in ‘family stuff’ or ‘general stuff’), which does not appear to be anachronistic and yet viewers feel that it is a modern term. (A word of warning, the site is fascinating and it’s hard to stop reading it once you start!)
Professor Hitchcock gave this work as an example of using a macroscope effectively to combine the large and the small. Schmidt reveals narrative arcs; maybe showing us something that hasn’t been revealed before…and at the same time creates anxiety amongst script writers with his stark analysis!
Viewing data on a series of scales simultaneously seems a positive development, even with the pitfalls. But are humanists privileging social science types of analysis over more traditional humanist ones? Working with Big Data can be hugely productive and fun, and it can encourage collaboration, but are humanist scholars losing touch with what they traditionally do best? Language and art, cultural construction and human experience are complex things. Scholars therefore need to encompass close reading and Small Data in their work in order to get a nuanced reading. Our urge towards the all-inclusive is largely irresistible, but in this fascination we may lose the detail. The global image needs to be balanced with a view from the other end of the macroscope.
It is important to represent and mobilise the powerless rather than always thinking about the relationship to the powerful; to analyse the construct of power rather than being held in the grip of power and technology. Histories of small things are often what gives voice to those who are marginalised. Humanists should encompass the peculiar and eccentric; they should not ignore the power of the particular.
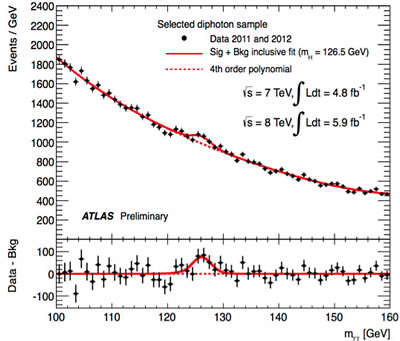
Of course, Big Data can have huge and fundamental results. The discovery of the Higgs particle was the result of massive data crunching and finding a small ‘bump’ in the data that gave evidence to support its existence. The other smaller data variations needed to be ignored in this scenario. It was a case of millions of rolls of the dice to discover the elusive particle. But if this approach is applied across the board, the assumption is that the signal, or the evidence, will come through, despite the extraneous blips and bumps. It doesn’t matter if you are using dirty data because small hiccups are just ignored. But humanists need to read data with an eye to peculiarities and they should consider the value of digital tools that allow them to think small.
Hitchcock believes that to perform humanities effectively we need to contextualise. And the importance of context is never lost to an archivist, as this is a cornerstone of our work. Big Data analysis can lose this context; Small Data is all about understanding context to derive meaning.
Using the example of voice onset timing, which refers to the tiny breathy gap before speaking, Hitchcock showed that a couple of milliseconds of empty space can demand close reading, because it actually changes depending on who you are talking to, and it reveals some really interesting findings. A Big Data approach would simply miss this fascinating detail.
Big data has its advantages, but it can mean that you don’t look really closely at the data set itself. There is a danger you present your results in a compelling graph or visualisation, but it is hard to see whether it is a flawed reality. You may understand the whole thing, and you can draw valuable conclusions, but you don’t take note of what the single line can tell you.