Background
Back in 2008 the Archives Hub embarked upon a project to become distributed; the aim was to give control of their data to the individual contributors. Every contributor could host their own data by installing and running a ‘mini Hub’. This would give them an administrative interface to manage their descriptions and a web interface for searching.
Five years later we had 6 distributed ‘spokes’ for 6 contributors. This was actually reduced from 8, which was the highest number of institutions that took up the invitation to hold their own data out of around 180 contributors at the time.
The primary reason for the lack of success was identified as a lack of technical knowledge and the skills required for setting up and maintaining the software. In addition to this, many institutions are not willing to install unknown software or maintain an unfamiliar operating system. Of course, many Hub contributors already had a management system, and so they may not have wanted to run a second system; but a significant number did not (and still don’t) have their own system. Part of the reason may institutions want an out-of-the-box solution is that they do not have consistent or effective IT support, so they need something that is intuitive to use.
The spokes institutions ended up requiring a great deal of support from the central Hub team; and at the same time they found that running their spoke took a good deal of their own time. In the end, setting up a server with an operating system and bespoke software (Cheshire in this case) is not a trivial thing, even with step-by-step instructions, because there are many variables and external factors that impact on the process. We realised that running the spokes effectively would probably require a full-time member of the Hub team in support, which was not really feasible, but even then it was doubtful whether the spokes institutions could find the IT support they required on an ongoing basis, as they needed a secure server and they needed to upgrade the software periodically.
Another big issue with the distributed model was that the central Hub team could no longer work on the Hub data in its entirety, because the spoke institutions had the master copy of their own data. We are increasingly keen to work cross-platform, using the data in different applications. This requires the data to be consistent, and therefore we wanted to have a central store of data so that we could work on standardising the descriptions.
The Hub team spend a substantial amount of time processing the data, in order to be able to work with it more effectively. For example, a very substantial (and continuing) amount of work has been done to create persistent URIs for all levels of description (i.e. series, item, etc.). This requires rigorous consistency and no duplications of references. When we started to work on this we found that we had 100’s of duplicate references due to both human error and issues with our workflow (which in some cases meant we had loaded a revised description along with the original description). Also, because we use archival references in our URIs, we were somewhat nonplussed to discover that there was an issue with duplicates arising from references such as GB 234 5AB and GB 2345 AB. We therefore had to change our URI pattern, which led to substantial additional work (we used a hyphen to create gb234-5ab and gb2345-ab).
We also carry out more minor data corrections, such as correcting character encoding (usually an issue with characters such as accented letters) and creating normalised dates (machine processable dates).
In addition to these types of corrections, we run validation checks and correct anything that is not valid according to the EAD schema, and we are planning, longer term, to set up a workflow such that we can implement some enhancement routines, such as adding a ‘personal name’ or ‘corporate name’ identifying tag to our creator names.
These data corrections/enhancements have been applied to data held centrally. We have tried to work with the distributed data, but it is very hard to maintain version control, as the data is constantly being revised, and we have ended up with some instances where identifying the ‘master’ copy of the data has become problematic.
We are currently working towards a more automated system of data corrections/enhancement, and this makes it important that we hold all of the data centrally, so that we ensure that the workflow is clear and we do not end up with duplicate slightly different versions of descriptions. (NB: there are ways to work more effectively with distributed data, but we do not have the resources to set up this kind of environment at present – it may be something for the longer term).
We concluded that the distributed model was not sustainable, but we still wanted to provide a front-end for contributors. We therefore came up with the idea of the ‘micro sites’.
What are Hub Micro Sites?
The micro sites are a template based local interface for individual Hub contributors. They use a feed of the contributor’s data from the central Archives Hub, so the data is only held in one place but accessible through both interfaces: the Hub and the micro site. The end-user performs a search on a micro site, the search request goes to the central Hub, and the results are returned and displayed in the micro site interface.
The principles underlying the micro sites are that they need to be:
• Sustainable
• Low cost
• Efficient
• Realistically resourced
A Template Approach?
As part of our aim of ensuring a sustainable and low-cost solution we knew we had to adopt a one-size-fits-all model. The aim is to be able to set up a new micro site with minimal effort, as the basic look and feel stays the same. Only the branding, top and bottom banners, basic text and colours change. This gives enough flexibility for a micro site to reflect an institution’s identity, through its logo and colours, but it means that we avoid customisation, which can be very time-consuming to maintain.
The micro sites use an open approach, so it would be possible for institutions to customise themselves, by manipulating the stylesheets. However, this is not something that the Archives Hub can support, and therefore the institution would need to have the expertise necessary to maintain this themselves.
The Consultation Process
We started by talking to the Spokes institutions and getting their feedback about the strengths and weaknesses of the spokes and what might replace them. We then sent out a survey to Hub contributors to ascertain whether there would be a demand for the micro sites.
Institutions preferred the micro sites to be hosted by the Archives Hub. This reflects the lack of technical support within UK archives. This solution is also likely to be more efficient for us, as providing support at a distance is often more complicated than maintaining services in-house.
The responders generally did not have images displayed on the Hub, but intended to in the future, so this needed to be taken into account. We also asked about experiences with understanding and using APIs. The response showed that people had no experience of APIs and did not really understand what they were, but were keen to find out more.
We asked for requirements and preferences, which we have taken into account as much as possible, but we explained that we would have to take a uniform approach, so it was likely that there would need to be compromises.
After a period of development, we met with the early adopters of the micro sites (see below) to update them on our progress and get additional requirements from them. We considered these requirements in terms of how practical they would be to implement in the time scale that we were working towards, and we then prioritised the requirements that we would aim to implement before going live.
The additional requirements included:
- Search in multi-level description: the ability to search within a description to find just the components that include the search term
- Reference search: useful for contributors for administrative purposes
- Citation: title and reference, to encourage researchers to cite the archive correctly
- Highlight: highlighting of the search term(s)
- Links to ‘search again’ and to ‘go back’ to the collection result
- The addition of Google Analytics code in the pages, to enable impact analysis
The Development Process
We wanted the micro sites to be a ‘stand alone’ implementation, not tied to the Archives Hub. We could have utilised the Hub, effectively creating duplicate instances of the interface, but this would have created dependencies. We felt that it was important for the micro sites to be sustainable independent of our current Hub platform.
In fact, the Micro sites have been developed using Java, whereas the Hub uses Python, a completely different programming language. This happened mainly because we had a Java programmer on the team. It may seem a little odd to do this, as opposed to simply filtering the Hub data with Python, but we think that it has had unforeseen benefits. Namely, that the programmers who have worked on the micro sites have been able to come at the task afresh, and work on new ways to solve the many challenges that we faced. As a result of this we have implemented some solutions with the micro sites that are not implemented on the Hub. Equally, there were certainly functions within the Hub that we could not replicate with the micro sites – mainly those that were specifically set up for the aggregated nature of the Hub (e.g browsing across the Hub content).
It was a steep learning curve for a developer, as the development required a good understanding of hierarchical archival descriptions, and also an appreciation of the challenges that come from a diverse data set. As with pretty much all Hub projects, it is the diverse nature of the data set that is the main hurdle. Developers need patterns; they need something to work with, something consistent. There isn’t too much of that with aggregated archives catalogues!
The developer utilised what he could from the Hub, but it is the nature of programming that reverse engineering of someone else’s code can be a great deal harder than re-coding, so in many cases the coding was done from scratch. For example, the table of contents is a particularly tricky thing to recreate, but the code used for the current Hub proved to be too complex to work with, as it has been built up over a decade and is designed to work within the Hub environment. The table of contents requires the hierarchy to be set out, collapsible folder structures, links to specific parts of the description with further navigation from there to allow the researcher to navigate up and down, so it is a complex thing to create and it took some time to achieve.
The feed of data has to provide the necessary information for the creation of the hierarchy, and our feed comes through SRU (Search/Retrieve via URL), which is a standard search protocol for Internet search queries using Contextual Query Language (CQL). This was already available through the Hub API, and the micro sites application makes uses of SRU in order to perform most of the standard searches that are available on the Hub. Essentially, each of the micro sites are provided by a single web application that acts as a layer on the Archives Hub. To access the individual micro sites, the contributor provides a shortened version of the institution’s name as a sub-string to the micro sites web address. This then filters the data accordingly for that institution, and sets up the site with the appropriate branding. The latter is achieved through CSS stylesheets, individually tailored for the given institution by a stand-alone Java application and a standard CSS template.
Page Display
One of the changes that the developer suggested for the micro sites concerns the intellectual division of the descriptions. On the current Hub, a description may carry over many pages, but each page does not represent anything specific about the hierarchy, it is just a case of the description continuing from one page to the next. With the micro sites we have introduced the idea that each ‘child’ description of the top level is represented on one page. This can more easily be shown through a screenshot:
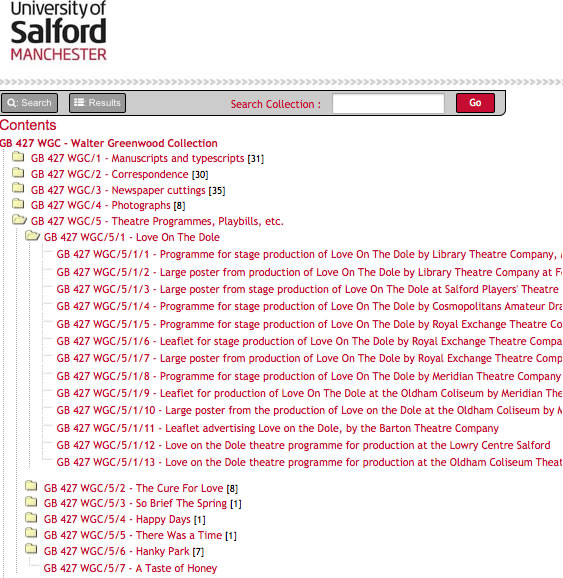
In the screenshot above, the series ‘Theatre Programmes, Playbills, etc’ is a first-level child description (a series description) of the archive collection ‘The Walter Greenwood Collection’. Within this series there are a number of sub-series, the first of which is ‘Love on the Dole’, the last of which is ‘A Taste of Honey’. The researcher will therefore get a page that contains everything within this one series – all sub-series and items – if there are any described in the series.
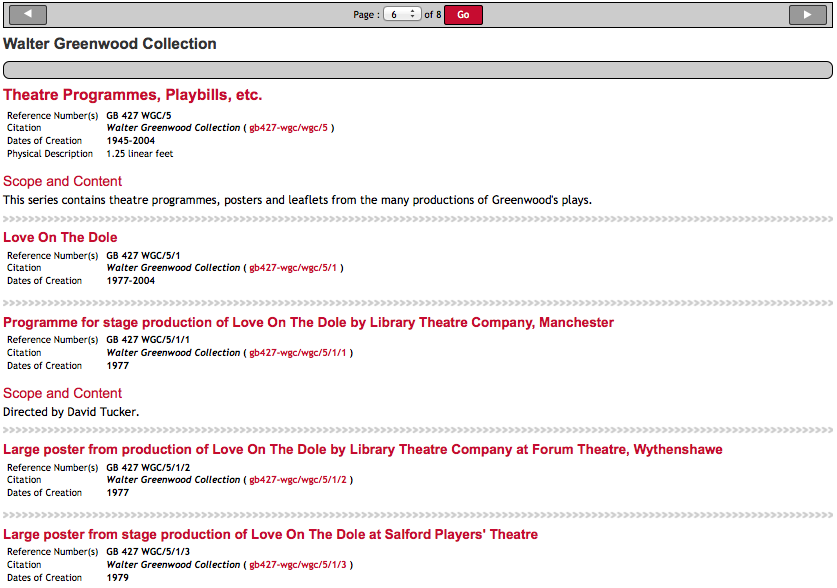
The sense of hierarchy and belonging is further re-enforced by repeating the main collection title at the top of every right hand pane. The only potential downside to this approach is that it leads to variable length ‘child’ description pages, but we felt it was a reasonable trade-off because it enables the researcher to get a sense of the structure of the collection. Usually it means that they can see everything within one series on one page, as this is the most typical first child level of an archival description. In EAD representation, this is everything contained within the <c01> tag or top level <c> tag.
Next Steps
We are currently testing the micro sites with early adopters: Glasgow University Archive Services, Salford University Archives, Brighton Design Archives and the University of Manchester John Rylands Library.
We aim to go live during September 2014 (although it has been hard to fix a live date, as with a new and innovative service such as the micro sites unforeseen problems tend to emerge with alarming regularity). We will see what sort of feedback we get, and it is likely that we will find a few things need addressing as a result of putting the micro sites out into the big wide world. We intend to arrange a meeting for the early adopters to come together again and feed back to us, so that we can consider whether we need a ‘phase 2’ to iron out any problems and make any enhancements. We may at that stage invite other interested institutions, to explain the process and look at setting up further sites. But certainly our aim is to roll out the micro sites to other Archives Hub institutions.